基于Hadoop的钢铁生产大数据存储平台研究
2016-11-29常锦才
王 卓,辛 星,尹 晓,常锦才,2*
(1. 华北理工大学 理学院,河北 唐山 063009;2. 河北省数据科学与应用重点实验室 河北 唐山 063009)
基于Hadoop的钢铁生产大数据存储平台研究
王卓1,辛星1,尹晓1,常锦才1,2*
(1. 华北理工大学 理学院,河北 唐山063009;2. 河北省数据科学与应用重点实验室 河北 唐山063009)
大数据平台在钢铁企业的部署对产业转型和升级有重要作用。钢铁产业大数据具有 明显的实时性、动态性和不确定性等特点。为应对Hadoop分布式文件系统在处理实时工业数据流显现出的一些不足,提出了基于分布式NameNode节点的HDFS。对基于分布式NameNode节点的HDFS进行了总体设计,包括TopNameNode和分布式NameNode的主要功能和工作机制。分析了分布式NameNode节点的HDFS的性能优点。提出了在虚拟化资源管理平台上搭建基于Hadoop的动态可伸缩的分布式文件存储平台。将基于知识工程的方法和基于数据驱动的方法相结合,建立了一种新的混合故障诊断模型。最后对分布式钢铁生产大数据存储平台的优势进行分析。
钢铁大数据;HDFS;分布式NameNode;技术架构;故障诊断
本文著录格式:王卓,辛星,尹晓,等. 基于Hadoop的钢铁生产大数据存储平台研究[J]. 软件,2016,37(9):47-51
0 引言
大数据平台的尽早部署直接影响着整个钢铁产业的转型升级和战略突破。在美国工业联网和德国工业4.0引领的第四次工业革命的背景下,若不能将大数据技术运用于钢铁实际生产,实现钢铁产业智能化,中国钢铁将会在国际竞争中处于劣势,甚至面临被淘汰的危险。因此,把大数据和钢铁生产行业结合,实现钢铁工业4.0非常必要。大数据存储方案和平台是大数据的基础和关键的一环,传统的存储模式有存储数据量小,计算速度慢,故障后解决困难,损失大的问题,而Hadoop HDFS分布式文件系统具有高容错性,高可扩展性的特点,存储平台安全、稳定、可靠[1],同时HDFS使工业生产的流式数据充分发挥其价值,减少钢铁工业的原料浪费,充分利用生产中的热量,减少热量浪费,同时又减少对环境的伤害。本文就Hadoop HDFS为适应钢铁生产数据特点的优化,存储平台的技术架构,指导生产的实现以及混合故障诊断展开讨论。
1 Hadoop发展现状
Hadoop作为Apache Nutch项目的一个子项目,从2002开始实现开发,经过4年的发展,逐步实现以MapReduce作为计算框架并与NDFS(Nutch distributed file system)结合的方式来支持Nutch的主要算法,直到2006成为一套完整而独立的软件,并正式起名为 Hadoop。
Apache Hadoop软件库是一个框架。它的目的是把单一服务器扩展到成千上万的机器,每个节点提供本地计算和存储,而不是依靠硬件来实现高可用性。
Hadoop主要包括以下模块:
(1)Hadoop Common:常见的实用程序,支持其他Hadoop模块。
(2)Hadoop分布式文件系统(HDFS):一个分布式文件系统,它提供了高通量访问应用程序数据。
(3)Hadoop YARN:一个集群作业调度和资源管理的框架。
(4)Hadoop MapReduce:基于YARN的系统,并行处理大型数据集。
Hadoop目前在互联网行业的发展已进入成熟阶段,Hadoop设计之初的目标就定位于高可靠性、高可拓展性、高容错性和高效性,正是这些设计上与生俱来的优点,才使得Hadoop一出现就受到众多大公司的青睐,同时也引起了研究界的普遍关注。Apache Hadoop技术已广泛应用在互联网领域,雅虎使用多达4000个节点的Hadoop集群来支持广告系统和Web搜索的研究;中国移动研究院基于Hadoop开发了“大云”(Big Cloud)系统,不但用于相关数据分析,还对外提供服务;百度每周的数据量可达200 TB,该公司使用Hadoop处理进行搜索日志分析和网页数据挖掘工作;国内的高校和科研院所也对基于Hadoop在数据存储、资源管理、作业调度、性能优化、系统高可用性和安全性方面进行研究。
