基于云计算的后勤保障资源数据处理平台研究与设计
2016-11-17武警工程大学研究生管理大队
武警工程大学研究生管理大队 杨 曦
武警工程大学信息工程系 巩青歌
基于云计算的后勤保障资源数据处理平台研究与设计
武警工程大学研究生管理大队 杨 曦
武警工程大学信息工程系 巩青歌
近年随着全军信息化建设的迅速发展,后勤保障信息化势在必行,当前每天产生于后勤保障相关的数据量巨大,既有传统保障资源数据,又有与部队相关的文件资料、战场态势及流媒体中的信息等非结构化数据,但目前没有对这些保障资源实现集中、统一调配,许多资源数据没有得到很好的利用。本文针对这一问题提出基于云计算的后勤保障数据处理平台,对后勤保障工作相关数据进行采集、分析及处理,实现保障资源综合管理,为部队快速、高效地完成后勤保障任务提供可行性。
云计算;后勤保障;综合管理
0 概述
武警部队担负着维护国家安全和社会稳定,保障人民安居乐业的神圣使命,是社会主义现代化建设的武装保障。当前环境下,突发事件难以预料、情况复杂;抢险救灾事发突然、形势紧急,处置突发事件、担负抢险救灾和遂行维稳反恐行动已成为武警部队执勤的重要任务,其中,后勤应急保障工作作为日常工作中的支撑,在当前环境下也变得越来越重要。
在大数据时代的今天,信息产业高速发展,武警部队三级网系统中的服务器每天产生、更新、处理、存贮巨大的有价值资源数据,面对如此庞大复杂的数据,需要进行整理、辨别、运算,才能将隐含的、凌乱的、未知的及有潜在应用价值的可用信息转化为进行决策的支撑、依据,为决策支持提供数据依据。在本系统中拟利用云计算平台对以上的数据进行处理、分析,实现保障资源数据的综合、一体化服务,便于部队完成平时保障任务,同时为战时应急保障任务提供数据支持,为首长决策提供可靠的参考依据。
1 基于Hadoop保障资源数据处理平台架构
本文依据当前形势和背景,设计了基于Hadoop的保障资源处理平台,如图1所示。首先,在数据组件、模型组件、互联网组件以及获取相关数据的互联网关键节点部署数据获取设备,对当前网络中的流量数据进行采集。将收到的原始数据通过数据转发的分类、合并、转发等操作,最终上传至Hadoop平台的数据存储区。为保证存储数据的准确、全面、可靠性,首先使用HDPF[1](Hadoop-based Data Processing Framework)模块对原始保障资源数据进行预处理,过滤其中错误、无用及残缺数据,将预处理后的初级数据存入HDFS中。由于这些实时数据来自互联网,绝大多数是半结构化、非结构化的数据,本文针对以上特点,利用MapReduce技术进行分析处理。当决策者需要时,调用MapReduce分析处理存储在HDFS中的海量资源数据及与资源保障相关的数据,从中获取有利用价值的分析结果例如受灾地区的天气、交通状况,群体性事件中闹事群体的规模、集结的范围等战场态势数据。
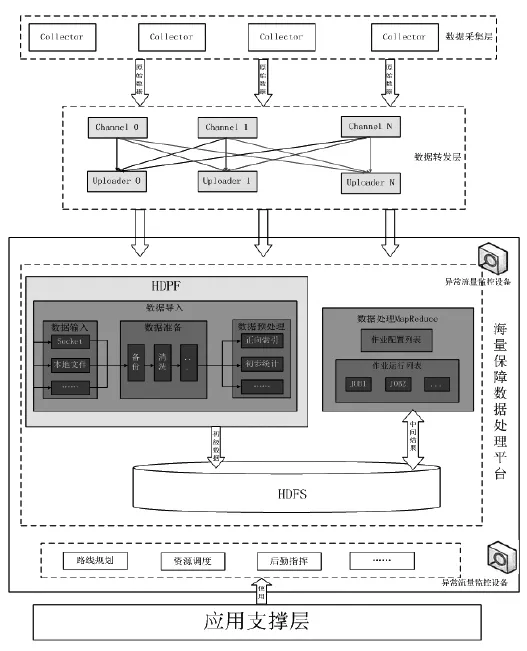
图1 基于Hadoop保障资源数据处理平台架构
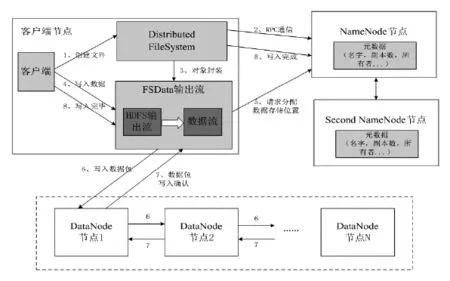
图2 HDFS数据写入流程
2 基于HDFS分布式后勤保障资源数据存储
HDFS文件系统对海量后勤保障资源数据处理平台提供据存取服务,包含NameNode、SecondNameNode和DataNode三类节点[2],具体功能:
(1)NameNode:就是主控制服务器,管理文件系统命名空间(Namespace)同时管理目录和元数据。NameNode节点存储与数据块有关信息,如文件和数据块、数据块和DataNode节点之间的映射关系。
