时钟共享多线程处理器通信机制的设计与实现*
2016-12-03雷晓锋
雷晓锋,李 涛
(1.西安邮电大学 计算机学院,陕西 西安 710061;2.西安邮电大学 电子工程学院,陕西 西安710061)
时钟共享多线程处理器通信机制的设计与实现*
雷晓锋1,李 涛2
(1.西安邮电大学 计算机学院,陕西 西安 710061;2.西安邮电大学 电子工程学院,陕西 西安710061)
多核多线程处理器[1]是并行技术的一个发展方向,基于多核多线程处理器,提出了一种时钟共享多线程处理器。该处理器有近邻通信和线程间通信两种通信机制,近邻通信采用近邻共享FIFO来传递信息,线程间通信通过线程间共享存储来传递信息,这样可以提高处理器的资源利用率和并行执行能力。
时钟共享多线程;近邻通信;线程间通信
0 引言
随着并行技术的不断发展,如何更好地提高处理器性能成为设计者急需解决的问题。传统处理器通过开发指令级并行(Instruction Level Parallelism,ILP)来提高处理器的性能,但硬件的复杂度及功耗等因素影响了处理器的性能。因此设计者们纷纷把目光投向更高层次的并行-线程级并行(Thread Level Parallelism,TLP),时钟共享多线程处理器就是在这种背景下产生的。但微处理器核间与线程间通信的线延迟问题仍是需要解决的核心问题[2-3]。本文基于时钟共享多线程处理器的功耗和结构复杂度要求,设计了近邻通信和线程间通信两种通信机制[4],并且对设计电路进行了功能仿真和FPGA验证。
1 时钟共享多线程处理器的体系结构
本文提出的时钟共享多线程处理器系统支持多指令多数据(MIMD)、分布式指令并行和流处理3种运行模式[5-6]。它由 16个处理单元(Processing Element,PE)互连构成一个4×4的二维阵列,还包括1个前端处理器、4个协处理器、2个调度器及2个存储管理。系统整体结构如图1所示。
2 设计与实现
2.1 近邻通信机制设计与实现
近邻通信机制采用邻接共享FIFO实现。处理单元(PE)可访问的存储空间包括本地存储、近邻共享 FIFO、线程间共享存储。本地存储分为8个4 K大小的Bank存储,单个PE的近邻通信结构如图2所示。
近邻通信的电路在译码模块中完成,该模块完成指令的解析,近邻通信数据、线程间通信数据及本地数据的读取,判断近邻通信和线程间通信阻塞的产生及解除。近邻通信机制完成如下功能:
(1)译码单元将近邻通信数据写入近邻 FIFO中。它首先判断该指令是否属于阻塞以及读取近邻FIFO的状态。当近邻FIFO不满时,将目标数据直接写入近邻FIFO中,当处于满状态时则发生近邻写阻塞;(2)译码单元需要从邻接PE的东、西、南、北4个方向的FIFO中读取数据。译码单元首先判断该指令是否属于阻塞指令并且是否需要读近邻FIFO,同时读取近邻FIFO的状态。当近邻FIFO不空时,将目标数据从近邻FIFO中直接读取到译码单元,当近邻FIFO处于空时说明当前线程发生了近邻读阻塞。
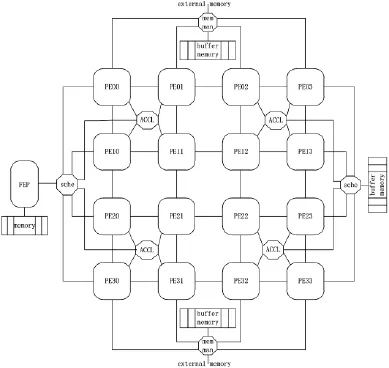
图1 时钟共享多线程处理器系统整体结构
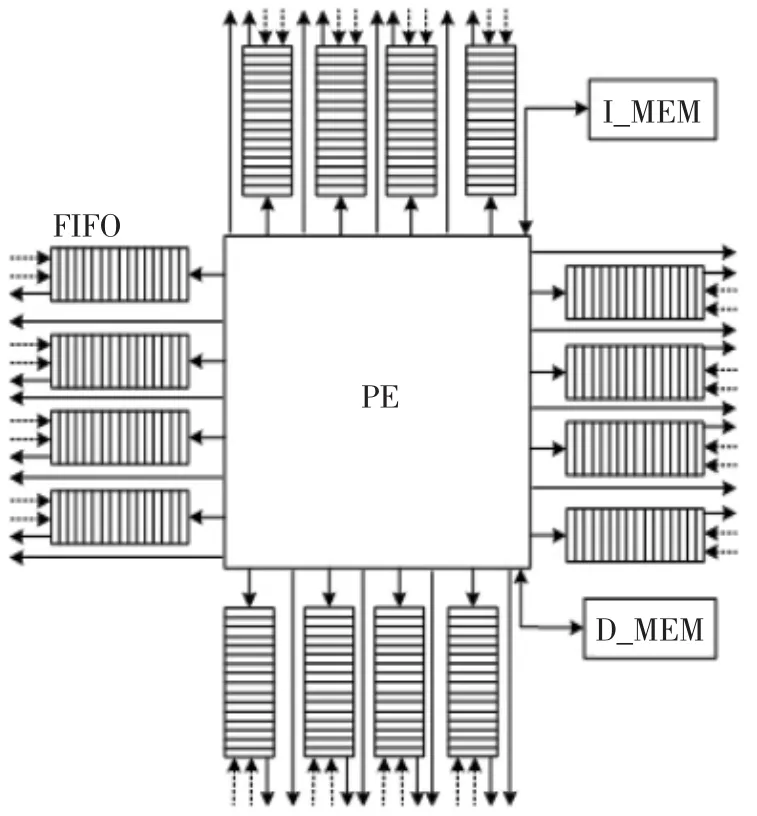
图2 单个PE的近邻通信结构
本处理单元(PE)与4个邻接PE进行近邻数据通信,东/西/南/北四个方向的近邻通信机制结构、端口数量及接口时序也类似。本小节以西边第一组的相关接口时序为例进行说明。
