基于32位微处理器系统架构的Cache设计
2016-11-21杨大为
杨大为,王 爽,王 丹
(中国电子科技集团公司第四十七研究所,沈阳110032)
基于32位微处理器系统架构的Cache设计
杨大为,王爽,王丹
(中国电子科技集团公司第四十七研究所,沈阳110032)
近年来随着芯片技术的发展,嵌入式微处理器迎来了新的机遇,广泛应用于通信、多媒体、网络以及娱乐等方面。处理器的处理速度发展迅速,近乎于指数增长,然而内存的处理速度增长缓慢,因此内存的存储速度成为了影响嵌入式微处理器系统性能的主要瓶颈,为了均衡成本、性能和功耗,高速缓存Cache广泛应用于嵌入式系统中。首先介绍Cache的工作原理,其次对直接映射、全关联映射、组相联映射三种策略进行比较分析,然后分析行大小与命中率的关系,最后设计一款基于32位微处理器系统架构的高速缓存Cache。
高速缓存;组相联;行填充;命中率;写通;写回
1 引 言
近年来,嵌入式微处理器发展迅速,在移动终端、多媒体、网络通信等方面应用尤其广泛,对处理器性能的要求也越来越高。为了弥补内存速度较低的问题,Cache作为连接内核和内存的桥梁,对于提高处理器访问程序和数据的速度[1],起到了至关重要的作用。
2 Cache工作原理
Cache位于主存与内核之间,用于提高存储系统的性能,提高处理器访问主存的效率。Cache的功能完全用硬件来实现,对于软件人员是完全透明的。如果处理器内核可以在Cache中找到需要的数据,叫做hit(命中);如果没有找到,叫做miss(未命中)。
当Cache命中时,可以很快将所需数据返回给内核;当Cache未命中时,需对Cache进行更新,从主存中重新把需要的数据搬移进Cache,再返回给处理器内核。Cache存储体由块即Cache行(line)构成,块是Cache与主存之间进行数据交换的基本单位。
由于程序具有局部性特点,所以Cache 具有时间局部性和空间局部性[2]的特点。时间局部性即如果某个数据被访问,那么在不久的将来它很可能再次被访问。空间局部性即如果某个数据被访问,那么与它相邻的数据很可能很快被访问。每次miss都把被访问地址相邻块大小的数据调入到Cache中,能够提高Cache的命中率。图1为cache工作原理图。
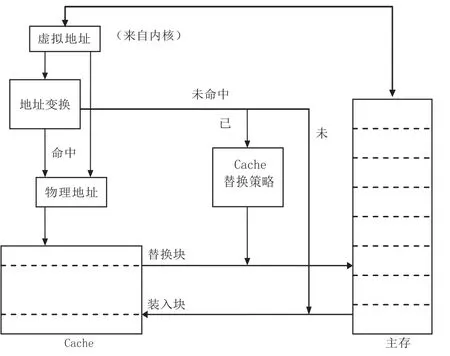
图1 Cache工作原理
3 Cache设计
3.1地址映像方式
