3D-HEVC中深度图帧内预测模式判决过程的改进*
2016-12-02雷海卫刘文怡王安红
雷海卫,刘文怡,王安红
(1.中北大学 仪器科学与动态测试教育部重点实验室,山西 太原 030051;2.太原科技大学 电子信息工程学院,山西 太原 030024)
3D-HEVC中深度图帧内预测模式判决过程的改进*
雷海卫1,刘文怡1,王安红2
(1.中北大学 仪器科学与动态测试教育部重点实验室,山西 太原 030051;2.太原科技大学 电子信息工程学院,山西 太原 030024)
深度图建模模式的使用可以有效地降低编码的深度图内部边界处的伪影效应,从而改善深度图的编码质量,但同时也极大地增加了编码的计算复杂度。为了降低由此而带来的计算复杂度,对深度图帧内预测的模式判决过程和现有的快速模式判决方案进行了分析,同时对不同大小的编码块使用深度图建模模式的情况进行了统计。然后,从编码块的特征和编码块的大小两个角度对现有的模式判决过程进行了改进。实验结果表明,改进后的方案在基本不影响编码质量的前提下能有效地加速帧内预测的模式判决过程。
3D-HEVC;深度图编码;帧内预测;模式判决
0 引言
3D-HEVC(The 3D Extension of High-efficiency Video Coding)是继 HEVC之后由视频编码协作小组制定的又一个视频编码标准,它是 HEVC的扩展[1],主要用于实现 3D视频和自由视点视频(Free Viewpoint Video,FVV)的编码。在3D-HEVC中,除需要对几个不同视点的纹理视频(Texture)进行编码外,还需要对相应视点的深度图(Depth)进行编码。解码端根据接收到的纹理视频和深度图利用基于深度图绘制的技术(Depth Image Based Rendering,DIBR)[2]合成中间的虚拟视点视频。从而可以由少数的几个视点的视频生成更多可观看的视点。在采用3D-HEVC技术后,用户可以欣赏到来自同一场景但从不同角度拍摄的视频内容,此外,视频的呈现方式也可以是3D的,这样的视频被称为自由视点立体视频。可以看出,采用3D-HEVC编码的视频能给人们带来更好的视觉感受和增强用户体验。但这也造成了3D-HEVC的编码结构以及编码过程十分复杂,进而使得编码时间过长。
3D-HEVC基本沿用了HEVC中的编码技术,这些技术能高性能、高质量地完成对纹理视频的编码,但对深度图的编码效果并不好,因为深度图有不同于纹理图的特征,深度图通常包含了一些锐利的边界和大片的平坦区域。采用HEVC中的编码技术来编码深度图,解码后的深度图内部边界处会产生伪影效应,这将影响合成的虚拟视点的质量。为了改善深度图的编码效果,3D-HEVC禁用和修改了HEVC中的几个编码工具。此外,还加入了一些新的编码工具,包括深度图建模模式(Depth Modelling Mode,DMM)[3]、简化的深度图编码(Simplified Depth Coding,SDC)和单一深度帧内模式(Single Depth Intra Mode)等。
