姿态图像缺失情况下的SAR目标识别
2016-12-06刘宏伟王英华
丁 军,刘宏伟,陈 渤,王英华
(西安电子科技大学雷达信号处理国家重点实验室,陕西西安 710071)
姿态图像缺失情况下的SAR目标识别
丁 军,刘宏伟,陈 渤,王英华
(西安电子科技大学雷达信号处理国家重点实验室,陕西西安 710071)
针对目标姿态图像缺失的情况,提出通过姿态图像合成的方式增加训练集的姿态覆盖程度,并将扩充后的图像也用于训练目标分类器.受稀疏表示模型的启发,建立了一种合成孔径雷达图像姿态合成模型.该模型根据少量已知姿态的图像,线性组合出缺失姿态下的近似图像.在运动和静止目标获取与识别数据集上的实验表明,通过合成缺失姿态下图像的方法可有效提升目标识别的精度,特别是在训练数据集中姿态缺失严重时,文中方法提升尤为明显.
合成孔径雷达图像目标识别;姿态图像缺失;稀疏表示
合成孔径雷达(Synthetic Aperture Radar,SAR)图像目标识别技术在对地观测和国防安全等方面具有非常重要的前景.过去几年研究者们完成了大量的工作[1-4,7-9],例如文献[1]采用支持向量机(Support Vector Machine,SVM)作为分类器进行SAR目标识别.文献[2]通过研究预处理方法提高SAR目标识别精度.文献[3]利用多分类器融合的方法改善识别性能.文献[4]通过全局属性散射中心模型提取散射中心特征进行SAR目标识别.但是,SAR目标图像具有姿态敏感的特点,即同一个目标在不同的方位角下,SAR成像结果会有较大的差异.因此,很难采用给定方位角下的图像或者模板识别不同方位角下的同一目标.这也要求训练数据集尽可能包含目标全部方位角下的图像.然而,对于非合作目标的识别问题,这一要求通常难以满足.于是研究如何在训练数据存在目标姿态缺失情况下,仍然保持较好的识别性能是SAR图像目标识别中需要解决的一个重要问题.
近年来,稀疏表示方法作为一种有效的信号分析工具已被应用于人脸识别[5]和目标检测[6]等领域.在SAR图像目标识别方面,文献[7]利用非负稀疏表示模型进行SAR目标识别.文献[8]采用阴影与目标联合稀疏表示模型进行SAR目标识别.文献[9]对多视角下SAR图像进行联合稀疏表示.以上方法的共同点是采用训练样本构成基字典,利用测试样本在字典上的不同稀疏表示系数来确定目标型号.此类方法的隐含假设,使同一目标的测试图像可由少量相同类别的训练图像的线性组合更好地重构.
在上述方法的启发下,笔者提出一种用于SAR图像目标识别的姿态图像合成方法.该方法通过少量输入图像线性组合出缺失方位角下的近似图像,以解决识别所需训练集中目标姿态缺失的问题.在运动与静止目标的获取与识别(Moving and Stationary Target Acquisition and Recognition,MSTAR)数据集上的实验表明,相比仅使用姿态缺失训练集直接训练分类器的方法,采用姿态图像合成的方法具有更好的识别性能,并且与采用全部姿态图像进行训练的识别精度相差不大.
1 SAR 图像姿态合成
1.1稀疏表示模型
稀疏表示的目的是将观测信号分解为给定字典中少数信号(又称为原子)的线性组合,其模型可表示为

其中,y为n维输入信号,y∈Rn×1;D为字典,D∈Rn×m,字典中列向量称为原子;K为稀疏度常量;α为稀疏表示系数,表示向量的零范数,即非零值元素的个数.也就是说,输入信号y可使用字典中的少量原子的线性组合进行重构.图1给出了一幅方位角为152.492°的BMP2目标图像在其他BMP2图像字典上的稀疏表示系数.由图1可以看出,该幅目标图像可使用与其方位角度非常接近的其他BMP2图像的线性组合进行近似重构.且与其方位角度越接近,表示系数的值也越高,说明如果使用少量其他方位角度下的图像来对给定方位角的图像进行重构,则最优选择是使用与该图像对应的方位角度相差不大的图像,按照方位角度远近关系进行线性组合.由此,引出了下节要讨论的姿态图像合成模型.