由于内存的空间远远大于Cache,因此内存中的数据与Cache为多对一的映射关系。设计时采用组相联映像方式[3]。组相联是一种较为通用的映射策略,结合了直接映射访问速度快、实现简单的优点和全相联映射命中率高的优点。首先,将高速缓存分成若干大小相等的块,每一块称作一个way(路);接着用类似于直接映射方式中的分页方法将主存按照一个way的大小进行分页;然后将高速缓存中的每一个way都分成大小相同的line,包含每一个way中相同位置的line的集合称作一个set(组)。在进行数据填充时,主存的每一个数据块只能映射到高速缓存中固定的set上,即在set之间采用直接映射的方式;但是主存的每一个数据块可以映射到组内的任意一个way上,即在set内部采用全相联映射方式。
3.2Cache种类
本设计采用独立[4]cache结构,即指令Cache与数据Cache分开。数据写入Cache时采用可配置策略,即写通(Write-Through)还是写回(Write-Back)由CP15协处理器寄存器的设置决定。并且采用读分配策略[5],也就是说只有在读操作下有命中时才会产生行填充(linefill)。
3.3替换算法
如果在读取数据或指令的过程中发生Cache miss,则需要从主存中调入包含被访问数据的新块到Cache中。而这个新块可以装入到任一路Cache中的对应块中。当可以装入这个新块的几路Cache块都已经装满时,就启动Cache替换算法[6],从那些块中找出一个不常用的块,把它调回到主存中,腾出一个块存放从主存中调来的新块。本设计中的替换算法有两种:随机替换算法和轮转法[7]。
随机替换算法通过一个伪随机数发生器产生一个伪随机数,用新块将编号为该伪随机数的Cache块替换掉。这种算法很简单,易于实现。但是它没有考虑程序的局部性特点,因而效果较差。
轮转法设计一个计数器,利用该计数器依次选择将要被替换出去的Cache块。这种算法容易预测最坏情况下Cache的性能。但它有一个明显的缺点,在程序发生很小的变化时,可能造成Cache平均性能的急剧变化。
3.4Cache大小
Cache大小设计为4KB-64KB之间可配置。每块Cache的标签(TAG)和每Cache行的索引(Index)由内核地址组成,其形成方法如表1所示。
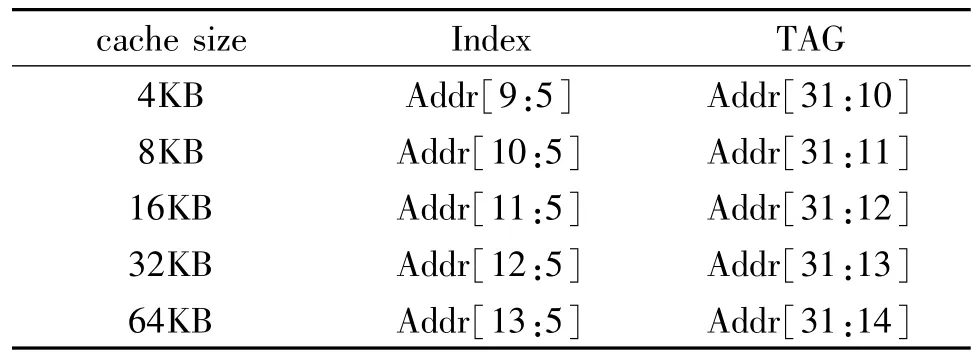
表1 Cache对内核地址的处理
3.5Cache结构
