基于多约简Fisher-VSM和SVM的文本情感分类
2016-11-09邢玉娟曹晓丽
邢玉娟 谭 萍 曹晓丽
(兰州文理学院数字媒体学院 甘肃 兰州 730000)
基于多约简Fisher-VSM和SVM的文本情感分类
邢玉娟谭萍曹晓丽
(兰州文理学院数字媒体学院甘肃 兰州 730000)
为了提高文本情感分类准确率,提出基于多约简Fisher向量空间模型和支持向量机的文本情感分类算法。该算法首先采用Fisher判别准则提取TF-IDF特征向量,然后依据低维文档向量空间模型间的相似度对文档进行聚类,减少文档的数目。该算法从维度和数量两个方面对文档的向量空间模型进行约简,以期提高支持向量机的训练速度和分类性能。仿真实验结果表明,该算法具有良好的召回率和分类准确率。
文本情感分类Fisher 判别比向量空间模型支持向量机
0 引 言
随着互联网技术的飞速发展,人们将网络作为发表个人观点、评价产品和服务的平台,相应的网络文本评论信息呈爆炸式增长。如何对海量的网络文本信息进行归纳处理,判定其表达的情感观点,如肯定和否定,成为当前互联网智能信息处理的研究热点。在电影评论、产品质量与服务评价、社会舆情分析、有害信息过滤、Blog评价、新闻报道评述、股票评论、图书推荐、敌对信息检测等领域具有广阔的应用前景和市场价值[1]。文本情感分类属于一种文本分类,它是对文本信息进行分析、处理、归纳和推理,从而判定其表达观点(肯定/否定)的过程。在文本情感分类中,有效情感特征的选择以及判别算法的设计是关键。
基于统计的文本向量空间模型VSM(Vector Space Model)的提出,使得机器学习算法可以广泛地应用于文本情感分类。多种机器学习算法如支持向量机SVM、经典朴素贝叶斯NBve Bayes)、最大熵ME(Maximum Entropy)等广泛地应用于文本情感分类。文献[2]最早采用NB、ME和SVM对Internet上的电影评论文本进行分类,验证了机器学习算法在文本情感分类中应用的可行性。同时实验结果表明,SVM具有良好的泛化能力和较高的分类精确率,性能优于NB和ME。文献[3]将形容词及其修饰词作为文档候选特征,建立VSM,并采用SVM进行分类,判断文档的正面和负面观点,获得了较好的实验结果。文献[4]在情感词典上选择和加权文档的情感特征,使用SVM判定情感极性。肖正等[5]采用SVM在基于“词-文档”的语义距离向量空间上判定文档情感极性的分类,获得较高的分类准确率。杨经等[6]采用SVM并结合词性特征和语义特征对句子进行情感识别和分类。由此可见,SVM作为典型的机器学习方法在文本情感分类中获得了成功的应用。
然而,由于文档的规模较大,且VSM的初始特征向量的维数较大,需要大量的存储资源和较高的计算复杂度,在很大程度上影响了SVM的训练速度。因此在基于SVM的文本情感分类中,文本特征向量的选择和约简直接影响到系统性能。文献[7]将文档频率加权方法和信息增益IG(Information Gain)、互信息 MI(Mutual Information)等特征贡献评估方法相结合,进行高判别性特征的选择。文献[8]提出一种基于多重词典的特征选择算法,实验结果表明,该算法具有良好的性能。Wang等[9]提出一种基于改进的Fisher判别比的文本特征选择方法,通过计算文本特征项词频和布尔值的Fisher判别比来衡量特征项的贡献程度。然而词频和布尔值只反映了特征项在所属文档出现的次数或是否出现,无法衡量特征项在文档集上的特性。