图1 一幅BMP2目标图像在其他BMP2图像字典上的稀疏表示系数
1.2SAR图像姿态合成模型
姿态图像合成问题是指通过已知姿态下的图像数据合成指定姿态下的图像数据.该问题描述如下:给定目标t在不同方位角下的N幅SAR图像集合I={Iθ1,Iθ2,…,IθN},其中, θi为第i幅图像对应的方位角度,θi∈[0°,360°);姿态图像合成的目标是根据图像集合I计算指定方位角θ*下的近似图像Iθ*.由于SAR图像由雷达系统参数、成像目标自身的结构及散射特性、目标相对雷达视线所处的姿态、相干斑噪声和杂波等多方面因素决定的.因而,很难找到一种统一的模型进行精确的姿态图像合成.但是对于SAR目标识别应用,只要求合成出的姿态图像保留目标可供识别的特征即可.因此,可通过将配准后的多幅图像线性组合出相近姿态下的图像.于是,文中提出如下姿态图形合成模型:

由模型式(2)计算Iθ*,需要选定图像配准操作、从基图像中选择原子和确定合成系数的大小.首先,图像配准操作的目的是使得处理后的图像更加符合线性组合模型.因此,可选择先对图像进行重心中心化处理;然后,再根据中心旋转各自对应的方位角度,使得处理后的目标图像具有相同的朝向.可定义距离的表达式为

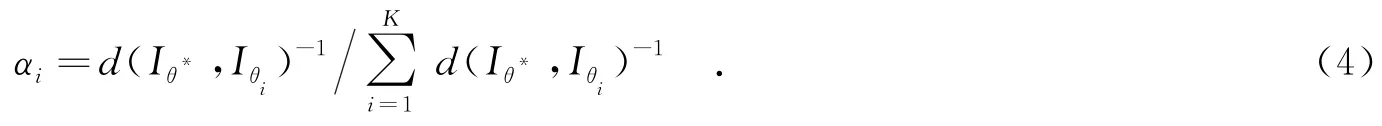
最终,得到的姿态图像合成算法如算法1.
算法1 姿态图像合成算法
输入:已知图像集I及对应的方位角度θ,输出图像的方位角θ*,稀疏度常量K.
输出:合成的图像Isyn.
②采用贪婪的策略选取K幅与θ*距离最小的图像,并根据式(4)计算合成系数{α1, α2,…,αK}.
图2给出了由一幅方位角为161.492°的BMP2图像与另一幅方位角为174.492°的BMP2图像合成出方位角示意图.由图2可以看出,合成得到的图像(图2(c))与方位角166.279°的图像(图2(d))相比具有较好的相似性,因此,替代真实方位角下图像作为分类器训练数据是可行的.

图2 一幅BMP2目标姿态图像合成示意图
2 实验与讨论
2.1实验数据集
为验证文中提出的姿态图像合成方法在SAR目标识别中的有效性,实验选用的是MSTAR公共数据集.该数据集包含X波段0.3 m×0.3 m分辨率的多个地面目标的SAR图像.全部实验使用线性支撑向量机(Linear Support Vector Machine,LSVM)作为特征分类器.文中使用3类目标识别问题和10类目标识别问题作为评估实验设定.每类目标训练图像大约为230幅,覆盖360°方位角范围,具体训练和测试的样本数目见表1,其中表1的上半部分即为3类识别问题所用的数据设置.为节约计算开销,先将原始128×128大小的目标图像从中心处切出大小为64×64的图像块.除了对图像块进行能量归一化外,实验中没有使用任何其他预处理方法以减少对姿态图像合成评估结果的影响.
为仿真姿态图像缺失的情况,实验时首先从每类的训练数据中随机抽取出N幅图像作为基图像.然后随机从[0°,360°)范围均匀随机生成M个方位角度作为需要合成的方位角度.接着使用算法1从每类基图像中合成出M幅图像.最后将合成图像与基图像合并为训练数据集训练SVM分类器.实验中将基图像加上合成图像进行训练的方法称为“姿态合成扩充”方法;而仅采用基图像来训练的方法称为“基图像”方法;使用全部训练数据的方法称为“全部真实姿态”方法.实验将分别讨论识别精度与每类选取基本图像个数N、每类合成图像个数M以及稀疏度常量K之间的变化关系.

表1 10类识别问题所用数据设置
2.2每类基图像个数变化
为解识别精度随每类抽取的基图像个数变化的情况,实验中固定合成数目M=500,稀疏度K=2.图3给出了实验结果.由图3可以看到,无论是3类识别问题还是10类识别问题,使用姿态合成扩充后的数据进行训练都可以带来识别性能的提升(相对于仅使用基图像的情况).虽然识别性能随着选择的基图像个数减小而逐步降低,但使用合成图像训练带来的性能增益反而是更大(图3中基图像个数取30和60时,提升大约3%~8%).图3中虚线表示采用全部训练数据时候的识别精度,可以看到,在每类仅使用150幅基图像时与全部训练数据(每类230幅左右)在性能上相差不大.

图3 识别性能随基图像个数变化的情况
2.3每类合成个数变化
图4给出了每类基图像个数N=30,稀疏度K=2时的实验结果.对于识别精度随合成图像个数的变化情况,3类识别精度和10类识别精度基本随着合成图像数目的增加而增加.但是在每类合成图像数目设置太大,如图4中3类识别问题在M=600时,有可能造成一些负面的影响,使得识别性能降低.这是由于SAR图像姿态合成模型只是对缺失姿态图像的一种近似,因此过多地依赖合成图像进行训练反而会造成性能损失.

