基于深度自编码器网络的人脸特征点定位方法
2016-11-09梁洋洋
梁洋洋 陈 宇 杨 健
(南京理工大学计算机科学与工程学院 江苏 南京 210094)
基于深度自编码器网络的人脸特征点定位方法
梁洋洋陈宇杨健
(南京理工大学计算机科学与工程学院江苏 南京 210094)
使用深度学习网络技术的人脸特征点定位方法已经取得了比较突出的效果。然而,人脸图像由于姿态、表情、光照、遮挡等变化而具有复杂多样性,因此数目较多的人脸特征点(超过50个特征点)定位依然有很大的挑战性。设计了三层级联的自编码器网络,并通过由粗到精的方法对多数目的人脸特征点进行定位。第一层网络以整张人脸图像为输入,直接估计人脸轮廓和部件位置,从而将特征点分成三部分(眼眉鼻,嘴巴和人脸轮廓)进行下一步定位;之后的两层网络分别对各部件特征点进行估计求精。在LFPW、HELEN数据库上的实验表明,该方法能够提高人脸特征点定位的准确性和鲁棒性。
人脸特征点定位深度学习自编码器网络逐步求精
0 引 言
人脸特征点定位在人脸识别、姿态估计、人脸跟踪、人脸表情分析等大部分人脸感知任务中扮演着重要的角色。文献[1] 中指出,错误的特征点定位会导致提取的人脸描述特征的严重变形,即使不精确的对齐也会带来识别性能的快速下降。文献[2]表明如果能够获得准确的人脸特征点位置,那么在人脸识别上简单的特征就能到达领先的性能水平。由此可见,准确的定位是非常重要的前期准备步骤。人脸特征点定位的研究因此也得到了越来越多的关注和发展,然而,由于姿态、表情、光照、部分遮挡等因素导致人脸图像的复杂多样性,也给准确的定位带来了巨大的挑战。
在早期的一些方法中,主动形状模型ASM(Active Shape Model)[3],主动表现模型AAM(Active Appearance Model)[4]在实验室中建立的数据库上具有了可靠的性能,在此基础上,许多学者也提出了改进的方法[5-9]。然而,在真实环境应用中,在人脸外观上的呈现出复杂多样性时,这些方法通常会失效,主要原因为一个单一的线性模型很难刻画人脸形状所有非线性的变化。近年来,在自然环境下建立起来的数据库变得非常流行,从而对人脸特征点定位方法提出了更多的挑战。一些新的定位方法已在这些数据库上取得了较好的成果。Piotr Dollar等人[10]提出级联姿态回归CPR(Cascaded Pose Regression)方法对初始形状估计进行逐步的求精,每一个求精过程都由一个不同的回归器实现,每个回归器处理与前一个回归器输出相关的图像度量,整个系统从训练样本中自动的学习。在此基础上,Xavier P. B.等人[11]提出鲁棒级联姿态回归RCPR(Robust Cascaded Regression),通过显式表达是否存在遮挡,利用鲁棒的形状索引特征进行在遮挡环境下的人脸特征点定位。Cao等人[12]提出了一种高效准确的显式形状回归模型。该方法设计了两层增强回归,利用形状索引特征,使用基于相关的特征选择方法直接学习出一个向量回归函数来估计整个人脸形状,并在训练集中显式地最小化定位误差。Xiong等人[13]提出一种有监督的梯度下降方法SDM(Supervised Descent Method)解决复杂最小二乘问题,即从训练数据中学习梯度下降的方向并建立相应的回归模型,然后利用得到的模型来进行梯度方向估计,并应用于人脸对齐,取得了较好的效果。最近,深度自编码器DAEs(Deep Auto-Encoders)、卷积神经网络CNNs(Convolution Neural Networks)、受限波尔兹曼机RBMs(Restricted Boltzmann Machines)等深度网络模型被广泛应用于计算机视觉的各个领域[14],在特征点定位中也取得了突出效果。这主要得益于它强大的非线性拟合能力,能够更好地学习到从人脸图像到人脸形状(特征点)的非线性映射关系。Wu等人[15]使用深度置信网络DBNs(Deep Belief Networks)从人脸表情中捕获人脸形状变化特征,同时使用三元受限波尔兹曼机处理姿态变化。Luo等人[16]使用深度置信网络进行人脸部件检测,之后利用深度自动编码器对每个部件进行训练预测。