基于Spark Streaming流技术的机动车缉查布控系统设计
2016-12-15陈丽,王锐
陈 丽,王 锐
(1.广东交通职业技术学院 计算机工程学院,广东 广州 510650;2.中国移动通信集团 广东有限公司,广东 广州 510623)
基于Spark Streaming流技术的机动车缉查布控系统设计
陈 丽1,王 锐2
(1.广东交通职业技术学院 计算机工程学院,广东 广州 510650;2.中国移动通信集团 广东有限公司,广东 广州 510623)
机动车缉查布控系统以治安交通卡口系统为基础,将公路运行车辆的构成、流量分布、违章情况等信息进行汇总,实现对车辆轨迹的查询分析,从而为交通规划、管理和案件侦破等提供有效决策。由于机动车的数量增长迅猛,且机动车违规违章具有流动性、偶发性的特点,造成卡口系统录入的数据量巨大,传统的机动车缉查布控技术只能在预设条件下对数据进行查询,不能实现快速地实时分析查询。通过采用Spark Streaming技术进行大数据实时处理,实现实时显示和告警机动车违规违章活动热点,分析和预测机动车活动轨迹。
机动车缉查布控系统;交通管理;Spark Streaming;流数据处理
为进一步推进公路交通安全管理科技建设,提升动态化﹑信息化条件下的公路交通安全管控水平,2013年公安部交管局在全国组织推广了机动车缉查布控系统联网,2014年以来,各地公安交管部门加大了机动车缉查布控系统(以下简称缉查布控系统)的建设力度,缉查布控系统建设取得了很大进展[1]。但随着全国的机动车数量高速增长,以及公路建设的发展,机动车的流动性也大大增强,造成当前各省市部署的缉查布控系统积聚了海量的过车数据等信息[2]。由于数据量过大,大多数交管部门采用离线分析进行分析型监控,也就是将一个周期内(比如一天内)全部的过车数据都存储起来后再对整个数据集进行计算。这种处理方式显然延时过高,监控系统在特殊状况发生很久以后才能将结果报告给交警。由于无法及时准确的提供有效可靠的机动车违规违章信息给公安部门,刑侦抓捕工作由此变得异常艰难。此外,分析型监控任务具有时效性,例如黑名单车辆通过某个卡口时,需要系统立刻捕捉到这一行为并通知卡口附近的交警前往拦截;另外,道路流量统计的目的之一是通知交警在交通流量过大时前去疏导。离线分析的高延时使得交警无法对这些状况进行及时响应[3]。因此,急需一种新型﹑快速的分析工具,能够实时地处理机动车缉查布控的相关信息。
本文提出一种基于Spark Streaming流技术的机动车缉查布控系统设计,将机动车位置事件数据和Spark Streaming流处理技术结合,先从海量数据中筛选机动车违规违章等关键信息,然后在时间﹑空间上进行多维分析,实现准确实时地显示和告警机动车违规违章活动热点﹑以及分析机动车违规违章活动的轨迹趋势,预测下一个犯罪活动区域,成为机动车缉查布控的利器。整个系统处理过程中没有大量数据计算延迟,保证整个数据处理链在极低的延迟内完成,从而保证对某省所属所有机动车进行实时监控。
1 系统业务流程分析
在一个分布式存储﹑计算集群上建立系统,能对数据流进行快速缉查布控。其基本业务流程为:分布式消息队列接收实时数据,Spark Streaming流处理引擎按时间切片获取消息队列数据,时间窗口不断向前滑动,基于规则模型库对时间窗口内数据进行实时统计分析,发现异常进行实时告警,并将记录写入大数据分析平台;同时,大数据分析引擎对流处理结果进行快速检索,提高机动车缉查布控的准确性[4]。系统的业务流程如图1所示。