经过多年的发展与完善,Apache Hadoop在2016年1月25日,发布了Hadoop最新的2.73版本。
2 为适应钢铁大数据特点的HDFS优化研究
2.1分布式NameNode节点总体结构设计
传统Hadoop构架中,只存在单一的NameNode节点。而钢铁企业的实时生产大数据具有时效性强,数据量大的问题。Hadoop传统的单一NameNode节点,会有单点失效,性能瓶颈,扩展瓶颈等问题。一旦出现问题,对企业会造成一定的损失。虽然Hadoop使用SecondaryNameNode来备份NameNode的元数据,然而NameNode出现问题时并不能实现自动切换,必须由人工介入,将会打乱企业的生产计划[2]。因此,创新性地提出了分布式NameNode节点的HDFS设计。
在HDFS集群中加入一个能够可靠工作的TopNameNode节点,它负责管理所有的NameNode节点,使各个NameNode节点更好地协作,确保HDFS集群的正常运行。
在采用分布式NameNode架构的HDFS中,各个NameNode节点组成一个分布式的NameNode系统,作为HDFS的主节点,它们对文件系统提供相同的服务。同时为保证TopNameNode和NameNode的高可用性[3-4],每个节点在集群中都有备份节点。分布式NameNode节点的HDFS系统结构如图1所示。
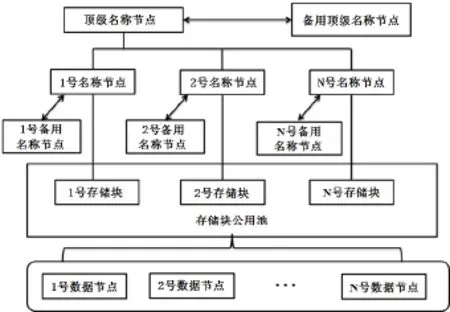
图1 分布式名称节点的HDFS系统结构图Fig.1 HDFS System Structure Diagram Based on Distributed NameNode
(1)TopNameNode节点
TopNameNode节点是所有NameNode节点的控制节点,它要维护所有NameNode的健康状态、所有DataNode的信息。其主要任务为:
① 监控分布式NameNode系统的工作状况:HDFS集群中的所有NameNode节点每隔一段时间向TopNameNode节点发送一次心跳信号,如果TopNameNode节点在指定时间内没有收到某个NameNode节点的心跳信号,便认为此节点故障。
②处理NameNode节点的故障:当TopNameNode节点发现某个NameNode节点发生故障时,立即启动该NameNode节点的备份节点Secondary NameNode替换故障节点。
③转发DataNode的信息,TopNameNode节点收集所有DataNode的状态信息,再转发给所有的NameNode节点。
(2)NameNode节点
NameNode节点与单一NameNode节点的任务基本一致。唯一的区别点在于:单一的NameNode节点包含了HDFS的所有元数据,而分布式的NameNode节点中,元数据是分散存储在各个NameNode节点中的。集群中所有NameNode节点都是对等的,一起为HDFS提供元数据服务。
2.2HDFS可靠性的设计实现
(1)安全模式
HDFS启动时,NameNode将进入安全模式。处于安全模式的NameNode无法进行任何的文件操作,内部的副本创建也被禁止[5]。NameNode此时需和各DataNode通信,获得DataNode保存的数据块信息,并对数据块信息进行检查。只有通过了NameNode的检查,此数据块才被认为安全。当认为安全的数据块所占的比例达到了配置值,NameNode才会退出。
(2)TopNameNode
