异构环境下基于双重预取的Hadoop调度算法
2016-11-17孙玉强王文闻李媛媛顾玉宛
孙玉强,陆 勇,王文闻,李媛媛,顾玉宛
(常州大学 信息科学与工程学院,江苏 常州 213000)
异构环境下基于双重预取的Hadoop调度算法
孙玉强,陆 勇,王文闻,李媛媛,顾玉宛
(常州大学 信息科学与工程学院,江苏 常州 213000)
Hadoop处理海量数据时,无论是Map任务还是Reduce任务都需要耗费大量的时间传输数据,故提出一种基于双重预取的调度算法;该算法通过估算节点上任务执行的进度来预测Map任务的执行节点,然后通知节点提前预取所需的数据,并且在Map任务完成的数量达到预定值时,开始为Reduce任务预取部分数据;由于在异构的环境下集群中节点的性能各不相同,为此采取了改进的预测模型,以提高任务进度判断的准确性;实验证明,本算法在作业响应时间等方面优于现有的调度算法。
Hadoop;异构环境;调度算法;双重预取
0 引言
近年来,随着计算机的普及和信息技术的快速发展,互联网的使用也越来越广泛。与此同时,互联网上的数据也呈现出爆炸式的增长。例如,纽约证券交易所每天产生1TB的交易数据。FaceBook存储着超过1亿张照片,约1PB存储容量。据预测,2015 年全球产生的数据量将达到近10 ZB,而2020年全球产生的数据量将达到40 ZB。我们已经生活在一个大数据的时代,越来越多的公司需要面对大数据的处理问题。
传统的的解决方案存在着存储量小、稳定性差、耗时过长等缺点。当前广泛使用的大数据处理模型是由Google公司设计的MapReduce[1]编程模型。MapReduce作为并行分布式数据处理框架获得了极大的成功。MapReduce把海量的数据计算划分为许多小的任务,并且让它们在不同的节点上并行执行。它隐藏了底层处理的细节,为开发分布式应用提供了简单的编程接口。由于其具有良好的可扩展性、容错性、可用性等特点,使得其成为近年来数据处理领域的研究热点。Hadoop[2]平台作为MapReduce的开源实现,由于其良好的性能,已经被Yahoo!、Amazon等公司采用。
MapReduce的处理过程主要分为两步。首先是执行Map任务,处理输入数据并生成中间结果,将其存储在本地节点。然后Reduce任务远程读取这些中间结果,经过运算产生最终的输出结果。任务的执行需要调度器将用户作业队列中的任务分配给相应的节点,调度算法的优劣对于系统的性能起着至关重要的作用。为此,大量的学者对Hadoop的调度算法做了相关的研究。
常见的Hadoop调度算法有FIFO[3]调度,HOD[4]调度,公平调度[5]等算法。陶永才等人提出基于动态负载均衡的Hadoop动态延迟调度机制[6],金嘉晖等人提出基于数据中心负载分析的自适应延迟调度算法[7],两种方法均提高了作业的响应时间,但都没有考虑节点的异构性。M Zaharia等人针对异构环境提出推测任务剩余时间的LATE[8]算法,李丽英等人基于LATE算法提出数据局部性改进的调度算法[9]。但上述算法都缺乏对数据预取方面的考虑。本文提出异构环境下基于双重预取的Hadoop调度算法,以提高作业的执行效率。
1 MapReduce框架分析及问题的提出
如图1所示,MapReduce中任务的执行分为Map和Reduce两个阶段。在用户提交了一个作业后,输入数据被划分为多个数据块(默认为64 M),每个数据块对应一个Map任务。Map任务对输入进行处理生成
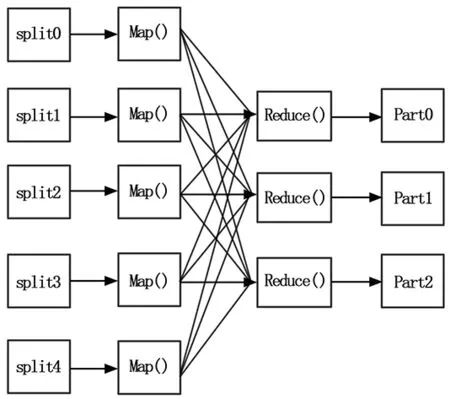
图1 MapReduce框架