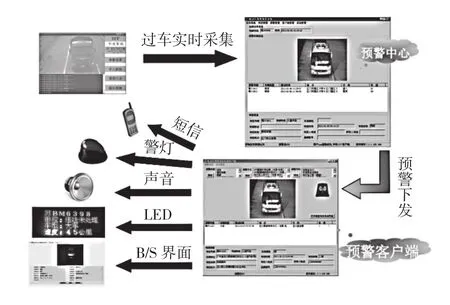
图1 机动车缉查布控系统业务流程
从图1中可看出,设计的缉查布控系统由数据采集﹑预警中心的识别﹑预警信息的分发等环节组成,通过流处理技术保证对数据的实时处理[5],通过多样的预警告知手段提供有效的预警通知。具体步骤包括:
1)分布式消息队列接收卡口过车数据;
2)实时流处理引擎(Spark Streaming)按照200 ms时间切片不断获取消息队列中卡口过车数据,充当分布式消息队列的消费者角色,对卡口过车数据进行实时比对与分析[6];
3)利用流处理实时分析结果,与离线数据分析系统相结合,进行多维度分析,统计机动车违规违章出现的规律[7];
4)根据多维分析结果,反向进一步完善规则模型库,不断修正调整规则库中阈值参数,增加新的缉查布控业务逻辑,保证缉查布控的准确性。
2 系统的主要功能
当前机动车缉查布控系统的中心功能主要指数据传输存储到分布式文件系统后,针对具体业务应用进行统计和挖掘分析。主要业务有:
1)布控管理及报警功能。平台具有设置车辆布控报警功能,并且能自动与全国被盗抢数据库及用户要求的其他数据库接口进行对接,实现布控车辆的报警信息处理,同时可根据用户不同的功能需求进行报警设置。
2)交通事件检测。系统能对车辆经过情况进行数据分析,例如对路段堵塞﹑车流量异常减少/增多﹑不同区域不同车辆不应出现的同号牌车辆等情况进行提示报警(套牌车辆识别)等检测分析。
3)交通流统计分析功能。能够按车道进行流量统计,按行驶方向进行流量统计﹑车速统计,实现统计断面/车道流量﹑流率(每小时每车道车辆数)﹑平均速度﹑车型(可分为五类车型)﹑时间/空间占有率﹑车头时距﹑服务水平(可分为六级)﹑密度(单位长度上的车辆数)﹑空间平均速度(单位长度上的车辆平均速度)等统计数据。
4)区间测速功能。系统能够对任意两个卡口点进行区间测速的配置,实现对通过两个相邻卡口的车辆进行区间测速的判断,输出区间超速的违法信息。
5)道路旅行时间分析。通过对设有卡口的路线提供实时的最接近的旅行时间,用以发布道路交通状态,为节假日出行者提供参考。
6)报警管理。系统能够实现与机动车登记系统自动比对﹑自动筛选报废﹑假牌﹑未年检等重点管控车辆,形成卡口网状布控报警模型。实现当车辆通过一个布控点时,如果没有及时拦截,还可以在下一个布控点及时拦截,这样将布控和报警点形成一个网状模型,实现关联报警点。
7)海量数据的分析处理。基于超级计算等并行处理技术,实现海量数据的道路交通状态判别,由相关的数据融合处理算法,生成交通出行信息,为交通管者提高管理水平提供借鉴,为交通出行者提供实时﹑有效的出行信息。
8)快速模糊搜索涉案车辆。在车牌号码不完整或无车牌情况下,根据车牌号某一字段或车辆特征字段,实现车辆的模糊检索,得到车辆图片集合,缩小检索范围,提高了办案效率。
9)公共车辆的监控管理。实现对BRT﹑普通公交﹑班车﹑出租车等公共交通车辆的针对性监控管理,建立单独的监控管理模块。