在以上研究工作的基础上,本文提出一种基于多约简Fisher-VSM和SVM的文本情感分类算法。该算法首先采用Fisher判别准则剔除VSM中的冗余和噪声信息,在特征加权方面采用词频-逆文档频率法以克服词频法和布尔值的缺陷;然后对文档进行相似性聚类。在保证文本特征向量高判别性的前提下,从文档VSM的维数以及数量两个方面进行约简,以期加快SVM的训练速度,减少SVM的计算复杂度和空间占用,进而提高文本情感分类系统的性能。
1 相关理论
1.1向量空间模型
在向量空间模型VSM[2]中,依据特征项在所属文档中的重要程度,将文档数字化为一高维向量,每一个特征项对应向量的一维。如何衡量特征项的重要程度是文档向量空间模型建立的关键。常用的特征项权重计算方法主要有:二值法、绝对词频TF(Term Frequency)法、逆文档频率IDF(Inverse Document Frequency)法和词频-逆文档频率TF-IDF(Term Frequency-Inverse Document Frequency)法[10]。二值法是最简单的权重计算方法,反映特征项是否在文档中出现;绝对词频法主要反映特征项在文档中出现的次数,是一种局部文本信息加权方法;逆文档频率法反映该特征出现文档的数目,是一种全局信息加权方法;TF-IDF法既考虑到了文本信息的局部特性,同时也兼顾了特征项的全局特征[11],是目前使用最为广泛的文档特征加权方法,其计算公式如下:
(1)
其中di表示含有N个文档的文档集D={D1,D2,…,DN}中第i篇文本Di的数字化向量,di=(w1,i,w2,i,…,wn,i),wji(j=1,2,…,n)表示文档Di中出现特征项tj的权重,n表示特征项的个数。
1.2支持向量机
支持向量机[12]是基于结构风险最小化原则在两类中寻找最优分类边界,在数据分类方面显示了优越的性能。它的基本原理是首先通过非线性变换将输入空间映射到一个高维特征空间,然后根据核函数在这个新空间中求取最优线性分类平面。支持向量机由于具有较高的分类精确率和召回率,且具有较好的稳定性,被广泛地应用于文本分类中。并且支持向量机的分类超平面有效地克服了特征冗余、样本分布以及过拟合等因素的影响,具有较好的泛化能力。然而,它在大数据集上训练收敛速度较慢,并需要大量的存储资源和较高的计算复杂度。采用输入向量进行SVM的训练,可得到决策分类函数:
(2)

(3)
2 多约简Fisher判别性向量空间模型
文档的VSM维数较高,且包含大量的噪声信息和冗余信息。为了更好地选择高判别性的低维文档特征向量,减少相似文档对分类算法的影响,本文提出多约简Fisher判别性向量空间模型Fisher-VSM,并采用SVM判定文档的观点。本文提出的文本情感分类系统框图如图1所示。

