基于FileSystem API的HDFS文件存取和副本选择优化研究
2016-11-22贾会玲李英娜李萌萌
贾会玲 吴 晟 李英娜 李萌萌 杨 玺 李 川
(昆明理工大学信息工程与自动化学院,昆明 650500)
基于FileSystemAPI的HDFS文件存取和副本选择优化研究
贾会玲 吴 晟 李英娜 李萌萌 杨 玺 李 川
(昆明理工大学信息工程与自动化学院,昆明 650500)
在对HDFS进行分析和研究的基础上,在HDFS文件分布式系统中应用FileSystem API进行文件存储和访问,并通过改进的蚁群算法对副本选择进行优化。HDFS API能够有效完成海量数据的存储和管理,提高海量数据存储的效率。通过改进的蚁群算法提升了文件读取时副本选择的效率,进一步提高了系统效率并使负载均衡。
HDFS FileSystem API 改进的蚁群算法 副本选择
互联网特别是移动互联网的发展,加快了信息化向社会经济各方面和日常生活的渗透。无论是个人数据、家庭数据还是企业数据都呈指数增长的态势,这些数据大多为非关系型数据,具有海量、复杂、多样、异构及动态变化等特性。如何高效存储和管理这些数据,使之得到高效利用已成为海量数据研究的热点[1]。分布式技术的迅速发展,使它成为了一种解决海量数据与管理的有效方式。
HDFS(Hadoop Distributed File System)提供了一种高效、安全的海量数据分布式解决方案[2,3]。HDFS不仅提供了一个分布式环境,同时结合了FileSystem API,可大幅度提高文件上传和下载的效率。副本技术是保证HDFS可靠性和性能的关键技术,它能在很大程度上减少传输延迟,提高数据访问和处理效率[4]。而副本选择是HDFS中数据访问和管理的基础,副本选择策略的优劣将直接影响系统的性能、负载平衡和可靠性[5]。
在HDFS整体结构和读写原理研究的基础之上,笔者在HDFS中应用FileSystem API进行文件存储和访问,介绍了系统设计和关键模块的实现。并且,利用改进的蚁群算法对HDFS文件读取时的副本选择进行了优化。
HDFS是一个典型的主从(Master/Slave)架构(图1),主要由一个名字结点(Namenode)、一个SecondaryNamenode、一个或多个数据结点(Datan-ode)组成。Namenode为Master结点,是HDFS文件目录和分配的管理者,它主要负责名字空间和块的管理。SecondaryNamenode实质上是Namenode的一个快照,用来保存Namenode中对HDFS的元数据备份,并减少Namenode的启动时间。Datanode为Slave结点,是HDFS中真正存储数据的地方,它是文件存储的基本单元。
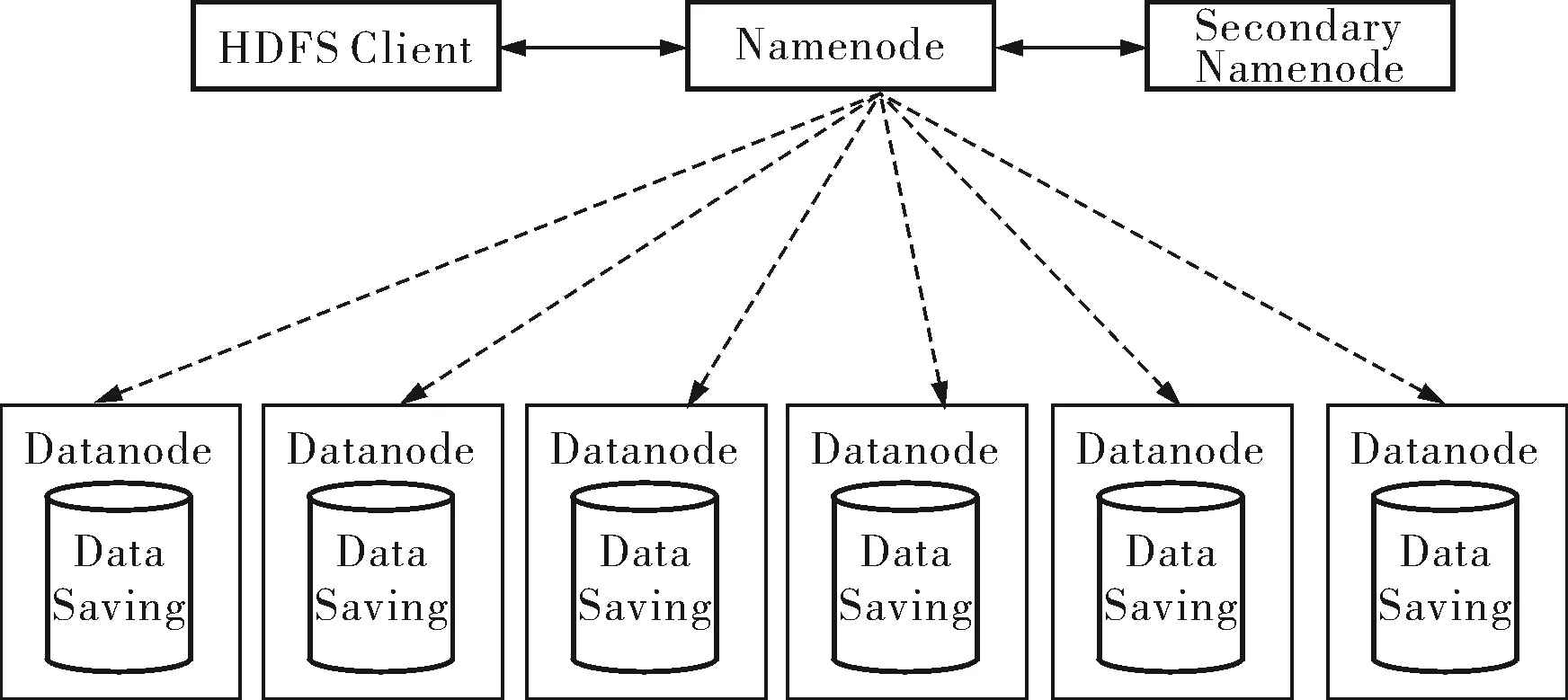
图1 HDFS架构示意图
2 HDFS读写原理
HDFS采用流式数据访问方式存储数据,对于客户端写入的数据先按照固定大小对这些数据进行分块,然后把每一个数据块的多个副本存放在不同的Datanode节点上。客户端也是按照分块来读取文件的数据,客户端总是选择从距离它最近的可用的Datanode节点上读取数据块。
2.1文件读流程
客户端在读文件时(图2),首先通过FileSystem的open方法发出打开文件的请求;接着,客户端调用read方法,开始从Datanode上读取数据,当前Datanode的数据块读取完毕后,关闭此流与Datanode的连接;然后连接此文件的下一个数据块的最近Datanode进行块读取。当客户端读取数据结束后,调用close方法,关闭该流。在读取数据的过程中,若客户端与Datanode节点通信出现错误时,客户端会通知Namenode,然后试着连接下一个拥有此数据块的Datanode进行数据读取。