10)特殊车辆的运行轨迹分析。实现对长途客运车辆﹑危险化学品运载车辆﹑校车等车辆运行轨迹分析,提取其运行特征,为实施有针对性管理提供依据。
3 关键技术及其实现
3.1 系统整体架构说明
系统涉及的核心组件包括Kafka分布式消息总线﹑Spark Streaming实时流式计算﹑HBase/HDFS﹑Map/Reduce分布式计算﹑应用服务引擎等,如图2所示。
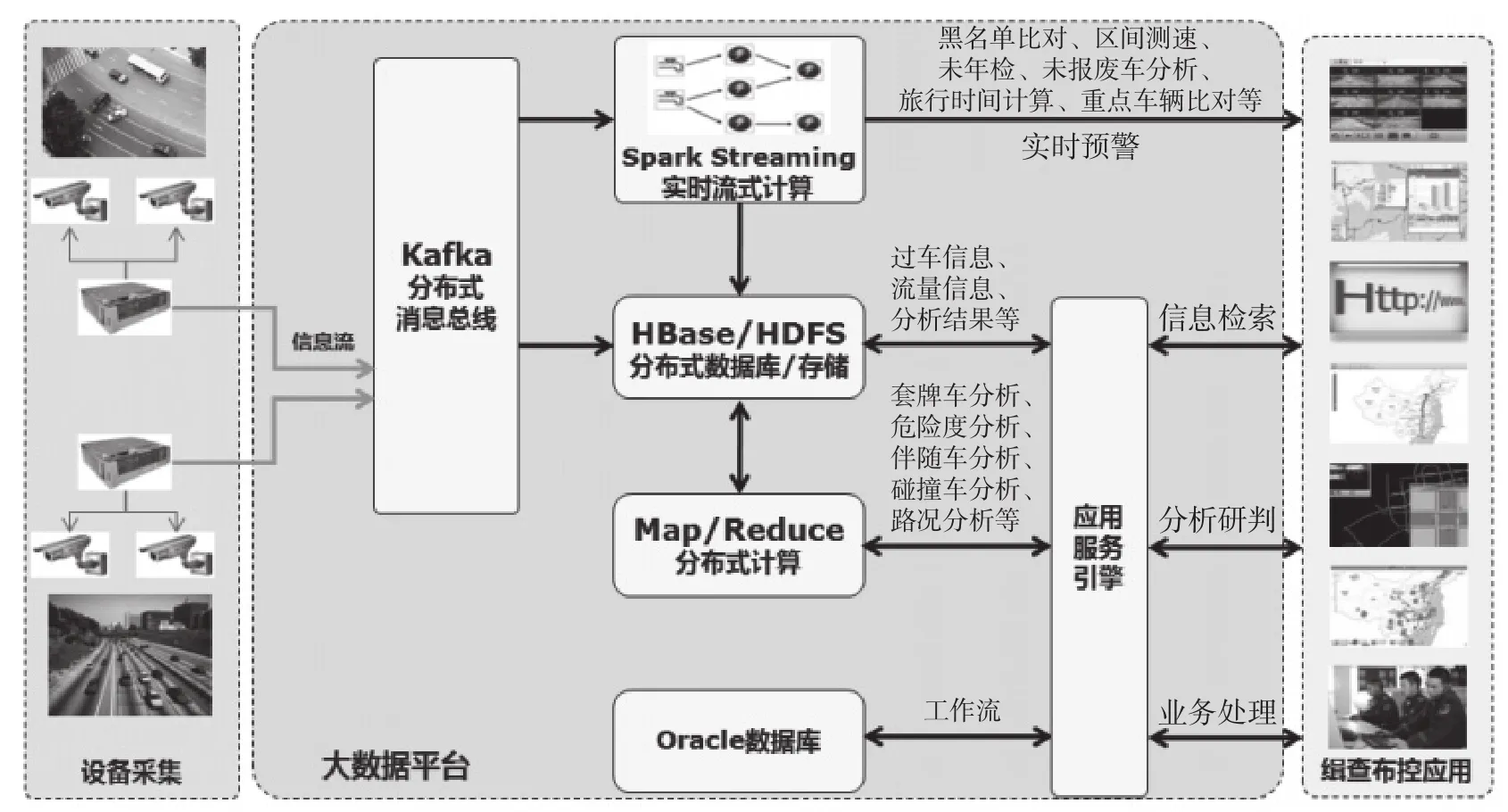
图2 基于Spark Streaming流技术的机动车缉查布控系统架构图
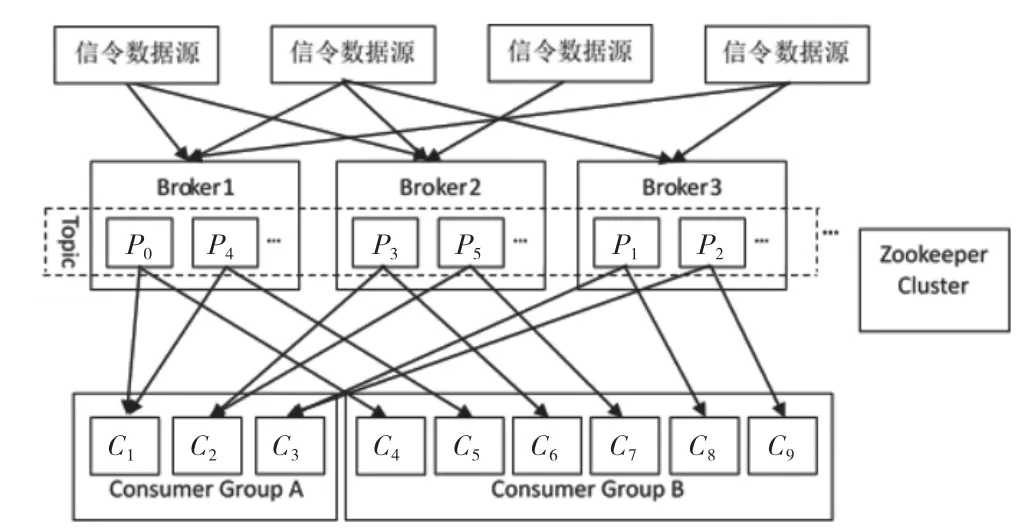
图3 分布式消息队列数据流图
3.2 分布式消息队列
分布式消息队列是基于Zookeeper协调管理的,将完整的卡口过车数据发送至分布式消息队列。流处理平台根据卡口过车产生数据量速率,在分布式消息队列中将卡口过车数据近乎均匀地分散到各个服务器中多个Partition中。流处理引擎Spark Streaming在分布式集群中开启多个并发数据流消费线程,组成针对于不同业务规则的多个消费组Consumer Group。在每个Consumer Group中,Partition个数是数据流消费总线程数的倍数,每个计算线程消费相同数目的卡口过车数据Partition,以达到集群负载均衡的目的。
系统设计中,分布式消息队列的数据流图如图3所示,多个卡口过车数据源将数据写入分布式消息队列集群的Topic中,P0~P6等数据分区Partition被分散在集群的各个节点中,Spark Streaming作为数据消费者针对不同的业务规则建立不同的消费组,在消费组Consumer Group A中,每个消费线程处理两个Partition的实时数据,在消费组Consumer Group B中,每个消费线程处理一个Partition的实时数据。所有的生产者(Broker)以及消费信息被记录在Zookeeper集群中。
3.3 Spark streaming流式实时分布式计算
3.3.1 Spark Streaming介绍[8]
Spark Streaming是建立在Spark(Berkeley的交互式实时计算系统)上的实时计算框架,Spark Streaming的优势在于:能运行在100+的结点上,并达到秒级延迟。Spark Streaming的基本原理是将输入数据流以时间片(秒级)为单位进行拆分,然后以类似批处理的方式处理每个时间片数据。
Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成多段数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加,或者存储到外部设备。
Spark Streaming的优势主要表现在容错性﹑实时性﹑可扩展性。
1)容错性。表现在两个方面:一是使用HDFS作为文件系统。HDFS的备份机制保证了数据不易丢失;二是将采集的数据保存到2个节点上,防止数据在源头丢失。