1 深度图建模模式
深度图建模模式是一种新的帧内预测模式,用于对深度值有明显过渡的区域进行编码。最初制定了4种预测模式,即DMM1、DMM2、DMM3和DMM4,目前保留使用的是 DMM1(Explicit Wedgelet Signalling)和 DMM4(Inter-component-predicted Contour partitioning)。两者采用了不同的划分类型:楔形和轮廓形划分。两种划分方式均会把一个编码块划分为两部分(P1和P2),如图1所示。

图1 块的楔形划分(上)和轮廓形划分(下)
图1中以8×8的编码块为例进行说明,左侧为连续空间,右侧为对应的离散空间。深度图建模模式除需要划分信息外,还需要为划分出的每个区域指定一个常量值,来表示这一区域的深度值。在使用深度图建模模式对深度图进行编码时,可以选择这两种模型中的一种对当前编码块进行建模,作为当前编码块的预测信号。
在原有预测模式基础上加入深度图建模模式后,能有效地降低内部边界处的伪影效应,改善深度图的编码质量,但同时也极大地增加了编码的计算复杂度。复杂度的增加来自两个方面:一方面,新增加的模式使可供选择的模式数量增加,从而在模式判决时会消耗更多的时间;另一方面,深度图建模模式自身的建模过程也非常耗时。因此,对模式判决过程或者建模过程进行优化都会使编码过程加速,从而提高编码效率。本文旨在对模式判决过程进行优化。
HEVC中原有 35种帧内预测模式,分别是 Planar模式、DC模式以及33种角度模式。对这35种模式,首先采用基于残差的哈达玛变换方法进行粗选,针对64× 64、32×32和 16×16大小的编码块会选出3个,针对 8× 8和4×4大小的块会选出8个预测模式加入全率失真候选列表,然后进行全率失真代价计算,选取使得率失真代价值最小的模式作为最佳的帧内预测模式。深度图建模模式被设计为帧内预测模式,因此DMM1和DMM4也被加入到全率失真候选列表参与率失真代价计算。整个帧内预测的模式判决过程如图2所示。

图2 帧内预测的模式判决过程
2 相关工作
如前所述,深度图包含了大块的平坦区域,这也就表明并不是深度图中的所有编码块都适用于深度图建模模式。因此当对某个块进行预测编码时,DMM1和DMM4两个预测模式无条件地加入到全率失真候选列表进行全率失真代价的计算会额外增加编码的计算复杂度。
针对这种情况,一些快速的模式判决算法被提出。文献[4]基于最大概率模式提出了一个快速的深度图建模模式选择算法。文献[5]提出当预测块中深度值的变化小于某个阈值时,则略过深度图建模模式。在文献[6]中,一个类似的采用阈值的方法被提出。文献[7]中,一个简化的边检测器和一个基于梯度的模式滤波器被用来决定是否略过深度图建模模式。文献[8]采用了一种基于哈达玛域的边分类算法来加速模式判决过程。
