数据断层分析在广播电台数据处理中的应用
2016-11-09夏骄雄周时强
徐 俊 夏骄雄 周时强
1(上海广播电视台技术运营中心 上海 200051)2(上海大学计算机工程与科学学院 上海 200444)3(上海市教育委员会信息中心 上海 200003)
数据断层分析在广播电台数据处理中的应用
徐俊1,2夏骄雄2,3周时强2
1(上海广播电视台技术运营中心上海 200051)2(上海大学计算机工程与科学学院上海 200444)3(上海市教育委员会信息中心上海 200003)
随着大数据技术的不断升温,数据断层现象的分析与处理已经成为数据挖掘领域重要的方式与手段。数据断层理论作为描述数据对象之间发生局部位移趋势的分析理论,对于数据预处理过程具有十分重要的指导性意义。在初步描述数据断层理论基本概念的基础上,以上海“动感101”音乐电台的移动客户端应用日志数据为例,构建数据断层理论分析系统来处理电台数据中所存在的数据断层现象,提高了数据对象预处理的质量,得到了有效的电台决策辅助信息,从而充分说明了数据断层理论的科学性和有效性,为进一步研究奠定了坚实基础。
数据断层数据挖掘数据预处理日志数据分析移动客户端应用
0 引 言
在大数据时代,众多信息的迅速传播正由平面媒体转向以互联网为代表的先进移动终端媒体[1]。通过把握这一契机,在手机、平板电脑等移动设备平台上开发一系列应用程序,并通过网络载体主动地推送到用户面前,将极大提高人们获取有用信息的效率。用户访问应用时,服务器将产生大量的日志文件,包括用户的IP地址、访问时间、终端类型号等。对于这些日志文件进行数据挖掘,可以得到日志数据的总体特征,及时掌握与日志文件产生有关的应用程序使用情况,并可以进一步预测该应用程序未来的发展趋势,从而为决策支持提供支撑[2,3]。
与应用程序配套的日志文件信息是按照一定格式存储的,属于半结构化的数据,其中包含着一些不完整的、冗余的、错误的数据。同时,根据不同用户的需求,也有可能存在大量的不相关数据。这些数据造成了数据断层现象,对数据挖掘的准确性有着一定的负面影响[4]。因此,对这类数据断层进行分析和处理,是更好获取应用程序使用情况的有效途径。
1 数据断层
文献[5]结合大数据环境,借鉴地质学的理论,首次在数据挖掘领域提出数据断层的理论体系。通过数据断层剖面的分析,系统阐述了数据预处理过程中的数据断层现象,并给出数据断层在显隐断层、内间断层之间相互转化的规则和算法。初步说明了数据断层理论体系的基础。
定义1数据断层大数据环境中,各个数据对象之间的性质随着各种主题、结构、时效属性等维度变化而变化所产生相关性描述的具体表象,称为数据断层。
按照不同的分类原则,数据断层有不同的分类。根据数据断层的表现形式,可以将其划分为数据显断层和数据隐断层。
定义2数据显断层相对于大数据环境,常存在于数据库与数据库之间,受到主题、结构、时效等因素影响而发生变化的数据断层称为数据显断层。
定义3数据隐断层相对于大数据环境,常存在于数据库内部,受到结构、成分、数据关系等因素影响而发生变化的数据断层称为数据隐断层。
本文引入数据库中的孔隙定义,用于描述造成显断层的问题数据对象。
