高效匹配引擎的设计与实现*
2016-11-30麦涛涛潘晓中李晓策
麦涛涛,潘晓中,李晓策
(武警工程大学 电子技术系,陕西 西安710086)
高效匹配引擎的设计与实现*
麦涛涛,潘晓中,李晓策
(武警工程大学 电子技术系,陕西 西安710086)
针对软件模式匹配引擎速度慢、占用系统资源大的问题,提出了一种基于 Bloom Filter的 FIBF结构,结合FPGA NIOSII微处理器(MUP),设计了软硬核相结合的匹配引擎方案。引擎通过FIBF过滤过滤掉大部分正常数据,将过滤出的可疑字符串输入到NIOSII软核进行精确匹配,两者之间通过一个指针产生器连接,整个系统以流水线方式工作。FIBF结构资源消耗低,n-FIBF并行处理,系统引擎可以达到较高的吞吐率。实验表明,在使用相同资源的情况下,本方案系统吞吐率要优于其他算法。
FIBF;指针产生器;NIOSII微处理器;流水线方式
0 引言
高速网络在提供便利的同时也带来很多安全问题,数据流管理系统是目前解决网络安全问题最主要的防御手段[1]。基于软件的防御系统可以满足普通用户的应用需求,但是对于网络传输速度达到 G bit/s的企业级网络来说,系统容易出现丢包、漏检的情况,且较大资源占用量也大大影响了整体系统的性能。因此设计专用的硬件匹配引擎成为防御系统的发展趋势。
随着网络中恶意数据的种类急剧增加,使得将匹配的特征码全部存到内部存储器成本也越来越高,但若使用外存又将大大降低系统吞吐率。Bloom Filter(布鲁姆过滤器)作为一种精简的信息表示方案,在实现高速的数据查找的同时可以降低存储资源的消耗。
基于标准 Bloom Filter和改进 Bloom Filter[2-7]的匹配方案有很多,例如文献[8]使用双Hash的方案,利用FPGA中的双端口存储器实现特征码Hash值的存储和查找,同时可以实现数据的在线更新,但是双Hash方案没有解决Bloom Filter假阳性误判(即不属于集合中的元素而误判为属于集合中)[9]问题,较高的错误率将大大降低系统的可靠性。文献[10]提出了一个基于Bloom Filter和位拆分状态机的多模式分步匹配引擎设计方案,可以实现数据流的高速精确检测,方案的精确匹配部分使用选择位状态机,在检测时依然占用较大内存。文献[11]使用窗口折叠 Bloom Filter与软件结合的设计方案,方案提高了系统的资源利用率,但系统匹配精度不高,同时软件低频率也大大影响了系统的吞吐率。文献[12]构造了一种特殊结构的Bloom Filter,其向量空间存储值并非 0或1,而是由计数器和编码值两部分组成,在匹配中,通过这两部分值可以恢复匹配位置存储的数据,解决了传统Bloom Filter假阳性误判问题,该方案仅适用于匹配短关键字。
本文将 Bloom Filter与FPGA系统软核相结合,设计了一种资源消耗少、匹配速度快的软硬核结合的分步匹配引擎方案。在系统部分匹配中,文本基于标准Bloom Filter原理,设计了 FIBF(Finite-Input Bloom Filter),FIBF对特征码长度不进行区分,通过对固定长度特征前缀的高速扫描,过滤出可疑数据;而后,使用FPGA软核微处理NiosII[13]和片外存储器SDRAM对数据进行精确扫描。
1 Bloom Filter原理
Bloom Filter可以实现高速数据传输下的数据查找,算法实质是将集合中的数据通过K个Hash函数映射到位串向量中。与传统的Hash表的链式存储结构相比,Bloom Filter过滤器的 Hash表查找快,占用的存储空间大小与集合规模和集合中数据位宽无关,仅与映射后向量的位数相关。