Sun等人[17]使用三层深度卷积网络DCNN(Deep Convolution Neural Networks)进行人脸特征点检测,在第一阶段,首先估计出所有特征点(5个)作为初始形状,在之后的两个阶段中,对初始形状的每一个特征点分别训练深度网络进行逐步求精。然而,该方法对初始形状比较敏感,对每个特征点分别训练深度网络又不易扩展到特征点较多的情况。Zhang等人[18]提出由粗到精的自动编码网络CFAN(Coarse-to-Fine Auto-Encoder Networks)进行人脸特征点定位,在估计初始形状之后,将所有特征点一起逐步求精。在以上深度模型基础上,本文设计了三层级联的自编码器网络,通过由粗到精的方法对数目较多的人脸特征点(超过50个)进行定位。第一层网络以整张人脸图像为输入,并非直接估计所有特征点作为初始形状,而是先估计出人脸轮廓和部件位置,从而将所有特征点划分到若干部件;第二层针对不同部件分别训练网络对各个部件内特征点进行估计;第三层为每个部件训练相应网络并以部件为单位对其内所有特征点进行求精。实验结果表明,这种方法能够在定位多数目特征点的任务中提高估计的准确性和鲁棒性。
1 基于深度自编码器网络的定位方法
在数目较多的人脸特征点定位任务中,如果使用一个单一的深度学习网络对所有特征点进行估计,将导致网络结构复杂和训练过程困难,同时由于姿态、表情、光照等因素使得精确的定位更加困难。针对这一情况,本文设计了一个基于深度自编码器网络的人脸特征点定位方法,这一部分首先对设计的方法进行概述,然后分析自编码器网络的设计细节,最后给出实验中的网络设置参数。
1.1方法概述
本文设计了三层级联的自编码器网络,并通过粗到精的方法对多数目的人脸特征点进行定位。如图1所示,根据面部结构特征,我们将眉毛、眼睛和鼻子整体作为一个部件(包含31个特征点),嘴巴单独作为一个部件(包含20个特征点),人脸轮廓作为一个部件(包含17个特征点),从而将所有特征点分成三部分。第一层深度网络以整个人脸图像作为输入,训练网络直接估计出三个部件的边框位置(边框左上角和右下角点的坐标)作为输出。通过边框位置信息对人脸图像进行剪裁,分别得到三个部件的图像,作为第二层网络的输入,针对三种不同部件分别训练第二层深度网络对相应部件中的特征点做出初始的估计,得益于深度网络对从图像到特征点之间复杂的非线性映射关系的优良拟合能力,同时每个网络仅对数目不多的特征点进行预测,使得第二层深度网络的初始预测已经比较接近实地真值。鉴于人脸图像在表情、姿态、光照等方面的较大变化,设计第三层深度网络来刻画描述这些变化,在当前特征点周围提取的局部索引特征用于特征点定位是经常使用并且有效的方法[10-12],该层网络也以各个部件局部索引特征作为输入,分别预测当前特征点估计值与实地真值的偏差,以对特征点进一步求精,得到更加准确和鲁棒的特征点坐标。整个方法公式表示如下:
S=S0+ΔS
(1)
其中,S表示最终人脸特征点(人脸形状)估计值,S0表示第二层网络对特征点的初始估计值,ΔS表示第三层网络对上一层网络特征点估计值与真实值的偏差估计值。
第一层估计各部件位置,将得到各个部件边框左上角和右下角坐标,为便于显示,图中各部件位置用不同粗细的矩形框框出来,之后将各部件剪裁出来分别进行估计和求精,最后将所有部件特征点合并得到一个完整的人脸形状。

图1 方法概述
1.2深度自编码器网络
我们使用深度自编码器网络作为设计的三层级联网络的基本构件。给定一个由d维人脸(或人脸部件)图像x∈Rd,Tg(x)∈Rp表示p维的目标输出变量,各层的网络学习出一个从图像到目标值的映射函数F,如下所示:
F:x→T
(2)
一般来说,映射F是一个复杂的非线性函数,为了实现这一目标,k个单一的隐藏层自动编码器被堆叠起来作为一个深度神经网络来拟合这个映射函数。具体而言,各层网络的任务可以看作最小化以下目标函数:

(3)
ai=fi(ai-1)=σ(Wiai-1+bi),i=1,2,…,k-1
(4)
fk(ak-1)=Wkak-1+bk
(5)
其中,F={f1,f2,…,fk},fi是深度网络中第i层的映射函数,σ是sigmoid函数,ai是第i层的特征表示。自编码器网络中前k-1层神经元节点激活函数使用sigmoid函数来刻画图像特征与目标变量之间的非线性,然而,由于sigmoid函数的输出范围是[01],与目标变量范围不一致,因此在网络最后一层fk中神经元节点激活函数使用线性函数以得到目标输出估计值。
