基于离散粒子群算法的数据中心网络流量调度研究
2016-11-22林智华吴春明李勇燕
林智华,高 文,吴春明,李勇燕
(1.福建江夏学院电子信息科学学院,福建福州350108;2.浙江大学计算机学院,浙江杭州310027;
基于离散粒子群算法的数据中心网络流量调度研究
林智华1,2,高 文2,吴春明2,李勇燕3
(1.福建江夏学院电子信息科学学院,福建福州350108;2.浙江大学计算机学院,浙江杭州310027;
3.绍兴文理学院上虞分院,浙江上虞312300)
数据中心网络利用多个并行路径为集群计算等网络服务提供高对分带宽.然而,现有的流量调度算法可能会引起链路负载不均衡,核心交换机冲突加剧,造成网络总体性能降低.本文将流调度问题转化成0-K背包问题求解,提出基于离散粒子群的流调度算法DPSOFS(Discrete Particle Swarm Optimization Flow Scheduling).该算法根据Fat-Tree结构特点定义了粒子速度、位置和运算规则,以两次迭代冲突流个数差值作为目标函数,并限定路径搜索范围,减少随机搜索的盲目性.仿真实验验证了该算法对减少流冲突快速有效,能提高网络对分带宽.
Fat-Tree;数据中心网络;离散粒子群;流调度
1 引言
随着数据量指数级的增长和各种网络服务不断涌现,网络拓扑结构对现代云计算数据中心的扩展性、成本、容错、整体性能等方面产生重大影响[1].目前新型的数据中心网络拓扑结构主要有两类[2],一类是以交换机为中心的结构,如Fat-Tree[3],PortLand[4],SPAIN[5]等;另一类是以服务器为中心的结构,如DCell[6],BCube[7],Hyper-BCube[8],等.其中,Fat-Tree拓扑结构相对简单,容易部署,同时支持多条等价路径和完全的对分带宽[9],是新型的数据中心网络中最受重视的体系结构之一.
研究表明,网络流量由大部分短暂流和小部分长命流组成,长命流占据了大部分带宽.数据中心网络中流量也是由很多小型的、事务方式的RPC(Remote Procedure Call)流和小部分大流组成.这些大流在网络中存在的时间较长,对应的数据包数或字节数相对较多[10],占据大量的链路带宽.在Fat-Tree等树型拓扑结构中(图1),主机之间存在多条等价的路径.因此,针对网络拓扑结构特点研究并设计大流调度算法,减少大流碰撞,保证链路负载均衡,对于提高网络传输性能至关重要.
数据中心网络流调度算法主要分成静态和动态两类,ECMP(Equal-CostMultipathRouting)[11],VLB(Valiant Load-Balancing)[12]等静态调度法会造成某条链路过载.动态调度算法中,GFF[11]对边界交换机收到的流在全网线性查找无冲突路径,实现局部优化.Hedera[11]采用集中控制调度策略,在全网视图下通过模拟退火算法得到流优化路径.DDFS[13]和Flowlet[14]通过分布式方式控制汇聚层交换机链路负载率来实现网络负载均衡,DiFS[15]通过交换机间控制命令来减少流量冲突,从而增加网络带宽利用率.
未来数据中心的网络设备将实现数据面和控制面的分离,在控制面上可以进行全局流量集中管控.本文针对Fat-Tree数据中心网络拓扑结构特点,借鉴离散粒子群DPSO思想,提出流调度算法DPSOFS,将流调度问题转化成0-K背包问题求解,在数据中心网络全局高度上进行流路由安排,得到最优网络对分带宽.实验结果表明,该算法使网络对分带宽较GFF和Hedera算法提高了20%以上,冲突流数量减少40%左右,网络性能得到明显改善.

2 相关工作
总体来讲,当前数据中心网络的流调度算法分成静态和动态两种,动态算法中又划分成集中式调度和分布式调度两种方式.
ECMP通过计算收到的数据包头的散列值所对应的等价路径的端口地址来转发数据流.但由于静态调度的特性,该算法在转发过程不考虑数据包或数据流大小,当某一主机流量较大时,依然会映射到同一转发端口,造成该端口负载增加,使得多条等价链路并不平衡.