Hadoop集群中有一个JobTracker负责调度作业运行。当JobTracker收到客户端提交的作业后,就把它放在一个队列中。调度器为其创建相应的Map和Reduce任务。其余的节点作为TaskTracker负责具体任务的执行并且通过心跳信号(heartbeat)与JobTracker进行通信。当某个TaskTracker有空闲资源时,就会向JobTracker请求新的任务,此时调度器会给这个节点分配一个Map或者Reduce任务。
通过分析MapReduce的执行流程可以发现,Map任务执行前如果没有取到相应的数据,会先远程读取所需要的数据。如果数据量非常大,那么Map任务的数量也较多,并且它们分布在集群中不同的节点执行,这将导致大量的数据传输开销。另外,Reduce阶段要等到所有的Map任务执行结束后才开始,并且同样需要传输大量数据。这些都会耗费大量的时间。
针对以上问题,本文将采用改进的调度算法,通过双重数据预取的方式来减少任务执行时读取数据的时间,提升Hadoop的执行效率。
2 改进的算法
本文提出的改进算法从两方面进行数据的预取。
1)在节点分配Map任务之前,通过预测模型找出最快即将完成任务的节点,通知相应的节点进行下次Map任务所需数据的预取。
2)在所有Map任务完成之前,即将进行Reduce任务的节点对Map任务已经生成的中间数据进行预取。
2.1 Map任务的数据预取
在MapReduce中,当一个节点被分配Map任务后,首先要获取任务所需要的输入数据。在最好的情况下,运行的任务和需要的数据在同一个节点上,则称其满足数据本地性,否则需要从远程节点进行读取。为了减少数据读取的时间,可采用数据预取的方式,使得当前任务的执行与下次任务数据的传输并行执行。
具体步骤如下:
1)TaskTracker节点检查其正在执行的任务,推测出任务结束还需要的剩余时间,并通知JobTracker节点。
2)JobTracker节点生成一个预调度节点队列PreNodes,并且设定一个阈值MapThreshold,把剩余时间低于阈值的节点加入队列。时间越短的在队列中的位置越靠前。
3)JobTracker从任务队列中取出即将调度的任务,预先将其分配给队列中最前面的节点,并且通知其预取相应的数据。
4)接收到预取数据任务的节点开始预取下一次Map任务的数据。
首先,为了让节点推测出任务执行需要的剩余时间,就需要一个推测模型。Hadoop根据任务的执行进度判断任务执行的快慢。但是在异构的环境下,每个节点的CPU、内存以及I/O性能都不一样,因此上述方法并不适用于判断任务的剩余完成时间。目前有一种针对异构环境的LATE算法,其核心思想是通过执行进度判断任务的速率进而推算出任务的剩余完成时间,这正符合我们的目的。
LATE算法的计算公式如下所示:
(1)
(2)
其中:ProgressScore是任务执行的进度,量化为百分比。T是任务已经运行的时间,TimeRemain是任务完成需要的剩余时间。
ProgressScore的值基于任务执行的阶段。在此处我们仅仅关注Map任务,Map任务的执行被划分为两个子阶段:1)Map函数执行,占2/3;2)sort和partition阶段,占1/3。但是由于在异构环境下节点差异较大,任务执行的各阶段比例也会有所不同,所以采用固定的划分方式并不合理。为此,本算法在TaskTracker执行Map任务时,把各阶段的比例信息保存在磁盘中。下次执行任务前,首先读取应用的历史执行信息,动态确定各阶段的比例,使得每个节点都能得到更准确的进度值。ProgressScore与运行时间T的比值则为当前任务的速率ProgressRate,用任务剩余进度除以速率则可以估算出任务完成需要的时间。