本设计采用的Cache结构[8]为4路组相联结构,以8KB大小为例,每路cache有2KB大小,每块Cache有8个字大小,所以每路Cache的块数为64。图2为8KB 4路组相联Cache结构示意图。
在cache实现中,Icache分为DataRam、TagRam、ValidRam,Dcache分为DataRam、TagRam、ValidRam和DirtyRam。它们分别由不同的Ram实现。下面以8KB大小为例说明cache的Ram实现。
DataRam:每路的大小为2KB,由于设计中数据宽度是32位的,所以Cache的Ram要用32位数据宽度的Ram实现。这样每个DataRam的大小为512W。考虑到Cache的高速要求,在实现中不会将一个DataRam对应一路Cache来实现,而是将一路Cache分散在四个DataRam中,这样一次linefill的数据可以在最短的时钟周期内全部写入到DataRam中,保证了Cache读取数据及替换的高速要求。分配原则如表2所示。
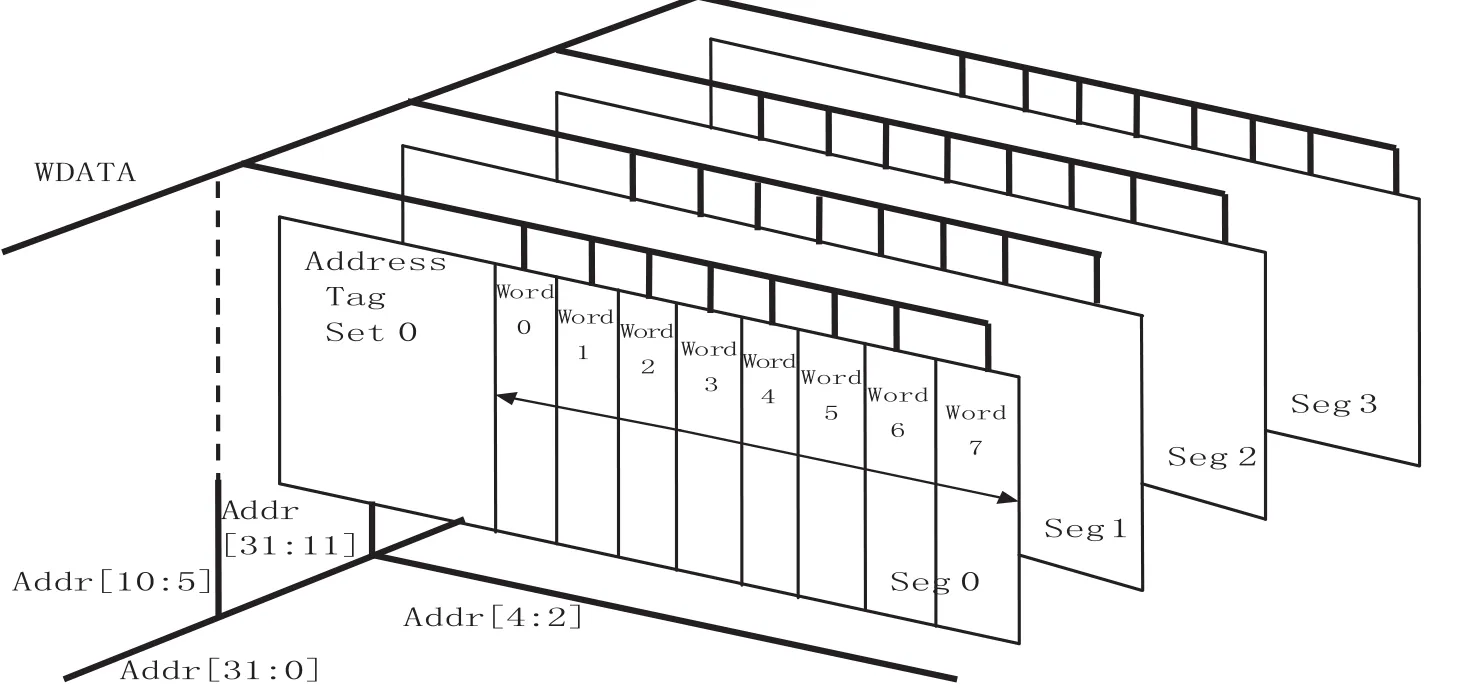
图2 8KB 4路组相联Cache结构

表2 DataRam结构
TagRam:每块cache八个字数据的Tag是相同的,所以每块cache只有一个Tag,这样一片cache对应的TagRam宽度为22位,深度为64(同cache每片的块数)。四片cache对应四个Tag Ram。
ValidRam:Icache和Dcache分别有一个ValidRam与之对应,深度为一路cache块数的四分之一,宽度为24位,0-15位存放Valid数据,16-23位存放RRCount数据。RRCount用在轮转替换策略中,指示cache块在上次替换中的路数。ValidRam的格式如表3所示。
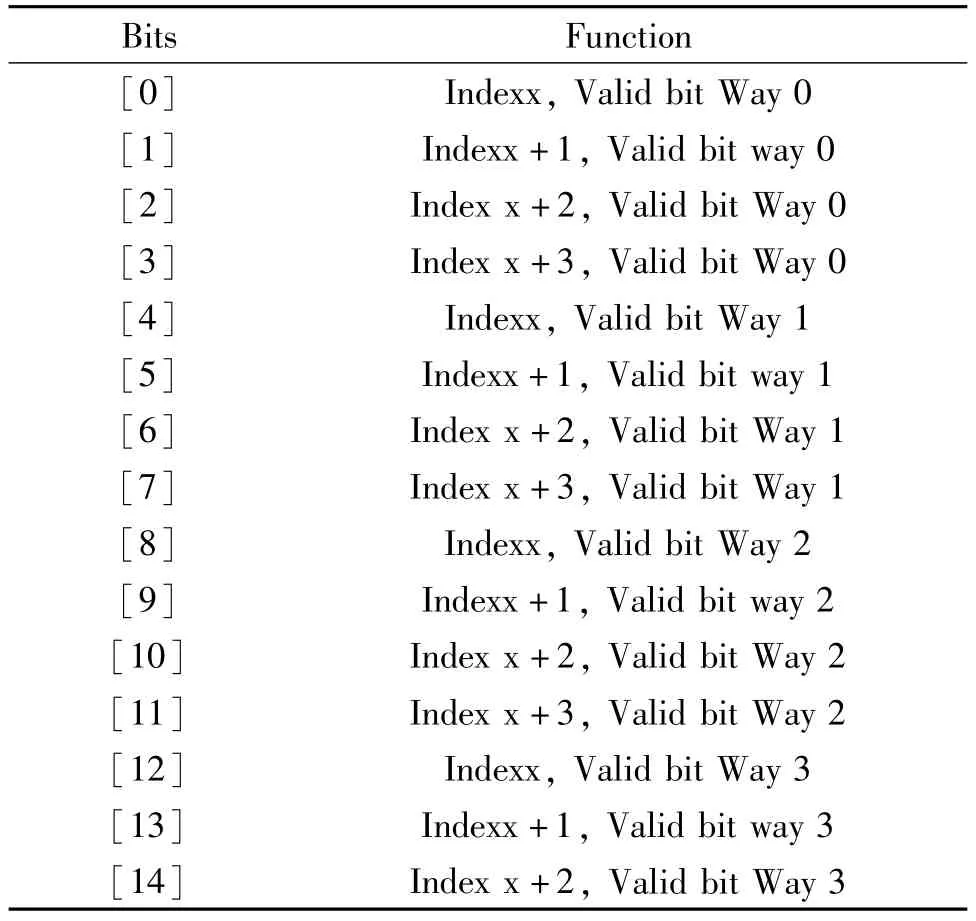
表3 ValidRam结构

BitsFunction[15]Index x+3,Valid bit Way 3[17:16]Index x,RRCount[1:0][19:18]Index x+1,RRCount[1:0][21:20]Index x+2,RRCount[1:0][23:22]Index x+3,RRCount[1:0]
DirtyRam:Dcache有一个DirtyRam与之对应,深度为一路cache块的大小,宽度为八位,每一位表示半行(四个W)cache是否有Dirty数据,格式如表4所示。