VLB随机选择可用的转发端口实现负载均衡,但是依然存在多条数据流选择同一端口,导致流冲突和链路过载.
GFF流调度算法构建了中心调度器,对边界交换机收到的流线性查找一条无冲突路径.但是由于该算法在流分配上的先后次序不同,不能保证整个网络获得较优的对分带宽.
Hedera在全局网络视图下通过模拟退火算法得到流优化路径,使网络对分带宽有了一定的提高.但是它在路径选择上完全随机,在主机数量较大的情况下,核心交换机上可能产生流量拥塞,优化效果不明显.
DDFS分布式调度定义了链路负载率,通过控制聚合层交换机链路负载率来防止核心层交换机过载,实现负载均衡.Flowlet在DDFS的基础上利用Flow splitting技术,按不同链路负载率之间的比例关系,动态分割数据流到这些链路上,达到充分利用空闲链路带宽的目的.但这两种算法没有验证数据中心总体网络性能和吞吐量的改进.
DiFS算法在交换机上增加Explicit Adaption Request控制命令,通过该命令通告发送端远程流冲突,从而使发送端调整数据传输路径来避免冲突发生.但在数据中心网络较大的情况下,每台交换机分布式独立处理EAR控制命令,可能会增加通信开销,降低整体网络性能.
3 DPSOFS流调度算法
3.1 流调度问题数学模型
背包问题(Knapsack problem)是一种组合优化的NP完全问题,其相似问题经常出现在商业、组合数学,密码学和应用数学等领域中.由于背包问题与流调度问题本质是一致的,因此本文把该问题转换成0-K背包这种经典的问题进行求解.
在Fat-Tree拓扑结构中,主机之间有条路径.为某条流指定核心交换机的编号值,则唯一确定了主机间的通信路径.因此,流调度问题可以描述成一个n维背包问题:已知n条流f1,f2,…,fn,以及对应的流带宽属性值bi,(i=1,2,…,n),bi∈(0,1],m条链路l1,l2,…,lm,每条链路带宽上限值为1.用一个向量ci(i=1,2,…,n)表示n条流对应的核心交换机的编号,ci=(0,1,…,(K/2)2).当ci取值为0表示选择任何核心交换机都会造成流冲突,而非0值表示选择某一台核心交换机可行.另外,我们定义map(fi,bi,ci)为映射函数,表示把流通过ci选择的路径映射到对应的若干条链路上,用i×j的矩阵a表示映射结果,对应的值是流fi占用链路lj的带宽bi.该问题求解的目的是如何为所有的流fi选择合适的ci,在保证所有链路l1,l2,…,lm,的带宽上限值的前提下,使ci取值为0的个数最少.
严格的数学描述为:
(1)
式(1)中Minf(c1,c2,…,cn)为目标函数,求所有ci=0的个数总和最小值.约束条件为占用任意lj的流的带宽之和aij应限制在1以内.
3.2 流量带宽需求预测算法
对数据中心网络流量调度之前,必须先对每条大流的带宽需求bi进行预测.但流实际占用的带宽值无法反映其真实带宽需求.另外,流的大小、长度以及字节数都是未知变量,即使事先已知其流量大小,对其进行带宽需求的预测也是NP难的优化问题.考虑到任何流的传输带宽受限于发送端和接收端主机网卡的带宽,利用主机网卡带宽的限制来预测流的最大实际可用带宽是可行的.流量带宽预测算法描述如下:
输入:n×n矩阵I(元素值Iij表示主机i向主机j发出大流数量),Si表示发送端主机i带宽限值,Rj表示接收端主机j带宽限值,带宽初始限值为1.
输出:n×n矩阵O(元素值Oij表示主机i向主机j发出流带宽需求预测值).
矩阵变量T,其元素值Tij是由于受限于发送端的带宽,计算得到发送端i向接收端j发送流的预测带宽值.
矩阵变量A,其元素值Aij是由于受限于接收端的带宽,计算得到发送端i向接收端j发送流的预测带宽值.