2)实时性。主要涉及流式处理框架的应用场景。Spark Streaming将流式计算分解成多个Spark Job,对于每一段数据的处理都会经过Spark DAG分解,以及Spark的任务集的调度过程。对于目前版本的Spark是 Streaming而言,其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),所以Spark Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
3)扩展性与吞吐量。表现在Spark的节点数量上。Spark目前在EC2上已能够线性扩展到100个节点(每个节点4 Core),可以以数秒的延迟处理6 GB/s的数据量(60 M records/s),其吞吐量也比流行的Storm高2~5倍。在Berkeley利用Grep所做的测试中,Spark Streaming中的每个节点的吞吐量是670 k records/s,而Storm是115 k records/s。
3.3.2 Spark streaming的工作流
Spark Streaming接受到实时数据后,给数据分批次,然后传给Spark Engine处理最后生成该批次的结果。执行流程如图4所示。
1)卡口过车数据按照指定的队列方式将卡口过车数据分散存储于分布式消息队列集群。消息队列的相关术语说明如表1所示。

图4 Spark Streaming工作流

表1 消息队列术语及说明
2)Spark Streaming把卡口过车数据按照时间切片Δt(200 ms)为单位进行切分,对于Vehicle_Info Topic来说,每个时间切片(如200 ms)中的数据为该时间段内完整的卡口过车数据,Topic的信息结构如表2所示。
3)将每一个时间切片的卡口过车数据进行实时的批处理,本质上本流处理平台是基于小作业的高速低延时批处理分析,优势在于批处理在状态维护﹑不丢不重的精准完整性语意完成上更加容易。因为一致性状态的维护﹑完全不丢失不重复需要的元信息维护代价都非常大,传统的流
处理系统因为面向单条数据,在出现错误恢复时无力完成完全的精准恢复,从而造成数据或者状态的丢失。业务应用逻辑以DAG(有向无环图)形式的服务常驻在集群内存中,生产系统的消息通过实时消息队列进入计算集群,在集群内以Pipeline方式被依次处理。
4)卡口过车数据经过流处理,根据获得的异常车牌地理位置信息,获得异常车牌和驾驶证的活动范围以及移动趋势,实时输出结果数据,触发告警,为卡口过车下一路口拦截以及缉查布控应对提供可靠实时保障。
这样,流处理系统通过在软件层面上借助冗余﹑外部存储等方式实现容错,可以避免数台服务器故障﹑网络突发阻塞等问题造成的数据丢失问题。通过定义弹性数据集RDD来实现容错,RDD是一种数据结构的抽象,它封装了计算和数据依赖,数据可以依赖于外部数据或者其他RDD, RDD本身不拥有数据集,它只记录数据衍变关系的谱系,通过这种谱系实现数据的复杂计算变换,在发生错误后通过追溯谱系重新计算完成容错,如果计算的衍变谱系比较复杂,系统支持checkpoint来避免高代价的重计算发生。

表2 Topic信息结构表
4 系统使用场景分析
本节讨论系统在车辆套牌检测场景中的使用。系统首先将某省所有卡口信息和车牌对应信息以及驾驶证对应信息的码表预加载在集群各个服务器内存中。其次分多个消费组获取时间切片中卡口过车数据,如表2所示,包括开始时间,结束时间,卡口编号等,将时间切片Δt内卡口过车数据加载进入内存。
