近似重复视频检索方法研究*
2016-11-30余时强张为华
余时强,张 铮,张为华
(1.复旦大学 软件学院,上海 201203;2.复旦大学 上海市数据科学重点实验室,上海 200433;3.解放军信息工程大学 数学工程与先进计算国家重点实验室,河南 郑州 450001)
近似重复视频检索方法研究*
余时强1,2,张铮3,张为华1,2
(1.复旦大学 软件学院,上海 201203;2.复旦大学 上海市数据科学重点实验室,上海 200433;3.解放军信息工程大学 数学工程与先进计算国家重点实验室,河南 郑州 450001)
随着互联网的飞速发展,越来越多的视频被上传和下载,然而这些海量的视频中有很大的比例是近似重复的,这些近似重复的视频会给版权控制、视频检索准确性等造成一定影响,同时也会增加运营商的存储和处理成本。如何在大规模的视频集中找出近似重复的视频变得日益重要。本文对近几年关于近似重复视频检索方面的相关工作和研究成果进行了深入调研,详细论述了当前近似视频检索技术的现状及关键技术,并对其发展进行了展望。
近似重复视频;视频特征;视频检索
0 引言
随着社交媒体 Web 2.0飞速膨胀式的发展,大量的视频被上传到互联网上,这些视频被下载、观看、编辑,重新被上传到网上,因此互联网上充斥着大量内容相近的视频。根据comScore的数据分析,2008年11月时,互联网上的视频总量已达126亿个,而到2009年1月则达到了148亿个,如此短短的3个月时间内视频总量就有17%的增幅。通过Wu[1]的分析,可以知道通过24次基于YouTube,Google Video和 Yahoo Video的视频查询,平均有27%的视频,有最高可达93%的近似重复内容。这些数据表明互联网上存在海量的近似重复视频。
大量存在的近似重复视频会带来诸多的问题,例如视频版权保护和视频检索结果准确性等。由于无处不在的网络,拥有版权控制的视频可能会被重新编辑、修改然后重新发布,所以视频版权商经常会发现自己的视频在没有经过允许的情形下就被修改并且发布到互联网上,这会给他们的利益带来巨大的损失。同样,大量近似重复视频的存在也会影响视频检索系统的准确性。很多时候在网上搜索某一个视频,其实想要得到返回的结果是那些与之相关的原始视频,但是往往搜索结果靠前的是某个视频和它的近似重复视频,而另外那些与关键词相关的原始视频排名却靠后,极大地影响着检索的效果。同时大量近似重复的视频也会带来大量的存储开销。
对视频不同程度的编辑会给近似重复视频的提取造成不同的影响,近似重复视频的准确查询仍然存在着巨大的挑战。虽然可以通过给视频添加标签、注释分类等文字信息帮助提取过程,但是此类方法不够准确,而且提取结果较大程度上取决于标记的准确性。另外一种则是基于视频内容的近似重复性鉴定。当前基于内容的近似重复视频提取方法整体可分成两大类:全局特征提取方法和局部特征提取方法。全局的特征首先通过提取关键帧特征,然后通过空间、时间、颜色等模型整合这些帧的特征信息构成多维向量,视频之间的比较则为全局特征的匹配。局部特征方法则通过提取关键帧的局部特征(如 SIFT[2]、PCA-SIFT[3]特征向量)信息,来帮助查询近似重复视频。
全局特征方法提取的特征信息较局部特征方法更加精简,因此在存储和特征匹配的阶段能够节省大量资源,但是全局特征信息对于视频的变换较为敏感,在变化较大的情形下不能准确地提取近似重复视频。局部特征虽然在大量变形的情形下有较好的提取效果,但是计算复杂性和大量的存储开销使其在真实应用中实用性不高。
本文从全局特征和局部特征的准确性和计算性能出发,分析了当前主流方法的优缺点,并在此基础上对近似重复视频的发展方向进行了展望。
1 近似重复视频概念
近似重复视频是那些和原视频几乎一样,但是在文件格式、编码参数、光度变化(包括颜色以及光照变化)、编辑方式(包括插入水印、边框等)、长度或者某些特定变化下(例如帧的增加和删除等)有所不同。所以可以认定这些近似重复视频和原视频大体一样。