步骤3:若存在任一元素Tij≠Aij则Oij=Min(Tij,Aij);根据已确定的Oij,更新矩阵I和剩余Si值和Rj值;返回步骤1;
步骤4:若所有Tij=Aij则Oij=Tij;
步骤5:返回矩阵O;
3.3 DPSOFS算法设计
3.3.1 DPSOFS算法模型
粒子群算法PSO是一种受到鸟群飞行集群活动的规律启发的群智能算法.在PSO算法中,每一个粒子被认为问题的一个可行解,粒子以一定的速度在解空间运动,并向自身的历史最佳位置和全局最佳位置聚集,实现对候选解的进化[16],最终找到最优解.与其他进化算法相比,该算法收敛速度更快,更加简单,易于实现并具有更强的全局优化能力.近年来为了应对实际工程应用中的离散问题,研究者在原有算法基础上进行二进制空间的扩展,形成了离散粒子群算法DPSO.
(2)
整个群体得到的全局最优值记为Gbk,则
(3)
每个粒子的速度更新公式为:
(4)
位置更新公式为:
(5)
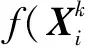
输入:由GFF流调度算法得到的ci(i=1,2,…,n);
输出:算法运算后的ci(i=1,2,…,n)结果以及ci=0的个数值;
步骤1:当ci=0且i 步骤2:对每一条冲突的流随机分配一台核心交换机,即ci=Rand(1,…,(k/2)2); 步骤3:将步骤2中的流对应的链路写入矩阵a中,即map(fi,bi,ci); 步骤4:替换出原先已安排好的流,保证步骤2中的冲突流符合带宽要求,R=replace(bi,ci); 步骤5:对R集合中的流f执行GFF(f); 步骤6:计算ci=0的个数值并返回结果. 3.3.4 DPSOFS算法流程 DPSOFS流调度算法步骤如下: 输入:n条流(f1,f2,…,fn); 输出:Gbk; 步骤1:设定最大迭代次数,粒子个数,获得流量带宽预测bi值,GFF算法ci值; 步骤3:令k=1; 步骤8:k=k+1; 步骤9:若k达到最大迭代次数,则输出Gbk,算法结束,否则返回步骤4. 为了验证DPSOFS算法的效果,我们通过Mininet[17]实验平台来搭建Fat-Tree网络.另外,为了验证该算法收敛性能以及在大型数据中心网络的扩展性能,我们也模拟了算法在k值较大情况下的运行结果. 4.1 Mininet仿真平台 在Mininet平台上,我们配置了k=8-ary的Fat-Tree数据中心结构,每台主机产生不同长度的流,长度服从指数分布,流产生的时间服从泊松分布. 每台主机根据某种通信模式来选取目的主机,并且每台主机只接收网络中某一台主机的流量数据.通信模式[3]有以下三种:间隔方式Stride(x)、交错方式Staggered(pEdge,pPod)和随机方式Random. 调度算法每隔5秒查询所有边界交换机大流(流传输数据超过100KB)的统计值,并计算最优路径.在流调度算法中,我们设定DPSOFS迭代次数为10,粒子数为3.在与Hedera算法对比时,由于Hedera循环不考虑流数量,因此我们把Hedera循环次数设为10×3×需调度的流数量. 在实验中,我们使用对分带宽作为测试的性能指标.对分带宽越大,说明网络的传输性能越强. 4.2 实验结果 图2是GFF、Hedera和DPSOFS三种算法在k=8的Fat-Tree拓扑下网络对分带宽测试的结果.我们对三种通信模式分别进行了多次测试,每次测试运行60秒,在第10秒到50秒这段时间内测量对分带宽. 在间隔模式下(一台主机与距离其位置x的其它主机通信),GFF总能找到一条无冲突的路径,得到最优的对分带宽值.这是由于Fat-Tree拓扑结构的特点,每台交换机上联和下联的带宽相同,即网络过载率为1:1.按该模式通信的主机可以并行无冲突地传输. 在stag(0.5,0.3)交错模式下,大多数流来自同一子网,这些流通过边界交换机直接进行全双工通信.由于不同Pod间通信的流数量较少,造成冲突的流也较少.三种算法得到的对分带宽相差不大.在stag(0.2,0.3)交错模式下,随着Pod间通信流数量增加,冲突流也增多,因此,GFF得到的对分带宽值有所降低.Hedera和DPSOFS在流数量较少的情况下都采用随机调度的方式,但是DPSOFS利用多粒子并行搜索,并且粒子间共享全局最优解,得到的结果好于Hedera,网络对分带宽亦高于Hedera. 在随机模式下,同一个子网以及同一个pod之间的通信流减少,大多数为不同Pod之间的数据流.由于GFF调度先后次序造成较多的流无法找到无冲突路径.因此其对分带宽较低.Hedera对流的调度优化不太明显.但是从图2(c)中可以看出,冲突流越多,DPSOFS多粒子并行运算获得的网络对分带宽就越优,全局调度效果就越好. 4.3 大型数据中心网络实验仿真结果 由于大型数据中心网络中的主机数量庞大,用Mininet无法实现仿真.为了验证DPSOFS算法在收敛速度上的优势以及在大型数据中心网络流调度性能,我们模拟了调度过程,得到了调度后三种算法产生的冲突流个数,并进行了比较. (1)三种算法的收敛效果 在k=16的Fat-Tree拓扑结构下,我们测试了GFF、Hedera和DPSOFS在随机通信模式下迭代20次后获得的冲突流的个数. 从图3可以看出,经过GFF调度后有124条流产生冲突.而DPSOFS在第三次迭代后时就获得Hedera第五次迭代得到的较优结果(优化结果为108).DPSOFS在第七次迭代时就获得超出Hedera最终的优化结果(Hedera优化结果为92).在迭代11次左右,DPSOFS算法基本完成了收敛,获得全局较优的结果,体现了该算法较强的收敛特性和全局优化能力. (2)三种算法在k值较大情况下的流调度效果 在算法测试过程中,我们选择k=16、24和32的Fat-Tree拓扑结构.测试结果为在随机模式下,三种算法得到的冲突流个数值和对应的占比关系,见表1,表2和表3. 