如何使用Oracle数据库分区表
2016-11-26
引言:随着互联网技术以及互联网商业的发展,大数据条件下高并发量、海量数据的性能直接影响着用户的网上应用。如何处理好这种海量数据,已经成为任何数据库管理系统必须面对的挑战。本文讨论的内容就是如何在生产实际中处理海量数据。
Oracle作为一种数据库,处理海量数据最基本的方法就是“分而治之”,即将海量表拆成小表,具体技术而言就是采用分区表的形式拆分大表,从而提高用户在海量数据环境下的用户体验,减少DBA维护的时间和精力成本从而有效降低海量数据处理的复杂度。
分区表与海量数据
海量数据的特点是在高并发环境下的高数据量,这样就造成传统的单表(具有单独的段标识)很大。如此大的数据量,极有可能引起数据访问以及管理的各种问题。
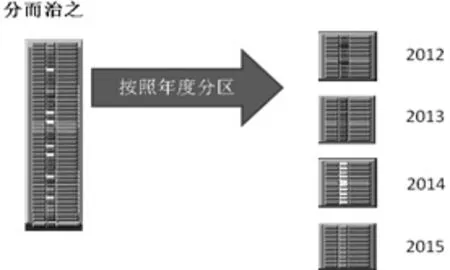
图1 分区表示意图
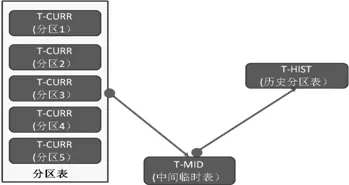
图2 高效归档海量数据分区表示意图
Oracle解决这种海量数据的方法是利用分区表技术。所谓的分区表就是依据分区主键而创建的多个独立的表。对应用而言它只是一个表,而在底层是由几个独立分区组成,每个分区具有自己的段标识以及段的高水位线。图1是按照时间分区的分区表示意图。从图1可以看出,分区表在物理上是独立的存储段,其优点是:其一,数据分布到多个独立的段中,单个段的损坏不影响其他段的数据,提高了段的可用性;其二,对每个分区实施单独的备份和恢复策略,提供了段管理的灵活性;其三,不同的物理分区可以存储到不同的物理磁盘上从而来分散I/O,提高了数据I/O性能。
分区表与数据归档
对历史数据的备份在成熟的信息化应用系统中占有十分重要的地位。对历史数据进行归档,降低其数据量,消除磁盘碎片,可以使得系统高效运行。
在有数据需要归档时,分区表的作用就发挥出来,按照时间进行分区,对于数据归档,数据维护,数据的可用性都有好处。图2是分区表高效归档海量数据示意图。
在生产实际中,经常需要按照时间进行历史数据归档,随着数据量的快速增长,需要归档这些历史数据,如果此时采用了时间分区,前提是该表有时间字段作为分区主键,就很容易使用分区技术快速高效地实现数据归档。如当前表为T-CURR是按照表中T-date字段的分区表,每个月一个分区,可按照如下步骤实现数据归档:先创建中间临时表T-MID。然后创建历史分区表T-HIST。最后进行分区交换。
这里的历史表T-HIST和当前的表T-CURR结构相同,唯一区别就是名称不同。而中间临时表T-MID与需要交换的分区具有相同的表结构。下面是具体的交换过程:

这样通过两次分区交换完成当前表中分区d1中的数据归档,此时使用including indexes包含索引段的交换,如果是本地索引则不需要重建历史归档表中的本地索引,这里的without validation指出不需要数据验证,这样就不需要在交换前对T-MID中的数据进行全表扫描,提高分区交换的效率。
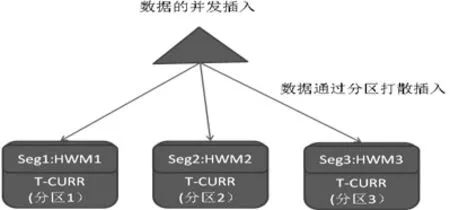
图3 分区表示意图
分区表解决高水位推进问题
海量数据环境下,高并发量的数据对单表而言会数据存储空间的不足造成高水位推进的问题,从而影响到数据的并发处理。而通过分布表技术可以有效化解这个难题。在生成系统中会出现enq:HW或者enq:FB等待事件,在RAC集群环境下出现大量gc current grant等待事件,这些都是和高水位推进相关的等待事件。
当数据插入分区表时,如果表段的空间不足会首先格式化一组新数据块,只有格式化完成才能继续插入数据,否则当前数据插入的会话会出现等待HW/FB锁的等待。