Bloom Filter数据结构如图1所示。设数据集合 C= {c1,c2,…,cn},其 n个元素通过 k个相互独立 Hash函数h1,h2,…,hk映射到长度为 m的位串向量 V中,Hash函数的取值范围为{0,1,…,m-1}。对字符串c′进行检测,若输出值为1,则元素c′是可能需要查找的字符串,否则肯定不是。
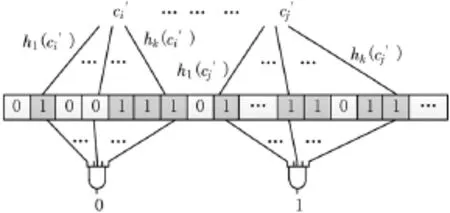
图1 BF结构图
Bloom Filter存在假阳性误判,因而,在应用中需要对查询误判率进行评估,设计出符合应用需求的Bloom Filter[9]。
假设Hash函数取值服从均匀分布,则当集合中所有元素都映射完毕后,向量V中任意一位为0的概率p′为:

不属于集合中的元素被误判属于的概率(即误判率) f为:
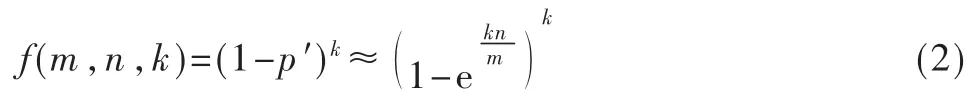
式(2)两侧对k进行求导,令导数为0,得:
当k=kmin时,,此时元素出现误判的最小概率fmin为:
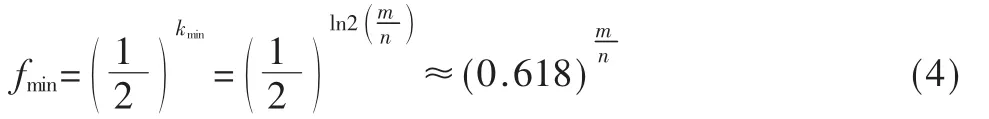
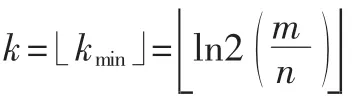
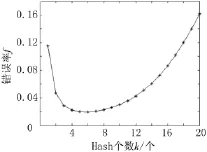
图2 误判率f与Hash个数k的关系
若设计时对k个Hash函数,每个Hash函数使用独立的向量,则向量中某比特位为1的概率,此时元素出现误判的概率为:

取 n=2 000,f′=fmin=0.019 6,如图3所示,图中单个向量空间大小m随着k成指数递减,但是所需的存储器总量m′随k成“√”变化,当Hash函数个数k=4时所需的存储空间总量最小。
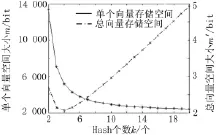
图3 Hash个数k与单个向量空间大小m及总向量空间大小m′关系图
2 高效过滤器设计
2.1过滤系统结构
病毒过滤系统的总体设计模型如图4所示,系统由硬件系统和MPU系统两个部分组成。系统的工作流程如下:
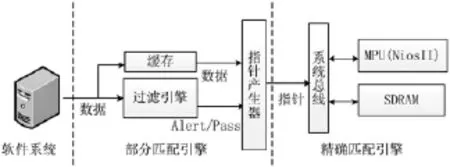
图4 过滤系统设计模型
(1)软件系统抓取数据包或者读入磁盘信息,此过程由软件扫描引擎来完成。例如 ClamAV扫描引擎,其将文件数据读入,对文件进行有效性扫描,这个过程主要用于检测文件大小是否越界、文件是否可以打开,然后将有效数据输出。
(2)部分匹配引擎对输入的文本数据进行高速扫描,此过程由硬件过滤系统完成。硬件过滤系统将数据流与特征码前缀进行匹配,将匹配的可疑数据经指针产生器处理后输入到精确匹配模块。
(3)精确匹配引擎对可疑数据进行深度过滤,此过程由MPU完成。MPU根据指针产生器给出的地址读取特征码,使用KMP算法对文本进行匹配,若前缀匹配失败则匹配产生虚警,精确匹配结束。
2.2FIBF设计
FIBF由 c个移位寄存器和一个 Bloom Filter组成,如图5。数据由输入端口输入到移位寄存器中,移位寄存器在每个时钟上升沿都要进行一次右移操作,同时将寄存器中的数据输出到Bloom Filter中。
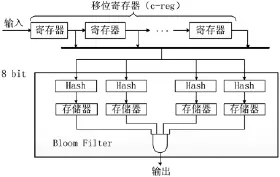
图5 FIBF结构图
FIBF与标准Bloom Filter引擎设计,其每个结构中只使用一个Bloom Filter,检测特定长度8c bit的文本信息。N个FIBF并行操作可以同时查找N×8c bit信息,图6所示是使用3个FIBF构成的部分匹配引擎模型,每个FIBF扫描6 B信息。
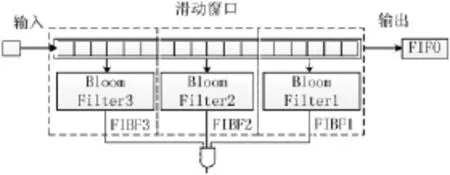