图2 文件读流程
2.2文件写流程
客户端在写文件时(图3),首先对文件进行分块操作,同时通过create方法发出创建文件的请求,FileSystem通过RPC协议将请求发送给Namenode,在Namenode的Namespace里面创建一个新的文件,同时Namenode分配可用的Datanode。FileSystem返回一个FSDataOutputStream给客户端,用于写入数据,客户端调用write方法,以流式方式将各块写入Datanode。当客户端写数据完成后,调用close函数,关闭该流。最后,FileSystem通知Namenode写入完毕。
3 HDFS文件存储系统的设计与实现
3.1系统架构
HDFS文件存储系统基于JSP+JavaBean+Servlet模型,JSP充当视图层,JavaBean充当模型层,Servlet充当控制层。模型层(Model)把上传或下载抽象成一个JavaBean组件,负责完成文件的上传或下载。视图层(View)主要负责显示所要上传或下载的文件目录。控制层(Controller)主要负责对前端JSP页面传进的参数进行处理,然后调用相应的JavaBean组件实现文件的上传和下载。MVC模式的系统架构如图4所示。
MVC模式的工作原理为:所有的请求都被发送给作为控制层的Servlet。Servlet接收请求,并根据请求信息将它们分发给相应的JSP页面来响应;同时Servlet还根据JSP的需求生成相应的JavaBean对象并传输给JSP,JSP通过直接调用方法或利用UseBean的自定义标签,得到 JavaBean中的数据。这种设计模式通过Servlet和JavaBean的合作来实现交互处理。

图3 文件写流程
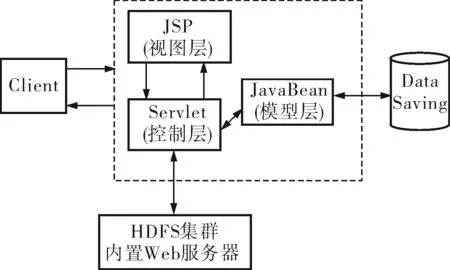
图4 HDFS文件存储系统架构框图
3.2主要功能模块的设计与实现
笔者提出的HDFS存储系统采用HDFS作为底层架构。HDFS的高可用性、高可靠性及容错机制等特性增强了分布式云系统的稳定性、可靠性和可扩展性。为方便上层逻辑往底层文件系统中读写数据,设计并实现了文件上传和下载模块。另外,文件下载模块又包括副本选择优化模块。HDFS文件的存储是基于FileSystem API实现的。Hadoop类库中最终面向用户提供的接口类是FileSystem,该类是一抽象类,封装了几乎所有的文件操作。
用户向Hadoop分布式文件系统中上传文件时,首先由FileInputStream类创建本地文件的输入流;然后由FileSystem类获得URI对应的HDFS文件系统,以创建的方式打开Hadoop文件的输出流,该输出流指向HDFS目标文件;最后用IOUtils工具将文件从本地文件系统复制到HDFS目标文件中,并显示当前HDFS目标文件中的所有文件目录。文件上传模块流程如图5所示。

图5 基于FileSystem API的HDFS文件上传流程
用户从Hadoop分布式文件系统中下载文件到本地时,首先由Configuration类读取Hadoop文件系统配置项;其次,由FileSystem类获得URI对应的HDFS文件系统并打开一个URI对应的FSDataInputStream文件输入流,读取文件;最后用IOUtils工具将文件从HDFS目标文件中选定并保存到本地文件系统的指定路径下,关闭输入流和输出流。文件下载模块流程如图6所示。