如图3所示,当本地PE的目标地址为近邻通信时,首先使用目标地址的低两位(dec_dst_addr[1:0])判断近邻通信的方向,当目标地址为12hFFC时表明该指令需要向西边对应的FIFO中写数据,当检测到西边FIFO的几乎满信号为1时,表明该指令发生了写近邻阻塞(wr_ngb_blk),当前线程不能继续运行,需要切换线程。同时将写近邻阻塞标志、写近邻阻塞地址及写近邻阻塞来自于哪个线程发送给存储管理模块。当检测到西边FIFO的几乎满信号为0时,表明该指令可以直接将目标数据写入到对应FIFO中。

图3 近邻通信判断写阻塞接口时序
如图4所示,首先使用源地址的低两位(dec_src_addr [1:0])判断近邻通信的方向,如图所示当源地址为12hFFC时,表明该指令需要从邻接PE西边对应的FIFO中读数据,当检测到西边FIFO不空,表明该指令可以直接从西边对应的FIFO中读取数据,当拍发送读使能(npe_rd_fifo_west_en)及线程选择信号(npe_rd_fifo_west_sel),下一拍得到数据(npe_rd_fifo_west_data)。当检测到西边 FIFO为空时,表明该指令发生了读近邻阻塞(rd_ngb_blk),当前线程不能继续运行,需要切换线程。
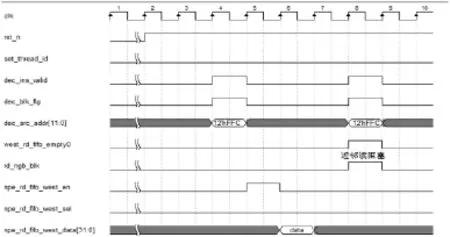
图4 近邻通信判断读阻塞接口时序
因为近邻通信的读阻塞和写阻塞判断逻辑类似,只是条件不同,下面对近邻通信的写阻塞判断逻辑做详细介绍。
如图5所示,首先在指令(dec_ins_valid=1)和指令的阻塞标志都有效(dec_blk_flg=1)情况下判断指令的目标地址是否为近邻通信地址,然后根据目标地址的低两位(dec_dst_addr[1:0])判断近邻通信的方向,每个方向有两个FIFO分别对应低线程和高线程;当目标线程号set_thread_id=0时判断低线程对应的FIFO是否为几乎满,如果为几乎满则表示该方向对应的低线程发生了近邻通信写阻塞(wr_ngb_blk=1),且同时将近邻通信写阻塞标志(wr_ngb_blk_flag)、近邻通信写阻塞地址(wr_blk_ngb_addr)及近邻通信写阻塞来自哪个线程的信号(wr_blk_ngb_from_t)发送给存储管理模块;如果不为满则当前目标数据直接写入到对应方向的 FIFO中。例如指令“BMULT 4092,20,21”,该指令经过译码解析,将 20号地址单元中的数据与21号地址单元中的数据进行乘法运算并将结果送到西边邻接的PE。此时译码单元需要判断西边FIFO是否为满。若西边FIFO为满时,此时该指令就发生了近邻写阻塞;若西边FIFO不为满时,直接将乘法结果写入到西边FIFO中。
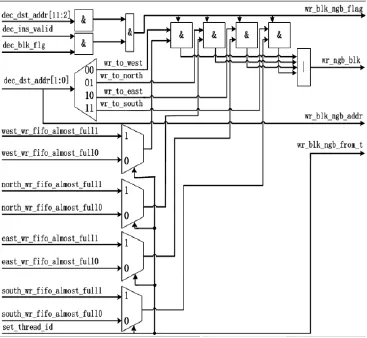
图5 近邻通信写阻塞判断结构
2.2 线程间通信机制设计与实现
线程间通信是处理单元(PE)线程内部之间的数据交换,每个处理单元(PE)的线程间通信地址都有自己的标志寄存器,用于判断是否发生线程间通信阻塞。每个线程数据存储地址的0~7对应0~7号线程的共享存储。
如图6所示,首先判断目标地址是否为线程间通信地址,图中dec_dst_addr[11:0]=12’d1表明当前线程需要向1号线程写数据,其次判断1号线程对应的写阻塞寄存器(th_low_wr_t1_blk)的最低位,为 0时表明目标数据可以直接写入到对应线程的共享存储中,同时将写线程间阻塞标志(wr_th_blk_flag)、写线程间阻塞地址(wr_th_ blk_addr)及写线程间阻塞来源于哪个线程(wr_th_blk_ from_t)发送给存储管理模块。为1表明当前线程发生了写线程间阻塞(wr_th_blk),当前线程无法继续运行需要切换线程,同时将写线程间阻塞标志(wr_th_blk_flag)、写线程间阻塞地址(wr_th_blk_addr)及写线程间阻塞来自于哪个线程(wr_th_blk_from_t)发送给存储管理模块。