表4 DirtyRam结构
3.6Cache控制器结构
Cache控制器的设计包括了接口设计(与CP15及Sysctl接口、与Cache存储器接口、与总线接口(BIU))、替换模块设计、行填充缓冲器(FB)及写操作替换缓冲器(EWB)设计、Cache标签处理等模块的设计,Cache控制器结构如图3所示。
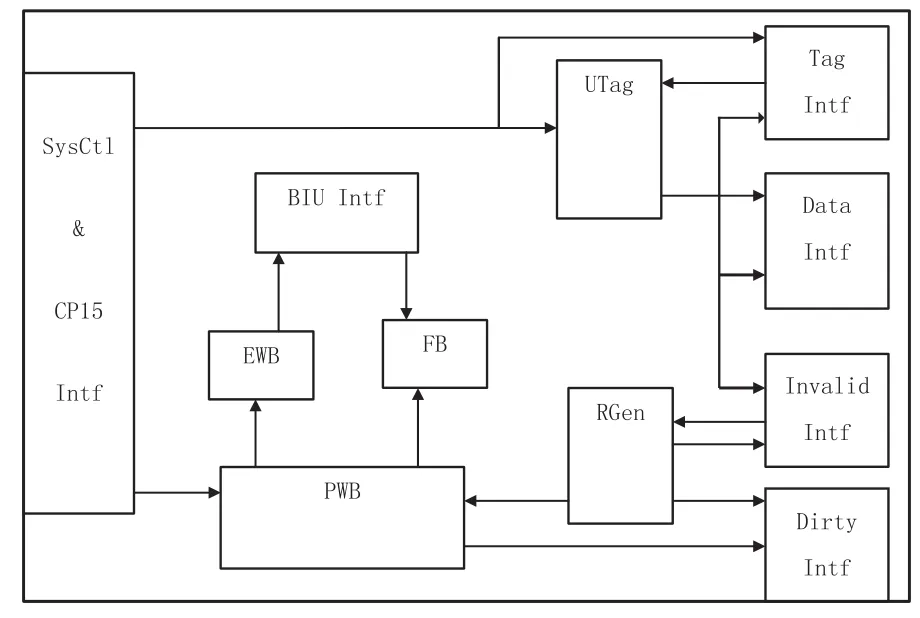
图3 cache控制器结构框图
Cache设计中的接口时序如图4-6所示。
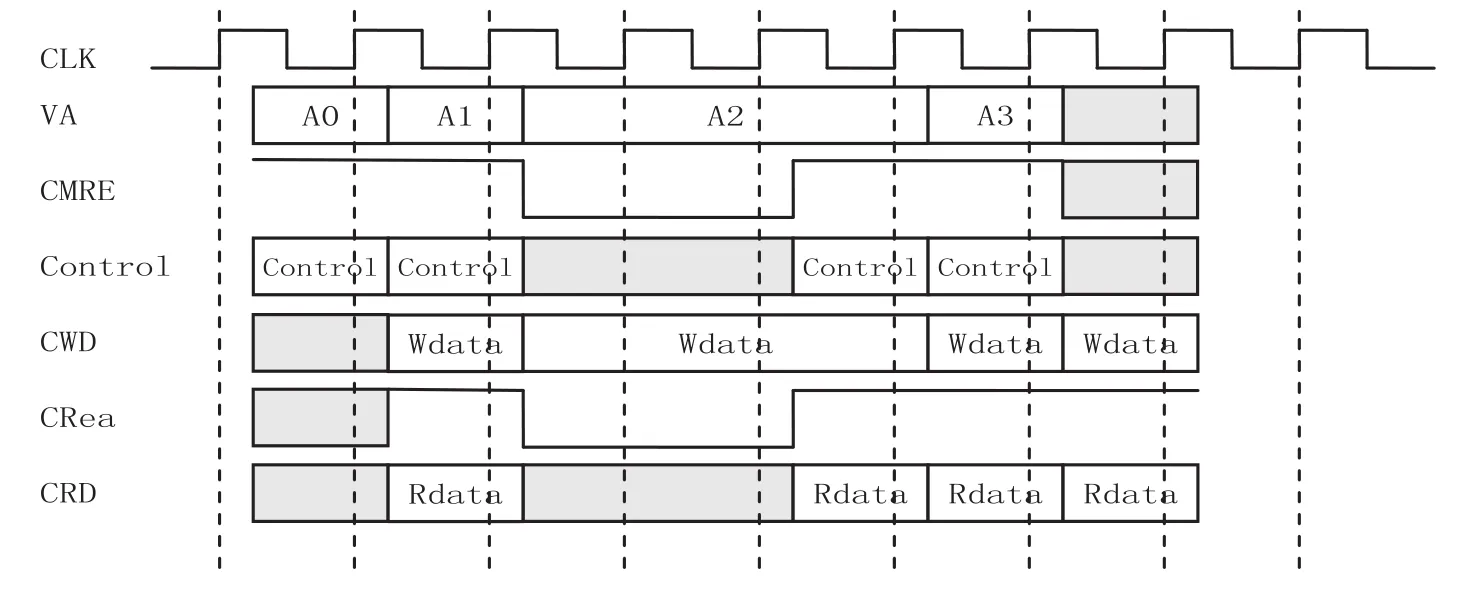
图4 Cache与SysControl、CP15接口时序图
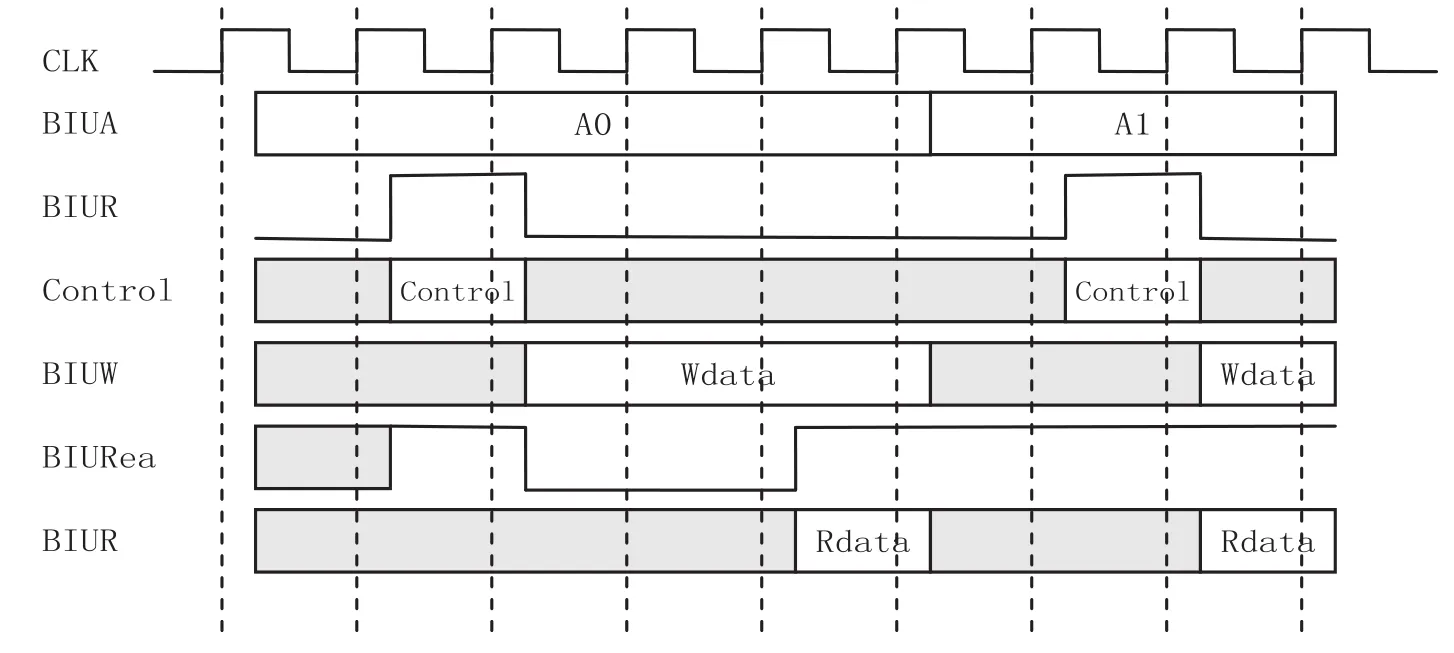
图5 CacheBIU接口时序图
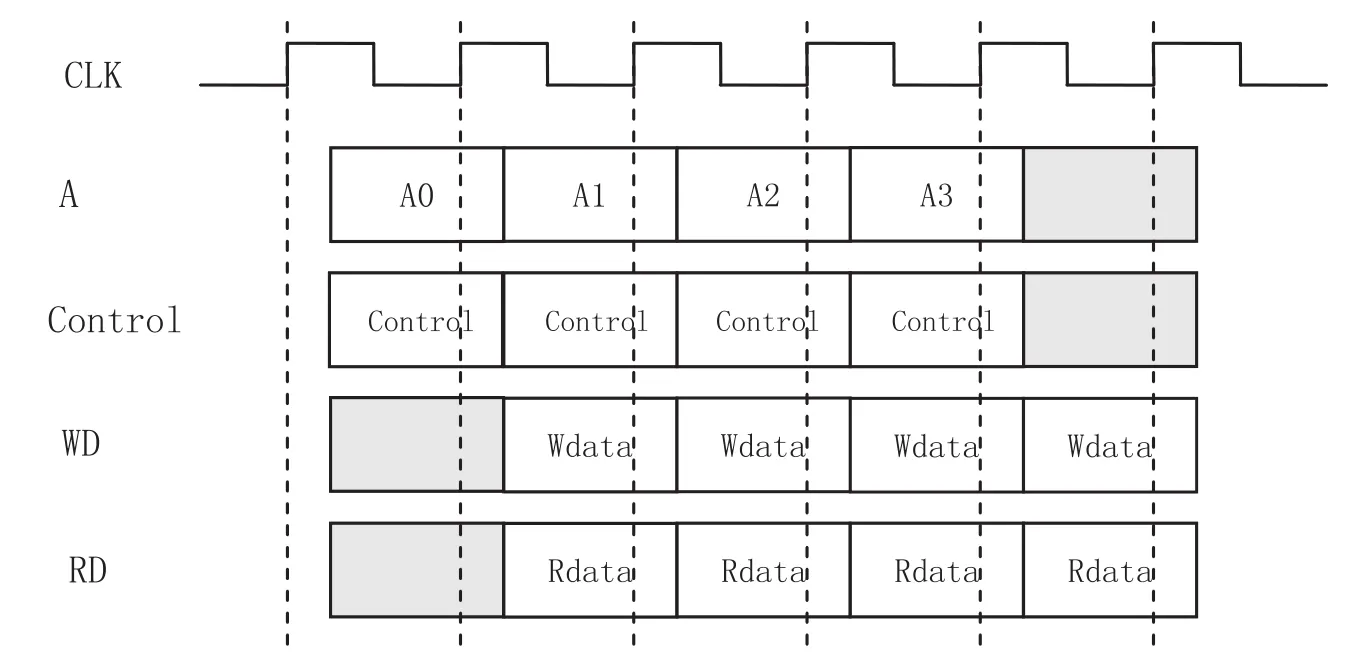
图6 CacheRam接口时序图
Cache控制器的功能实现依靠状态机设计完成。本Cache设计主要有6个状态机,一个主状态机,伴随5个次状态机完成Cache控制器所有功能的实现。这6个状态机的设计过程如下:
Cache状态产生状态机(见图7):产生Cache当前状态。有读存储器请求时,在Cache中没有命中,并且没有取消操作时进入Cache的行填充状态机进行linefill操作。有读存储器请求时,在FB命中,但是命中无效,说明linefill没有完成,需要的数据还没有进入BIU,并且没有取消操作时进入FB状态机进行等待。否则数据就在FB中保持准备好状态。根据上面三种情况和一些控制信号来判断当前的Cache是否是准备好状态。

图7 Cache状态产生状态机
行填充状态机(见图8):请求BIU传递8个linefill数据。在LF1状态下判断BIU是否正在line-fill一组数据或者是否有EWB数据还没有通过BIU写到外部存储器中,如果有就停留在LF1状态,如果没有或操作完成就进入PEND状态。在PEND状态中,查询总线的反馈信号,总线反馈后表示可以进行linefill操作,进入FB2状态开始linefill,并无条件进入IDLE状态,并且在IDLE状态下可以继续剩下的linefill操作。