重复视频是近似重复视频的一种,且重复视频包含的信息和原视频基本一样,这并不意味着重复视频在像素层面上和原视频一模一样,而是说包含的场景、任务一样,没有添加新的信息。而且判断两个视频是否重复取决于比较的角度。例如有些版权控制的场景甚至需要判断视频中的某一帧是否和其他视频一样,而视频搜索过程中视频是否重复则是通过视频播放的整体内容而定的。本文所述的重复视频是近似重复视频的一种,在检索方法中并不区别对待,因为无论是重复视频还是近似重复视频,都会被检索出来而且排名较高。原始、重复、近似重复视频概念图例如图1所示。

图1 原始、重复、近似重复视频概念图例
2 近似重复视频检索方法
视频作为多帧图像在时间轴上的累加,图像领域的识别和检索方法也同样可以运用在近似重复视频检索中。近似重复视频的检索整体分成3个部分:视频特征的生成、视频特征的管理、视频特征的匹配。
给定一个查询视频,并且需要从视频数据库中检测出相应的近似重复视频,首先需要对视频库中的所有视频进行特征提取,根据检索需要采用相应的特征,然后再对这些视频特征采用特定数据结果进行管理,例如树形或者局部哈希的方法等。这个阶段属于检索过程中的离线过程,在输入查询视频之前就可以完成。接着提取输入视频的特征,与视频库中的视频特征进行匹配,找出与之近似重复的视频,该过程属于数据检索中的在线部分。
在视频特征提取过程中,主要可以分成全局特征和局部特征两种。全局特征主要是基于视频关键帧的颜色、纹理、动作等信息,将其整合成一个多维向量,在计算和存储方面较局部特征有较大优势,但是对于变化较大的视频识别效果较差。虽然局部特征能在光线、噪声、微视角变化较大的情形下有较高的辨识度,但是其带来的巨大计算和存储开销使得在实际应用中并不适用。所以当前较好的方法是采用两者各自的优势,先用全局特征过滤那些差别较大的视频,接着利用局部特征进一步匹配,使得检索结果在性能和准确性方面都有较大的提升,接下来描述一些当前主流的视频全局特征和局部特征方法。
3 视频特征
3.1全局特征
视频全局特征是通过将视频作为一个整体提取出的特征,该特征具有占用存储空间小、提取速度高的特点,被用在很多应用中。颜色直方图以及主成分分析是经常被采用的两种方法。
3.1.1颜色直方图
颜色直方图能够较好地反映图像中颜色的组成分布,即各种颜色区间在图像中出现的概率,虽然该方法对光照敏感,但是仍然是一种好的特征方法。对于视频而言,基于颜色直方图的特征首先应提取视频中的关键帧,接着提取每一帧的直方图,然后对这些关键帧的颜色直方图取平均值,如式(1)所示[1]。

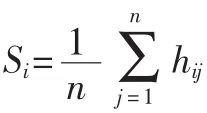
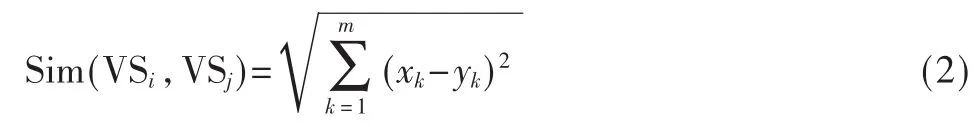
其中 VSi=(x1,x2…xm),VSj=(y1,y2…ym)。如果两视频的距离接近,就认为它们是近似重复的。
3.1.2主成分分析
主成分分析是一种将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法,又称为主分量分析。
通过视频的主成分分析可以将最重要的信息作为视频的特征,不重要的部分将被舍弃。该方法认为视频中的一小段都有着自己独特表达的主题,所以可以通过对视频帧的变化趋势用向量的方式表示出来,然后通过获取突出分布从而获取重要维度得到主要成分,形成视频的特征[4],在比较两个视频主成分的相似性的时候,为了提高精确性,主成分的旋转变化也是需要考虑的部分。
3.2局部特征
视频的局部特征主要来源于关键帧的局部特征。在图像和模式识别领域,局部特征点的发明使得近似重复视频的检测也有了巨大的发展,而且由于基于关键帧的局部特征在视频几何变换程度很大的情况下仍然有较高的辨识度,检索准确度较高,但是由于局部特征包含过多的信息,通常采用高维的向量表示,其在存储和计算方面占用较大的资源。
一张图片或关键帧包含成百上千个的局部特征点,而每个特征点由高维的向量构成(如SIFT的128维向量,PCA-SIFT的36维向量),虽然已有研究通过出现频率的高低去过滤掉低频的特征点来减少存储和计算的开销,但是基于局部特征向量的关键帧信息在匹配阶段仍然是耗时的。