其中,文献[4]和文献[5]是在视频编码协作小组举办的国际会议上提交的提案。提案中的方法已被采纳并加入到3D-HEVC的参考软件HTM中。具体而言,它采用了两个策略来判断是否将深度图建模模式加入到全率失真候选列表。一个是基于最大可能性统计,即认为经过粗选之后若候选列表中的第一个预测模式为Planar模式,则当前块极可能是平坦的或光滑的,因此深度图建模模式将以极大的概率不会被选作最佳的预测模式。另一个是基于阈值的方法,阈值表达式如式(1)所示,其中QP表示当前编码块的量化参数。当当前编码块的深度值变化大于此阈值时,才考虑把深度图建模模式添加到全率失真候选列表。
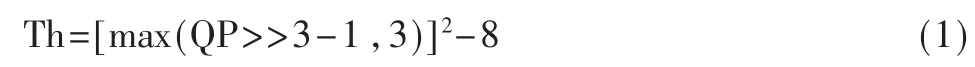
3 提出的改进
文献[5]和文献[6]中提出的方案的目的是使对于那些明显不适合采用深度图建模模式进行预测编码的块进行模式判决时,不把DMM1和DMM4加入到全率失真候选列表。从而避免对DMM1和DMM4的全率失真代价计算过程,也略过这两个预测模式自身建模的过程,进而加速了模式判决的过程。本文在此基础上进一步优化模式判决过程,主要提出了两点改进。
3.1基于块特征的方法
如前所述,无论是DMM1还是DMM4,都会将当前编码的块分割成两个区域,并为每个区域指定一个常量值,用这样的模型作为当前块的预测信号。深度图建模模式只适用于对深度值有明显过渡的块进行预测,文献[4]和文献[5]中的改进也主要基于此思想。改进策略用表达式(2)描述,其中,uiRdModeList[0]表示候选列表中的第一个预测模式,等号右侧的0代表Planar模式,variance表示当前块深度值的变化。

观察发现,采用此方案后,仍有少量平坦的块被遗漏,因为方案中采用了“或”的运算关系,即当第一个条件满足时,当前编码块仍有可能是平坦的。为此,本文采取边缘检测的方法进一步过滤遗漏掉的平坦块。首先采用canny算法对整帧深度图像进行边缘检测,最初的深度图像如图3所示,边缘检测的结果如图4所示,图中黑色的线条表示深度的过渡。然后,定义图4中(大块)的白色区域为平坦区域,如果当前正在编码的深度块位于平坦区域处,则不把DMM1和DMM4加入全率失真候选列表。

图3 Balloons深度图序列的第一帧

图4 Balloons深度图序列第一帧的边缘检测结果
3.2基于块大小的方法
与对纹理视频的编码方式一样,对深度图的编码同样也采用了基于块的编码方案。一帧图像按行列的方式被划分为多个编码树单元(Coding Tree Unit,CTU),每个编码树单元再以四叉树的形式递归地划分为更小的编码单元(Coding Unit,CU)。编码单元被划分为更小的预测单元(Predicted Unit,PU),每一个预测单元可采用不同的预测模式来产生它的预测信号。在3D-HEVC标准配置模式下,编码树单元的大小为64×64。编码树单元允许最多4级的递归划分,因此编码单元的大小可以是64×64、32×32、16×16或8×8。在采用帧内预测时,编码单元要么整体作为一个预测单元,要么被四等分为4个预测单元。因此预测单元的大小可以是64×64、32×32、16×16、8×8或4×4。