然后对消费组Consumer Group A中加载在内存中的卡口过车数据,设置时间窗口,时间窗口由时间切片组成(如设置时间切片为200 ms,时间窗口为20 s,那么时间窗口内有100个时间切片的数据)并不断向前滑动(滑动时间跨度为单位时间切片Δt)。根据当前卡口字段统计各个卡口在当前时间窗口内机动车同一车牌数量并记录。比对前后两个时间窗口内各个卡口的机动车的过车时间Δt和卡口的距离Δl。如公式(1)所示:

当Δv超过设定阈值例如机动车最大速度200 km/h,将该机动车列为疑似套牌车辆,并触发告警记录。
最后对消费组Consumer Group B中加载在内存中的卡口过车数据,实时比对其车牌号字段,以及驾驶证字段。
一旦发现机动车车牌字段代码不在某省年检过的车牌数据库码表中,那么将该条卡口过车数据中当前机动车的车牌字段作为未年检车辆出现进行记录与告警。同时比对卡口过车驾驶证字段正常的驾驶证分数,与预加载在内存中的驾驶证数据库数据进行比对,如不能对应,则将该条卡口过车数据中当前驾驶证字段作为异常驾驶证出现点进行记录与告警。
5 结语
本文研究和分析了当前机动车缉查布控的业务需求﹑机动车缉查布控系统的功能和不足,并在此基础上提出了一种基于Spark Streaming流技术的机动车缉查布控系统。本文根据Spark Streaming的技术特点,设计和实现了分布式消息队列系统﹑实时流处理系统﹑数据分析系统以及Spark Streaming与其他组件的协同工作框架。系统能有效地完成了机动车套牌分析﹑过往车辆统计﹑重点车辆比对等功能。
[1] 张森,翁育峰,方艾芬. 基于卡口的大范围机动车缉查布控技术研究:以广东省为例. //中国智能交通协会.第八届中国智能交通年会优秀论文集:智能交通与安全[C].中国智能交通协会:2013:7.
[2] 徐晓东,孔晨晨,席正祺. 大数据云计算技术在全国机动车缉查布控系统中的应用[J]. 中国公共安全(学术版),2015,38(1):87-91.
[3] 缪新顿,莫子兴. HBase在机动车缉查布控系统中的应用[J]. 中国交通信息化,2014(5):123-125.
[4] KOBIELUS A. The role of stream computing in big data architectures[J/OL].IBM Big Data & Analytics Hub,2013. http://ibmdatamag.com/2013/01/ the-role-of-stream-computing-in-big-dataarchitectures/.
[5] 王先文,陈锋,程智等. 基于偏斜t混合模型的流式数据自动聚类方法研究[J]. 电子学报,2014,42(12):2527-2535.
[6] 王成章,林学练,谭静芳. 流式处理系统的动态数据分配技术[J]. 计算机工程与科学,2014,36(10):1846-1853.
[7] 孙大为,张广艳,郑纬民. 大数据流式计算:关键技术及系统实例[J].软件学报,2014(4):839-862.
[8] SPARK A. lightning-fast cluster computing[J/OL]. SPARK,2013. http://spark-project.org/.
