基于SolrCloud的分布式相似性检测系统
2016-12-16蒋佳洲北京师范大学株洲附属学校株洲412000
蒋佳洲 北京师范大学株洲附属学校 株洲 412000
基于SolrCloud的分布式相似性检测系统
蒋佳洲 北京师范大学株洲附属学校株洲412000
文档相似性检测中,很多文本的资源是碎片化存储,实现全局的文本查重,在没有统一管理的情况下,不可能短时间将数据集中,数据仍旧是分散存储,为实现全局的检查,采用基于SolrCloud的分布式查重。论文在b位Minwise Hash的基础上,提出了弹性细粒度相似性检测方法;通过分析多粒度特征提取的特点,设置项目模板进行正则表达式匹配,提升了相似性检索的效率,最后通过系统实现验证该系统的有效性。
SolrCloud;相似性检测;哈希;分布式
0 引言
随着信息时代的发展,数字文档(如基金项目申报文档,论文文档,网页等)呈几何级数增长的同时,由于其本身的易复制性,导致项目重复申请,论文抄袭,网页重复等不良现象频频出现;大量相似文档的存在和数据孤岛数量不断的增加,也降低了信息检索的效率和精度。在这种情况下,研究高性能的分布式相似性检测系统显得尤为重要。
Minwise Hash[1]算法作为目前主流的海量集合相似度估计算法,经过不断改进[2],在信息检索中得到广泛应用[3]。Li等人[4]提出的b位Minwise Hash在Minwise Hash算法的基础之上通过降低存储空间和计算时间进一步提高了算法的效率。同时,b位Minwise Hash也是对集合估计算法的一种理论创新,在三者相似性检测[5]、大型线性支持向量机[6]以及基于最大似然估计的估计算法[7]等领域有了新的应用发展[8]。论文在b位Minwise Hash的基础上,提出了一种细粒度文档相似性快速检测方法,并将其应用到分布式相似性检测系统中,介绍它的系统框架、系统关键技术难点和解决方案以及软件实际使用效果。
1 系统的架构
1.1基于SolrCloud的分布式系统
(1)SolrCloud是基于Solr和 ZooKeeper的分布式搜索方案。该方案具有集中配置、自动容错、近实时搜索、负载均衡等特点。系统为满足全局相似性检查,基于SolrCloud提出一种分布式文档相似检测方案,较好解决跨数据源相似性检测问题。这种分布式查重方式核心算法应用了b位Minwise Hash,兼顾检测的精度和效率,结合弹性细粒度,对各类数据进行加工处理,准确匹配各章节,将文档最小原子锁定到句子级,形成海量句子指纹库;每个数据站点间的传输通道和统一的传输接口规范。
把所有的索引集合视为一个总索引库,将总索引库分为三个索引片,分别存放在三个站点,即为主索引库,并且,考虑到平台的健壮性,为每个索引片增设了一个备份,即为从索引库。各个索引库之间的联系通过ZooKeeper提供的服务协调。

图1 基于SolrCloud,ZooKeeper的检测系统架构图
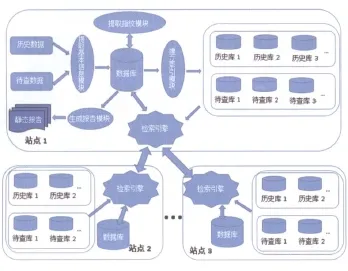
图2 跨部门检测模式
(2)联盟式检测的模式。如图2所示,站点1是查重系统站点,主要进行预处理数据,计算相似度。站点2和站点3主要是作为跨部门的数据采集点,在站点1需要的时候传输历史数据至站点1,站点将获得自身数据库以外的待对比历史库,以期获得更准确的查重结果。
(3)数据的检测流程。如图3所示,包含以下两个流程。
1)本地检测:将待查库的文本发给本地引擎,对文本中每个段落进行计算相似性,检索出相似的段落。
2)远程检测:系统中站点表保存了所有站点的IP地址及端口。索引库表保存了能够访问到的远程所有索引库的信息。
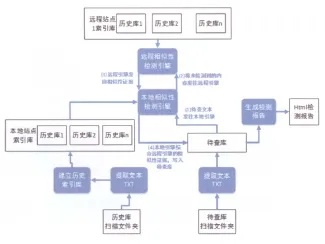
图3 检测流程
在两种检测的基础上实现跨站点检测步骤:以与远程站点1的历史库1比对为例。
第一步:用户选择远程站点,系统访问站点表,获取远程站点1的IP。然后向远程站点1发送请求获取站点1可供查的索引库列表。
第二步:用户选择历史库1,系统在任务表中新建检测任务。
第三步:本地检测引擎扫描数据库,获取检测任务信息,检测完后,没有找到的句子,再将句子的指纹加密发送到远程站点1,远程站点1的引擎接收后检测。

