一种基于关联度的Skyline多目标优化文献检索方法设计与测试
2016-12-05王春梅
王 春 梅
(吉林农业大学, 吉林 长春 130000)
一种基于关联度的Skyline多目标优化文献检索方法设计与测试
王 春 梅
(吉林农业大学, 吉林 长春 130000)

查询与结果排序是文献检索系统的两个重要指标,直接影响着用户对文献资源的利用率。针对目前文献检索排序策略上存在的不足, 从用户检索文献的需求出发,在Skyline算法的基础上提出一种基于Skyline关联度的多目标优化文献检索排序方法,将文献之间的关联程度作为查询算法的主要条件进行检索和排序,从而将有价值的资源挖掘出来。最后, 基于CNKI数据库平台对相关文献进行检索,并应用所设计模型对检索结果进行重新排序。结果表明,该方法可有效优化排序结果,将关联度较高的文献信息挖掘出来,满足用户对期望资源的检索要求,提高了文献的利用率,具有一定的参考价值。
文献检索; Skyline查询; 关联度; 优化
0 引 言
信息技术的发展,用户可以足不出户地通过互联网查询所需资料,尤其对数字图书馆电子文献的需求,更是与日俱增。人们可以借助于文献检索工具,方便快捷地找到自己所需信息。而就目前的基于关键字的检索现状来看,常出现返回不相关的文献信息、文献不按规则排序、检索结果关联度不高等弊端[1-2],随着用户对检索需求的日益深化,暴露出的局限性也越来越明显。基于此,寻求一种高效的文献检索工具成为研究人员关注的重点。文献[3]通过具有语义特征的本体概念对文献集进行描述,提出一种根据上下文评价的文献检索方法,取得了很好的应用效果。文献[4]在Lucenel的基础上,设计了一种基于语义的文献检索系统,该查询模块与Lucene契合度高,检索效果好。文献[5]针对文献检索过程中的分类问题,定义了特征提取的概念,提出一种基于支持向量机的内嵌空间特征选择查询与排序方法。文献[6]针对文献检索中存在的信息冗余或信息缺失等问题,采用统一数字化标度方法,构建了一种基于检索项匹配的文献检索模型,使用户直观的了解文献的等级分布以及文献之间的相互联系,缩短了检索时间,提高了文献利用效率。
在现有成果的基础上,本文将文献检索后的排序策略作为主要的研究内容,设计了一种基于关联度的Skyline多目标优化文献检索方法,将文献之间的关联度作为排序的重要衡量标准,从而使用户得到一个更加满意的查询结果,目的是为了加快查询速度,提高文献的利用效率。
1 文献利用率影响因素分析
衡量文献检索利用率的两个重要指标是检索速度和排序策略,有效的排序方式是保证检索结果被用户有效利用的前提。文献利用率主要受筛选机制和用户检索习惯的影响。
1.1 筛选机制对文献利用率的影响
信息源多,无用信息量大是目前文献检索存在的普遍问题。虽然搜索引擎功能日益强大,但由于信息资源急剧增加,导致用户检索结果数量庞大。譬如在中国学术期刊网络出版总库(CNKI)中以“检索”为关键词进行查询,输出的结果超过22万条。各信息良莠不齐,如果没有一个合理的筛选机制及有效的检索结果处理手段,会使用户面对大量的无用信息,无从下手,而最后无法找到自己真正想要的文献,导致文献利用率大打折扣。
1.2 检索习惯对文献利用率的影响
一般的数据库查询系统都包括初级检索和高级检索两种途径,但多数用户都习惯于使用初级检索方式,而很少使用高级检索。这使检索结果虽然包含了带有某关键词的所有数据,但不能真正按照用户的意愿处理,这种情况下作者只能一页一页的去查看结果,浪费大量时间,也很难获得满意的信息。
2 Skyline算法研究
Skyline计算是一个典型的多目标优化的问题,作为数据挖掘技术的重要分支,Skyline算法在多标准决策、数据挖掘以及网络作业调度等领域应用非常广泛,尤其是在数据的查询计算方面更具有十分重要的应用前景[7-8]。Skyline查询的主要目标是从一个潜在的、海量的数据中找出用户感兴趣的、相对重要的点,过滤掉一些不需要的点,从而为进一步的数据处理工作打下基础,减少不必要的资源浪费。
2.1 算法分析
设数据空间Y包含了n个数据集,表示为:Y=D1×D2×…×Dn。若数据集Di(1≤i≤n)又包含了j个数据,即(d1,d2, …,dj)∈Di,dj表示数据Di的第j维值,定义如下[9-10]:对于Di中任意两个数据P和Q,若对象P在所有维度上的属性值都不比对象Q差,并且至少在某一维上的属性值优于对象Q,则称P支配Q,记作:PQ。根据以上语义,实现Skyline查询的嵌套SQL语句可表示为:
SELECT...FROM...WHERE
GROUP BY...HAVING...