FB状态机(见图9):在IDLE状态下判断是否有linefill请求或者如果有CP15的FB排空命令就进入LF1状态。在LF1状态下,判断BIU是否正在linefill一组数据或者是否有EWB数据还没有通过BIU写到外部存储器中,如果有就停留在LF1的状态,否则进入FB1状态。在FB1状态下,使能FB排空控制,将FB中的四个字写入Cache存储器中,然后进入FB2状态。在FB2状态下,将FB中的另外四个字写入Cache存储器中并无条件进入IDLE状态,完成linefill填充FB的过程。所以在整个过程中,FB中的内容不被写到Cache中,直到新的linefill情况发生时FB中的内容才被写入到Cache存储器中以便FB存放新的linefill数据,并且八个数据的写操作在两个周期内完成。
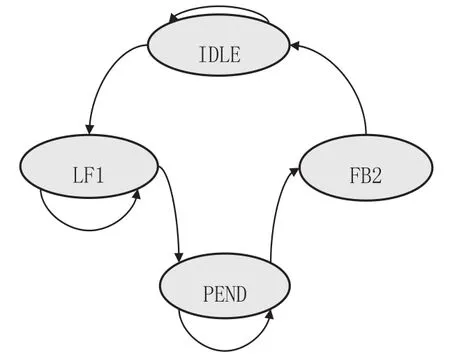
图8 行填充状态机
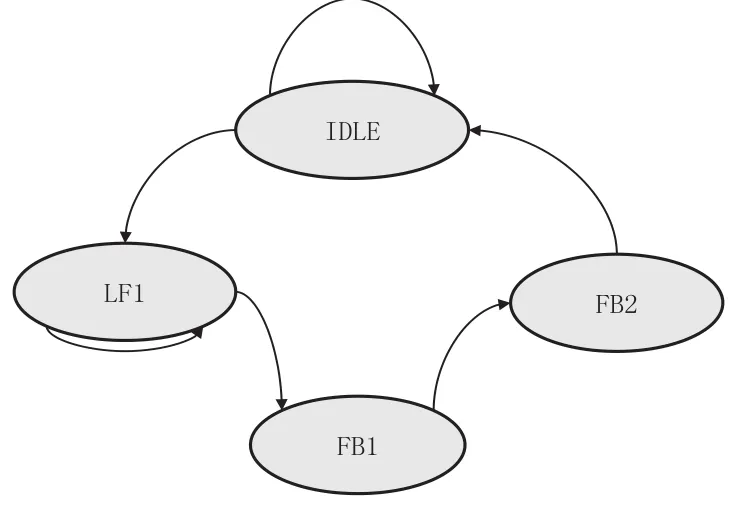
图9 FB状态机
写替换状态机(见图10):在IDLE状态下,如果有linefill发生并且将被替换的行中有dirty数据,就会进入下一个状态。可能进入的下一个状态是WAIT还是WB1则是根据当前EWB是否是空来决定,如果当前EWB不是空,则EWB处于busy状态,这时的下一个状态就应该进入WAIT状态,否则发出读取被替换行物理地址信息,读取被替换行的低四个字,然后进入WB1状态。在WB1状态下,读取被替换行的高四个字,写EWB的低四个字,申请BIU传输EWB数据,进入WB2状态。在WB2状态下,写EWB的高四个字,这时如果写数据缓冲器(PWB)中的一个数据是被替换行中的一个数据,则PWB中的这个数据写入到EWB中,进入EWB2状态。在EWB2状态下,如果PWB中的另一个数据是被替换行中的一个数据,则此数据也写入到EWB中。
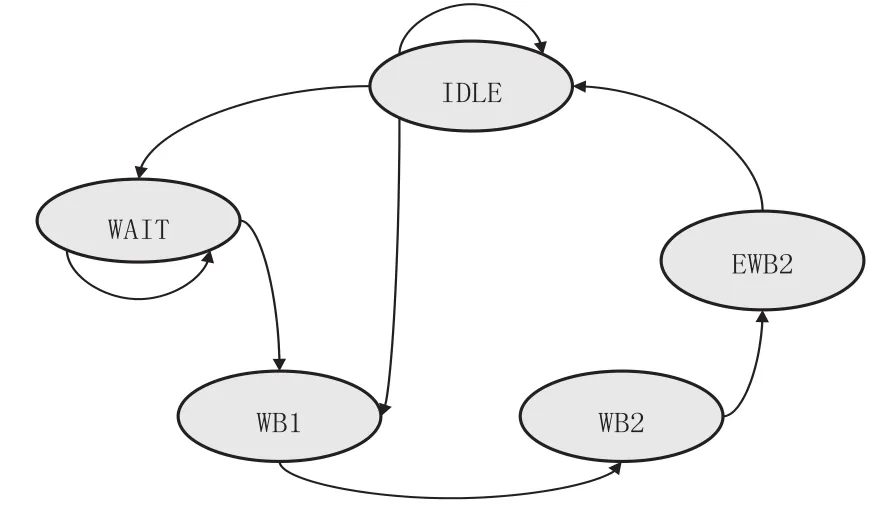
图10 写替换状态机
写替换总线状态机(见图11):在IDLE状态下,如果有替换请求,表示此时有新的数据填充到EWB中,需要总线将EWB中的数据写到外部存储器中,这时就会进入WB2状态。在WB2状态下,判断总线当前是否正在进行linefill的数据传输,如果没有,就进入EWB2状态,否则停留在WB2状态等待。在EWB2状态下,申请总线传输数据,并进入PEND状态。在PEND状态下,表示当前有一组EWB数据没有存储到外部存储器中,当总线完成传输后回到IDLE状态。

