基于改进TSVM的未知网络应用识别算法*
2016-12-01李丽娟
李 斌,李丽娟
(石家庄职业技术学院 信息工程系,河北 石家庄050081)
基于改进TSVM的未知网络应用识别算法*
李 斌,李丽娟
(石家庄职业技术学院 信息工程系,河北 石家庄050081)
针对训练集中出现未知网络应用样本的识别问题,提出一种基于改进的直推式支持向量机的未知网络应用识别算法,引入增类损失函数刻画在训练过程中新增的未知应用样本的损失代价,建立TSVM的优化问题并推导其求解过程,使得构造的分类模型能够实现对未知类别样本的识别。通过实际网络数据集进行仿真分析,结果表明所提出的算法在识别未知网络应用的可行性和有效性方面均有良好表现。
支持向量机;直推式学习;未知网络应用;流量识别
0 引言
根据 Internet2 NetFlow组织对骨干网中流量的统计发现:超过 40%的网络数据流属于未知的应用[1],其中恶意代码流量占有相当的比例。针对上述问题,需要设计合理、有效的方法快速准确地识别和分析未知应用流量,进而作出相应的控制,提高网络管理的效率和对网络攻击的反应速度。
网络流量识别方法根据研究对象的不同可分为基于端口号、基于有效负载和基于流统计特征3种主流的方法。由于未知应用流量一般采用动态端口号或者伪端口号进行传输,且应用规范尚未公开,无法获取其载荷特征,使得基于端口号和基于有效负载这2种方法失去了对其识别的能力。而基于流统计特征方法通过分析网络流的统计特征,可以实现对未知应用的识别。然而,传统的基于流统计特征的机器学习方法对未知应用的识别效果要优于前两者方法,但严重依赖于训练分类器的样本集合。
文中提到的类型应用已知简称为已知类,应用类型未知简称为未知类。根据训练集中是否存在未知类样本,将基于流统计特征的未知应用识别方法大致分为3类:(1)有监督方法[2],通过训练集中已知类样本学习构造一个判决边界,并设定临阈值,实现对待识别样本进行预测,测试样本超出阈值的则认为属于未知类。由于缺乏未知应用信息,存在判决边界模糊和临阈值设定困难问题,识别效果一般。(2)无监督方法[3],通过聚类分析将混合的训练样本集聚成几个簇,实现对已知类和未知类的识别。由于未能有效利用已知类样本的类别信息,聚类结果面临解释困难。(3)半监督方法[4,5],可以有效利用无标记样本辅助已知类样本学习构造分类模型,实现对未知样本的识别。如果未标记样本出现未知类的样本,会导致该方法对已知类的效果大大下降,也无法识别出新增未知类的样本。
针对上述存在的问题,本文提出了一种基于改进的直推式支持向量机的未知网络应用流量识别算法(UPCTSVM),通过引入增类损失函数刻画未知类的损失代价,构造的判决边界能够实现对未知应用的识别。实验结果表明,该方法能够在保证已知类别的识别准确率情况下,有效地识别出未知类数据。
1 问题描述
本文解决的新增类识别问题可以描述为如下形式:已知原始网络数据集中包含K类已知类和M类未知类。训练样本集为,其中,yi∈Y={1,2,…,K},属于已知类。测试样本集为,含有新增类的样本信息,其中,yi∈YO={1,2,…,K,K+1,…,K+M}。由于这些未知类样本信息在训练过程中是不可预见的,那么该新增类问题的目标函数可以表示为 f(x):X→Y′={1,2,…,K,novel},其中 novel表示样本 x属于新增加的类别。该目标函数最小化期望错误为,其中 H为 hypnosis空间,误差函数定义如下:
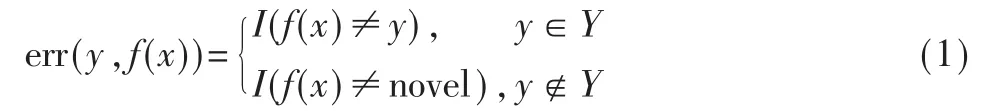
其中 I(·)表示示性函数,若表达式(1)成立,其值则为 1,否则为0。
根据最大分类间隔理论,所有类别都可以利用最大间隔进行判定,所以利用未标记样本帮助训练已知类的最大间隔,可以实现识别已知类和未知类。那么,在增加Du这部分样本后,该新增类识别问题中用来识别未知类样本的分类函数可以描述为:

其中:f(x)∈H代表分类函数,Ih(f,DL)和 Iu(f,Du)分别代表训练集中标记样本和辅助训练的未标记样本的损失函数,Inovel(f,DL)为新增类别样本的损失函数。C1、C2和 C3为影响因子,用于平衡3种不同样本在目标函数中的损失权重。
2 工作原理
假设独立带标记样本训练集(x1,y1),…,(xL,yL),xi∈Rm,yi∈{-1,+1},其中 xi为标记样本向量,yi为样本所属类别,+1表示正类,-1表示负类。另一组无标记样本集:,辅助训练分类模型。其中+b为线性分类函数,其中 θ=(w,b)为分类模型的参数,w为最优超平面的向量,b为偏置,得到 TSVM的优化问题为:

其中ζi和ζj分别代表标记样本与无标记的损失式。为了解决多分类问题,需要对式(3)进行扩展,本文采用LEE Y等[6]提出的铰链损失函数对多类数据进行刻画,引入增类损失函数对无标记样本集中新增的未知类样本进行刻画得到UPCTSVM的优化问题,然后需要对该优化问题训练 K次,每次将某个已知类判为正类(yi=+1),而剩下的所有类别判为负类(yi=-1)。其中 3类损失函数分别代表为:

其中损失函数Inovel是用来调整控制判决边界的移动,使得最大分类间隔最小化,I+、I-分别是训练集中的正例和负例。
通过式(2)和式(4)训练得到一个 K+1分类器,得到待测样本x进行的判别函数为:

当fnovel为 0时,将测试样本 x判为 novel。
为了求解上述的优化问题,需要为Inovel(f,DL)添加一个约束条件:
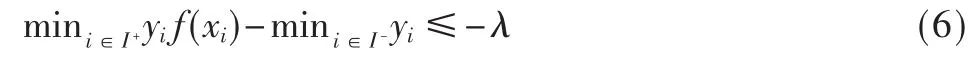
其中参数λ>0,用来控制正类样本影响判决边界的动态调整方向,该约束条件转换成:

由于 Iu(f,Du)采用裁剪的对称铰链损失函数 max(0,1-|z|)≈Rs(z)+Rs(-z)+const,导致该优化问题仍很复杂,Rs(z)min(1-s,max(0,1-z)),s∈(-1,0]。为了更好地区别Ih和 Iu两种损失函数,Rs(z)也可以用 Rs(z)=H1(z)-Hs(z),Hs(z)=max(0,s-z)来表示。
通过前面分析,式(2)的优化问题转化为下面最小优化问题:

其中:J1(θ)为凸函数,J2(θ)为凹函数,当 L+1≤i≤L+U时,yi=+1;当L+U+1≤i≤L+2U时,yi=-1,且当1≤i≤U时,xL+U+i=xL+i。

由于在训练集中正类样本在Du中所占比例远小于DL,为了防止将未标记样本都错归为一类,提出约束条件:
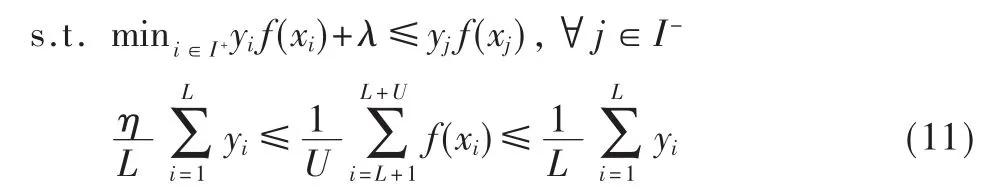
引入文献[7]中的凹凸求解方法对目标函数进行优化,凹凸求解方法是通过求解一系列不同的子问题,包括凸问题和非凸的问题。在凹凸问题求解过程中每次迭代需要求解下面的子问题:

该子问题是由一个凸函数和一个线性函数组成,注意到在式(3)仍存在一个非凸约束条件,提出选择优化方法来求解该子问题。当第t+1次迭代,用固定值代替,式(12)可以转化为标准的SVM对偶问题及约束条件:

其中N=L+2U+2+|I-|为对偶变量总数。当 yif(xi|θt)<s,L+1≤i≤L+2U时,βi=C2,否则为 0。G∈RN×N为核函数矩阵,Gij=〈φ(xi),φ(xj)〉。前面 L+2U个样本为已知类的训练样本,后面2+|I-|个样本定义为:
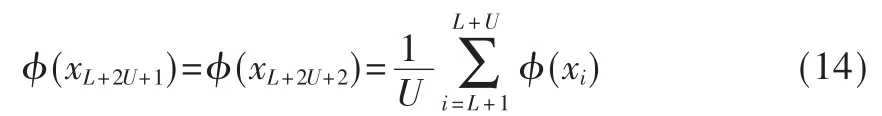
3 实验和分析
3.1数据集和评价指标
为了验证UPCTSVM算法的分类性能,本文将采用2个真实的网络数据集进行仿真测试,分别是MAWI实验室提供的WIDE公开网络数据集[9]和校园网截获的网络数据CND。WIDE数据集分别是采集于2010年4月13日共4个小时的流量和2012年3月30日共5个小时的流量;CND数据集在校园主干网采集4个小时的流量。提取流行的9种应用层协议对文中算法的性能进行评估,分别为 HTTP、SSH、SSL、FTP、SMTP、POP3、SMB、DNS和IMAP。为了减少样本分布不均衡的影响,样本超过5 000的类随机抽取5 000个样本,小于5 000的类保持原有样本,组成一个含有 32 978个样本的实验数据集,详细信息如表1所示。实验中,本文提取20个单向流的统计特征作为代表样本信息,然后利用特征选择算法剔除不相关或冗余的特征,得到其中的9个特征,详细的描述如表2所示。在实验过程中,将HTTP、SSL、FTP、SMTP、POP3、DNS和 IMAP分别标记为序号 1~7。各类样本按照一定比例,分别组成训练样本集、未标记样本集和测试样本集。
为了验证UPCTSVM算法的有效性,将与其他3种算法(OVR-SVM[10]、MOCSVM[4]和 MULTIpLE[5])分别进行性能比较,采用整体识别准确率(Overcall-Precision)和调和均值(F-measure)作为评价指标。每次实验重复10次,取其平均值作为实验结果。

表1 实验数据集的详细信息

表2 选择后的特征详细信息

图1 各类算法在不同训练集上的整体识别准确率
3.2实验结果分析
(1)测试1:不同算法的识别性能比较。实验过程中,随机选择5种应用作为已知类,剩余2种作为未知类进行测试,训练集中各类标记样本数为 200,未标记样本为200,剩余作为测试样本。图1和图2分别表示各类算法在不同训练集上的整体识别准确率和未知类的F-measure值。从结果可以看出,本文提出的算法利用未标记样本辅助训练分类模型可以有效准确地识别出新增未知类数据,其整体识别准确率和未知类的识别效果均优于其他算法。因为OVR-SVM算法无法识别新增的未知类,在判别过程中未知类样本都被误判为已知类,导致其识别效果最差;另外2种算法虽然都具备一定的未知类识别能力,但未能有效利用未标记样本中未知类的样本信息,使得整体识别效果和未知类的F-measure值也都比较差。
(2)测试 2:不同未标记样本对 UPCTSVM算法的识别性能的影响。图3和图4分别表示训练集中标记样本数为100和200的情况下,不同的未标记样本辅助训练得到的整体识别准确率和新增未知类的F-measure值的曲线图。结果显示,该算法的整体识别准确率和未知类的F-measure值均随着辅助未标记样本的增加而逐渐提高,说明在训练集标记样本数一定的情况,含有未知类的未标记样本的增加有助于提高分类器识别未知类样本的能力。