4 特征索引
无论是采用视频的全局特征还是局部特征方法,在提取特征信息后,都需要将查询视频与视频库进行匹配,那么如何管理海量数据库的特征信息将直接影响查询性能和准确性。
4.1树形结构
树形结构已经在图像检索领域有非常广泛的应用,如VOC-Tree[5],可以利用该树形结构对视频帧的局部特征进行聚类,使得在特征匹配过程中以树的方式查询,能够快速提升检索性能。在视频检索领域,视频提取的特征是基于图像特征的,都是用高维向量表示,所以基于树形结构的索引能有效提高索引速度,但是随着维数的不断增大,检索的效率会有所减少。
4.2局部敏感哈希
无论是视频采用全局特征或者是局部特征,特征信息都是以高维向量进行表示,局部敏感哈希是一种在高维情形下有效提高搜索效率的方法,通过哈希的方法可以在存储的时候将相似的特征信息存放在一起,在搜索的时候便能快速定位到近似重复的特征,无论是从准确性还是速度方面都有很好的性能。
5 实验分析标准和数据集
在近似重复视频检测领域,需要有大量的视频数据集来测试检索效果,如今已经有很多机构专门在这方面提供了较为丰富的测试集,这些视频都是从网络上下载下来,有些还经过了一些编辑处理以模拟近似重复关系。在测试性能方面,检索准确率和效率是关注度较高的两个方面。
5.1测试基准集
CC_WEB_VIDEO是香港城市大学和卡耐基梅隆大学提供的近似重复视频数据集合。它总共包含通过24次查询过程中从 Google Video,Yahoo Video和 YouTube上下载的13 129个视频,这些视频下载后没有通过特定的软件进行编辑,并且通过人工做标记来表明最真实的近似重复关系,来和实现结果做比较以判断准确性。
VCDB[6]是上海智能信息实验室和复旦大学收集的大规模的近似重复视频集合,总共包括100 000个网络视频,这些视频没有经过人为的变化处理,重复关系通过人为手动做标记。
TRECVID[7]是美国政府支持视频检索的数据集,每年都会基于上一年提供一些新的视频集合,这些视频经过人工的编辑然后和原视频混合在一起,真实的重复关系在变换之后也有记录。
MUSCLE-VCD-2007是一个重复视频的集合,该集合中总共包括100个小时的视频,这些视频形式多样,有网络视频片段、电视视频、电影片段等,这些视频从分辨率和文件格式等方面均存在很大差异。
5.2性能标准
在近似重复视频检索中,检索速度和准确性是评判结果的两个非常重要的指标。
检索速度一般是从检索行为开始至结果返回中间这段过程中花费的时间来评定的。在实验过程中,实验准确性是将程序返回的近似重复结果和最开始人为标记的视频近似重复关系做比较,人为标记的重复关系作为基准,在Wu[1]的CC_WEB_VIDEO集合中,就对集合中的所有视频做了标记,以记录近似重复关系。
6 结语
近似重复视频的检测在当前爆炸式增加的视频的时代是十分重要的,随着深度学习在视频分类的领域中的快速发展[8],并且也已经取得显著效果,该技术也定能够在近视重复视频检测的领域发挥作用。同时随着视频量的增加,当前方法在更大量的视频数据情况的可扩展性也是需要解决的问题之一。为了更好地提升检索的精确性,不断地根据反馈机制去调整检索结果也是一个非常有前景的研究方向。
[1]WU X,HAUPTMANN A G,NGO C W.Practical elimination of near-duplicates from web video search[C].Proceedings of the 15th international conference on Multimedia.ACM,2007:218-227.
[2]LOWE D G.Distinctive image features from scale-invariant keypoints[J].International journal of computer vision,2004,60(2):91-110.