图4 系统网络拓扑结构图
第四步:远程站点1查完将检测结果发回本地站点,本地结合远程站点1的相似性证据一起写回待查表。
1.2系统的网络拓扑结构
由于相似性检测系统通常都是单位内部人员使用,因此系统一般部署在内部局域网环境中。当然,对于大众用户的相似性检测需求,系统也可以对Internet开放。
本文构建系统部署的网络拓扑结构如图4所示。
2 系统的关键技术
2.1确定检测粒度
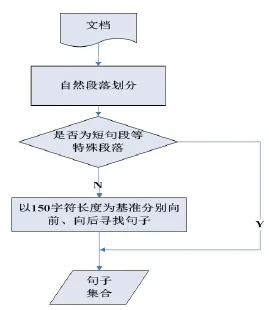
图5 确定检测粒度流程图
细粒度文档相似性检测,通常是将文档切割为多个自定义长度的文本块集合,通过相关检索,计算并获取每个文本块与文本集合中的文本的相似程度。如果文本块的长度选择过大,则计算准确度不高,容易遗漏多方抄袭部分内容的情况。同时,如果文本块长度选择太小,也会造成时间和空间的开销过大。
在文档切割的过程中,通常会首先按照自然段对文档进行初步的划分,这是由于自然段可以表达作者相对完整的思想,同时也提供了对文档结构的换行。而另一方面,大部分抄袭者也都是选择以段落为单位进行抄袭的。然而,文档中通常也会存在一些很长的自然段。例如,在论文中又包括了引言、研究方法和内容、实验结果、讨论和结论等,每项内容又包括了段、句子、文本块、词等,这些特征都是多层次的。大量过长自然段和多层次特征的存在使得单单基于自然段落的划分是行不通的。
如图5所示,通过将自然段落切分为150字符左右的“句子”作为检测单元粒度。同时对于特殊的独句段,短句段等段落,这类段落通常具有很强的同义性,使用频度很高,并且通常在文章中是起起承转合的作用而与文档的核心内容无关。因此,对于这类段落不进行相似性的检测。
2.2细粒度指纹索引的建立
实际上文档相似性检测就是文档间“句子”指纹的海明距离的范围检索。令细粒度的检测单位“句子”的指纹为100位的海明码指纹(fs,1-fs,100),将k=100位指纹进行分组,分为m=5组(20,20,20,20,20,20)[11]。如(1)所示,则一个具有s个长句的文档D可以表示为:

文档数为n的文档集M表示为:

其中fn,s,k为第n个文档的第s个句子对应的第k位海明码。若每个分组命名为{A,B,C,D,E},则定义向量VA,VB,VC,VD,VE。

分别对向量VA,VB,VC,VD,VE建立m=5个B+树索引。
在实际的系统应用中,可以利用数据库管理技术在指定的表中建立m=5个字段,并对这5个字段分别建立INDEX索引。论文采用了lucene4.9的版本来建立索引,Lucene作为一种全文检索引擎架构,具有优秀的检索效率,增量插入和删除等操作非常方便。
2.3细粒度相似性比对