SKYLINE OF [DISTINCT]d1[MIN|MAX|DIFF], …, dj[MIN|MAX|DIFF]
2.2 算法实例
Skyline算法实例[11]:要去海滩游玩,想找一个既便宜又靠近海滩的宾馆。而实际上,这存在一个矛盾,距离海边越近的酒店通常价钱越高,而价钱相对便宜的酒店一般距离海边很远,它们的关系如表1所示。
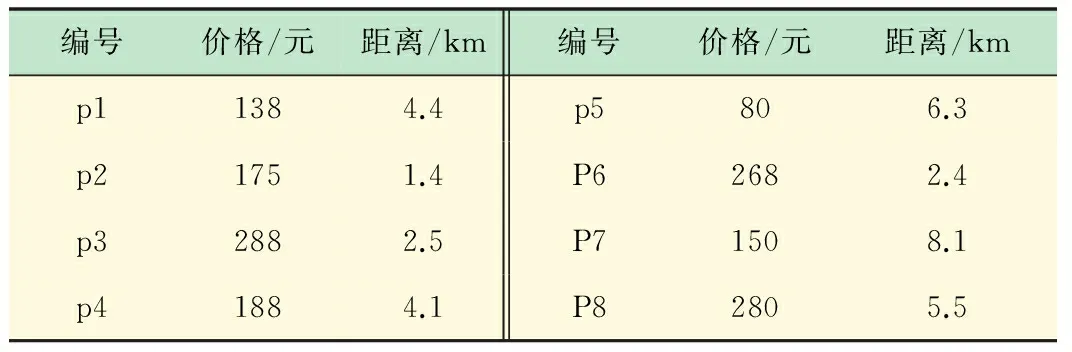
表1 宾馆价格与距海边距离关系
这时我们就希望有一个旅馆集合,能为我们的选择提供帮助,我们称这个集合为Skyline,每个可以选择的宾馆为SP(Skyline Point)点。如图1所示,对于旅游者来说,很明显折线上p1,p2,p5三个SP点是比较偏好的选择,其他非SP点可以不做考虑,因为总可以在折线上找到一个SP点,或者在价格,或者在距离上优于非SP点。
2.3 Skyline文献检索排序模型
通常用户期望将最匹配的检索结果排在最前面,可见文献排序策略的优劣,直接影响用户的检索效率[12]。