若NameNode、DataNode节点向TopNameNode发送的心跳信息在指定时间内未得到回复,则认为TopNameNode发生了故障[6],进而把心跳信息发送给SecondaryTopNameNode;若SecondaryTop NameNode向TopNameNode发送的信息请求在指定时间内未得到回复,就代替其进行工作。这样的保障机制使得TopNameNode/SecondaryTopNameNode能时刻维护集群中NameNode和DataNode节点的最新信息。
(3)心跳包和副本重新创建
为了保证NameNode和各个DataNode的联系,分布式存储平台采用了心跳包(Heart beat)机制。位于整个HDFS核心的NameNode,通过周期性的活动来检查DataNode的活性。NameNode周期性向管理的各个DataNode发送心跳包,而收到心跳包的DataNode则需回复。由于心跳包总是定时发送,NameNode把将要执行的命令通过心跳包发送给DataNode,而DataNode收到心跳包,一方面回复NameNode,另一方面就开始了与用户或者应用的数据传输[7]。
如侦测到了DataNode失效,那之前保存在此DataNode上的数据就变成不可用的[8-9]。那么,如果有的副本存储在失效的DataNode上,则需要重新创建这个副本,放到另外可用的地方。其他需要创建副本的情况包括数据块校验失败等。
(4)数据一致性
DataNode与应用数据交互的大部分情况都是通过网络进行的,而网络数据传输带来的一大问题就是数据是否能原样到达[10]。为保证数据的一致性,HDFS采用了数据校验,校验和机制。
(5)租约
每当写入文件之前,一个客户端必须要获得NameNode发放的一个租约。NameNode保证同一个文件只会发放一个允许写的租约,那么就可以有效防止出现多人写入的情况。
2.3基于分布式NameNode节点的HDFS特性和优点
(1)NameNode/SecondaryNameNode实现了快速切换
在原有的SecondaryNameNode机制的基础上,分布式NameNode节点增加了TopNameNode,统筹管理各NameNode,在某个NameNode节点发生故障时,可迅速实现NameNode/SecondaryNameNode的切换,提高了HDFS的可用性。
(2)分布式NameNode服务性能的提升
HDFS集群中多个NameNode可同时为客户端提供元数据服务,对于元数据的请求,根据元数据存放策略可定位对应的NameNode节点,解决了单一NameNode节点的单点性能瓶颈问题。
(3)Hadoop集群更易扩展
集群中的多个NameNode,大大增加了可用于存放元数据的内存资源,集群中可扩展更多的DataNode,存储更多的数据,不再轻易受到单一NameNode节点内存和存储容量的限制。
3 钢铁生产大数据存储平台技术架构
本文设计的钢铁生产大数据存储平台由虚拟化资源管理平台和Hadoop分布式存储平台构成。Hadoop分布式存储系统部署在资源管理平台提供的虚拟机池中[11]。其特点是可动态部署Hadoop Slave节点,快速搭建Hadoop分布式存储系统。其技术架构如图2所示。
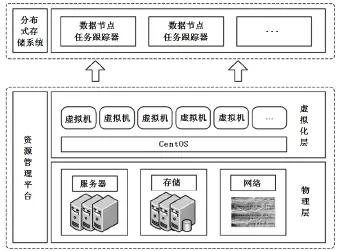
图2 基于Hadoop的钢铁生产大数据存储平台Fig.2 Big Data Storage Platform for Iron and Steel Enterprises Based on Hadoop
虚拟化资源平台基于CentOS操作系统。CentOS由Red Hat Enterprise Linux依照开放源代码规定释出的源代码所编译而成[12]。其硬件兼容性好,生命周期为7到10年,基本可以覆盖硬件的生命周期。
在搭建的分布式存储平台上,可搭建Apache Hive, Apache HBase, Apache Cassandra等数据库系统,对钢铁企业生产的实时数据处理分析,指导钢铁企业生产规划,如图3所示。
