分布式数据流挖掘技术综述
2016-12-02万新贵
万新贵
(南京邮电大学 计算机学院,江苏 南京 210003)
分布式数据流挖掘技术综述
万新贵
(南京邮电大学 计算机学院,江苏 南京 210003)
网络信息技术的高速发展产生了新的数据模型,即数据流模型,并且越来越多的领域出现了对数据流实时处理的需求,庞大且高速的数据以及应用场景的实时性需求均推进了数据流挖掘技术的发展。首先介绍了常见的数据流模型;然后根据数据流模型的特点总结数据流挖掘的支撑技术;最后,分析了分布式数据流挖掘的重要性和有效性,给出了算法并行化的数学模型,并介绍了几种具有代表性的分布式数据流处理系统。
数据流模型;数据流挖掘;分布式;并行化;数据流处理系统
0 引言
数据流(Data Stream)常常产生于Web上的用户点击、网络入侵检测、实时监控系统或无线传感器网络等动态环境中。与传统数据集相比较,这些海量的数据流具有快速性、连续性、变化性、无限性等特点。海量的数据流、复杂的数学模型和高要求的时效性使得传统的数据挖掘面临巨大的挑战,数据流挖掘技术得到了迅猛的发展。
20世纪初,出现了诸如STREAM[1]、Aurora[2]等数据流管理系统(Data Stream Management System)。早期的数据流管理系统应用领域较为单一,并且大多采用集中式架构,虽然提供了基本算子,但是算子与底层模块的耦合度较高,难以实现扩展开发。随着技术的发展和需求的提升,分布式技术对数据流处理的重要性显现出来。
21世纪初,随着各类开放式计算平台的兴起,S4[3]、Storm[4]、Spark Streaming[5]以及Samza[6]等数据流处理平台相继被提出,分布式数据流处理技术已经成为热点。
1 数据流模型
数据流是一个带有数据时间戳(Time Stamp)的多维数据点集合x1,…,xk,每个数据点xi是一个d维的数据记录。数据流不被控制且潜在体积无限大,数据流处理系统无法保存庞大的数据流。
目前的数据流研究领域存在多种数据流模型,根据数据流模型自身的特点,可以从两个方面对数据流模型进行分类[7],分别是按照数据流中数据描述现象的方式和算法处理数据流时所采用的时序范围。
1.1 按照描述现象的方式分类
按照数据流中数据描述现象的方式,数据流模型可以分为时序(Time Seriel)模型、现金登记(Cash Register)模型和十字转门(Turnstile)模型,其中十字转门模型的适用范围最广,但也是最难处理的。
(1)时序模型:将数据流中的每个数据看作独立的对象。
(2)现金登记(Cash Register)模型:数据流中的多个数据项增量式地表达某一现象。
(3)十字转门(Turnstile)模型:数据流中的多个数据项表达某一现象,随着时间的流逝,该现象可增可减。
1.2 按照算法所采用的时序范围分类
部分算法并不将数据流的数据作为处理对象,而是选取某个时间范围的数据进行处理,按照算法处理数据流时所采用的时序范围,可以将数据流模型分为:快照(Snapshot)模型、界标(Landmark)模型和滑动窗口(Sliding Window)模型,其中界标模型与滑动窗口模型使用得比较普遍。
(1)快照模型:处理数据的范围限定在两个预定义的时间戳之间。
(2)界标模型:处理数据的范围从某一已知时间到当前时间。
(3)滑动窗口模型:处理数据的范围由固定窗口的大小决定,窗口的终点永远是当前时间。
2 支撑技术
根据数据流的特点,数据流处理技术需要满足单遍扫描、低时空复杂度等要求。为了有效地处理数据流,新的数据结构、技术和算法是必须的。参考文献[8]将数据流挖掘的支撑技术分为两类,分别是基于数据(Data-based)的技术,旨在以小范围的数据代替所有数据,达到数据流处理方法的高性能;另一种是基于任务(Task-based)的技术,力图在时间和空间上得到更有效的解决方法。
2.1 基于数据的技术
数据挖掘与查询需要读取扫描过的数据[9],但是由于数据流的数据量远大于数据流处理系统的可用内存,不能保证所有数据都能被存储。因此数据流处理系统需要维持一个概要数据结构,用于保留扫描过的信息。生成数据流概要信息的主要方法有:抽样、梗概和大纲数据结构等。
(1)抽样:属于传统的统计学方法,通过一定概率决定数据是否被处理。抽样技术的弊端是,数据流的长度无法预测,并且数据流的流速不稳定。
(2)梗概:是将数据流中的数据做随机投影,从而建立小空间的汇总,其主要缺陷是精度问题。
(3)大纲数据结构:通过应用概要技术生成比原始数据流小得多的数据概要,是当前数据流的概要描述。直方图、小波变换分析和哈希方法都属于大纲数据结构。