图2 各类算法在不同训练集上的未知类F-measure值

图3 算法的整体识别准确率

图4 未知类的F-measure值
4 结束语
针对训练集中出现未知应用的识别问题,本文提出一种改进直推式支持向量机的未知应用识别算法,通过获取与训练集相同网络环境下的未标记样本,包含着未知应用的数据样本,用来辅助训练分类模型,引入增类损失函数刻画新增未知类样本的损失代价,使得构造的判决边界能够识别出未知应用样本。实验结果表明,与其他算法相比,本文提出的算法在识别未知网络应用的可行性和有效性方面均有良好表现。
[1]王一鹏,云晓春,张永铮,等.基于主动学习和SVM方法的网络应用识别技术[J].通信学报,2013,34(10):135-142.
[2]KUZBORSKIJ I,ORABONA F,CAPUTO B.From n to n+1:Multiclass transfer incremental learning[C].Proce.of the 26th IEEE Conference on Computer Vision and Pattern Recognition,2013:3358-3365.
[3]王变琴,余顺争.未知网络应用流量的自动提取方法[J].通信学报,2014,35(7):164-172.
[4]ZHOU Z H,LI M.Tri-training:Exploiting unlabeled data using three classifiers[J].Knowledge and Data Engineering,IEEE Transactions on,2005,17(11):1529-1541.
[5]李洋,方滨兴,郭莉,等.基于直推式方法的网络异常检测方法[J].软件学报,2007,18(10):2595-2604.
[6]LEE Y,LIN Y,WAHBA G.Multi-category support vector machines,theory,and application to the classification of microarray data and satellite radiance data[J].Journal of the American Statistical Association,2004,99(465):67-81.
[7]COLLOBERT R,SINZ F,WESTON J,et al.Large scale transductive SVMs[J].The Journal of Machine Learning Research,2006,7(8):1687-1712.
[8]BOTTOU L,LIN C J.Support vector machine solvers[J].Large Scale Kernel Machines,2007,3(1):301-320.
[9]WAWI Working Group.Packet traces from WIDE backbone [EB/OL].[2016-03].http://mawi.wide.ad.jp/mawi/.
[10]ALLWEIN E L,SCHAPIRE R E,SINGER Y.Reducing multiclass to binary:A unifying approach for margin classifiers[J].The Journal of Machine Learning Research,2001,1(2):113-141.
Unknown network applications traffic classification algorithm based on improved TSVM
Li Bin,Li Lijuan
(Department of Information Engineering,Shijiazhuang Vocational Technology Institute,Shijiazhuang 050081,China)
An unknown network protocol classification method based on improved transductive support vector machine learning is proposed to solve the problem of classifying augmented class when unknown network protocol data appeared in the training process.This method uses the large number of unlabeled samples to assist training classification model,where the augment loss of new unknown class samples is described by the loss augment function.TSVM(Transductive Support Vector Machine)optimization model is established and its solving process is deduced,so the decision boundary can classify the unknown class samples.The performance of the proposed method is examined in simulations with real network data sets.The experimental results illustrate the feasibility and effectiveness of the unknown network applications classified by this proposed method.
support vector machine;transductive learning;unknown network protocol;traffic classification
TP393;TN918.91
A
10.16157/j.issn.0258-7998.2016.09.025
国家自然科学基金(61309007);国家安全重大基础研究项目(613148)
2016-03-30)
李斌(1982-),女,硕士,讲师,主要研究方向:数据库技术、软件可靠性。
李丽娟(1978-),女,硕士,讲师,主要研究方向:软件技术、网络安全。
中文引用格式:李斌,李丽娟.基于改进TSVM的未知网络应用识别算法[J].电子技术应用,2016,42(9):95-98.
英文引用格式:Li Bin,Li Lijuan.Unknown network applications traffic classification algorithm based on improved TSVM[J].Application of Electronic Technique,2016,42(9):95-98.