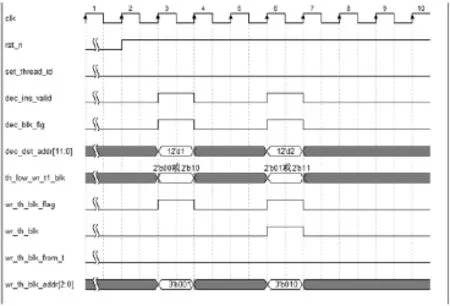
图6 线程间通信写阻塞判断接口信号
如图7所示,首先判断源地址是否为线程间通信地址,图中dec_src_addr[11:0]=12’d1表明需要读取1号线程的数据,其次判断1号线程对应的读阻塞信息寄存器(th_low_rd_t1_blk)是否为 2’b11,当为 2’b11时表明对应的共享存储中有数据且当拍发送读使能信号(dec_src_rd_en), 下 一 节 拍 得 到 对 应 线 程 的 数 据(dec_src_rd_data)。不为2’b11时表明需要的数据还没有写入到对应的线程共享存储中,则该指令发生读线程间阻塞(rd_th_blk)。
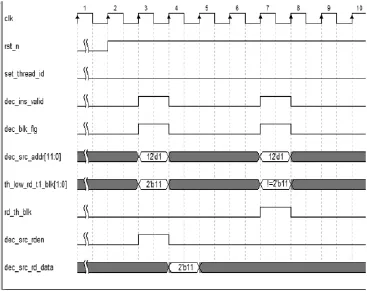
图7 线程间通信读阻塞判断接口信号
因为线程间通信的读阻塞和写阻塞判断逻辑类似,只是判断的条件不同,因此下面对线程间通信的写阻塞判断逻辑进行详细介绍。
如图8所示,首先在指令(dec_ins_valid=1)和指令的阻塞标志(dec_blk_flg=1)有效情况下,判断指令的目标地址是否为线程间通信地址,根据目标地址的低三位(dec_dst_addr[2:0])判断写哪个线程,根据线程间通信地址对应的阻塞寄存器低位判断当前地址是否有阻塞信息。如果有阻塞,表明发生写线程间阻塞(wr_th_blk=1),同时发送写线程间阻塞标志(wr_th_blk_flag)、写线程间阻塞对应的地址(wr_blk_th_addr)及写线程间阻塞来自于哪个线程的信号(wr_blk_th_from_t)给存储管理模块,如果无阻塞则数据直接写入到对应线程的共享存储中。例如指令“BMULT 2,20,21”,该指令经过译码单元解析后判断该指令属于阻塞指令并且属于线程间通信指令,需要写2号线程的共享存储,此时译码单元首先判断2号线程对应的阻塞寄存器中的阻塞标志位,若为高,表明该共享地址中已经有数据,此时该指令就会发生写线程间阻塞;若为低,表明该共享地址中没有数据,可以直接将乘法写入2号线程对应的共享存储中。

图8 线程间通信写阻塞判断结构
3 仿真验证及结果分析
仿真验证使用 Mentor公司的 Modelsim SE 10.1c仿真工具,根据实际情况编写不同方案下的测试激励,在System Verilog搭建的平台和软件仿真平台上验证时钟共享多线程处理器系统的功能。
3.1 近邻通信的功能仿真
测试方案:为了测试近邻通信的完整性,分别测试东/西/南/北四个方向的写共享FIFO和读邻接 PE的共享FIFO数据至本地PE。测试汇编程序如图9所示。

图9 近邻通信测试汇编程序
测试说明:选择0号线程测试近邻通信功能。首先测试 0号线程分别向东/西/南/北4个方向对应的共享FIFO中分别写入4个数据,等待邻接PE读取。最后测试本地PE的线程0从邻接PE东/西/南/北4个方向的线程0共享FIFO中分别读取4个数据至本地PE,参与相关运算;测试汇编程序如图10所示。

图10 近邻通信仿真波形