(2)Second NameNode:当NameNode节点发生故障时作为备用节点,可以对数据进行恢复,保证HDFS系统正常工作。它与NameNode节点保持定时通信,并对其元数据信息进行复制备份。
(3)DataNode:DataNode节点维护其存储的数据块管理工作,属于从节点。HDFS将文件分块存储,每个数据块默认为64MB,将它们存储在不同的DataNode节点中。同时依据HDFS默认设置的3个副本,在多个DataNode备份相同数据块。
当用户需将文件写入到HDFS系统中时,通过客户端向NameNode节点申请包括写入的各个DataNode节点的数据块信息。NameNode依据申请分配节点,在HDFS文件系统的默认配置中认为所有机器在同一机架。数据写入流程如图2所示。
(1)客户端调用DistributedFile-System类实例化对象,同时调用create方法生成新文件。
(2)DistributedFileSystem对象向NameNode节点发出RPC请求,NameNode节点依据用户的权限判断是否创建,若判断不通过,NameNode则返回异常信息,写入操作终止,否则继续。
(3)DistributedFileSystem 封装一个 FSDataOutputStream 对象,以备写入数据到新文件中。
(4)通过客户端用户在新生成文件中写入数据。FSDataOutputStream将数据切分为多个数据包,同时将它们组成数据流,以便之后写入DataNode上的数据块。
(5)FSDataOutputStream向NameNode请求数据存储空间,即数据块和DataNode节点信息。依据HDFS配置副本数决定DataNode节点数。
(6)FSDataOutputStream将数据包组成的数据流逐个写入第一个DataNode节点,由该DataNode接着写入第二个DataNode,当所有需要写入的DataNode写入完毕后停止。
(7)写入完成的DataNode向源节点发送确认报文,证明完成写入操作。若该过程某个DataNode节写入失败,NameNode分配新DataNode继续写入操作当数据包在指定DataNode完成写入后,将其从数据流中删除,认为一个数据包写入操作完成。
(8)当所有数据包写入完成,则本次用户写入数据流程结束。
3 基于MapReduce海量网络保障资源数据处理
MapReduce[3]最早由谷歌公司提出同时运用至网络搜索服务的编程模型,采用分布式并行计算,可以处理TB甚至PB级别数据,是Hadoop架构最核心技术之一。
MapReduce技术主要有Map函数和Reduce函数组成[4],以键值对(Key-Value)[5]作为输入及输出,用户可根据需求自定义MapReduce函数,系统在接收海量的与保障资源相关信息数据后,通过MapReduce框架对数据进行处理。以油料资源为例,该资源数据包括油库的地理位置、油库名称、储油量、日常消耗等数据,可以用于保障任务中的油料供应点分析、资源调度点分析,以及调度路线规划等各方面数据挖掘及分析。这些类型的数据采集一周或半月数据量将达到TB级别,使用普通服务器对其进行处理,将消耗大量时间,利用MapReduce技术可以在短时间内高效完成。例如:加油站代号作为Key值,日消耗和供给量为Value值,可以快速统计该区域内承担业务最多的加油站等有用规律。
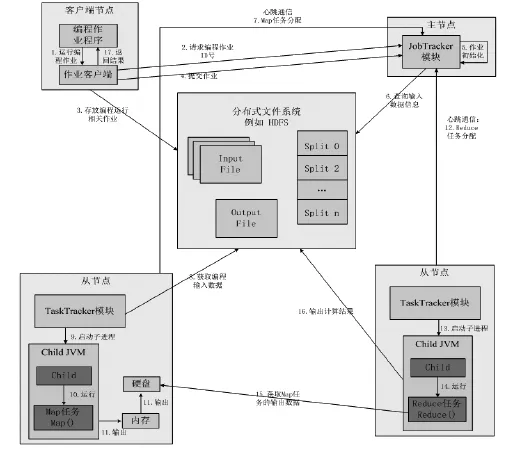
图3 MapReduce框架运行流程