图6 基于FileSystem API的HDFS文件下载流程
3.3副本选择优化模块
3.3.1数据模型
笔者应用蚁群算法设计出一种Hadoop集群环境下的副本选择策略,该策略综合考虑了磁盘的I/O速率、网络带宽、副本节点的负载状况和物理距离d这4个主要因素[6,7]。对于客户端来说,信息素浓度越大副本越佳。
当创建数据副本时,先初始化信息素浓度,具体如下:
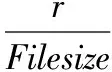
(1)
式中Filesize——副本大小;
r——磁盘的读取速度。
当副本发生变化时,副本的信息素浓度也会根据不同的情况做出相应的改变,变化规律为:
(2)
其中,ΔTj为信息素浓度改变量;ρ为信息素持久度,取ρ=0.8,该参数表示即使副本没有发生变化,信息素浓度也会相应降低。副本信息素的变化规律包括以下3种情况:

b. 当副本被成功访问时,信息素浓度会上升,上升值ΔTj=cek,其中ce=0.8;
c. 当副本被访问失败时,信息素浓度会降低,降低值ΔTj=-cpk,其中cp=1.1。
当副本被删除时,将信息素浓度置为零并设置停用标志。当副本信息素浓度有所变化时,该副本被选择的概率也会随之增减,可利用公式计算出每一个副本被选择的概率[8],具体如下:
(3)
其中,Tj(t)、Tu(t)分别为副本所在节点j、u的当前信息素浓度;ηj、ηu分别为相应节点的初始信息素浓度;α和β分别代表当前信息素和初始信息素的相对重要程度。笔者视二者权重相等,用于共同决定选择概率,即α和β分别取为0.5。
若每次都选择概率最大的副本,极易造成副本所在节点的负载不平衡。为保证节点的负载均衡,将计算出的选择概率与该副本所在节点的负载完成率进行结合运算,使得每次被选中的副本节点不一定是计算概率最大的节点:
(4)
其中,f、fmax分别表示访问同一个存储节点上的相同数据副本的任务个数和最大个数。
3.3.2副本选择算法流程
在上述信息素初始化和变化规律的基础上,设计了副本选择蚁群算法,具体步骤如下:
a. 初始化信息素。利用式(1)对新创建的副本进行信息素初始化。
b. 计算选择概率。根据用户的需求从副本中找出所有的可用副本,利用式(3)计算每个副本节点的选择概率。
c. 选择副本。将选择概率与副本所在节点的负载完成率按照式(4)进行结合运算,将概率最大的副本节点作为访问节点。
d. 更新信息素浓度。被选中作为访问对象的节点进行副本传送时,减少信息素。若副本传输成功,则信息素浓度上升;若副本传输失败,则信息素浓度降低。
4 结束语
海量数据信息的存储是当前信息时代面临的问题,寻找到海量文档的存储解决方案对信息资源的有效存储有着重要意义。HDFS提供了高效、稳定且存储成本相对低廉的分布式存储方案。笔者设计了一种基于FileSystem API的HDFS文件存储系统,并通过改进的蚁群算法对文件读取时的副本选择进行了优化。该系统基于分布式文件系统HDFS,并部署运行在廉价的服务器集群之上,充分发挥了HDFS高可扩展性、高可靠性的特点,较好地利用了现有的存储设施。但HDFS集群作为存储环境也存在一些缺陷,如不适合于文件的随机读写,对海量小文件的存储也存在效率问题。
[1] 崔杰,李陶深,兰红星.基于Hadoop的海量数据存储平台设计与开发[J].计算机研究与发展,2012,49(z1):12~18.
[2] Ghemawat S,Cobioff H,Leung S T.The Google File System[C].Proceedings of the 19th ACM Symposium on Operating Systems Principles.New York:ACM Press,2003:29~43.