图1 基于多约简Fisher-VSM和SVM的文本情感分类系统框图
由图1可知,本文提出的算法主要包括文档VSM维度约简和文档VSM聚类两个方面。由于文档的TF-IDF权特征不仅考虑到特征项在所属文档中的特性,同时也兼顾特征项在整体文档集中的分布情况,具有比二值法、词频法和逆文档频率法更优的分类特性。因此,本文提出采用Fisher 判别准则选择高判别性的低维的文档TF-IDF特征。
2.1低维Fisher-VSM
Fisher判别准则[13]的基本原理是通过寻找特征向量的投影空间,使得特征向量在该投影空间的分离度最大。它在去除噪声特征以及判别性能较差的特征和去除冗余特征方面具有良好的性能[14]。

(4)
(5)
(6)
(7)
则tk的Fisher判别比值为:
(8)
其中:
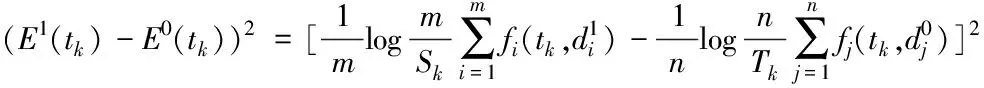
(9)
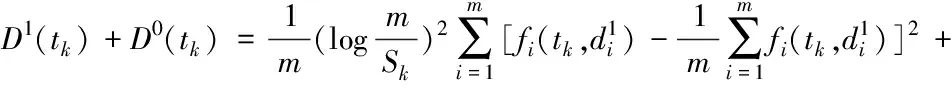

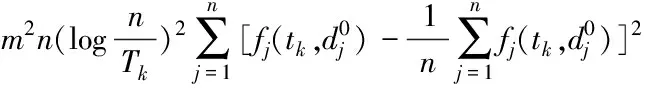
(10)
将式(9)和式(10)代入式(8)即可计算特征项tk的Fisher比值,该公式的计算复杂度为O(m+n)。F(tk)值越大,表明该特征项对分类的贡献越大。因此,可根据该公式分别对文档集中的特征项计算其Fisher判别比值,并由大到小排序,选择值最大的前q个特征项构建文档Fisher判别性VSM(Fisher-VSM)。
2.2Fisher-VSM聚类
本文在K-均值聚类算法的启发下,提出Fisher-VSM聚类算法。该算法在采用Fisher准则得到的约简向量集上,以文档间的差异度作为相似文档的衡量标准,对文档集进行聚类,以减少文档集的规模,进一步加快SVM的训练速度。同时,为了加快聚类算法的收敛速度,采用粒子群算法[15]全局搜索最优聚类中心。本文算法区别于K-均值聚类算法的优点是:原始数据集经过了Fisher降维处理,且采用粒子群确定聚类中心,聚类算法收敛速度较快、计算复杂度低。
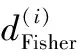
(11)
在本文的聚类算法中,假设初始化m个粒子群,则第i个粒子的位置为xi=(xi,1,xi,2,…,xi,q),速度为vi=(vi,1,vi,2,…,vi,q)。种群的个体极值为pi=(pi,1,pi,2,…,pi,q),全局极值为g=(g1,g2,...,gq)。粒子的速度和位置更新公式为:
vi=ωvi+c1·r1()·(pi-xi)+c2r2()·(g-xi)
(12)
xi=xi+vi
(13)
其中,r1()和r2()是分布在[0,1]之间的随机数;c1和c2是加速常数,本文取值为2;ω为惯性权值,用于平衡全局搜索和局部搜索。
Fisher-VSM聚类算法的具体步骤如下:
Step1设定聚类的类别数为C,随机指定C个文档的Fisher-VSM作为最初聚类中心,将各类的聚类中心作为粒子的初始位置,计算粒子的适应度,初始化粒子速度,反复进行m次,生成m个初始粒子群;Rs=0(s=1,2,…,C)用于记录属于当前类别s的文档的数目。