(6)

自编码器网络在通过式(7)进行初始化后,网络所有层参数按照式(6)进行微调,如此,自编码器网络的前几层用来捕获低层特征,如图像中的纹理模式;较后面的几层来刻画包含纹理模式上下文信息的较高层的特征。网络以图像原始像素为输入变量,以期望的回归目标值作为输出进行训练,测试时,网络的输出值即为相应的预测值。
1.3实现细节
数据扩增:为了通过训练得到一个鲁棒的深度网络,对每一个训练样本(按照数据集提供的人脸边框提取的人脸图像)进行随机缩放和平移操作扩充样本容量,这样可以有效地防止深度网络模型训练过拟合,增强对自然环境下各种变化的鲁棒性。
参数设置:实现中使用由三个非线性隐藏层和一个线性输出层构成的深度自编码器网络模型来拟合非线性映射函数。调整输入网络的人脸(或人脸部件)图像到固定大小(50×50像素),隐藏层神经元节点个数分别为取1600、900、300,在提取局部形状索引特征时,我们在每个特征点周围提取9×9的小块,式(6)中的权重衰减项参数α用来控制样本集均方差项和权重衰减项的相对重要性,实验中取值为0.001。
2 实 验
为了评估所文中设计方法的性能,我们在常用人脸特征点定位数据库上进行了多次实验。这一部分首先介绍所使用的数据库,之后给出实验结果与分析。
2.1数据库介绍
我们在LFPW[19]和HELEN[20]两个数据库上进行了多次实验,这两个数据库中的图片在姿态、光照、表情方面变化较大,并且存在一些遮挡,是近几年提出的在自然环境条件下的人脸对齐数据库,具有一定的挑战性,广泛应用于理论研究。LFPW数据库中包含1132张训练集图片和300张测试图片,由于该数据库只提供了图片链接并且有些链接已经失效,我们使用IBUG[21]提供的数据库图片,包含811张训练集图片和224张测试集图片。HELEN数据库为高分辨率图片库,由2000张训练集图片和330张测试集图片构成。两个数据库中的人脸图片均标注由300-W提供的68个人脸特征点。
2.2实验结果与分析
实验结果采用平均估计误差和失效率两个指标来度量所设计方法的性能,这两个指标显示了一个特征点定位算法的准确度和可靠性。估计误差公式如下:
(8)
其中,(x,y)和(x′,y′)分别表示特征点真值坐标和估计坐标,d表示估计误差标准化因子。如果估计误差超过10%,则认为估计失效。两眼中心距离常用来作为估计误差标准化因子,然而,与正脸相比,侧脸两眼中心的距离较短,使用两眼中心距离作为估计误差标准化因子在人脸姿态变化较大时显然是不合适的,这一点在文献[22]中也被提出。因此,实验中我们使用人脸边框的水平方向上像素个数(边框宽度)作为估计误差标准化因子进行性能度量。
我们将文中设计的方法和主动表现模型(AAM)方法[4]和有监督梯度下降方法(SDM)[13]进行比较。AAM方法主要通过网络资源提供的API实现[23],SDM方法发布的代码只估计了49个特征点,为了统一比较,借鉴源代码重新实现了估计68个特征点的版本。
表1和表2分别给出了在LFPW和HELEN数据库上的平均估计误差和失效率。与AAM和SDM方法相比,文中设计的方法在两个数据库上平均估计误差最小,失效率最低(表中用粗体呈现),表明文中设计的方法在特征点定位的准确度和可靠性(鲁棒性)上有相应提高。图2给出了在LFPW(左三列)和HELEN(右三列)数据库上结果对比。从上到下依次为:实地真值、AAM方法、SDM方法和本文设计的方法。从图中可以看出,当人脸姿态或表情有较大变化时,鼻子和嘴巴处的特征点准确定位比较困难,然而,文中设计的方法在应对这种姿态或表情变化有一定的鲁棒性。图3和图4分别给出了文中设计方法在LFPW和HELEN数据库上的一些特征点定位结果,这些人脸图片在姿态、表情、年龄、肤色都有变化,有的还存在一些遮挡,尽管如此,我们设计的方法依然能够比较准确地定位。
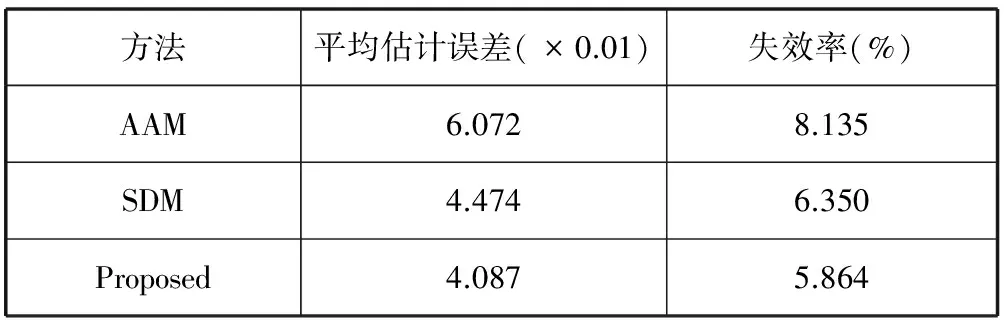
表1 LFPW数据库上不同方法比较结果
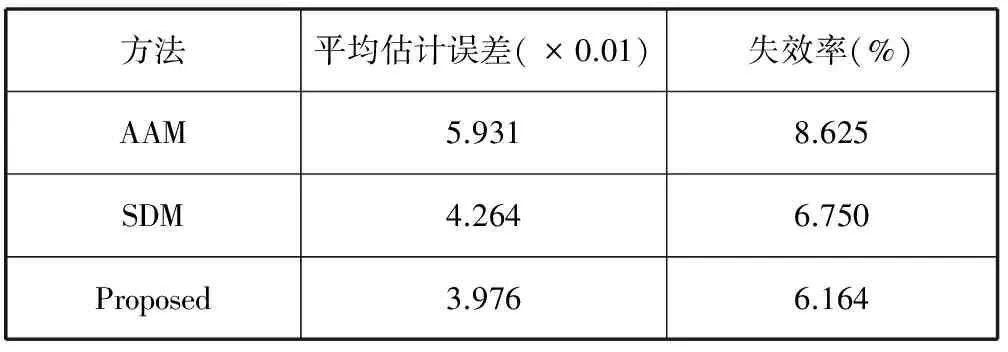
表2 HELEN数据库上不同方法比较结果

图2 不同数据库和不同方法同方法的对比结果

图3 LFPW数据库上一些样本的结果

图4 HELEN数据库上一些样本的结果
3 结 语