图11 写替换总线状态机
CP15控制状态机(见图12):在IDLE状态下,有CP15对Cache的操作控制,但不是使整个Cache无效的操作,就会进入下一个状态PW。在PW状态下,判断是否有未处理的操作,有写替换操作则保持在PW状态,linefill操作则进入FB1状态,否则进入OP1状态。FB1状态下,无条件进入FB2状态。在FB2状态下,判断本次linefill是否结束,如果没有结束,保持FB2状态不变,否则进入OP1状态。在OP1状态下,表示所有没有处理的操作全部结束,并判断CP15清除信号,如果信号有效,表示CP15没有其他操作,状态返回到IDLE状态,否则进入OP2状态。在OP2状态下,无条件进入OP3状态后进入OP4状态。在OP4状态下,如果是清除Cache操作,并且有dirty数据时就会进入OP5状态,否则返回到IDLE状态。在OP5状态下,要将Cache中的dirty数据通过EWB写到外部存储器中,完成后进入IDLE状态,否则停留在OP5状态等待dirty数据写替换完成。
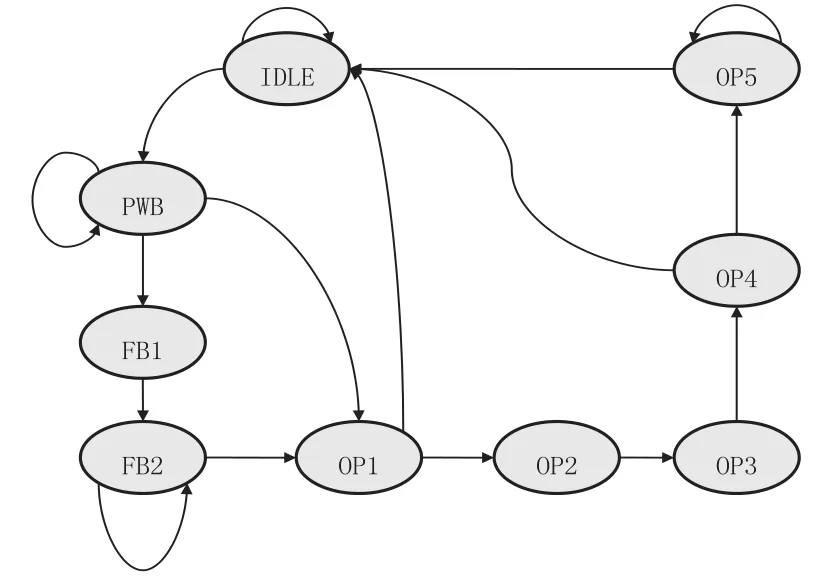
图12 CP15控制状态机
4 仿真验证
为了对设计的32位4路组相联Cache进行验证,需要搭建一个虚拟仿真验证平台,该平台的示意图如图13所示。
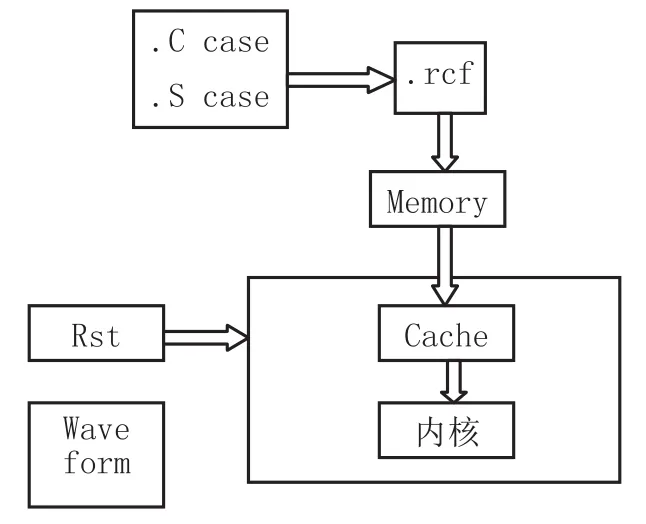
图13 仿真平台示意图
该平台包括以下几个部分:
(1)内核,实现32位微处理器的核心功能;
(2)Cache模块,包括4路组相联Cache控制器和存储器,完成Cache功能,是被测试模块;
(3)仿真环境测例,使用汇编语言或者C语言编写,然后转为*.rcf文件的格式,存放在Memory中;
(4)仿真用的Memory模型,用于存放仿真程序的二进制文件,存放仿真过程中产生的中间数据;另外该Memory模型也是该仿真平台的主存,使能Cache功能后,可以通过Cache进行缓存;
(5)仿真环境所需的复位信号(Rst)及时钟信号(CLK);
(6)在仿真过程中,可依据不同的仿真命令生成不同格式的仿真波形,waveform模型完成这部分功能。
5 结束语
介绍了Cache的基本原理,阐述了一款高速缓存Cache的设计,包括映射方式、种类、替换算法的设计以及Cache和Cache控制器的结构设计。可以用于32位微处理器系统架构中,解决慢速主存给处理器内核造成的存储器访问效率低下的瓶颈问题。