图6 3-FIBF并行部分匹配引擎模型
在Bloom Filter设计中,选择Hash函数是非常重要的一个环节。在本设计中,Hash函数的选择遵循以下两条原则:
(1)Hash函数要适合硬件实现。硬件电路具有强大的逻辑运算能力,因此在算法选取时要尽量多使用逻辑运算,降低算术运算量。
(2)输出结果要与每一比特位相关,以降低 Hash冲突的概率。
文献[14]给出的 Hash函数构造方案H3很适合硬件实现。对于有 a个比特的字符串 S={s1,s2,…,sa},通过H3算法构造的 Hash函数可以表示为:
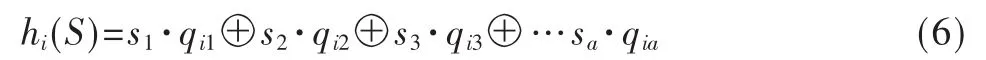
式中,“·”为与门,“⊕”为异或门,q表示一个 a×a′的随机数阵列。矩阵行数a对应输入字符串的比特位数,列数 a′对应Hash值的位数,a′的值由 Bloom Filter中向量空间大小决定。
2.3指针产生器设计
当 3-FIBF部分匹配引擎发生匹配时,FIBF2和FIBF3并不能确定已匹配的前缀是其对应子串的前缀,即在匹配中会出现排列组合的情况,这将大大增加匹配的误判率。而精确匹配耗时多效率低,若产生的误判率过高,精确匹配逐一匹配特征码将大大影响整个系统的吞吐率。指针产生器的设计可以检测匹配的多个子串是否可能对应于某一特征码,同时产生精确匹配中特征码的地址,提升精确匹配效率。指针产生器设计如图7所示。
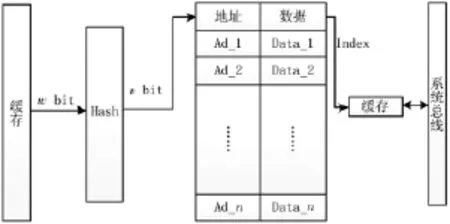
图7 指针产生器
指针产生器从缓存中取出w bit的可疑数据,经过一次Hash变换得到v bit的Hash值,以此Hash值作为地址到存储器中查找可疑数据对应特征码在SDRAM中的地址。若查找的地址空间的数据为全“1”,则表示匹配产生虚警。
例如,设特征库集合中元素个数为n=7,使用2-FIBF扫描数据,每个FIBF扫描2 B,则匹配的前缀长度为4 B。经 Hash函数 H(b)=bQ[14],n个前缀经 Hash运算后产生的地址、指针对应关系如图8所示。b是由缓存数据表示的1×16向量,Q是一个16×4的随机向量。
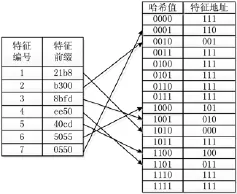
图8 特征前缀与Hash值、指针对应关系
对于特征编号为“1”的特征,其前缀为“21b8”,经Hash函数运算后得到的Hash值为“1010”,把 Hash值作为地址到存储器中查找对应的位置的数据,对应数据为精确匹配中特征码存储的地址。若输入数据为“2100”,在FIBF检测中输出发生匹配,此时指针查找器读取缓存中的“2100”,经 Hash变换后产生 Hash值“1011”,对应的特征地址为“111”,可判断产生虚警。若输入数据为2150,在FIBF检测中同样发生匹配,但是经指针查找器输出的地址数据为“101”,未排除虚警,但是由于给出的地址对应的特征前缀为“5055”,在精确匹配中,首字母匹配失败,则直接结束匹配。
Hash实现多对少映射,上边例子使用的Hash函数由H3算法构造,当特征集合中元素数目增多,且字符串数据随机性比较差的情况下,H3算法产生的碰撞概率比较大,此时可以采用文献[15]提出的多 IGU(Index Generation Unit)并行方案。IGU的预处理阶段首先使用特征码中的比特位构成二维数组,数组中的数据对应特征码的地址指针。通过对数组进行分析,选择合适的X、Y坐标的位进行异或操作,以产生的值作为Y值,使用Y可以唯一地确定指针。对于少部分产生碰撞的数据,文献[15]通过设计一个额外的IGU存储器存储这些数据。
2.4地址存储空间设计