图4 识别性能随每类合成个数变化的情况
2.4稀疏度变化
识别性能随稀疏度变化的情况如图5所示.实验中固定每类基图像个数N=30,每类合成个数M=500.对于3类和10类这两种识别问题,稀疏度的变化基本不会带来明确的影响.虽然参与合成的原子个数增多了,但是由于在式(4)中计算的合成系数与距离的倒数成正比,也就使得选择的角度差异越大的图像对应的合成系数值越小,因此,起主要作用的还是与目标方位角度相近的那些基图像数据.

图5 识别性能随稀疏度变化的情况
3 结束语
笔者提出的SAR图像姿态合成模型和算法为解决姿态缺失情况下的SAR图像目标识别提供了一种思路.在MSTAR数据集上的实验结果显示,相比仅使用姿态缺失训练集直接训练分类器的方法,采用姿态图像合成的方法可以获得识别性能增益,从而验证了该方法的有效性.文中实验采用线性SVM作为分类器,在识别性能上还具有很大提升空间,这也是后续需要改进和研究的方向.
[1]ZHAO Q,PRINCIPE J C.Support Vector Machine for SAR Automatic Target Recognition[J].IEEE Transactions on Aerospace and Electronic Systems,2001,37(2):643-654.
[2]胡利平,刘宏伟,吴顺君.一种SAR图像目标预处理方法[J].西安电子科技大学学报,2007,34(5):733-737. HU Liping,LIU Hongwei,WU Shunjun.Novel Pre-processing Method for SAR Image Based on Automatic Target Recognition[J].Journal of Xidian University,2007,34(5):733-737.
[3]SUN Y,LIU Z,LI J.Adaptive Boosting for SAR Automatic Target Recognition[J].IEEE Transactions on Aerospace and Electronic Systems,2007,43(1):112-125.
[4]ZHOU J X,SHI Z G,CHENG X,et al.Automatic Target Recognition of SAR Images Based on Global Scattering Center Model[J].IEEE Transactions on Geoscience and Remote Sensing,2011,49(10):3713-3729.
[5]WRIGHT J,YANG A Y,GANESH A,et al.Robust Face Recognition via Sparse Representation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):210-227.
[6]张晓伟,李明,左磊.一种利用稀疏表示的距离扩展目标检测新方法[J].西安电子科技大学学报,2014,41(3): 20-25. ZHANG Xiaowei,LI Ming,ZUO Lei.New Detection Method for Extended Targets Using Sparse Representation[J]. Journal of Xidian University,2014,41(3):20-25.
[7]丁军,刘宏伟,王英华.基于非负稀疏表示的SAR图像目标识别方法[J].电子与信息学报,2014,36(9):2194-2200. DING Jun,LIU Hongwei,WANG Yinghua.SAR Image Target Recognition Based on Non-negative Sparse Representation[J].Journal of Electronics&Information Technology,2014,36(9):2194-2200.
[8]丁军,刘宏伟,王英华,等.一种联合阴影和目标区域图像的SAR目标识别方法[J].电子与信息学报,2015,37(3): 594-600. DING Jun,LIU Hongwei,WANG Yinghua,et al.SAR Target Recognition by Combining Images of the Shadow Region and Target Region[J].Journal of Electronics&Information Technology,2015,37(3):594-600.
[9]ZHANG H C,NASRABADIC N M,ZHANG Y N,et al.Multi-view Automatic Target Recognition Using Joint Sparse Representation[J].IEEE Transactions on Aerospace and Electronic Systems,2012,48(3):2481-2497.
(编辑:齐淑娟)
SAR image target recognition in lack of pose images
DING Jun,LIU Hongwei,CHEN Bo,WANG Yinghua
(National Key Lab.of Radar Signal Processing,Xidian Univ.,Xi’an 710071,China)
The performance of synthetic aperture radar(SAR)image target recognition depends on the diversity of pose images in the training set.The problem of lack of pose images is considered,and the method of training data augmented with the synthesized pose images is introduced to train the classifier for target identification. Inspired by the sparse representation model,the model for synthesizing pose images is also developed,which approximately construct the missing pose image by linearly combining several images available.Experimental results on the moving and stationary target acquisition and recognition(MSTAR)dataset show that the proposed method of pose images synthesis can increase the recognition accuracy effectively.In particular,significant improvement can be obtained in the case of serious lack of pose images.
synthetic aperture radar(SAR)image target recognition;lack of pose images; sparse representation
TP957.51
A
1001-2400(2016)04-0005-05
10.3969/j.issn.1001-2400.2016.04.002
2015-04-03 网络出版时间:2015-10-21
国家自然科学基金资助项目(61372132,61201292);新世纪优秀人才支持计划资助项目(NCET-13-0945);青年千人计划资助项目
丁 军(1982-),男,西安电子科技大学博士研究生,E-mail:dingjun410@gmail.com.
陈 渤(1979-),男,教授,E-mail:bchen@mail.xidian.edu.cn
网络出版地址:http://www.cnki.net/kcms/detail/61.1076.TN.20151021.1046.004.html