Skyline查询是一种典型的多目标优化查询方法,根据其查询原理,研究人员提出了基于Skyline的迭代排序模型:假设用户对检索结果集的期望具有多维性,期望维度大于等于1。对多维文献集M进行Skyline查询操作,得到Skyline文献集S1,然后对剩余的子文献集N=M-S1再进行Skyline查询操作,得到Skyline文献集S2,……,依此类推,不断迭代,直到剩余文献集为空,最后按检索的先后顺序将得到的文献集排列,最后抒结果返回给用户,其模型如图2所示[13-15]。
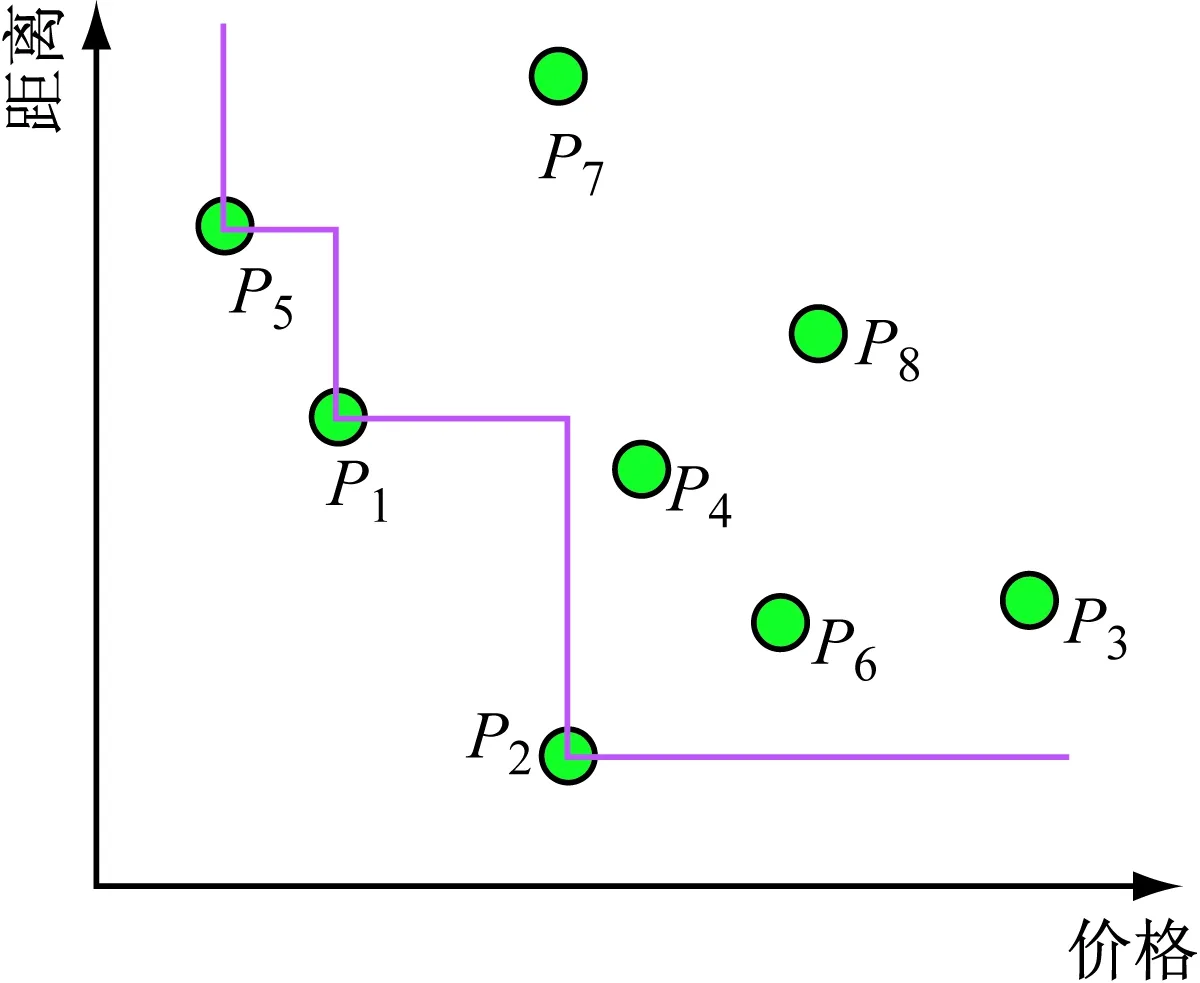
图1 SP点集合示意图
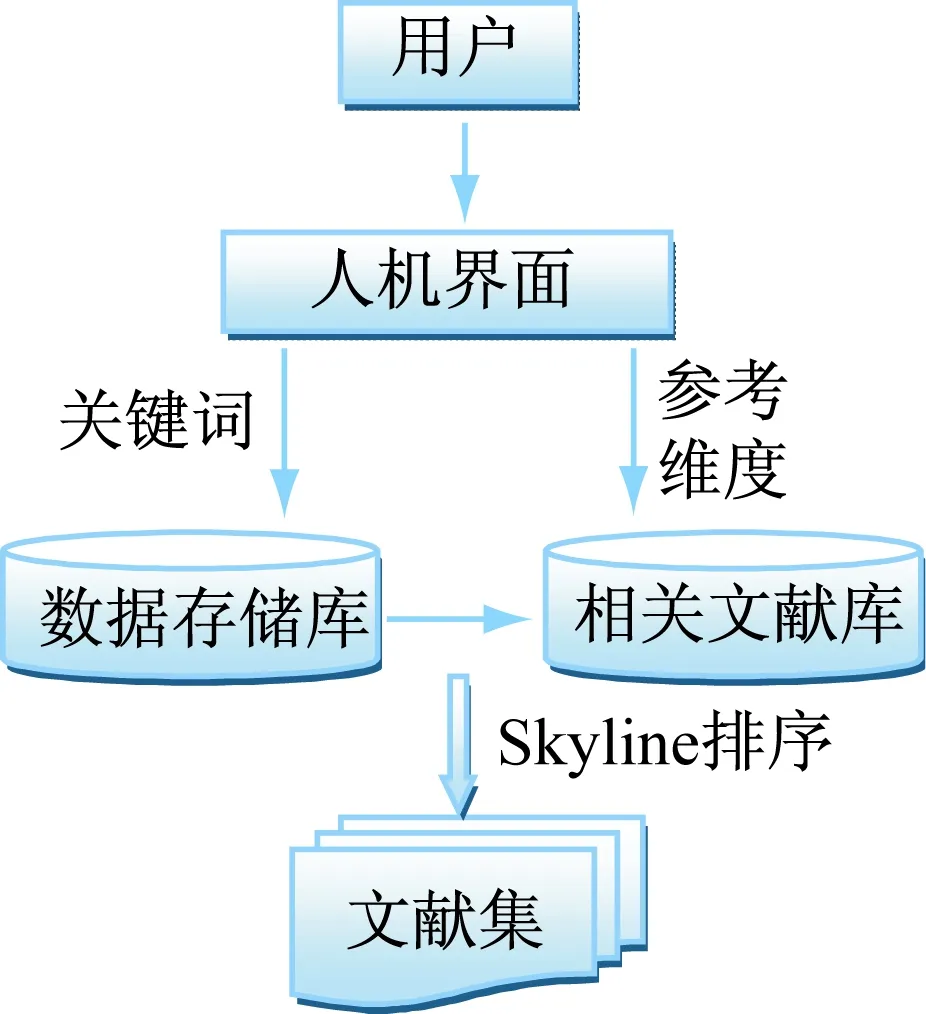
图2 Skyline查询模型
与传统的文献排序方案相比,Skyline迭代排序方法可以从不同维度进行多目标优化查询,并均衡各维度之间的关系进行合理排序。但是由于没有考虑文献之间的关联作用,导致一些本来满足作者要求的文献被Skyline迭代算法排在很靠后的位置,从而被忽视。