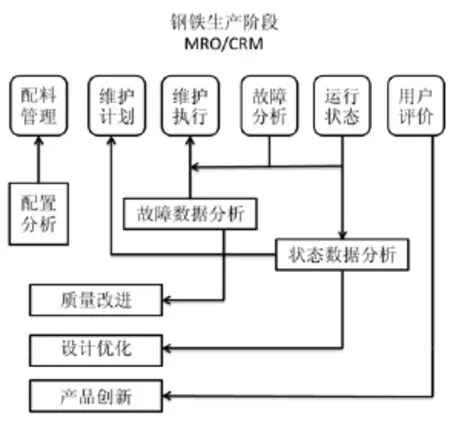
图3 钢铁工业大数据指导钢铁生产规划示意图Fig.3 Big Data of Iron and Steel Enterprises Directing Steel Production Planning Diagram
4 基于数据驱动的混合故障诊断
Hadoop HDFS具有能存储海量历史数据和采集实时流式数据的特点。可通过对历史和实时数据的处理,进行故障检测。将基于知识工程的方法和基于Hadoop的钢铁生产大数据分布式存储平台进行结合,主要利用基于数据驱动的方法来对故障进行检测,利用基于知识工程的方法来对故障进行诊断[13]。数据驱动的混合故障诊断的框架如图4所示。

图4 数据驱动的混合故障诊断的框架Fig.4 Hybrid Fault Diagnosis Framework Driven by Data
混合故障诊断的实现流程如下:
(1)应用HDFS收集处理流式数据,对数据进行处理。得到有效的数据。
(2)利用基于数据驱动方法建立故障模型对数据进行处理,得出故障检测结果。
(3)应用HDFS存储量大的特点。对历史数据进行挖掘。建立基于知识模型的专家系统[14]。
(4)将故障结果输入到基于知识的专家系统,得到故障原因,实现决策支持。
(5)若利用知识模型没有对故障诊断成功,实时数据和故障检测结果进行数据挖掘来实时地更新基于知识的模型。对实时的数据进行数据挖掘,得到出现的关键字,重要字段等,更新知识模型[15]。
5 钢铁生产大数据存储平台优势分析
5.1低成本的优秀解决方案
基于Hadoop的分布式存储系统提供了低成本解决问题的方案,其本身无License限制,可轻松在上百台普通PC上并发存储大规模数据。钢铁企业无需购置高性能机器来满足繁重的实时数据流处理。集群性能的提升与投入的资金呈线性关系,在成本控制方面的优势超过分析型数据库的可扩展方面的优势。
5.2可靠、高效、可伸缩的数据存储平台
基于Hadoop的分布式文件存储系统具有可靠,高效的特点,HDFS架构如图5所示

图5 分布式文件存储系统架构Fig.5 Hadoop Distributed File System Framework
上文已讨论分布式文件存储系统高可靠性的实现。HDFS假设计算元素和存储失败,因此通过创建并维护多个工作数据副本,确保能对失败的节点重新分布处理;由于存储平台通过并行方式存储,通过并行处理加快处理速度,因此该平台具有高效的特点;由于平台的运算性能可线性叠加,处理的数据流可达PB、ZB的级别,可伸缩性强。
5.3灵活的多服务应用支持
钢铁生产大数据存储平台基于Hadoop HDFS。HDFS的默认配置适合于大多数安装的应用,支持大多数平台,支持shell命令行风格的HDFS目录交互。Namenode和Datanode都内建了网络服务器,可方便地查看集群的状态。这些优点使得在云计算中运用Hadoop的分布式架构成为可能,使云计算能够不受平台等的限制。
6 结束语
随着工业互联网的迅速发展,工业生产的实时数据量在不断增长,HDFS在钢铁企业中的应用受到了越来越多的关注,但其单点设计给钢铁生产企业所带来的问题也日益凸显。本文首先提出了一种分布式NameNode节点的HDFS模型,以此来解决HDFS单一NameNode的不足。针对钢铁企业对海量数据处理的迫切需求,提出了在虚拟化资源管理平台上搭建基于Hadoop的动态可伸缩的海量数据存储平台,并给出其技术架构。最后,给出了一种工业大数据下的混合故障诊断模型,并对分布式数据存储平台的优势进行了分析,为钢铁工业数据的实时存储提供了新的解决方案。
致谢:感谢华北理工大学大学生创新创业计划项目(X2016128),河北省人力资源与社会保障厅留学回国人员科技活动项目(C2015005014)的资助。
[1] 周斌. 基于Hadoop的海量工程数据关联规划挖掘方法研究[D]. 北京交通大学, 2016.