为了实现预取数据的保存,TaskTracker节点必须做相应的改进。鉴于目前节点的内存都比较大,可直接把数据预取到内存中,加快Map任务的执行速度。为此,把节点的内存划分为两部分。一部分存放当前任务的数据,另一部分用于存放下次Map任务的数据。当前任务结束后,其所使用的数据空间将用于下次任务预取数据的存储,而当前的预取数据将成为下次任务的输入数据。这两部分空间轮换使用,从而达到数据预取的目的。
如图2所示,当JobTracker节点预判到map6这个任务即将在节点1执行时,就会给节点1下达预取指令,于是节点1从节点2开始传输map6所需的输入数据。
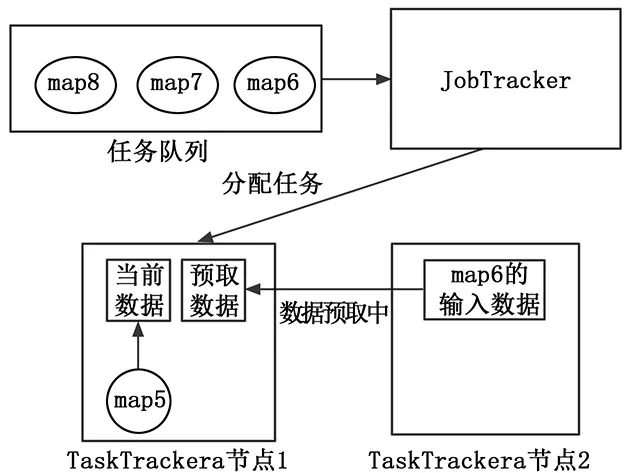
图2 数据预取模型
该预取算法伪代码描述如下:
for each map in TaskTracker do
TimeRemain = (1-ProgressScore)/ ProgressRate
endfor
sort(nodes)
if nodes.TimeRemain < MapThreshold then
queue.offer(nodes)
end if
for maps in job queue do
nodes ← map //把map任务分配给node节点
if nodes没有map任务的数据then
nodes begin data perfecting;
endif
end for
2.2 Reduce任务的数据预取
Reduce任务必须等到所有的Map任务执行完成之后才开始执行,第一步是从相应的节点将Map生成的中间结果进行拷贝,一样需要数据传输的开销。为此,同样对Reduce任务进行数据的预取。
Redecue任务的数据预取与Map任务的预取相似,但不同的是由于Reduce任务的输入数据来源于Map任务的输出,所以其数据预取不能依靠当前节点Reduce任务的剩余时间。本算法采取的策略是,利用式(3)计算已完成任务的Map数量与Map任务的总数量之比。当比值达到一个设定的阈值ReduceThreshold之后,即开始为Reduce任务进行预取。
(3)
其中:MapNumsfinished为已完成的Map任务数,MapNumstotal为Map任务总数量。
在为Reduce任务预取中间结果的时候,可能会出现多个节点同时从相同的输出结果预取数据,由此造成I/O资源的竞争,降低了预取的效率。为了解决这个问题,采用冲突检测的方式来为Reduce任务预取数据。当某个Reduce任务预取的数据所在节点已经有其它任务正在预取时,则先跳过这部分数据,转而预取其他节点上的所需数据。如果所有的节点都被其他任务占用,则等待一段时间再发起预取请求。等待时间设定如下:
(4)
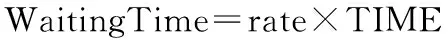
(5)
式(4)中Datafinished是已经预取的数据,Datatotal是需要预取的数据总量,Ratedata则为任务的数据预取率。TIME是一个时间常数,表示集群中传输一个数据块所用时间。WaitingTime则是等待时间,与数据预取率成正比。数据预取率较高的,等待时间也较长,以保证各Reduce任务均衡预取。
由于随着时间的推移,Map任务完成的数量越来越多,所以需要循环地探测执行Map任务的节点,获取更多地数据。该过程算法伪代码描述如下:
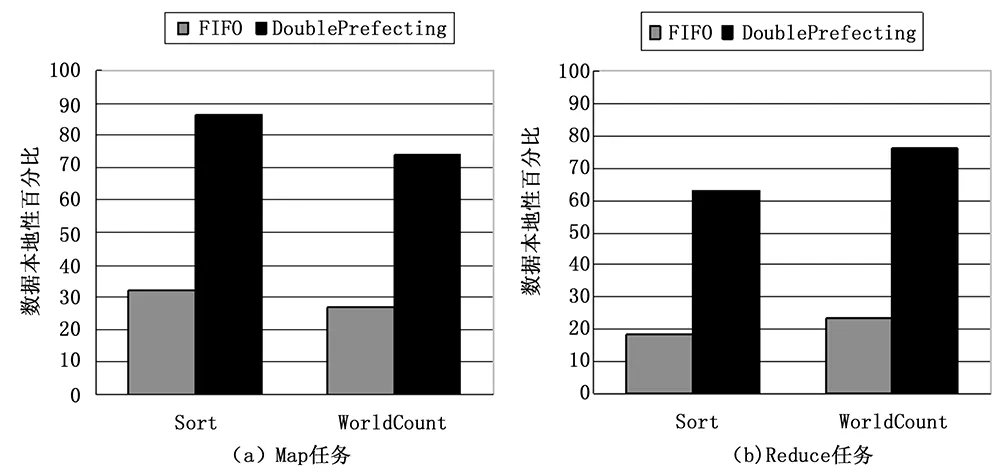
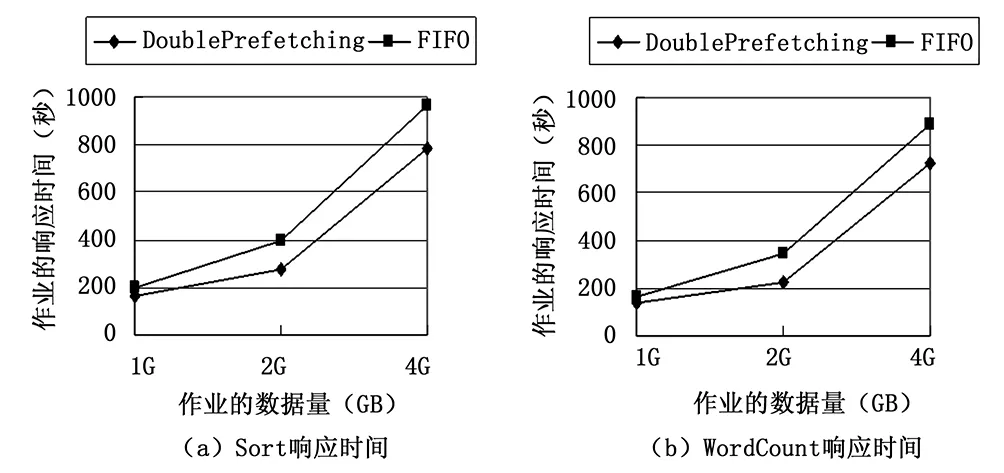