3 基于关联度的Skyline多目标优化文献检索模型设计
学者们撰写论文或著作,一般会对已有的成果进行引用。同时,一个领域的成果在某些字段或内容上也有很多相似之处,从而使各个文献之间建立起一种关联,反映了文献之间的相关性。根据文献的关联度往往可以进一步获得更有参考价值的文献资料。基于此,本文将文献之间的关联度作为文献查询时的衡量指标,设计了一种基于关联度的Skyline查询模型,如图3所示。模型的主要功能如下:
首先在查询模块中通过关键字和不同参考维度进行检索,过滤掉大部分不相关的文献,以提高整体检索效率;将查询得到的文献库在排序模块中进行Skyline查询,得到Skyline文献集和非Skyline文献集,通过计算相关度将有价值的非Skyline文献挖掘出来,并与Skyline文献进一步排序,从而使用户得到满意的检索结果。
4 测试论证
为验证基于关联度的Skyline文献检索与排序模型的有效性,采用该模型进行检索论证,并与传统文献检索排序方法进行对比。在中国知网(CNKI)期刊库中以“Skyline查询”为主题进行检索,检索时间从2009年1月1日~2013年12月31日,结果按被引频次由高到低排序,共搜索到66条记录,为使验证更具操作性,仅以被引频次和发表时间作为参考维度,部分检索结果如表2表示。
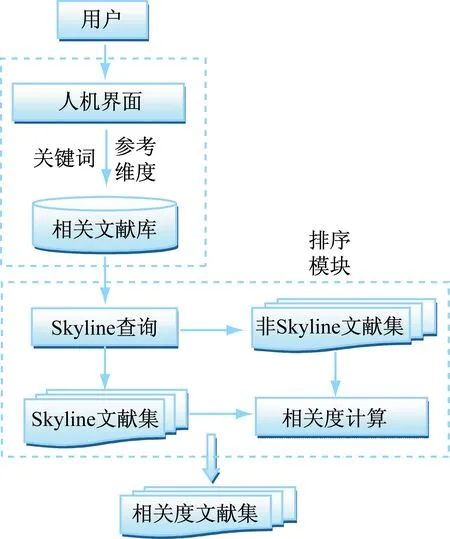
图3 基于关联度的多目标优化文献检索排序模型
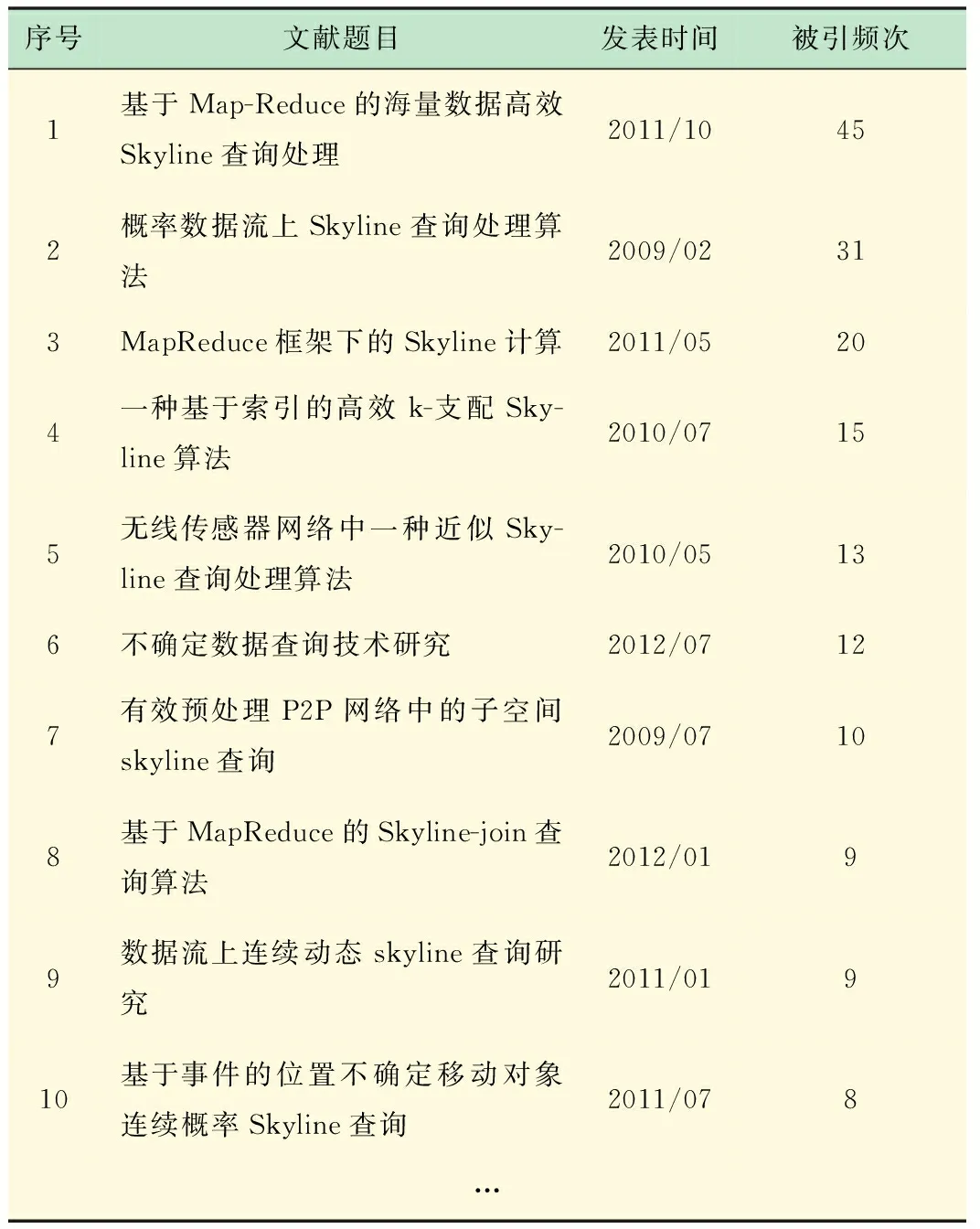
表2 部分检索结果列表
从表中可以看出,个别文献与用户期望结果有一定出入,从而增加了用户寻找目标文献的时间。对文献集合进行两个维度Skyline查询处理,得到Skyline初始文献集M,根据各文献之间的引用与关联关系,计算每个非Skyline文献的Skyline关联度大小。以Skyline关联度为排序依据,重新对文献集M进行排序,当存在Skyline关联度相同的文献时,将按文献被引频次的大小排序,优化后的排序结果如表3所示。
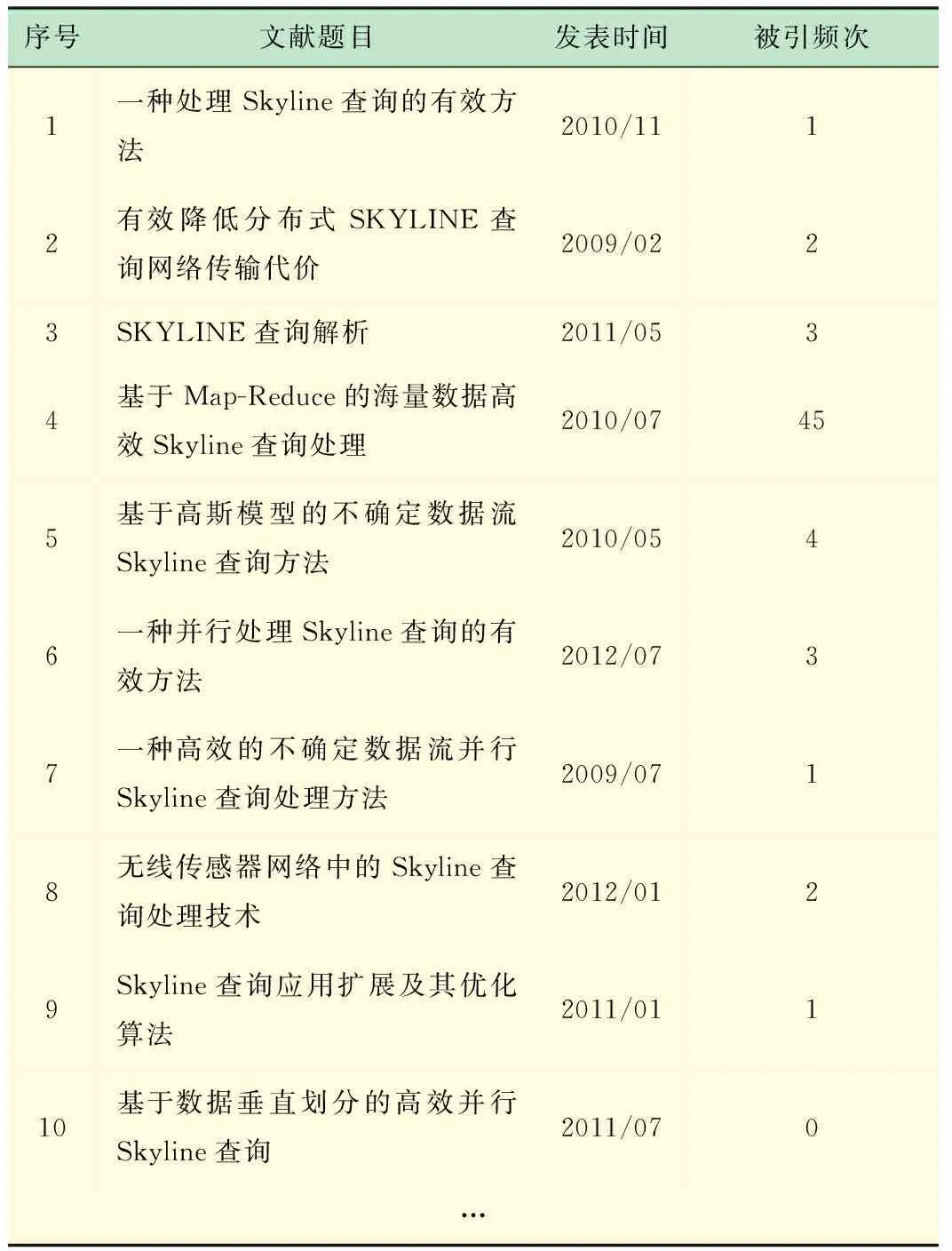
表3 Skyline关联度排序结果
结果表明,与优化之前相比,各文献的排列顺序发生了很大的变化,说明利用所设计模型能有效把原本排序位置靠后,但与用户期望资源关联度较高的文献信息挖掘出来,同时过滤掉原本排名靠前但关联度较低的文献,符合用户真正的检索需求。
5 结 论
资源利用率是评价文献检索有效性的重要指标,随着文献数量的迅速增长,传统关键字的检索方法已经很难满足用户的检索需求,因此寻求一种高效的文献检索与排序方法成为研究人员关注的重点。本研究从用户检索需求出发,在基于Skyline查询方法的基础上引入关联度的概念,将各文献之间的关联度作为排序的衡量指标,从而使Skyline文献集与非Skyline文献集之间紧密联系起来,以挖掘出满足用户需求且容易被忽视的文献,从而提高了资源的利用效率。测试结果表明,该方法可有效优化排序结果,真正把用户需要的文献信息挖掘出来,提高了文献的利用率和用户工作效率,设计方案满足实际需求,具有一定的实际应用价值。
[1] 蒋 涛, 张 彬, 余法红,等. 排序的相互k-Skyband查询算法[J]. 软件学报, 2015, 26(9): 2297-2310.