Design of Motor Vehicles Monitoring and Controlling System Based on Spark Streaming Technology
CHEN Li1,WANG Rui2
(1. Department of Computer Engineering,Guangdong Communication Polytechnic,Guangzhou Guangdong 510650,China; 2. China Mobile Group Guangdong Co.,Ltd.,Guangzhou Guangdong 510623,China)
Based on the Bayonet monitoring system,motor vehicles monitoring and controlling system can offer statistical data of traffic composition,traffic volume and traffic offence,and realize the query and analysis of vehicle trajectory,which provides the support for transportation planning,management and case detection. As the number of vehicles is increasing rapidly,and traffic offence is often mobile and accidental,the Integrated Transport Information System has to process huge data. So,traditional vehicles monitoring and controlling techniques can just query data under a preset condition,and can not realize real-time analysis and data tracking. With the help of Spark Streaming technique,realtime processing of big data is realized,and the real-time display and warning of traffic offence is possible,as well as the analysis and prediction of vehicle trajectory.
Motor vehicles monitoring and control system; traffic management; Spark Streaming; stream data processing
TP3
A
1672-6138(2016)04-0010-06
10.3969/j.issn.1672-6138.2016.04.003
[责任编辑:吴卓]
2016-09-27
陈丽(1978—),女,湖南邵东人,讲师,硕士,研究方向:大数据技术及应用﹑信息系统管理。