Step2将当前位置设置为个体极值位置,当前位置的适应度为个体极值,并根据各个粒子的个体极值找出全局极值和全局极值位置,调节ω的值。
Step3根据式(12)和式(13)更新粒子的位置和速度。
Step4在当前位置对文档特征向量进行聚类
Step4.2选择与聚类中心差异度最小的文档划分到相应的类中,Rs=Rs+1,重新计算文档聚类中心模型Ms。
Step5重复执行Step2至Step5,直到聚类中心向量不再变化为止。
3 仿真实验与分析
3.1实验语料库
实验语料库采用谭松波博士收集整理的中文语料库中的酒店评论数据[16],随机选取数据中正面和负面各1200篇,总共2400篇评论用于模型的训练,选取正负各800篇,总共1600篇用于测试。通过ICTCLAS汉语分析系统对所有的语料文本进行分词,标记词性,选择具有较重感情色彩的名词、形容词和副词作为候选特征项。性能衡量标准为分类准确率(CR)、正面查准率(PP)、正面召回率(RP)、负面查准率(PN)、负面召回率(RN)正面综合准确率(FP)和负面综合准确率(FN),计算公式[11]如下:
(14)
(15)
(16)
(17)
(18)
(19)
其中,aP表示正面文本中正确分类的文本数,aN表示负面文本中正确分类的文本数;bP表示分类为正面的文本数,bN表示分类为负面的文本数;cP表示正面文本数,cN表示负面文本数。
3.2实验结果及分析
实验1:SVM分类性能测试分析
该实验测试SVM、经典朴素贝叶斯NB和最大熵三种经典机器学习方法对文本情感分类性能的影响,采用TF-IDF函数为特征加权。实验结果如表1和图2所示。

表1 不同分类算法性能比较

图2 不同分类算法性能比较
由表1可知,在三种分类算法中,SVM的正确分类准确率最高为88.87%,相比于NB分类准确率提高了13.68%,相比于ME提高了将近25个百分点。因此,SVM在文本情感分类中,具有良好的分类性能。
实验2:特征权重实验
该实验分别采用二值法、词频法、IDF法和TF-IDF法对文档的特征项加权,测试这四种特征加权方法对情感分类的影响,采用SVM判别文本观点。实验结果如表2所示。

表2 不同权重特征Fisher特征选择性能比较
在这四种特征加权方法中,TF-IDF的性能最高,其分类准确率为82.74%,相比于二值法提高了将近20%,相比于词频法提高了8.3%,相比于IDF法提高了2.99%。这主要是由于TF-IDF在特征项加权中综合考虑特征项局部信息和全局信息,而其他三种方法各有偏重,因此分类准确率较低。
实验3: Fisher特征选择分析比较
该实验采用Fisher准则提取低维高判别性TF-IDF特征,标记为tFisher,原始TF-IDF特征标记为tOrginal,进行对比分析,测试Fisher特征选择对文本情感分类的影响。实验结果如表3所示。

表3 Fisher特征选择性能比较