图10 为近邻通信仿真波形。邻接PE分别检测本地PE线程 0对应的东/西/南/北 4个方向共享 FIFO是否为空,图中西边读 FIFO0信号不为空(west_rd_fifo0_empty0=0),表明本地PE已经将近邻数据写入到线程 0对应的FIFO中。邻接PE开始向西边的FIFO发送读使能信号(npe_rd_fifo0_west_en)及读选择信号(npe_rd_fifo0_west_ sel),下一拍得到数据(npe_rd_fifo0_west_data)。最后本地PE需要从邻接的4个方向读取数据,当检测到邻接4个方向的FIFO不为空时(rd_west_fifo0_empty=0,rd_north_ fifo0_empty=0,rd_east_fifo0_empty=0,rd_south_fifo0_empty= 0),表明邻接4个方向已经准备好数据,本地PE发送 4个方向的读 FIFO的使能信号(rd_npe_fifo0_en)和选择信号(rd_npe_fifo0_sel),下一拍得到数据(rd_npe_fifo0_data)。当数据读完之后4个方向的rd_fifo0_empty0变为高电平。
3.2 线程间通信的功能仿真
测试方案:选用PE的0、1、2、3号线程进行测试。0号线程执行加法运算,将其运算结果传递给2号线程进行乘法运算;1号线程执行加法运算,将其运算结果传递给3号线程进行乘法运算。测试线程间共享存储的访问功能。测试汇编程序如图11所示。
测试说明:线程0执行A+B操作(A=2,B=3)将运算结果D=5写到2号线程的共享存储中;线程1执行A+ B操作(A=3,B=4),将运算结果D=7写到3号线程对应的共享存储中;线程2需要读出线程2对应共享存储中的数据和21号地址里边的数据进行乘法运算,预期的运算结果为5;而线程3则需要读出线程3对应共享存储中的数据和20号地址里边的数据进行乘法运算,预期的运算结果为7。
如图12所示,线程1将数据写入到3号线程对应的共享存储中时,对应的写3号线程阻塞寄存器的值变为2’b11(th_low_wr_t3_blk=2’b11),当写入3号线程的共享数据读取后,阻塞信息寄存器清零(th_low_wr_t3_blk= 2’b00);3号线程执行乘法操作,图中横线位置表示 3号线程的乘法结果有效vout=1且运算结果mulout=7。
综上,处理器单元的近邻通信和线程间通信都是正确的,满足了预期的功能。
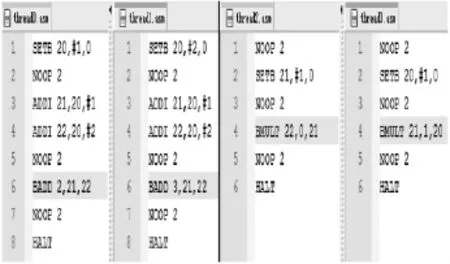
图11 线程间通信测试汇编程序

图12 线程间通信仿真波形
4 总结
本文提出了一种时钟共享多线程处理器的数据通信机制,完成了modelsim的功能仿真、Xilinx ISE14.4的综合,工作频率达到431.816 MHz,在Vertex7-2000T的FPGA开发板实现了验证。该设计的近邻通信和线程间通信机制减少了片上资源的使用率且降低了数据传输的延迟,有效地提高了处理器的性能。
[1]屈文新,樊晓桠,张盛兵.多核多线程处理器存储技术研究进展[J].计算机科学.2007(4).
[2]GRATZ P,SANKARALINGAM K,HANSON H,et al. Implementation and evaluation a dynamically routed processor operand network[C].Proceedings of First International Symposium on Networks-on-chip,IEEE Computer Society,2007,23(10):7-17.
[3]黄志钢,盛肖炜.多核处理器结构与核间通信的 CMC总线设计[J].沈阳理工大学学报,2012,31(6):70-91.