[1]万木杨.大话处理器-处理器基础知识读本[M].北京:清华大学出版社,2011.WAN Mu-yang.Topic Processor-Processor Basic Knowledge[M].BeiJing:Tsinghua University Press,2011.
[2]Peter Grun.Nikil Dutt.Alexandru Nicolau.Memory Architecture Exploration for Programmable Embedded Systems[M].New York:Kluwer Academic Publishers,2003.
[3]William Stallings.Computer Organization and Architechture[M].New Jersey:Prentice Hall,2010.
[4]Vincent P.Heuring,Harry F.Jordan.Computer Organization and Design(The Hardware/Software Interface)Edition[M].New York:Morgan Kaufmann,2008.
[5]Bruce Jacob,Spencer W.Ng,David T.Wang.Memory Systems(Cache,DRAM,Disk)[DB/OL].Burlington:Morgan Kaufmann,2008.
[6]D.Sweetman.See MIPS Run Linux[M].New York:Elsevier,2007.
[7]CoreLink Level 2 Cache Controller L2C-310 Technical Reference Manual[DB/OL].ARM Ltd.2012.
[8]杜春雷.ARM体系架构与编程[M].北京:清华大学出版社,2003.Du Chun-lei.ARM Architecture and Programming[M].BeiJing:Tsinghua University Press,2003.
Design of Cache Based on 32-Bit CPU System Architecture
Yang Da-wei,Wang Shuang,Wang Dan
(The 47th Research Institute of China Electronics Technology Group Corporation,Shenyang 110032,China)
With the development of the chip technology,the embedded processor catches the new opportunities,which is widely used in such fields as communication,multimedia,networking,entertainment,etc.The processing speed of the processor nearly increases in a certain index,while the slower processing speed of the memory becomes the major bottleneck of MCU system characteristics.Considering of balancing cost,performance and power,the cache widely is used in MCU system.In this paper,the principle of the cache is firstly described,the direct-mapping,full-associate cache and set-associate cache are compared as well.Then,the relationship between line size and hit rate is analyzed.Lastly,a cache,based on 32 bits processor architecture,is designed.
Cache;Set-associate;Linefill;Hit rate;Write-Through;Write-Back
10.3969/j.issn.1002-2279.2016.01.002
TN492
B
1002-2279(2016)01-0005-06
杨大为(1977-),男(回族),辽宁省沈阳市人,高级工程师,主研方向:集成电路设计。
2015-10-29