定义4孔隙数据库中存在的各种无关用户主题的异常数据对象,包括噪声数据对象、空白数据对象、重复数据对象等,统称为孔隙。
定义5孔隙度某一特定主题的数据资源中,存在的孔隙数量与数据对象总数量之间的比值,称为孔隙度。
孔隙度反映数据资源中数据对象关于特定主题的紧密程度。显然,孔隙度越小,数据质量越高。事实上,实际应用中的数据库所包含的孔隙往往不能完全被消除,在数据对象不断更新的情况下,对孔隙的处理只能以尽可能地减少孔隙为目标,从而减小孔隙对数据对象分析的影响。为了进行正常的数据分析和处理工作,必须对数据库进行孔隙检测,剔除尽可能多的孔隙。
定义6数据压实了减小孔隙对数据分析结果的影响而对数据对象进行各种处理操作的过程,包括处理空白数据对象、转换格式不一致的数据对象、删除重复数据对象等,称为数据压实。
同样,对于隐断层数据对象,可以将其提取出来进行分析;若是无用数据对象,则需要使用数据压溶技术对数据对象进行处理。
定义7数据压溶对与用户需求不相关的数据进行处理得到有用信息的过程称为数据压溶。
2 应用背景
广播电台是公共媒介的一种重要表现形式。通常情况下,人们收听电台广播都是通过传统方式(即利用无线电波向一定区域的听众传送声音节目信号方式),利用收音机等设备接收信号[6]。20世纪90年末期,通过互联网收听广播电台节目的方式应运而生[7]。只要在能够访问互联网的地方,用户就能够在计算机或者各种先进移动终端上收听到全世界范围内的广播电台节目。
本文以“全亚洲顶尖华语音乐电台”——上海“动感101”移动客户端为例,研究用户访问的日志数据,构建数据断层理论分析系统来分析并处理日志中存在的数据断层,获取有关决策支持信息。
“动感101”自1992年以来,一直是上海市收听率第一的电台。进入移动互联网时代,“动感101”也于2011年9月与时俱进地推出了移动客户终端应用程序(如图1所示)。移动终端用户可以通过Android或IOS系统的移动设备访问该应用程序,不仅可以随时随地地收听广播节目,更融合了录音、歌曲查询、一键互动、在线评论等一系列实用功能。

图1 “动感101”应用程序界面
数据断层理论分析系统的数据来源于“动感101”电台移动客户端的日志访问记录,分别从IP为222.XXX.YYY.167、222.XXX.YYY.207、222.XXX.YYY.208三台服务器下载用户访问的日志信息。选取从2012年5月28日0时到2012年6月3日24时的日志数据用于分析,日志文件大小为3.63 GB。日志文件中每条记录分别为一个切片,每个切片代表用户访问了十秒钟的时长。
日志文件分析主要是通过分析日志数据,获得用户的行为模式和各种数据资源之间的关联关系,以便了解用户对哪些数据资源比较感兴趣。然后根据数据挖掘的结果来预测未来发展趋势及行为,做出前瞻性决策,改善服务器的性能,提高服务质量[8]。
通过数据断层理论分析系统对电台日志文件进行分析,不仅可以掌握用户收听“动感101”的情况,而且可以针对现有情况做出调整,从而提高电台客户端的实用价值和广播节目的收听率。分析日志数据必然涉及统计数据环节,本文案例中需要统计的信息主要有三个方面:一周内每天收听节目的总时长和听众人数;一周内每天收听观众的地区分布情况;一周内每个时段的收听总时长和听众人数。