2.2 基于任务的技术
在算法与应用方面,基于任务的技术可以在时间和空间上更好地进行数据流的处理,目前主要的基于任务的技术包括:滑动窗口、倾斜时间框架、衰减因子。
(1)滑动窗口:用户往往对最近的数据更感兴趣,因此只需要保留少量最近的数据并对其进行分析,而对于大量的历史数据,只需要保留概要结构。这样,既满足了用户需求,又减少了内存开销。滑动窗口的大小需要用户自定义,但在大多数应用中,该窗口的大小是无法预知的,因此,这是滑动窗口的一个较大的缺陷。
(2)衰减因子:衰减因子是另一种强调近期数据重要性的方式,它衰减了历史数据对计算结果的影响。数据在计算之前,先经过衰减函数的作用,这样数据对计算结果的影响会随着时间的推进而减少。
(3)倾斜时间框架:也称为多窗口技术,滑动窗口与衰减因子只能在一个粒度的窗口上操作。但是,多数应用会需要在不同粒度的窗口上进行挖掘与分析,为此,可以构建不同层次的时间窗口。最近的数据记录在细粒度窗口上,较远的历史数据记录在粗粒度窗口上,这样既满足了需求,又不需要太多内存消耗。
除了上述支撑技术,参考文献[7]还提到了基于算法的自适应技术和近似技术,这些技术本质上都是为了算法能够有更好的效果,在精度与时间折中的状态下,对数据流进行有效的处理。
3 分布式数据流挖掘
随着计算机技术的迅速发展,众多领域内海量、高速的数据飞速增涨,并且需求也趋于多样化与实时性。例如在移动通信领域,电信数据种类繁多,数量巨大,网络承载流量巨大,如果能够对这些数据进行实时挖掘与分析,就可以有效地避免通信诈骗事件的发生。又如在交通领域,路线规划一直是该领域研究的热点,通过对车流量进行实时监测与分析,作出合理的路线规划,可以有效减缓交通压力。这些应用场景的主要特点就是数据量庞大、实时性要求高以及涉及的数学模型复杂。传统的集中式数据流挖掘不能很好地满足上述应用场景的特点,而分布式数据流挖掘却显示出它的优势。
分布式数据流挖掘是指基于分布式流处理系统,实现算法的分布式并行化,达到算法的有效性和时效性。分布式流处理系统采用分布式架构,区别于Hadoop[10]之类的处理平台,其处理能力随着节点数目的增长而扩展,具备良好的伸缩性。并且,大多分布式数据流处理系统分离了计算逻辑和基础模块,系统只负责数据的传输与任务的分配,具体的处理流程和计算单元则由用户自己定义。
在分布式数据流处理系统上实现算法,首先需要根据系统的编程模型设计算法的分布式架构,其次要实现算法的并行化。并行化后的算法能够在分布式平台上取得更好的效果。
3.1 并行化数学模型
算法的并行化指使用多台计算机资源实现算法,节省大量计算时间,能极大地提高算法效率。算法并行化是分布式数据流挖掘顺利进行的一个重要前提。
一般直接编写并行程序是相当困难的,而且各领域使用的串行算法已经相当成熟,所以如何将串行算法转换为并行算法成为研究的重点。参考文献[11]分析了串行算法并行化的可行性并总结了有向带权图模型、集合划分模型和标记AVL树模型三种将串行算法并行化的数学模型。
(1)有向带权图模型
一个串行程序可以抽象为一个有向带权图,程序中的所有函数为构成图的节点,节点的相关程度作为权值,函数之间的调用关系构成图的边,这样的图称为函数调用图。同理,一个函数也可以这样被拆分。
有向带权图分为连通图与非连通图,在函数调用图中,连通图表示各函数之间均存在调用关系,这样的图代表的串行程序是不易并行化的;而非连通图代表的串行程序是较易并行化的。需要对每个连通分支进行不断划分,直到划分至最小原子为止。
(2)集合划分模型
集合划分模型是为了解决如何搜索权值最小的边以及如何基于连通图进行并行划分。运用二元关系的相关知识建立模型,基于有向带权图进行划分。
(3)标记AVL树模型
AVL树,即平衡二叉树,在AVL树中任何节点的两个子树的高度最大差别为一,所以它也被称为高度平衡树。当AVL树增加或者删除节点导致树失去平衡时,AVL树通过旋转使树重新达到平衡。
使用AVL树模型并行化串行算法的前提是,AVL旋转不会影响函数之间的调用关系。在此前提下,基于有向带权图模型,将图中的一个连通分支作为根节点,分解该图。每进行一次分解,AVL树就增加两个子节点,若影响到树的平衡向性,则旋转树,否则继续分解图,最终生成一棵平衡二叉树。树的左子树与右子树代表并行的两部分函数。
3.2 分布式数据流处理系统
本文选取4种具有代表性的分布式数据流处理系统进行介绍,表1对比了这4种分布式数据流处理系统的各项特点。