[3] Shvachko K,Kuang H,Radia S,et al.The Hadoop Distributed File System[C].2010 IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST).Washington DC, USA:IEEE,2010:1~10.
[4] 刘田甜,李超,胡庆成,等. 云环境下多副本管理综述[J].计算机研究与发展,2011,48(z3):254~260.
[5] 罗鹏,龚勋.HDFS数据存放策略的研究与改进[J].计算机工程与设计,2014,35(4):1127~1131.
[6] 王彩亮,李浩,姚绍文.云环境中数据副本选择策略研究[C].The 2nd Asia-Pacific Conference on Information Network and Digital Content Security. Paris: Atlantis Press,2011:12~17.
[7] 陈蕾,杨鹏.蚂蚁算法在数据网格副本选择中的应用研究[J].计算机工程与设计,2008,29(23):6157~6160.
[8] 王辉,钱锋.群体智能优化算法[J].化工自动化及仪表,2007,34(5):7~13.
ResearchofHDFSFileSystemAccessandOptimizationofReplicaSelectionBasedonFileSystemAPI
JIA Hui-ling, WU Sheng, LI Ying-na, LI Meng-meng, YANG Xi, LI Chuan
(FacultyofInformationEngineeringandAutomation,KunmingUniversityofScienceandTechnology,Kunming650500,China)
Based on analysis and research of HDFS, having FileSystem API applied in HDFS to store and access files was implemented, including having the improved ant colony algorithm adopted to optimize the replica selection. HDFS API can effectively store and manage mass data and improve efficiency of mass data storage. Though making use of improved ant colony algorithm to promote efficiency of the file replica selection in reading files, the system efficiency and load balancing can be improved.
HDFS, FileSystem API, improved ant colony algorithm, replica selection
TP399
A
1000-3932(2016)06-0623-05
2016-04-28(修改稿)基金项目:国家自然科学基金项目(51467007)