由图2可知,由粗选过程选出前3个(或者前8个)较好的帧内预测模式与DMM1以及DMM4一并被加入到全率失真候选列表,进行全率失真代价计算,最终选取一种预测模式作为最佳预测模式。为了进一步分析深度图建模模式的使用情况,对在不同块大小情况下,深度图建模模式的使用次数进行了统计,统计的结果如表1所示。
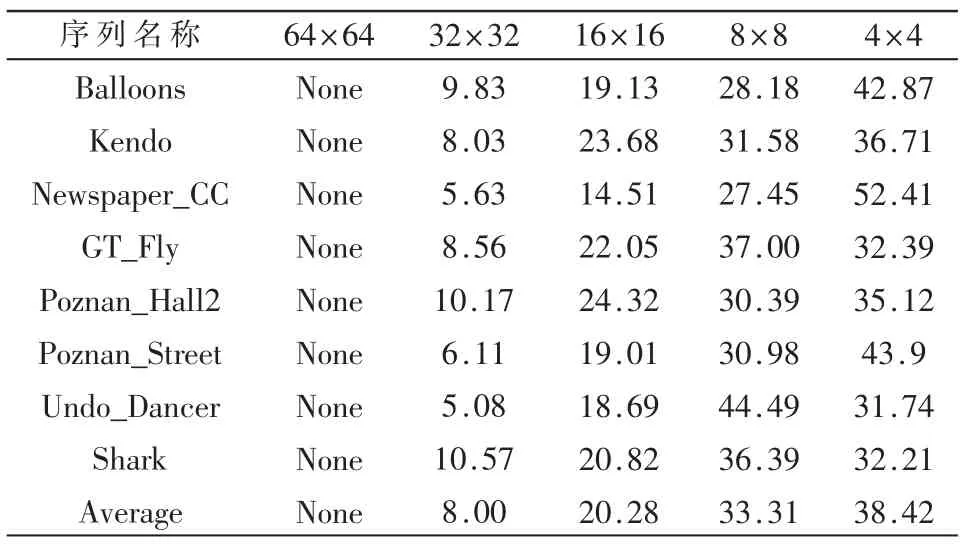
表1 深度图建模模式在不同大小的预测块中的使用情况
从表1中可以看出,当预测块的大小为32×32时,深度图建模模式的使用次数最少(平均占比为8%)。因此,如果事先规定当预测块的大小为 32×32时,深度图建模模式(DMM1和DMM4)将不被加入到全率失真列表,那么就能使这些块跳过深度图建模模式全率失真代价的计算过程。在深度图建模模式使用率较低的前提下,即使对某些特定大小的块不使用DMM1(或DMM4),这一预测模式也不会对编码质量产生太大的影响。
3.3改进后的模式判决过程
改进后的模式判决过程如图5所示。为了方便描述,只给出了深度图建模模式的模式判决过程,其中第1个判断框为原有方案。可以看到,改进后的方案能对深度图建模模式起到进一步的过滤作用,从而加快整个模式判决过程。
4 实验结果
为了评估提出的改进方案,进行了前后对比的测试实验。实验在3D-HEVC的参考软件HTM15.1[9]上进行。8个标准的测试序列作为输入,读取每个序列的前100帧进行测试。编码方案采用通用测试条件[10]中的编码帧结构,选取的纹理和深度的量化参数 QP分别为25:34、30:39、35:42和40:45。测试的结果如表2所示,表中列出了采用改进后的方案在编码质量和编码时间方面较之前的变化。可以看到,纹理视频的编码质量和合成视点的编码质量损失很少,分别为 0.16%和0.19%,但整个编码时间却节省了3%。
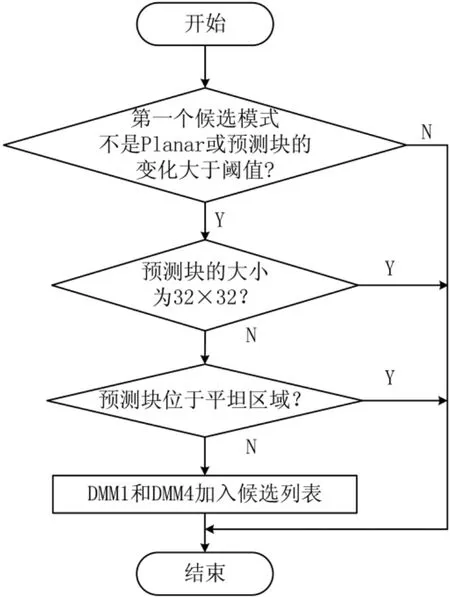
图5 改进后深度图建模模式的模式判决过程
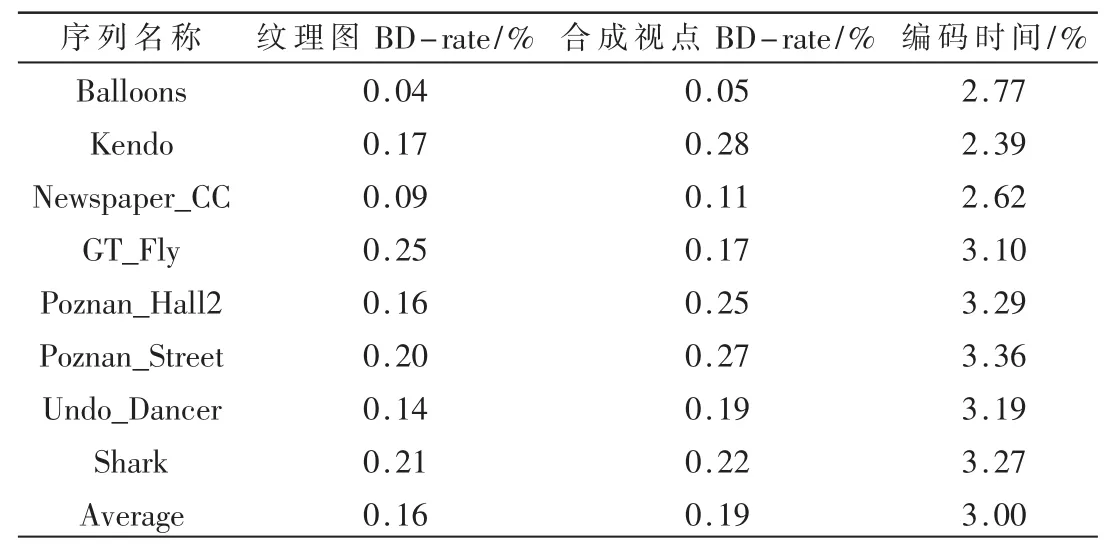
表2 改进前后编码质量和编码时间对比
5 结论
本文针对深度图编码中的帧内预测的模式判决过程提出了两点改进,旨在加快模式判决的过程。实验结果表明,在基本不影响编码质量的前提下,改进后的方案能有效地加快模式判决的过程,从而使整体的编码时间节省3%。这对促进3D-HEVC的实时性应用具有一定意义。
[1]MULLER K,SCHWARZ H,MARPE D,et al.3D highefficiency video coding for multi-view video and depth data[J].Image Processing,IEEE Transactions on,2013,22 (9):3366-3378.