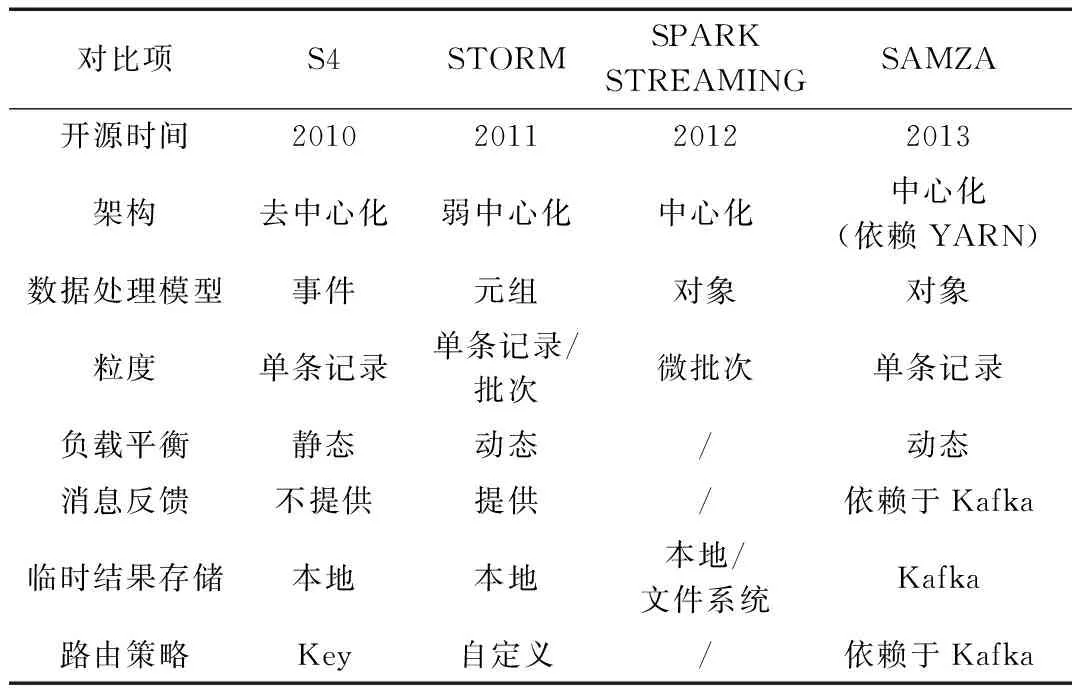
表1 分布式数据流处理系统比较
3.2.1 S4
S4于2010年由Yahoo!公司开源,是一个采用去中心化结构的数据流处理系统,各节点通过ZooKeeper[12]进行协调工作。S4遵循actor设计模式,数据项在S4中被抽象为事件(event),计算单元会以PE的形式存在,每个PE只能处理key值相同的事件。虽然系统的伸缩性和扩展性良好,但缺乏消息处理的反馈机制,无法进行有效的故障恢复等。
3.2.2 Storm
Storm于2011年由Twitter公司开源,是一个分布式、高容错的实时计算系统。Storm实现了实时处理数据流计算,弥补了Hadoop、Spark等批处理系统所不能满足的实时要求。Storm主要分为Nimbus和Supervisor两种组件,这两种组件都是无状态且快速失败的。与S4相同的是Storm通过Zookeeper进行任务分配与心跳检测,不同的是Storm利用消息反馈机制保证数据记录被完全处理。Storm被广泛应用于实时分析、在线机器学习、持续计算、分布式远程调用等领域。
3.2.3 Spark Streaming
Spark Streaming于2012年被开源,它是核心Spark API的一个扩展,Spark Streaming与Spark相同,均采用了RDD(弹性分布式数据集)机制。在数据处理方面,Spark Streaming引入微批次的概念,它并不会像Storm那样一次一个地处理数据流,而是在处理前按时间间隔预先将其切分为一段一段的批处理作业,把对数据流的处理看作是批处理操作。但是由于基于RDD转换的操作能力有限,并且微批次处理增加了数据处理延迟,所以Spark Streaming还有很大的改进空间。
3.2.4 Samza
Samza于2013年由LinkedIn公司开源。与Storm和Spark Streaming不同的是,Samza以一条条消息作为数据流处理的单位。在Samza中,数据流被切分开来,每个部分都由一组只读消息的有序数列构成,而这些消息每条都有一个特定的ID(offset)。该系统也支持批处理,即逐次处理同一个数据流分区的多条消息。尽管Samza的数据传输依赖于Kafka,并且需要依靠Yarn来完成资源调度,Samza的执行与数据流模块却是可插拔式的。
4 结论
本文系统地介绍了数据流挖掘中的数据流模型和支撑技术。结合数据流挖掘技术的发展,对分布式数据流挖掘进行了概述,并且详细地介绍了分布式数据流挖掘所涉及的相关数学模型及数据流处理系统。这些内容对于深入了解数据流挖掘并将其进行实际应用有着重要的意义。
[1] ARASU A, BABCOCK B, BABU S, et al. Stream: the stanford data stream management system[J]. Book Chapter, 2003(26):665-665.
[2] ABADI D J, CARNEY D, ÇETINTEMEL U, et al. Aurora: a new model and architecture for data stream management[J]. the VLDB Journal—the International Journal on Very Large Data Bases, 2003, 12(2): 120-139.[3] NEUMEYER L, ROBBINS B, NAIR A, et al. S4: Distributed stream computing platform[C].2010 IEEE International Conference on Data Mining Workshops. IEEE, 2010: 170-177.
[4] TOSHNIWAL A, TANEJA S, SHUKLA A, et al. Storm@ twitter[C].Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data. ACM, 2014: 147-156.
[5] ZAHARIA M, DAS T, LI H, et al. Discretized streams: an efficient and fault-tolerant model for stream processing on large clusters[C].Proceedings of the 4th USENIX Conference on Hot Topics in Cloud Computing, 2012: 10.