3 数据断层理论分析系统构建
针对“动感101”电台日志文件数据的特点和用户的实际需求,数据断层理论分析系统设计了如图2所示的总体结构图。主要分为四个模块,即日志集中模块、日志存储模块、日志处理模块和日志分析模块。系统主要在日志处理模块和日志分析模块中对显断层和隐断层的数据进行重点分析。
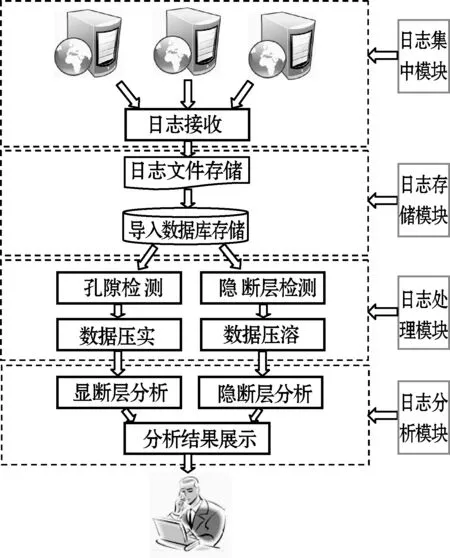
图2 数据断层理论分析系统的具体架构
在日志集中模块、日志存储模块和日志处理模块主要使用C#和SQL Server数据库方式实现数据存储、处理算法和数据统计等功能。在日志分析模块结合Excel、Matlab等工具进行分析。通过使用多种工具,较好地完成了利用移动客户端收听“动感101”电台节目日志文件数据对象的数据断层分析和处理工作。
用户利用移动客户端收听“动感101”电台节目时,用户的移动设备会自动连接到一个虚拟的IP地址。虚拟IP地址接受到用户的请求后,根据各服务器的负载量,“动感101”电台负载均衡LVS(Linux Virtual Server)选择调度算法,将用户的请求路由连接到最适合的服务器上。
移动客户端收听“动感101”电台节目的原始日志数据数量巨大,涉及十个以上的数据属性,但是并不是所有的数据属性都属于日志数据分析的范畴。为了减小存储空间,在日志数据文件导入SQL Server数据库的过程中,数据断层理论分析系统只选择了部分数据属性(如表1所示选择了五个数据属性),按照固定格式制作规范化文档。然后在导入程序中引用格式文档,导入后的数据状态可以由半结构化状态转化为结构化状态,实现了数据属性的约简。这样不仅有利于对日志数据的管理,而且为后续的数据处理和分析提供了极大的便利条件。
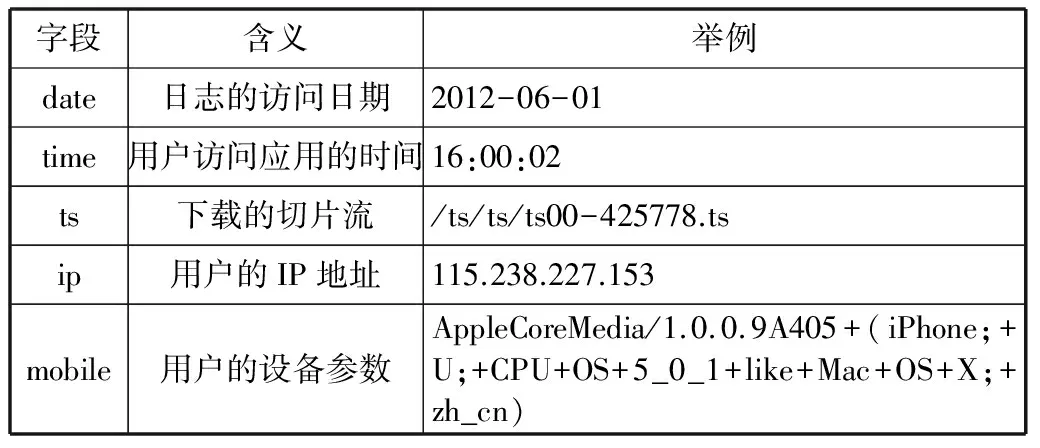
表1 SQL Server数据库中数据属性所表示的含义
数据断层理论分析系统的SQL Server数据库中,按照服务器的不同可以分为三个数据对象集合。三台服务器的数据对象按照格式化文档导入,有相同的格式,所以三个数据对象集合在属性上是相同的,且都属于同一主题的数据库,消除了宏观数据断层中结构不一致的问题。但在数据数量和数据内容上仍然存在差异,属于微观数据断层范畴。
4 数据显断层的分析与处理
日志处理模块主要采用数据断层理论的四种处理方法,即孔隙检测、数据压实、隐断层检测和数据压溶。对显断层数据和隐断层数据的检测和处理并无严格意义上的先后顺序,但是为了保证显断层数据的处理不会影响隐断层数据分析结果的准确性。因此,数据断层理论分析系统采用“先处理显断层数据,后分析隐断层数据”的模式。
显断层数据分析分为孔隙检测和数据压实两个步骤。
4.1孔隙检测的处理与分析
数据断层理论分析系统按照以下步骤对孔隙进行检测。
1) 以其中一台服务器的数据对象集合为样本例,按照日期将整个数据对象集合分为7个分区,分别命名为{p1,p2,…,p7},其中p1代表2012年5月28日的日志数据,依次类推。
2) 对分区内的所有数据对象进行层次聚类。