whileRate Rate=MapNumsfinished/MapNumstotal endwhile while!(allmapshasfinashed)do foreachnodeinNodesWithReduceTaskdo iftaskneedsmoredatado prefectchingdata if预取冲突then WaitingTime=rate*TIME//等待 endif endif endfor endwhile 本实验采用虚拟机的方式搭建异构环境,各PC机采用 100M的局域网互联。虚拟机使用VMwareworkstation10.0安装的CentOs6.5 32位系统。JDK版本为1.7.0_45,Hadoop版本为0.20.1。具体集群配置如表1所示。 表1 Hadoop集群环境配置 实验中选取的任务是Sort和WordCount。因为这些任务涉及到大量数据的传输,有利于比较算法之间的差异。在HDFS中数据块设为默认的64 M,且每个数据块保存2个副本。图3(a)和图3(b)分别是Map任务和Reduce任务的数据本地性比较。 图3 任务数据本地性对比 通过图3可以看出,相比于传统的无数据预取的FIFO算法,执行数据预取之后的Map任务和Reduce任务的数据本地性都得到极大提高。当然,对于作业执行效率的分析最重要的是响应时间。对上述任务设定不同的数据量多次执行后得到图4的响应时间图。从图中可以推算出,通过双重的数据预取后作业的响应时间提升了大约18%。 图4 作业响应时间对比 针对Hadoop作业执行时的数据本地性问题,本文提出基于双重预取的调度算法。通过预测任务的执行节点,为Map任务预取所需的数据。在Map任务完成了一定数量后,预先为Reduce任务拷贝Map已经生成的中间结果,解决了Reduce任务的远程调度问题。另外,算法充分考虑异构环境下节点性能的差异,采用改进的LATE算法以便更准确地判断任务的执行进度。实验证明,使用数据预取有效提高了作业的响应时间。 [1] Dean J, Ghemawat S. MapReduce: simplified data processing on large clusters[J].Commun. ACM 51 (1) (2008) 107-113. [2] White T. Hadoop: The Definitive Guide[Z]. O’Reilly Media,Inc., 2009. [3] HADOOP-3759: Provide ability to run memory intensive jobs without affecting other running tasks on the nodes[EB/0L].https://issues.apache.org/jira/browse/HADOOP-3759. [4] Apache. Hadoop On Demand[DB/OL]. http://hadoop.apache.org/common/does/r0.17.2/hod. html, 2008,20(8). [5] Zaharia M,Borthakur D,Sarma J S,et al.Job Scheduling for Multi-user MapReduce Clusters[R].EECS-2009—55.April 2009. [6] 陶永才,李文洁,石 磊,等.基于负载均衡的Hadoop动态延迟调度机制[J].小型微型计算机系统,2015,3(3):445-449. [7] 金嘉晖,罗军舟,宋爱波,等.基于数据中心负载分析的自适应延迟调度算法[J].