[3]KE Y,SUKTHANKAR R.PCA-SIFT:A more distinctive representation for local image descriptors[C].Computer Vision and Pattern Recognition,2004.CVPR 2004.Proceedings of the 2004 IEEE Computer Society Conference on.IEEE,2004,2:II-506-II-513 Vol.2.
[4]SHEN H T,ZHOU X,HUANG Z,et al.UQLIPS:a realtime near-duplicate video clip detection system[C].Proceedings of the 33rd international conference on Very large data bases.VLDB Endowment,2007:1374-1377.
[5]NISTER D,STEWENIUS H.Scalable recognition with a vocabulary tree[C].Computer Vision and Pattern Recognition,2006 IEEE Computer Society Conference on.IEEE,2006,2:2161-2168.
[6]JIANG Y G,JIANG Y,WANG J.VCDB:A large-scale database for partial copy detection in videos[M].Computer Vision-ECCV 2014.Springer International Publishing,2014:357-371.
[7]OVER P,AWAD G M,FISCUS J,et al.TRECVID 2010-An overview of the goals,tasks,data,evaluation mechanisms,and metrics[J].2011.
[8]KARPATHY A,TODERICI G,SHETTY S,et al.Large-scale video classification with convolutional neural networks[C]. Computer Vision and Pattern Recognition(CVPR),2014 IEEE Conference on.IEEE,2014:1725-1732.
[9]WU X,Ngo C W,HAUPTMANN A G,et al.Real-time near-duplicate elimination for web video search with content and context[J].Multimedia,IEEE Transactions on,2009,11(2):196-207.
[10]LIU J,HUANG Z,CAI H,et al.Near-duplicate video retrieval:Current research and future trends[J].ACM Computing Surveys(CSUR),2013,45(4):44.
[11]SHANG L,YANG L,WANG F,et al.Real-time large scale near-duplicate web video retrieval[C].Proceedings of the international conference on Multimedia.ACM,2010:531-540.
[12]SHEN H T,ZHOU X,HUANG Z,et al.Statistical summarization of content features for fast near-duplicate video detection[C].Proceedings of the 15th international conference on Multimedia.ACM,2007:164-165.
[13]ZHOU X,ZHOU X,CHEN L,et al.An efficient nearduplicate video shot detection method using shot-based interest points[J].Multimedia,IEEE Transactions on,2009,11(5):879-891.
[14]SHEN H T,ZHOU X,HUANG Z,et al.UQLIPS:a realtime near-duplicate video clip detection system[C]. Proceedings of the 33rd international conference on Very large data bases.VLDB Endowment,2007:1374-1377.
Research of near-duplicate video retrieval
Yu Shiqiang1,2,Zhang Zheng3,Zhang Weihua1,2
(1.Software School,Fudan University,Shanghai 201203,China;2.Shanghai Key Laboratory of Data Science,Shanghai 200433,China;3.State Key Laboratory of Mathematical Engineering and Advanced Computing,Zhengzhou 450001,China)
With the fast development of Internet,sheer amount of videos are upload and download in which high proportion are near-duplicate.And these near-duplicate videos arise problems in copy protection,video retrieval accuracy etc,also incurs extra unnecessary cost.It’s becoming more and more important to find out near-duplicate videos from large video sets.This paper systematically surveys current near-duplicate video retrieval technologies,compares trade-off between accuracy and throughput,and illustrates state-of-the-art works and explore the potential trending in this field.
near-duplicate;video signature;video retrieval
TP3
A
10.16157/j.issn.0258-7998.2016.05.007
国家高技术研究发展计划(863)(2012AA010905);国家自然科学基金(61370081)
2015-12-27)
余时强(1992-),男,硕士,主要研究方向:GPU、近似重复系统检测、操作系统。
张铮(1977-),男,博士,副教授,主要研究方向:体系结构、网络安全与模式识别。
张为华(1974-),通信作者,男,博士,副教授,主要研究方向:体系结构与编译优化,E-mail:zhangweihua@fudan.edu.cn。
中文引用格式:余时强,张铮,张为华.近似重复视频检索方法研究[J].电子技术应用,2016,42(5):24-26,35.
英文引用格式:Yu Shiqiang,Zhang Zheng,Zhang Weihua.Research of near-duplicate video retrieval[J].Application of Electronic Technique,2016,42(5):24-26,35.