表1 三种算法在随机通信模式下的流冲突比较(k=16) 表2 三种算法在随机通信模式下的流冲突比较(k=24) 表3 三种算法在随机通信模式下的流冲突比较(k=32) 从表1,2,3中可以看到,DPSOFS在k值较大的情况下比Hedera表现出更优的运算结果.随着主机数的增加,Hedera优化效果不明显,在k=32时,多次测试Hedera/GFF比值保持在95%左右,而DPSOFS/GFF比值基本都在65%左右,体现了DPSOFS较好的流调度效果.这主要源于DPSOFS对随机选择核心交换机的改进上.Hedera只是通过随机选择两条流并交换各自的核心交换机位置来判断两次结果的优劣;DPSOFS一方面通过多粒子并行计算并共享全局最优解,另一方面充分利用空闲链路,避免选择与其他流出现链路冲突的路径,使得算法迭代次数减少,加快收敛,获得更优的调度结果. 本文对当前常用的Fat-Tree数据中心网络流调度算法进行了分析,针对集中控制的两种动态调度算法GFF和Hedera进行研究和改进,提出DPSOFS算法,将流调度问题转化成0-K背包问题,以两次迭代冲突流个数差值作为目标调节函数,并限定路径搜索范围.在仿真和验证过程中,该算法体现出更快的收敛速度和更优的调度结果. [1]Hammadi A,Mhamdi L.A survey on architectures and energy efficiency in data center networks[J].Computer Communications,2014,40(1):1-21. [2]Zhang Y,Ansari N.On architecture design,congestion notification,TCP incast and power consumption in data centers[J].Communications Surveys & Tutorials,IEEE,2013,15(1):39-64. [3]Al-Fares M,Loukissas A,Vahdat A.A scalable,commodity data center network architecture[J].ACM SIGCOMM Computer Communication Review,2008,38(4):63-74. [4]Mysore R N,Pamboris A,Farrington N,et al.PortLand:a scalable fault-tolerant layer 2 data center network fabric[J].ACM SIGCOMM Computer Communication Review,2009,39(4):39-50. [5]Mudigonda J,Yalagandula P,Al-Fares M,et al.SPAIN:COTS data-center ethernet for multipathing over arbitrary topologies[A].Proceedings of Networked System Design and Implementation[C].San Jose:NSDI,2010.265-280. [6]Guo C,Wu H,Tan K,et al.DCell:a scalable and fault-tolerant network structure for data centers[J].ACM SIGCOMM Computer Communication Review,2008,38(4):75-86. [7]Guo C,Lu G,Li D,et al.BCube:a high performance,server-centric network architecture for modular data centers[J].ACM SIGCOMM Computer Communication Review,2009,39(4):63-74. [8]Lin D,Liu Y,Hamdi M,et al.Hyper-bcube:A scalable data center network[A].Proceedings of International Conferenceon Communications (ICC)[C].Ottawa:IEEE,2012.2918-2923. [9]Escudero-Sahuquillo J,Garcia P J,Quiles F J,et al.A new proposal to deal with congestion in InfiniBand-based fat-trees[J].Journal of Parallel and Distributed Computing,2014,74(1):1802-1819. [10]Tso F P,Hamilton G,Weber R,et al.Longer is better:exploiting path diversity in data center networks[A].Proceedings of Distributed Computing Systems[C].Philadelphia:IEEE,2013.430-439. [11]Al-Fares M,Radhakrishnan S,Raghavan B,et al.Hedera:dynamic flow scheduling for data center networks[A].Proceedings of Networked System Design and Implementation[C].San Jose:NSDI,2010.19-19. [12]Zhang-Shen R,McKeown N.Designing a predictable internet backbone with valiant load-balancing[A].Proceedings of