本文在深度学习网络基础上,针对在数目较多的人脸特征点定位任务中,使用单一的网络导致结构复杂、学习困难、定位不够准确的情况,设计了一个三层级联自编码器深度学习网络。将整个人脸特征点划分在若干部件范围内,从而对每个部件内特征点进行估计并求精,最后合并所有部件得到整个人脸图像上的全部特征点位置。实验表明该方法在自然环境下采集的人脸图像数据库LFPW和HELEN上取得比较准确的定位效果。
[1] Shan S G, Chang Y Z, Gao W. Curse of mis-alignment in face recognition: problem and a novel mis-alignment learning solution[C]//6th IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, South Korea, 2004. Washington, DC: IEEE Computer Society, 2004:314-320.
[2] Chen D, Cao X D, Wen F, et al. Blessing of dimensionality: high-dimensional feature and its efficient compression for face verification[C]//26th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, 2013. Washington, DC: IEEE Computer Society, 2013:3025-3032.
[3] Cootes T F, Taylor C J, Cooper D H, et al. Active shape models-their training and application [J]. Computer Vision and Image Understanding, 1995,61(1):38-59.
[4] Cootes T F, Edwards C J, Taylor C J, et al. Active appearance models[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence. Mach,2011,23(6):681-685.
[5] Matthews I, Baker S. Active appearance models revisited [J]. International Journal of Computer Vision, 2004,60(2):135-164.
[6] Milborrow S, Nicolls F. Locating facial features with an extended active shape model [C]//10th European Conference on Computer Vision (ECCV), Marseille, France, 2008. Berlin Heidelberg: Springer, 2008:504-513.
[7] Sauer P, Cootes T, Taylor C. Accurate regression procedures for active appearance models [C]//22nd British Machine Vision Conference (BMVC), University of Dundee, 2011. Norwich, UK: BMVA Press, 2011:1-11.
[8] Cootes T F, Ionita M C, Lindner C, et al. Robust and accurate shape model fitting using random forest regression voting [C]//12nd European Conference on Computer Vision (ECCV), Florence, Italy, 2012. Berlin Heidelberg: Springer, 2012:278-291.