(1) 将分区内的每个数据对象看作一个类,若两个数据对象的值相等,则直接归并为一类,否则计算各类之间的相关能。由于数据对象属于非数值型数据,所以按照文本的长度作为计算能量的标准。
(2) 将相关能最大且满足阈值条件的两类归并为一类,不满足阈值条件的归为另一类。
(3) 重新计算新类和其他类之间的相关能。
(4) 重复执行步骤(2)和步骤(3),直到分区内所有数据对象都经过阈值条件验证为止。
3) 若经过步骤2)的层次聚类后的分区只有一个类,则该分区不包含异常数据,将该分区剪除。
4) 在剩余的分区内重复步骤2)和步骤3),直到7个分区都被检测,保留存在异常数据的分区作进一步分析和处理。
一般情况下,若分区越多,则执行这样步骤的孔隙检测方法的效率将越高。数据断层理论分析系统对移动客户端收听“动感101”电台节目的原始日志数据按日期分区,每天的数据数量巨大,且每个分区都存在孔隙,所以没有剪除分区操作。
通过孔隙检测,数据断层理论分析系统实验数据的孔隙主要有三种。
一是缺失数据。在数据属性ts中,存在部分记录显示为空,此类记录为访问内部IP地址222.XXX.YYY.168,并没有下载或上传任何信息。
二是噪声数据。在数据属性mobile中,存在部分记录显示为LiveRadioEncoder,该记录为内部编码器向服务器发送音频切片文件的访问记录;另外还有部分记录显示为ChinaCache,这些记录对数据对象集合而言是一种噪声数据。
三是重复数据。数据库中每个数据属性都相同的记录属于重复数据,多见于访问页面的记录,而下载ts流量的重复数据相对较少。
由以上分析可知,影响数据质量的访问记录大多数产生于内部IP地址对应用程序的访问,所以在数据统计和分析之前需要对这些孔隙进行相应的处理。
存储的日志数据属于结构化数据,相对于半结构化或非结构化数据而言,存在的显断层数据比较少。在数据断层理论分析系统中,通过孔隙检测检测出来的孔隙,三台服务器一周的总孔隙数量达到1 902 949条记录,相对于总切片数量20 867 199条记录来说,孔隙度大约在9%左右。
通过统计每一天的孔隙度,可以在一定程度上了解电台日志数据的访问情况。在数据断层理论分析系统中,工作日(2012年5月28日至2012年6月1日)的日志数据孔隙度结果如图3所示,维持在比较稳定的水平,在8%~10%之间波动,而周末两天(2012年6月2日至2012年6月3日)的孔隙度明显提高。这说明在内部系统对应用程序访问量不变的情况下,用户对应用程序的访问量减少,从而导致孔隙度增加。针对以上各种孔隙类型,结合数据断层理论分析系统的实验需求,需要对孔隙进行数据压实操作。

图3 电台数据的孔隙度
4.2数据压实的处理与分析
缺失数据和噪声数据主要是由应用程序内部访问服务器所产生的。不同IP地址代表不同的用户,但相同IP地址未必是同一用户,所以重复数据可能是因为多个设备收听节目时使用的是同一个公网IP地址,基于端口转换的NAT、代理、防火墙等都有可能导致多个用户使用同一个公网IP地址进行访问。根据以上分析,数据断层理论分析系统的数据压实步骤中主要采用删除的方法,便可以较好地处理数据显断层。