Quality of Service-IWQoS [C].Passau:Springer,2005.178-192. [13]Bharti S,Pattanaik K K.Dynamic distributed flow scheduling with load balancing for data center networks[J].Procedia Computer Science,2013,19(1):124-130. [14]Bharti S,Pattanaik K K.Dynamic distributed flow scheduling for effective link utilization in data center networks[J].Journal of High Speed Networks,2014,20(1):1-10. [15]Cui W,Qian C.Difs:Distributed flow scheduling for adaptive routing in hierarchical data center networks[J].Measurement,2014,5(1):17. [16]程祥,张忠宝.基于粒子群优化的虚拟网络映射算法[J].电子学报,2011,39(10):2240-2244. Cheng Xiang,Zhang Zhong-bao.Virutal network embedding based on particle swarm optimization[J].Acta Electronica Sinica,2011,39(10):240-2244.(in Chinese) [17]Lantz B,Heller B,McKeown N.A network in a laptop:rapid prototyping for software-defined networks[A].Proceedings of the 9th ACM SIGCOMM Workshop on Hot Topics in Networks[C].New Delhi:ACM,2010. 林智华 男,1972年12月生于福建福州,现为福建江夏学院电子信息科学学院副教授,主要研究方向为新一代网络技术. E-mail:lindiva@126.com Data Center Network Flow Scheduling Based on DPSO Algorithm LIN Zhi-hua1,2,GAO Wen2,WU Chun-ming2,LI Yong-yan3 (1.CollegeofElectronicsInformationEngineering,FujianJiangxiaUniversity,Fuzhou,Fujian350108,China;2.CollegeofComputerScience,ZhejiangUniversity,Hangzhou,Zhejiang310027,China;3.UniversityofShaoxingatShangyu,Shangyu,Zhejiang312300,China) Data center networks leverage multiple parallel paths connecting end host pairs to offer high bisection bandwidth forcluster computing applications.However,state of the art flow scheduling algorithms may cause unfair link utilization and saturation of core switches,resulting in overall bandwidth loss.In the paper,we regard the flow scheduling problem as a 0-Kknapsack problem and propose a new flow scheduling algorithm named DPSOFS based on DPSO.DPSOFS formulates the position,velocity and their operation rules of particles according to Fat-Tree topology structure,and defines objective function as the difference of the number of conflict flows between two iterations.Moreover,our proposed mechanism reduces random search blindness by limiting the range of the path search.The simulation suggests that it can improve overall network bisection efficiently. Fat-Tree;data center network;DPSO;flow scheduling 2014-11-10; 2015-03-06;责任编辑:梅志强 973计划(No.2012CB315903);浙江省重点科技创新团队(No.2011R50010-21);国家科技支撑计划(No.2014BAH24F01);国家自然科学基金(No.61379118) TP393 A 0372-2112 (2016)09-2197-06 ��学报URL:http://www.ejournal.org.cn 10.3969/j.issn.0372-2112.2016.09.026



4 实验仿真平台与结果





5 结论