MapReduce技术为满足用户需求,提供了可编写的编程模型,用户根据所需编写Map、Reduce函数后就可在Hadoop平台中运行程序,得到分析结果。Hadoop平台的MapReduce框架采用主从架构,由一个JobTracker主节点和多个TaskTracker从节点组成,JobTracker负责包括确定用户提供编程的执行顺序、Map和Reduce任务的分配的编程调度。TaskTracker负责包括Map和Reduce任务以及推测性任务的执行等主节点指定的任务。运行流程如图3所示。
(1)用户提交编程作业。用户根据所需编写MapReduce程序并运行,编程客户端向JobTracker提交该编程相关信息,申请编程作业ID号,在客户端验证编程无误后,将编程资源储存至HDFS中,最后客户端向JobTracker申请执行编程。
(2)JobTracker初始化用户编程。JobTracker接收编程后,创建与之相关数据及编程对象,然后JobTracker根据配置的调度算法,将编程放入编程栈中,以便后续分配。
(3)任务分配。从TaskTracker模块定时向JobTracker发送信息,JobTracker程序栈如果存在待分配的编程,综合收到的信息判断是否向TaskTracker分配任务,当TaskTracker的Map任务槽有空余时,JobTracker依据策略向该节点分配合适Map任务。当JobTracker分配任务时,优先考虑给TaskTracker分配Map任务,只有当TaskTracker模块上任务槽空闲才分配Reduce任务。
(4)TaskTracker执行任务。TaskTracker每执行一个Map或Reduce任务,就启动一个Java子进程运行。首先TaskTracker从HDFS读取在编程客户端有关的信息,再创建Java子进程执行用户编写的Map任务,运行后定期向内存缓存数据。当缓存数据大小超出限定时,Map任务将其存入从节点磁盘。
(5)TaskTracker执行Reduce任务。当Map完成任务,若TaskTracker模块存在空闲Reduce槽,则TaskTracker从节点与JobTracker通信,JobTracker将该编程分配给Reduce的相应从节点。由于Reduce任务来源于各Map任务输出,因此JobTracker可直接分配Reduce任务。
(6)完成编程运行。Reduce任务结束后,其结果存入用户指定目录。JobTracker依据各TaskTracker发送信息,对编程设置完成标记,同时向编程客户端通知编程完成。需说明的是,客户端在编程运行期间持续掌握运行进度信息。
4 总结
本文为解决当前武警部队后勤保障任务大量数据的分析、处理及储存等问题,设计了基于云计算的后勤资源保障数据处理平台,研究了基于Hadoop保障资源数据处理平台架构、基于HDFS分布式后勤保障资源数据存储平台、基于MapReduce海量网络保障资源数据处理平台,为后勤保障平时任务的完成提供数据管理服务,为战时应急保障决策提供数据支持。
[1]刘丽,司小磊,张莹,彭弗楠.基于云计算的幼教资源管理平台实现[J].电脑知识与技术,2014,4:12-17.
[2]杜忠晖,何慧,王星.一种Hadoop小文件存储优化策略研究[J].智能计算机与应用,2015,3.
[3]田进华,张韧志.基于MapReduce数字图像处理研究[J].电子设计工程,2014(15).
[4]徐鹏.云计算平台作业调度算法优化研究[D].山东师范大学,2014.
[5]林智煜.基于海量高维图像的大数据处理框架[J].电子科技大学,2014.
巩青歌,教授,硕士生导师,研究方向:武警信息化研究,数据挖掘,数据库。
杨曦(1991—),女,硕士研究生,研究方向:武警信息化研究。