[4]徐卫志,宋风龙,刘志勇,等.众核处理器片上同步机制和评估方法研究[J].计算机学报,2010,33(10):1777-1787.
[5]李涛,肖灵芝.面向图形和图像处理的轻核阵列机结构[J].西安邮电学院学报,2012,17(3):43-46.
[6]蒲林.多态并行处理器中的 SIMD控制器设计与实现[J].电子技术应用,2013,33(11):53-59.
Design and implementation of communication mechanism for a shared-clock multithreading processor
Lei Xiaofeng1,Li Tao2
(1.School of Computer,Xi′an University of Posts and Telecommunications,Xi′an 710061,China;2.School of Electronic Engineering,Xi′an University of Posts and Telecommunications,Xi′an 710061,China)
Multicore and multithreaded processors is a development direction of parallel technology.This paper design a shared_clock multithreading processor for multicore and multithreaded processors.It has two communication mechanisms:the neighbor communication and the thread-thread communication.The neighbor communication conveys information by the neighbored shared FIFO and thread-thread communication conveys information by shared memory.This can improve resource utilization and parallel executing capacity.
shared-clock multithreading processor;neighbor communication;thread-thread communication
TP302
A
10.16157/j.issn.0258-7998.2016.03.012
雷晓锋,李涛.时钟共享多线程处理器通信机制的设计与实现[J].电子技术应用,2016,42(3):42-46.
英文引用格式:Lei Xiaofeng,Li Tao.Design and implementation of communication mechanism for a shared-clock multithreading processor[J].Application of Electronic Technique,2016,42(3):42-46.
2015-08-11)
雷晓锋(1990-),男,硕士研究生,主要研究方向:计算机系统结构与VLSI。
国家自然科学基金(61136002);陕西省科学技术研究发展计划(2011K06-47);陕西省重点学科建设西邮计算机体系结构项目资助
李涛(1954-),男,教授,主要研究方向:计算机体系结构、计算机图形学研究。