Bloom Filter必须使用一定的存储空间来存储向量,设计好的存储设计方案可以提高内存利用率并提高系统吞吐率。在模式匹配中,存储大容量的特征码数据内部存储器无法实现,只能使用片外存储,但是对于数据量比较小的向量,若使用片外存储器,不仅降低了系统频率,而且降低了内存使用率,浪费FPGA资源。
为了实现数据的快速的查询,设计中可以2个 Hash函数共用双端口 RAM存储器[14],也可以使用单口RAM,每个RAM对应一个Hash函数。通过实验分析,一个双端口RAM占用的资源量是一个单口RAM资源占有量的2倍多,并且双口RAM扇出比较大,延迟多,同时增加了发生虚警的概率,所以本文选择使用单口RAM进行数据存储。
3 性能实验及分析
实验选取 Clam AV特征库 main.db类中2 000个特征码,部分匹配为对应特征码的12 B前缀,可接受的误判率 f=0.019 6,根据式(5)和图3可计算出当k=4时每个 FIBF所需的总存储空间最小为 25 093 bit,此时单个向量空间大小为 5 019 bit,但是由于存储器空间大小为2的幂次方,所以k=4时每个Hash函数的实际占用空间大小为 8 192 bit,这使得总存储空间大小增大到32 768 bit。而取k=6,单个向量大小为3 858 bit,存储所需的存储器大小为4 096 bit,总存储空间为24 576 bit<32 768 bit。引擎使用 2个 FIBF并行操作,每个 FIBF检测长度为6 B。输入本文为“ca21b8005a”检测前缀的FIBF仿真波形如图9。数据输入以ASCII形式,向量输出为高电平表示其对应的Hash空间发生匹配,只有当所有的向量空间输出全为高电平,输出信号“result”才为高电平。从图中可以看出“21b800”为检测出的特征码前缀。

图9 FIBF仿真波形图
实验使用ALTERA低成本Cyclone II系列的开发平台。第一步部分匹配,每个FIBF存储2 000个特征码的6 B关键字需要使用6个M4K RAM,总的存储器消耗量为27 648 bit,单字节输入的最大工作频率为 260 MHz。指针产生器将 2 000个特征码的地址数据存储到一个12输入、11输出的储存器,使用11个M4K。第二步精确匹配,全部特征码存储在外部存储器 SDRAM中,匹配算法使用 NiosII/f嵌入式软核,使用 4002 LE,工作频率为100 MHz。
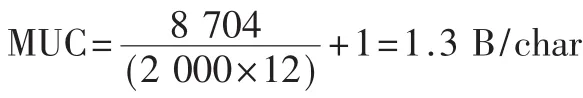
为了与其他算法相比较,使用标准化吞吐率Th/ MUC[16],结果如表 1所示,Th表示引擎的吞吐率单位是Gb/s,Pattern表示存储的特征码的数目,Tool表示使用的硬件器件。
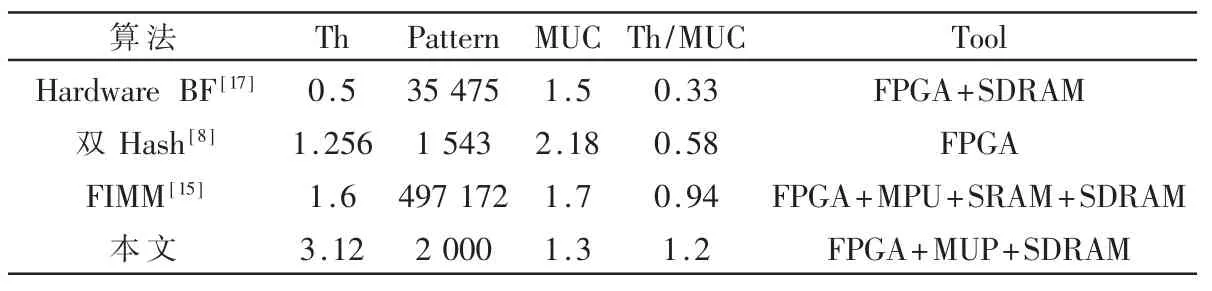
表1 本文算法与其他算法性能比较
4 结论
本文提出了一种结合了 Bloom Filter以及 FPGA软硬核的高效匹配引擎设计方案。方案使用分步匹配的方法,使用 Bloom Filter结合硬件高度并行的特点一次过滤掉大部分正常数据,而后系统MUP通过指针定位精确匹配特征码在SDRAM中的位置,实现快速的精确匹配。通过流水线的方式,设置缓存空间,将软硬件模块相连接,使系统可以实现高速网络下的数据精确检测。实验中 2-FIBF过滤系统吞吐率达到 3.12 Gb/s,完全可以满足千兆网络的需求,通过多个FIBF并行同时增大FIBF检测窗口大小,可以实现更高传输速率网络中的数据检测。
[1]徐东亮,张宏莉,张磊,等.模式匹配在网络安全中的研究[J].电信科学,2015,31(3):115-123.