数据断层理论分析系统中显断层分析系统界面如图4所示,选择需要处理的时间段和服务器,然后按照孔隙检测方法执行检测,最后对孔隙进行数据压实操作。

图4 显断层分析界面
5 数据隐断层的分析与处理
完成显断层数据的处理,日志处理模块将对隐断层数据进行分析和处理。隐断层数据分析分为隐断层检测和数据压溶两个步骤。
5.1隐断层检测的处理与分析
数据对象集合中存在的隐断层数据随着用户需求的不同而会有不同的结果。根据“动感101”电台的需求,数据断层理论分析系统中需要检测的隐断层类型主要有四种:
第一种为确定用户收听情况时,不是从服务器下载ts流量的记录不属于分析范围;
第二种为北京时间2:00-6:00属于“动感101”电台停播时间段,此段时间数据记录属于隐断层数据;
第三种为检测服务器发生故障、主持人变更等突发状况发生时产生的隐断层数据;
第四种为检测用户的地区分布差异引起的隐断层数据。
针对以上四种隐断层类型检测内容,需要制定不同的检测方法。简单的隐断层数据不需要算法便可以检测出来;有的隐断层数据则需要通过计算其信息熵,再与用户阈值条件进行比较才能确定隐断层的实际状态。例如:通过观察法可知,第一种隐断层数据还包括网页访问和图片下载的记录;第二种隐断层数据就是停播时间段内的数据;第三种和第四种隐断层数据的发现相对复杂,需要一系列步骤进行检测。
1) 用户地区分布差异的获取
数据断层理论分析系统以第四种隐断层数据为例,设计移动客户端收听“动感101”电台节目地区分析系统,展示隐断层数据检测的方法。将一周内访问“动感101”电台应用程序的IP地址做无重复的数据统计,可以获得一周的用户人数,将这些数据对象看作一个数据空间,对数据空间里的所有数据对象通过统计、计算信息熵和断层概率的方法进行隐断层检测。
由于“动感101”在不同地区的知名度并不一样,所以用户的地区分布必然存在着差异性。地域相差较远的不同省市之间存在数据断层是一种客观现象,而数据断层理论分析系统通过处理方法检测数据断层是针对同一区域内的。所以需要先对数据对象进行分区,然后逐步细化分析,最后确定隐断层数据产生的原因。
(1) 汇总需要检测的数据对象
本文实验以中国地区的数据对象为主要研究对象,所以需要对国外访问的数据对象进行溶蚀操作,即提取每天不重复的IP地址,查询其归属地区,然后将国外的访问记录分离出去。
(2) 统计IP地址数量
图5是数据断层理论分析系统实验数据所在的一周内每天访问服务器的IP地址数量。在这一周内数据波动并不显著,初步可以看出前四天的IP地址数量比较平衡地微微增加,周四达到最高值,而周末两天访问IP地址的数量明显下降。这种变化与人们的生活作息习惯、周末电台节目的变化等多种因素密切相关。

图5 一周内每天访问IP数量图
由于中国地区数量较多,每个地区依次分析需要投入较大的工作量。因此数据断层理论分析系统根据“数据空间进行初步分区”的思想,采取先对IP地址按地区分为多个集合,然后进行统计和分析。由于“动感101”是属于上海的电台,其在传统收听模式下的知名度和支持度就较高,上海的用户众多是必然的。另外,江苏和浙江与上海毗邻,“动感101”节目在江苏和浙江的用户数也不在少数。所以东部沿海地区的用户数量远远高于其他地区也属正常情况,并进而导致东部沿海地区与其他地区之间在用户数量上产生了明显的断层。