通信学报,2011,32(7):47-56. [8] Zaharia M, Konwinski A, et al. Improving mapreduce performance in heterogeneous environments[A].Proc of USENIX conference on Operating systems design and implementation[C].Berkeley:USENIX Association,2008:29-42. [9] 李丽英,唐 卓,李仁发.基于LATE的Hadoop数据局部性改进调度算法[J].计算机科学,2011(11):67-70. Scheduling Algorithm Based on Double Prefetching in Heterogeneous Hadoop Clusters Sun Yuqiang, Lu Yong, Wang Wenwen, Li Yuanyuan, Gu Yuwan (School of Information Science & Engineering, Changzhou University, Changzhou 213000,China) When Hadoop processing huge amounts of data, both in the Map tasks and Reduce tasks requires a lot of time to transfer data. This paper presents a scheduling algorithm based on double prefetching, the algorithm predicts the node which will execute the Map task by estimating the progress of running tasks, so that the node can prefetch required data for Map tasks. Moreover, the system can also prefetch the data for Reduce tasks while Map tasks are running. Due to the performance of the cluster nodes in heterogeneous environment are not identical, the algorithm adopts an improved prediction model to improve the accuracy of the judgment of task progress. Experiments show that the algorithm is superior to the existing scheduling algorithm with less response time. Hadoop;heterogeneous;scheduling algotithm;double prefetching 2016-02-29; 2016-04-25。 国家自然科学基金项目(11271057);江苏省普通高校研究生科研创新计划项目(SCZ1412800004)。 孙玉强(1956-),男,博士,教授,主要从事并行计算、软件工程方向的研究。 顾玉宛,女,博士生,通讯联系人,主要从事并行计算和图像处理方向的研究。 1671-4598(2016)09-0172-04 10.16526/j.cnki.11-4762/tp.2016.09.048 TP3 A3 实验


4 总结