[9] Zhao X, Shan S, Chai X, et al. Locality-constrained active appearance model[C]//Asian Conference on Computer Vision (ACCV), Daejeon, Korea, 2012. Berlin Heidelberg: Springer, 2013:636-647.
[10] Dollar P, Welinder P, Perona P. Cascaded Pose Regression[C]//23rd IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, 2010. Washington, DC: IEEE Computer Society, 2010:1078-1085.
[11] Burgos-Artizzu X P, Perona P, Dollar P. Robust face landmark estimation under occlusion[C]//IEEE International Conference on Computer Vision (ICCV), Sydney, 2013. Washington, DC: IEEE Computer Society, 2013:1513-1520.
[12] Cao X D, Wei Y C, Wen F, et al. Face alignment by explicit shape regression[J]. International Journal of Computer Vison. 2014,107(2):177-190.
[13] Xiong X H, De la Torre F.Supervised descent method and its application to face alignment[C]//26th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR,2013. Washington, DC: IEEE Computer Society, 2013:532-539.
[14] Bengio Y. Learning deep architecture for AI[J].Foundations and Trends in Machine Learning,2009,2(1):1-127.
[15] Wu Y, Wang Z, Ji Q. Facial feature tracking under varying facial expressions and face poses based on restricted boltzmann machines [C]//26th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, 2013. Washington, DC: IEEE Computer Society, 2013:3452-3459.
[16] Luo P,Wang X, Tang X. Hierarchical face parsing via deep learning [C]// IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, Rhode Island, 2012. Washington, DC: IEEE Computer Society, 2012,157(10):2480-2487.
[17] Sun Y, Wang X G, Tang X O. Deep convolutional network cascade for facial point detection[C]//26th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, 2013. Washington, DC: IEEE Computer Society, 2013:3476-3483.
[18] Zhang J, Shan S G, Kan M N, et al. Coarse-to-fine auto-encoder networks (CFAN) for real-time face alignment[C]//13rd European Conference on Computer Vision (ECCV), Zurich, Switzerland, 2014. Switzerland: Springer, 2014:1-16.
[19] Belhumeur P N, Jacobs D W, Kriegman D, et al. Localizing parts of faces using a consensus of examples[J].IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2013, 35(12):2930-2940.
[20] Le V, Brandt J, Lin Z, et al. Interactive facial feature localization[C]//12nd European Conference on Computer Vision (ECCV), Florence, Italy, 2012. Berlin Heidelberg: Springer, 2012:679-692.
[21] Christos S, Georgios T, Stefanos Z, et al. 300 faces in-the-wild challenge: the first facial landmark localization challenge[C]//IEEE International Conference in Computer Vision Workshops (ICCVW), Sydney, 2013. Washington, DC: IEEE Computer Society, 2013:397-403.
[22] Zhu X, Ramanan D. Face detection, pose estimation, and landmark localization in the wild[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 2012. Washington, DC: IEEE Computer Society, 2012:2879-2886.
[23] Mikkel B Stegmann. http://www.imm.dtu.dk/~aam/.
FACIAL LANDMARK LOCALISATION APPROACH BASED ON DEEP AUTOENCODER NETWORKS
Liang YangyangChen YuYang Jian
(School of Computer Science and Engineering, Nanjing University of Science and Technology, Nanjing 210094, Jiangsu, China)
Facial landmarks localisation methods using deep learning network technology have achieved prominent effect. However, the localisation of larger number of facial landmarks (more than 50 points) still have lots of challenges due to the complex diversities in face images caused by pose, expression, illumination and occlusion, etc. This paper designs a three-level cascaded autoencoder network, which are employed to locate a large number of facial landmarks in a coarse-to-fine manner. The first level of the network estimates facial contour and component positions directly by tacking the whole face image as input, which divides landmarks into three parts (eyes and nose, mouth, and facial contour) for the next localisation steps; the following two level of the network estimate and refine the landmarks of each part respectively. Experiments conducted on LFPW, HELEN databases show that the approach can improve the accuracy and robustness of facial landmark localisation.
Facial landmark localisationDeep learningAutoencoder networksCoarse-to-fine
2015-06-25。国家自然科学基金面上项目(61472187)。梁洋洋,硕士生,主研领域:人脸识别。陈宇,博士生。杨健,教授。
TP3
A
10.3969/j.issn.1000-386x.2016.09.033