[2]BONOMI F,MITZENMACHER M,PANIGRAHY R,et al. An improved construction for counting Bloom Filters[M]. Algorithms-ESA 2006.Springer Berlin Heidelberg,2006.
[3]MITZENMACHER M.Compressed Bloom Filters[J].IEEE/ ACM Transactions on Networking(TON),2002,10(5):604-612.
[4]肖明忠,代亚非,李晓明.拆分型 Bloom Filter[J].Acta Electronica Sinica,2004,32(2):241-245.
[5]GUO D,WU J,CHEN H,et al.Theory and network applications of dynamic Bloom Filters[C].INFOCOM,2006:1-12.
[6]XIE K,MIN Y,ZHANG D,et al.A scalable Bloom Filter for membership queries[C].Global Telecommunications Conference,2007.GLOBECOM'07.IEEE,2007:543-547.
[7]叶明江,崔勇,徐恪,等.基于有状态 Bloom Filter引擎的高速分组检测[J].软件学报,2007,18(1):117-126.
[8]郑尧.硬件防火墙中多模式匹配算法的设计与实现[D].哈尔滨:哈尔滨工业大学,2009.
[9]谢鲲,文吉刚,张大方,等.布鲁姆过滤器查询算法[J].软件学报,2009,20(1):96-108.
[10]刘威,郭渊博,黄鹏.基于 Bloom Filter的多模式匹配引擎[J].电子学报,2010,38(5):1095-1099.
[11]骆潇,郭健,黄河.基于 Bloom Filter的多模式匹配优化设计和硬件实现[J].电信技术研究,2011(5):8-13.
[12]XIONG S,YAO Y,CAO Q,et al.kBF:a Bloom Filter for key-value storage with an application on approximate state machines[C].INFOCOM,2014 Proceedings IEEE.IEEE,2014:1150-1158.
[13]吴厚航.爱上 FPGA开发特权和你一起学NIOS II[M].北京:北京航空航天大学出版社,2011.
[14]RAMAKRISHNA M,FU E,BAHCEKAPILI E.Efficient hardware hashing functions for high performance computers[J].Computers,IEEE Transaction on,1997,46(12):1378-1381.
[15]NAKAHARA H,SASAO T,MATSUURA M,et al.A virus scanning engine using a parallel finite-input memory machine and MPUs[C].Field Programmable Logic and Applications,2009.FPL 2009.International Conference on. IEEE,2009:635-639.
[16]NAKAHARA H,SASAO T,MATSUURA M,et al.The parallel sieve method for a virus scanning engine[C]. Digital System Design,Architectures,Methods and Tools,2009.DSD'09.12th Euromicro Conference on.IEEE,2009:809-816.
[17]ATTIG M,DHARMAPURIKAR S,LOCKWOOD J.Implementation results of Bloom Filters for string matching[C]. IEEE Symposium on Field-Programmable Custom Computing Machines(FCCM’04),2004:322-323.
The design and implementation of high-performance matching engine
Mai Taotao,Pan Xiaozhong,Li Xiaoce
(Department of Electronic Technology,Engineering College of the Chinese Armed Police Force,Xi′An 710086,China)
According to the problem that the pattern matching engine based on software having slowly matching-speed and occupying large system resources,this paper proposed a FIBF structure based on Bloom Filter.Using the FPGA NIOSII microprocessor (MUP),a matching engine combination of hard and soft core is designed.Though FIBF,the engine filtered out most of the normal data,then sent the suspicious string to the precise matching module.The FIBF module and the precise matching module were connected together by an index generator.The whole system was performed in pipeline method.The FIBF has low consumption of hardware resource.N-FIBF process in parallel can achieve high system throughput.Simulation results show that this engine is superior to other algorithms by using the same resources.
FIBF;index generator;NIOSII MUP;pipeline method
TP391
A
10.16157/j.issn.0258-7998.2016.05.024
国家自然科学基金项目(61402531,61309022)
2015-12-19)
麦涛涛(1992-),男,硕士研究生,主要研究方向:嵌入式系统、网络安全。
潘晓中(1964-),男,教授,主要研究方向:信息研究与安全。
李晓策(1991-),男,硕士研究生,主要研究方向:可信计算。
中文引用格式:麦涛涛,潘晓中,李晓策.高效匹配引擎的设计与实现[J].电子技术应用,2016,42(5):85-89.
英文引用格式:Mai Taotao,Pan Xiaozhong,Li Xiaoce.The design and implementation of high-performance matching engine[J]. Application of Electronic Technique,2016,42(5):85-89.