由表3可知:基于Fisher特征选择的TF-IDF权重特征的各项性能指标均高于原始TF-IDF特征,其FP=89.25%,FN=89.00%,且整体分类准确率达到了89.13%,相比于原始TF-IDF特征分类准确率提高了6.39%。在特征空间维数约简方面,原始TF-IDF的维数为9483, Fisher准则将其约简为5216,特征维度约简率为44.7%。因此,Fisher准则可以有效地提取低维的高判别性特征向量,提高SVM的分类性能,是一种有效的特征选择方法。
实验4:Fisher-VSM聚类算法分析
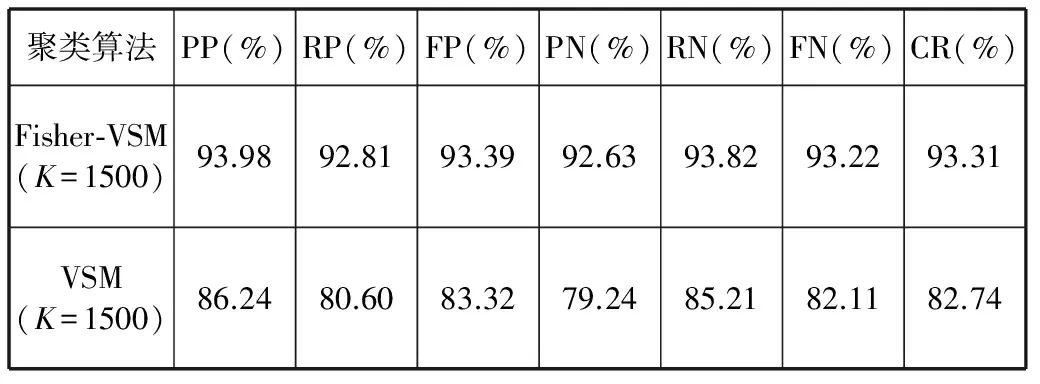
本实验主要测试Fisher-VSM聚类算法的性能。首先测试Fisher-VSM在不同聚类数目K情况下的性能,实验结果如表4和图3所示。紧接着将Fisher-VSM聚类算法与原始TF-IDF特征构成的VSM聚类进行对比分析,实验结果如表5所示。

表4 Fisher-VSM聚类性能分析比较
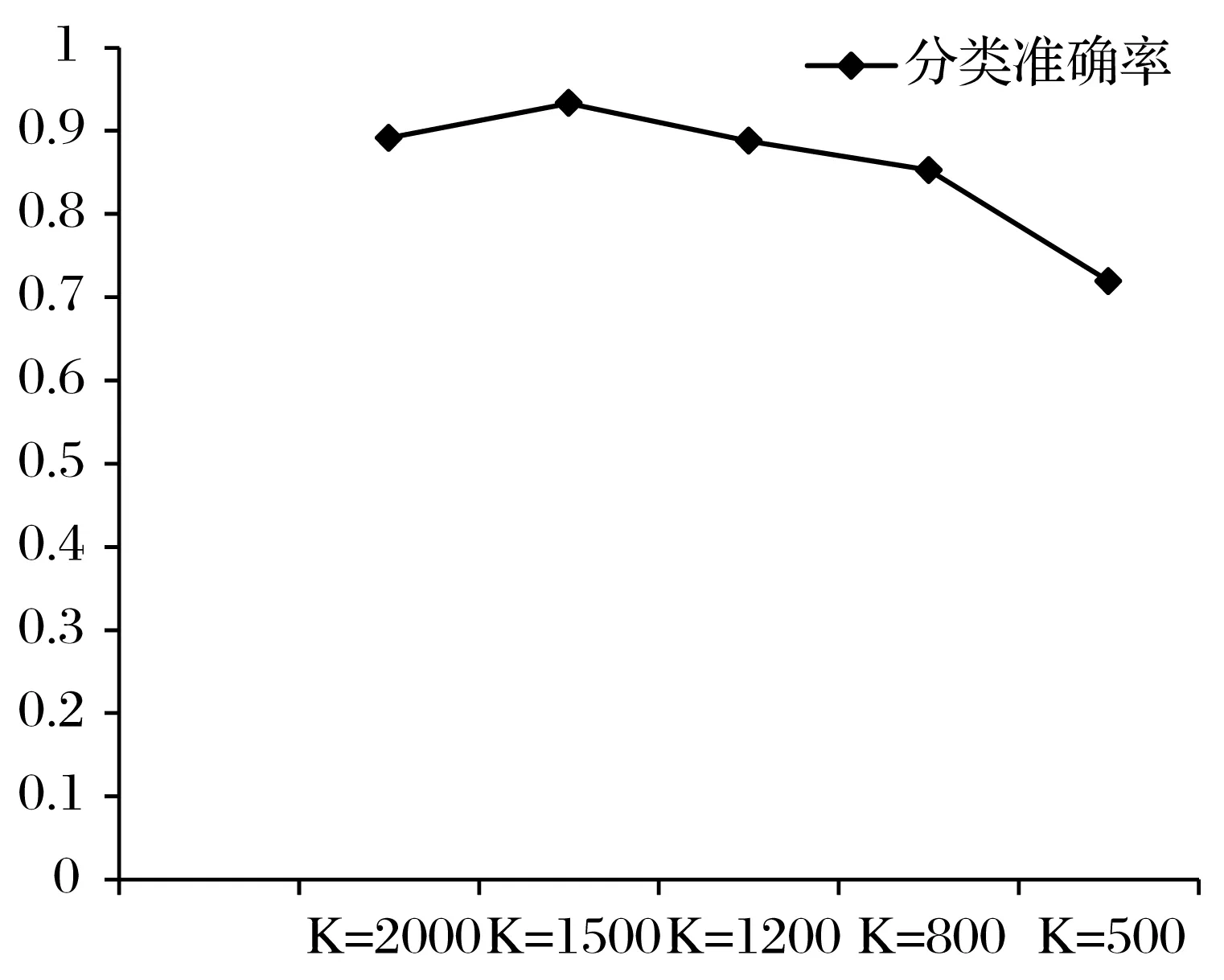
图3 Fisher-VSM聚类性能分析比较
聚类算法PP(%)RP(%)FP(%)PN(%)RN(%)FN(%)CR(%)Fisher⁃VSM(K=1500)93.9892.8193.3992.6393.8293.2293.31VSM(K=1500)86.2480.6083.3279.2485.2182.1182.74
由表4可知,当聚类数目设置为1500时,系统的分类准确率达到最佳,其分类准确率为93.31%。而随着聚类数目的减少,系统的分类性能急剧下降,主要是由于训练样本规模的减少,使得SVM出现训练不足的问题。然而,若K的值较大,虽然解决了训练数据不足的问题,但是大量相似数据的存在,影响了SVM的训练速度及分类准确率。因此,文档聚类数目K=1 500是系统的最佳值。系统的训练文档由2400篇减少到了1 500篇,数目约简率为37.5%,同时系统的分类准确率相比聚类前提高了4.18%。本文提出的Fisher-VSM聚类算法有助于SVM性能的提高,同时可以有效地节约存储空间。
由表5可知,在最优聚类数目K=1500情况下,本文提出的Fisher-VSM聚类算法相比于VSM聚类算法,其分类准确率提高了10.57%。因此,本文提出的聚类算法具有较好的性能。
4 结 语
本文提出一种基于多约简Fisher-VSM和SVM的文本情感分类算法。借助于TF-IDF权重函数兼顾文档特征项局部和全局分布信息的优势,采用Fisher准则选择高判别性的低维的TF-IDF特征,降低文档的维度,建立低维Fisher-VSM。根据Fisher-VSM之间的相似度,对文档模型进行聚类,从而减少文档集的数量。从文档的维数及数量两个方面的约简,提高了SVM的分类性能和训练速度。实验结果表明,本文提出的算法维度约简率为44.7%,文档数目约简率为37.5%,其分类准确率为93.31%,是一种可行的高效的文本情感分类算法。高效准确的文本评论观点的判定,有利于决策支持。本文提出的多约简文本聚类算法,不仅有利于SVM的训练,也适用于其他分类方法,期望对机器学习算法在文本情感分类领域的应用有所借鉴。
[1] 樊小超.基于机器学习的中文文本主题分类及情感分类研究[D].南京理工大学,2014.