可以想象在海量数据环境下,高并发量、高数据量的特点必然因为这种等待的加剧,从而影响数据插入的性能。此时如果合理使用分区表即可有效缓解这种等待。一旦将表分区,则每个分区具有独立的段标识,对应独立的高水位线管理。这样就将数据插入均衡到多个分区中,从而有效缓解HW锁的争用。
图3为高水位推进打算之后的分区表示意图,其说明高水位推进打算之后的示意图,并发环境下使用分区表时每个分区表一个高水位线,避免了单个段的高水位等待问题。
分区表与RAC集群环境
在RAC集群环境下,有效提高了数据的高可用性、可扩展性、负载均衡等,提高了系统处理海量数据的能力。结合集群环境的实际,需要考虑如何有效使用好分区表。合理的分区表使用可以减少实例间的数据争用。减少节点之间的网络流量,从而优化整个集群系统的性能。
如果条件允许,采用应用分区是十分有效的较少集群实例间数据流量的方法,它可以极大减少表的global buffer busy等待。即将每个区域的用户绑定到服务器连接池组中的某个固定的实例,固定的实例只用来访问一个固定区域用户的分区,这样就极大较少了实例对相同数据块的争用,从而避免global buffer busy带来的争用问题。
如果条件不允许使用应用分区,则需要详细分区访问该海量表的SQL语句特点,从而设计对应的分区方案。如果SQL的谓词中大量的出现某个字段的=条件,则可以选择该字段作为HASH分区的主键,从而尽最大可能将数据打算,这样通过将数据打散到不同的分区中,从而有效减少热快冲突的概率,提高整个集群的性能。
如何实施分区
1 选择分区主键
在使用分区技术时,合理的分区主键与分区粒度的选择十分重要,否则很难发挥分区表的优势。
分区主键是指实现表分区的字段,如表中的T_date字段实现按照时间分区。分区粒度是分区大小,如按照时间分区是以月为单位还是以年为单位,这些直接影响分区优势的发挥。
总之在设计分区前要根据业务需要,制定满足性能、维护等需求的分区方案,选择好分区主键与分区粒度。
分区主键的选择主要考虑分区目的。如果是归档数据显然使用时间字段实现范围分区;如果主要是打散数据分解全局数据冲突可以考虑谓词中的对应字段作为分区主键。即分区主键的选择原则是它是否经常出现在查询语句的谓词条件中。
如果在系统上线之后实现分区,此时DBA不清楚那些SQL经常访问,以及如何访问这些海量表,所以需要不断的分区共享池中的SQL语句,分区过滤条件和连接条件,从而合理判断分区主键。在选择了分区主键之后,必须保证该字段是非空的。
2 选择分区粒度
在确定了分区主键之后,就需要考虑分区粒度的选择。而分区粒度的选择没有固定的原则,适合系统需要就好,更好的服务于应用系统就是好的分区,但是这也是分区粒度的难点。不同目的采用不同分区方法。以下列举三个目的作为说明:
(1)便于维护:需要考虑多大的分区维护起来方便,满足维护时间窗口的条件,如果分区归档要求15分钟完成,则显然对分区粒度的大小有限制,这需要做实验分区,从而满足自己系统软硬件条件的容量限制。
(2)便于归档:归档频率需要考虑,即多久归档一次,显然归档周期就是分区粒度需要考虑的首要因素
(3)便于提高性能:需要考虑表的范围扫描的范围高概率发生在哪个时间范围内, 这样根据多数数据查询的扫描时间范围设计分区粒度比较好。
总结
本文分析了如何在高并发量以及高数据量的环境下提高数据访问性能。Oracle数据库通过分区表技术可以有效解决这个难题。
分区技术的使用需要针对具体场合以及结合分区表的特点作出合理的分区粒度以及分区键的选择。在RAC集群环境下合理使用应用分区可以极大减少实例之间数据通信以及实例间协商的开销,从而提高RAC的整体性能。