[6] MORALES G D F, BIFET A. Samoa: scalable advanced massive online analysis[J]. Journal of Machine Learning Research, 2015, 16(1): 149-153.
[7] 孙玉芬, 卢炎生. 流数据挖掘综述[J]. 计算机科学, 2007, 34(1): 1-5.
[8] GABER M M, ZASLAVSKY A, KRISHNASWAMY S. Mining data streams: a review[J]. ACM Sigmod Record, 2005, 34(2): 18-26.
[9] 谈恒贵, 王文杰, 李游华. 数据挖掘分类算法综述[J]. 微型机与应用, 2005, 24(2): 4-6.
[10] 谢桂兰, 罗省贤. 基于 Hadoop MapReduce 模型的应用研究[J]. 微型机与应用, 2010,29(8): 4-7.
[11] 吴越. 串行算法并行化处理的数学模型与算法描述[J]. 计算机技术与发展, 2012, 22(5): 14-18.
[12] HUNT P, KONAR M, JUNQUEIRA F P, et al. ZooKeeper: wait-free coordination for Internet-scale systems[C].USENIX Annual Technical Conference, 2010, 8: 9.
A survey of distributed data streams mining technique
Wan Xingui
(School of Computer, Nanjing University of Posts and Telecommunications, Nanjing 210003,China)
The rapid development of Internet information technology has generated a new data model—data stream model. The demands for real-time processing of data stream are emerging in an increasing number of areas, large-scale and high-speed data as well as real-time application of scenarios require the further technological development of data stream mining. This thesis, at its beginning, introduces the common data stream model and then summarizes the supporting technology applied in data stream mining based on the characteristics of the data stream model. Finally, this thesis analyzes the importance and effectiveness of distributed data stream mining technology, presents the parallel algorithm mathematical model and introduces several representative distributed data stream processing system.
data stream model; data stream mining; distributed; parallel; data stream processing system
TP311
A
10.19358/j.issn.1674- 7720.2016.21.002
万新贵. 分布式数据流挖掘技术综述[J].微型机与应用,2016,35(21):8-10,13.
2016-08-10)
万新贵(1991-),通信作者,女,硕士研究生,主要研究方向:流数据挖掘。E-mail:15850795019@163.com。