步骤2:分别在m=5个B+树上执行查询条件(3),执行查询条件后的集合定义为Set(Pre_Query)。

步骤3:对Set(Pre_Quer y)中的所有元素进行Disthamm距离计算,将所有满足条件:Disthamm<rhamm的加入集合Set(Query)中。其中上述rhamm为海明距离的阈值。
2.4系统相似性实施效果
为测试联盟式相似性检测的实际效果,论文在普通PC机上搭建起分布式处理平台,其中一台主机和三台机器子节点。本章采用的实验数据来至知网的的1万论文文档对,将数据分为数据集1,数据集2和数据集3,每个数据集大小不同,每个数据集都有一定的重复率。通过三个不同的数据集的实验,可以有效的评估出联盟式检测的性能。数据集详情如表1所示。数据集1,数据集2和数据集3的实验结果分别如表2,3所示。
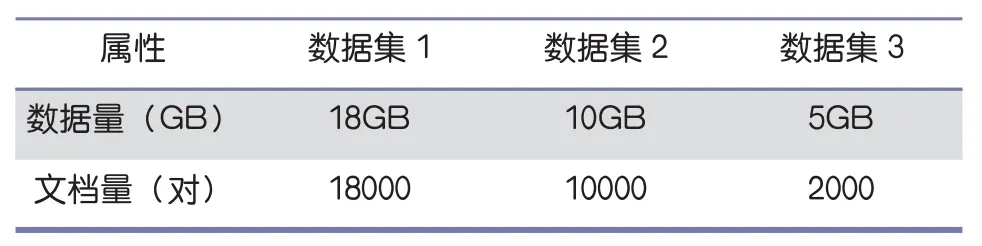
表1 数据集详情
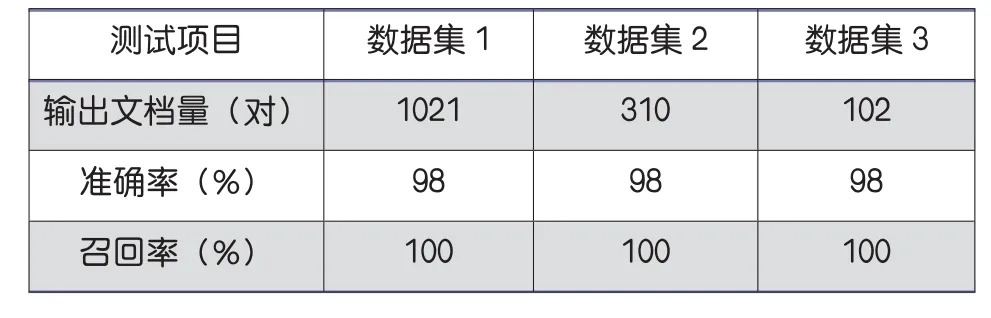
表2 阈值R0=0.3时,单个数据集相似性检测效果

表3 阈值R0=0.3时,3个数据集联盟相似性检测效果

图6 (a) 一对多相似性证据显示

图6 (b) 一对一相似性证据显示
三个数据集存在重复数据,要对数据进行相似性检测,首先要读取将要存储的文件数据,然后将文件数据进行处理,求出文件的特征指纹,将指纹与索引表进行匹配,最后计算出文档的相似度。如表2,3所示,联盟式相似性检测的结果表明,三个数据集独立的相似性检测输出文档对共为1333,三个数据集联盟相似性检测输出文档对2100,多输出了767份文档对,证明了跨数据源抄袭现象的存在。因此,在以后的查重工作中,根据实际情况有必要进行跨数据源检测,提升项目查重的整体效果。
如图6所示,系统给出的相似性证据界面,其中包括一对一直观比对显示以及一对多的细粒度抄袭证据显示。
3 结语
分组指纹的弹性细粒度检测主要解决了文档内容的分区查重问题,让结果更加智能和准确;联盟式相似性检测主要解决了不同数据源联合查重的问题,使得异源抄袭也无所遁形。本论文的工作对分布式相似性检测系统的推广起到了一定作用。
[1] Broder A Z, Charikar M, Frieze A M, et al. Min-wise independent permutations [J]. Journal of Computer Systems and Sciences, 2000, 60(3): 630-659
[2] Feigenblat G,Porat E,Shiftan A.Exponential time improvement for min-wise based algorithms.SODA '11 Proceedings of the Twenty-Second Annual ACM-SIAM Symposium on Discrete Algorithms,SIAM,2011.57-66
[3] Kane DM,Nelson J,Woodruff DP.An optimal algorithm for the distinct elements problem.PODS '10 Proceedings of the twenty-ninth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems.NY, USA:ACM,2010.41-52
[4] Li P,K☒nig AC.B-bit minwise hashing[A]. In Proceedings of the 19th international conference on World Wide Web, pages 671-680. ACM, 2010.
[5] Li P,K☒nig AC,Gui W.B-bit minwise hashing for estimating three-way similarities.Neural Information Processing Systems (NIPS) BC, Canada:Vancouver.2010
[6] Li P,Moore J,K☒nig AC.B-bit minwise hashing for large-scale linear SVM.Neural Information Processing Systems (NIPS) BC,Canada:Vancouver.2011
[7] Li P,K☒nig AC.Accurate Estimators for improving Minwise Hashing and b-bit Minwise Hashing.Technical Report,New York:Cornell university library,2011
[8] Li P, K☒nig AC.Theory and applications of b-bit minwise hashing [J]. Communications of the ACM, 2011, 54(8): 101-109
[9] T.Bray,J.Pao Li,CM.Sperberg-McQueen.Extensible markup language(XML) 1.0 W3C recommendation.Technical report,W3C,1998.
[10] E Hatcher.,O Gospodnetic,M McCandless.softsearch2.googlecode.com. 2004
[11] 袁鑫攀,龙军,张祖平,桂卫华.Near-duplicate document detection with improved similarity measurement [J].Journal of Central South University of Technology 中南大学学报(英文版),2012,19(8):2231☒2237
TP301.6
A
10.3969/j.issn.1000-386x.2013.01.001