[2] 李明明, 李伟. 基于HDFS的高可靠性存储系统的研究[J].西安科技大学学报, 2016, 03: 428-430.
[3] 王又立, 王晶. 一种基于Kerberos和HDFS的数据存储平台访问控制策略[J]. 软件, 2016, 37(01): 67-70.
[4] 蒋涛, 周傲英, 高云君, 等. 不确定数据查询处理[J]. 新型工业化, 2013, 3(5): 83-101.
[5] 王来, 翟健宏. 基于HDFS的分布式存储策略分析[J]. 智能计算机与应用, 2016, 01: 5-8.
[6] 李可, 李昕. 基于Hadoop生态集群管理系统Ambari的研究与分析[J]. 软件, 2016, 37(02): 93-97.
[7] 王少娟. 基于Hadoop的作业调度负载均衡算法研究[D].安徽理工大学, 2016.
[8] 杨彬. 分布式文件系统HDFS处理小文件的优化方案[J].软件, 2014, 35(6): 65-69.
[9] 杨海鹏, 戴波. 数据采集与监控系统在石油化工企业中的应用[J]. 新型工业化, 2014, 4(3): 44-51.
[10] Tupe A, Priyadarshi A. Data Mining with Big Data and Privacy Preservation[J]. nature, 2016, 5(4).
[11] Ma, Ke. Research and implementation of distributed storage system based on big data. 2016 IEEE International Conference on Big Data Analysis (ICBDA): IEEE, 2016:1-4.
[12] Singh, Somya, Gaurav Raj, and Gurneet Kaur. Analysis of HDFS RPC and Hadoop with RDMA by evaluating write performance.2016 6th International Conference-Cloud System and Big Data Engineering (Confluence): IEEE, 2016: 368-372.
[13] Wang, Chia-Hui, et al. Coupling GPU and MPTCP to improve Hadoop/MapReduce performance. 2016 2nd International Conference on Intelligent Green Building and Smart Grid (IGBSG): IEEE, 2016: 1-6.
[14] Docherty J, Corbett H. Managing Change in the Public Relations Industry: The Impact and Potential of Big Data[J]. 2016.
[15] Vega-Gorgojo G, Fjellheim R, Roman D, et al. Big Data in the Oil & Gas Upstream Industry-A Case Study on the Norwegian Continental Shelf[J]. OIL GAS-EUROPEAN MAGAZINE, 2016, 42(2): 66-68.
Research on Big Data Storage Platform for Iron and Steel Enterprises Based on Hadoop
WANG Zhuo1, XIN Xing1, Yin Xiao1, CHANG Jin-cai1,2
(1. College of Sciences, North China University of Science and Technology, Tangshan 063009; 2. The Key Laboratory of Data Science and Applications of Hebei Province, Tangshan 063009)
The deployment of big data platform in iron and steel enterprises has an important role in the industrial transformation and upgrading. The big data of iron and steel industries has the characteristics of real time, dynamic and uncertainty. HDFS is gradually showing some deficiencies with the real time industrial data stream, to cope with this, a HDFS based on distributed NameNode nodes is proposed. HDFS based on distributed NameNode nodes is designed generally, including the main functions and working mechanisms of TopNameNode node and distributed NameNode nodes. The performance benefits of HDFS based on distributed NameNode nodes are analyzed. A Solution that building a dynamic scalable distributed file storage platform based on Hadoop in the virtual resource management platform is proposed. A new hybrid fault diagnosis model is built combining method based on Knowledge Engineering with the data driven method. At last, advantages of the big data storage platform for Iron and steel enterprises based on Hadoop are analyzed.
Big data on iron and steel enterprises; HDFS; Distributed nameNode; Technology framework; Fault diagnosis
TP311.13
A
10.3969/j.issn.1003-6970.2016.09.011
河北省人力资源与社会保障厅留学回国人员科技活动资助项目(C2015005014)。华北理工大学大学生创新创业计划项目(X2016128)。
通讯联系人: 常锦才(1973-),男,博士,教授。