[2] 孙圣力,戴东波,黄震华,等. 概率数据流上skyline查询处理算法 [J].电子学报, 2009, 37(2): 285-293.
[3] Nattakarn, Ratprasartporn. Evaluating Different Ranking Functions for Context-Based Literature Search [N]. Data Engineering Workshop,2007.
[4] JIANG Y F, WANG H. Design and implementation of semantic search engine based on Lucerne [J]. Computer Engineering and Design,2008(20).
[5] 周绮凤,杨小青,洪文财,等.内嵌空间排序支持向量机及其在文本检索中的应用[J].信息与控制,2010,39(5):629-634.
[6] 孙笑明,崔文田.一种网络展现文献检索结果的理论模型[J].情报学报,2011,30(2).
[7] 向剑平,郑皎凌. Skylin计算在多维排序问题上的分析[J]. 太原师范学院学报(自然科学版),2009,8(2): 82-84.
[8] 杨立龙,董一鸿,何贤芒. 分布式环境下的Skyline代表点查询[J]. 计算机应用研究,2015(1):102-107.
[9] 瞿 亮,杨 贯.基于本体的专业文献检索[J].计算技术与自动化,2007,26(1).
[10] Lin Zhu, Yufei Tao, Shuigeng Zhou. Distributed Skyline Retrieval with Low Bandwidth Consumption [J]. IEEE Trans. Knowl. Data Eng., 2009, 21(3): 384-400.
[11] 黄子晴,刘东苏.Skyline查询处理在文献检索排序中的应用[J]. 情报理论与实践,2011(10):104-108.
[12] 刘松涛. 基于引文排序的科技文献检索初探[J]. 制造业自动化,2010,32(10): 129-131.
[13] 王晓伟,黄九鸣,贾 焰. 分布式不确定数据上的概率Skyline计算[J]. 计算机科学与探索, 2010, 4(10): 951-961.
[14] 杨林青,李 湛,牟雁超,等. 面向大规模数据集的并行化Top-k Skyline查询算法[J]. 计算机科学与探索,2015,9(8):897-904.
[15] Wei Xiaojuan,Yang Jing,Li Cuiping,etal. Skyline query processing [J]. Journal of Software,2008, 19(6): 1386-1400.
Design and Experiment of a Skyline Multi-objective Optimization Literature Retrieval Method Based on Correlation Degree
WANGChun-mei
(Jilin Agricultural University, Changchun 130000, China)
The querying and sorting the results are two important indexes of literature retrieval system, they directly affect the utilization of literature resources. In view of the current literature retrieval sequencing strategy, this study started from the user retrieval information needs, and was based on Skyline algorithm to propose a multi-objective optimization literature retrieval ranking method. The degree of correlation of the literature was the main condition and used to retrieving and ranking information, so that it could have the value of resource mining. Based on the CNKI database, relevant literature was retrieved, and application design model of search results was established. Results showed that the method could effectively optimize the ranking results, and mine associative information with a higher degree of correlation to meet the user expectations of resource retrieval requirements. The method improved the utilization rate of literature, and had a certain reference value.
document retrieval; Skyline query; correlation degree; optimization
2016-01-13
国家自然科学基金项目(31172144)
王春梅(1974-),女 ,吉林长春人,硕士,馆员,研究方向为信息系统实践研究。
Tel.:13194352337;E-mail: wcmwcm_1974@163.com
TP 391.3
A
1006-7167(2016)09-0126-04