[2]FEHN C.Depth-image-based rendering(DIBR),compression and transmission for a new approach on 3D-TV[C].Proceedings of the Stereoscopic Displays and Virtual Reality Systems XI,2004:93-104.
[3]MERKLE P,BARTNIK C,MULLER K,et al.3D video:depth coding based on inter-component prediction of block partitions[C].Proceedings of the Picture Coding Symposium (PCS),2012:149-152.
[4]ZHOUYE G,JIANHUA Z,NAM L,et al.Fast depth modeling mode selection for 3D HEVC depth intra coding[C].Proceedings of the Multimedia and Expo Workshops (ICMEW),2013 IEEE International Conference on,2013:1-4.
[5]GU Z Y,ZHENG J H,LING N,et al.Fast intra prediction mode selection for intra depth map coding[C].JCT3VE0238 of JCT-3V,Vienna,AT,2013.
[6]ZHANG Q,LI N,WU Q.Fast mode Ddecision for 3DHEVC depth intracoding[J].The Scientific World Journal,2014(3):620142.
[7]SANCHEZ G,SALDANHA M,BALOTA G,et al.DMMFast:a complexity reduction scheme for three-dimensional highefficiency video coding intraframe depth map coding[J].ELECTIM,2015,24(2):1-15.
[8]CHUN-SU P.Edge-based intramode selection for depthmap coding in 3D-HEVC[J].Image Processing,IEEE Transactions on,2015,24(1):155-162.
[9]JCT-3V.Subversion repository for the 3D-HEVC test model version HTM-15.1[EB/OL].[2015-11-28].https://hevc.hhi.fraunhofer.de/svn/svn_3DVCSoftware/tags/HTM-15.1/.
[10]RUSANOVSKYY D,MÜLLER K,VETRO A.Common test conditions of 3DV core experiments[C].JCT3V-F1100 of JCT-3V,Geneva,Switzerland,2013.
Improvement on mode decision process of depth map intra-predicted in 3D-HEVC
Lei Haiwei1,Liu Wenyi1,Wang Anhong2
(1.Key Laboratory of Instrumentation Science&Dynamic Measurement,Ministry of Education,North University of China,Taiyuan 030051,China;2.School of Electronic Information Engineering,Taiyuan University of Science and Technology,Taiyuan 030024,China)
The use of depth modelling mode can effectively reduce the artifact effects at the sharp edges of the encoded depth map,and thus improve the encoding quality of the depth map.But it also greatly increase the computational complexity of encoding.In order to reduce the computational complexity,the mode decision process of the depth map intra-predicted and the existing fast mode decision scheme are analyzed.Meanwhile,the usage of depth modelling mode in the case of different block sizes is gathered.Then,the mode decision process is improved based on the characteristic and the size of the block to be encoded.Experimental results show that the improved scheme can effectively accelerate the mode decision process of intra-prediction with negligible coding quality loss.
3D-HEVC;depth map coding;intra-predicted;mode decision
TN919.8
A
10.16157/j.issn.0258-7998.2016.10.030
国家基金委重大国际(地区)合作研究项目(61210006);国家自然科学基金(6127262);2015年山西省高等学校科技创新项目(20151101)
(2016-02-23)
雷海卫(1980-),男,博士研究生,讲师,主要研究方向:视频信号处理、3D视频编码。
刘文怡(1970-),男,博士,教授,主要研究方向:数字信号处理、压缩编码、存储测试和嵌入式系统。
王安红(1972-),女,博士,教授,主要研究方向:图像编码、分布式视频编码。
中文引用格式:雷海卫,刘文怡,王安红.3D-HEVC中深度图帧内预测模式判决过程的改进[J].电子技术应用,2016,42 (10):116-119.
英文引用格式:Lei Haiwei,Liu Wenyi,Wang Anhong.Improvement on mode decision process of depth map intra-predicted in 3D-HEVC[J].Application of Electronic Technique,2016,42(10):116-119.