[2] Pang B,Lee L,Vaithyanathan S.Thumbs up? Sentiment classification using machine learning techniques[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing,Philadelphia,2002:79-86.
[3] Whitelaw C,Garg N,Argamon S.Using appraisal groups for sentiment analysis[C]//Proceedings of the ACM Conference on Information and Knowledge Management,Bremen(DE),2005:625-631.
[4] 陈培文,傅秀芬.采用SVM方法的文本情感极性分类研究[J].广东工业大学学报,2014,31(3):95-101.
[5] 肖正,刘辉,李兵.一种基于语义距离的Web评论SVM情感分类方法[J].计算机科学,2014,41(9):248-252,284.
[6] 杨经,林世平.基于SVM的文本词句情感分析[J].计算机应用与软件,2011,28(9):225-228.
[7] 周城,葛斌,唐九阳,等.基于相关性和冗余度的联合特征选择方法[J].计算机科学,2012,39(4):181-184.
[8] 朱艳辉,栗春亮,徐叶强,等.一种基于多重词典的中文文本情感特征抽取方法[J].湖南工业大学学报,2011,25(2):42-46.
[9] Wang Suge,Li Deyu,Song Xiaolei,et al.A feature selection method based on improved fisher’s discriminant ratio for text sentiment classification[J].Expert Systems with Applications,2011,38(7):8696-8702.
[10] 孙劲光,马志芳,孟祥福.基于情感词属性和云模型的文本情感分类方法[J].计算机工程,2013,39(12):211-215,222.
[11] 王素格.基于web的评论文本情感分类问题研究[D].上海大学,2008.
[12] 谷文成,柴宝仁,韩俊松.基于支持向量机的垃圾信息过滤方法[J].北京理工大学学报,2013,33(10):1062-1066,1071.
[13] 张璇.基于 Fisher 准则的说话人识别特征参数提取研究[D].湖南大学,2013.
[14] 王飒,郑链.基于Fisher准则和特征聚类的特征选择[J].计算机应用,2007,27(11):2812-2813,2840.
[15] 刘靖明,韩丽川,侯立文.基于粒子群的K均值聚类算法[J].系统工程理论与实践,2005,25(6):54-58.
[16] 谭松波.中文情感挖掘语料-ChnSentiCorp [EB/OL].[2012-08-10].http://www.searchforum.org.cn/tansongbo/corpus-senti.htm.
TEXT SENTIMENT CLASSIFICATION BASED ON MULTI-REDUCED FISHER-VSM AND SVM
Xing YujuanTan PingCao Xiaoli
(School of Digital Media,Lanzhou University of Arts and Science,Lanzhou 730000,Gansu,China)
We propose a novel text sentiment classification algorithm in this paper,it is based on multi-reduced Fisher-VSM and SVM,to improve the accuracy of text sentiment classification.The algorithm first adopts Fisher’s discriminant criterion to extract TF-IDF eigenvector,and then clusters the documents according to the similarity between vector space models of low-dimension documents so as to reduce their numbers.The algorithm makes reduction on vector space model of documents from two aspects of dimensionality and number so as to improve the training speed and classification performance of SVM.Simulation experimental results demonstrate that the proposed algorithm has good recall ratio and classification accuracy.
Text sentiment classificationFisher discriminant ratioVector space model (VSM)Support vector machine (SVM)
2015-04-27。邢玉娟,副教授,主研领域:文本情感分类。谭萍,副教授。曹晓丽,讲师。
TP181
A
10.3969/j.issn.1000-386x.2016.09.070