2) 用户地区断层分布的获取
尽管通过分析可以判断出东部沿海地区数据存在着断层,但并不是所有的案例都有如此明显的数据特征。所以必须通过科学方法来计算与验证,增强说服力,进一步反映数据断层的状态。数据断层理论分析系统采取的方法是:先根据定义计算各个地区集合的信息熵,找出断层最为显著的地区;然后计算该地区内各个数据对象的断层概率,确定数据断层数据所对应的省份;最后分析该省存在数据断层的原因。
(1) 计算各地区集合的信息熵


图6 地区分析程序界面
(2) 计算集合对象的断层概率
通过计算各地区集合的信息熵从而确定了数据断层存在的区域之后,需要进一步追踪该区域的重点数据对象,获得相应的断层概率分布。在确定东部沿海地区是存在数据断层的地区之后,追踪东部沿海地区所包含的城市,查看IP地址数量,获得各个省市的断层概率。例如:上海市的用户人数为24 895人,断层概率为0.5302;浙江省的用户人数为1286人,断层概率为0.2887;江苏省的用户人数为2648人,断层概率为0.2415等。
5.2数据压溶的处理与分析
根据实际情况,不同的隐断层有着不同的处理方式。有的隐断层正好是被分析的数据对象,有的隐断层则需要进行数据压溶处理。对于以用户分布情况为例的隐断层检测结果,由于电台方面的需求只为了解分布情况和哪些地区存在断层情况,所以并不需要进行数据压溶。
通常情况下,围绕系统用户的需求,类似案例中可能需要进行数据压溶的处理内容主要有三方面。
一是那些不是ts流的数据对象。因为围绕统计用户收听时间的需求,访问页面的aspx相关内容并不在分析范围之内,只需要统计用户从服务器下载的ts流数据即可。
二是处理那些收听不超过10秒的切片。因为若某条记录在连续时间里只出现一次,访问应用的时间不超过10秒,很可能是用户操作失误或无意访问应用造成的。这些数据信息会对统计结果产生一定的误差,不利于有用信息的获取。
三是处理那些每天停播时间段的数据对象。因为北京时间凌晨两点到六点是没有节目的,而这段时间内若存在大量数据对象,则需要将这些数据对象单独提取出来进行分析。
6 统计数据结果的断层分析与处理
经过断层处理的数据对象相比原始数据对象而言,其数量将明显减少,而且会更加符合用户需求,对这些数据对象进行分析得出的结果将有助于得到更加准确的信息。对于不同的需求,有着不同的统计结果数据断层分析思路。针对数据断层理论分析系统而言,断层分析的主要需求包括三个方面。
6.1每天的ts切片数量和IP数量
通过数据断层理论分析系统统计每天的ts切片数量和IP数量,可以计算出收听的总时长和平均收听时长。
为了对比断层处理后的数据对象与原始数据对象之间的差别,通过统计原始数据对象和断层处理后数据对象的相关内容,得到的结果如表2和表3所示。
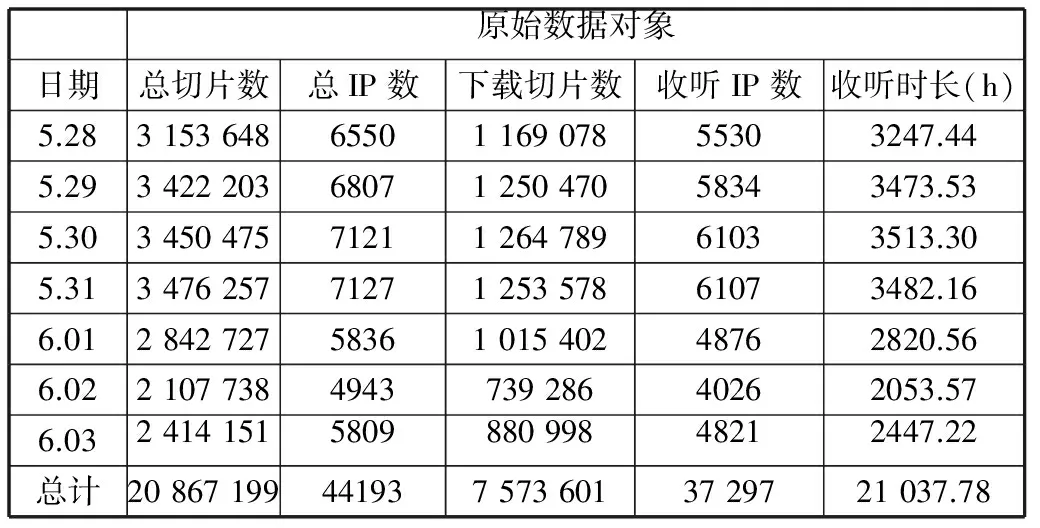
表2 原始数据对象的统计表

表3 断层处理后数据对象的统计表
其中,总切片数是指导入的所有记录数量,包括ts切片、aspx切片以及其他记录数据;总IP数是指对所有访问的IP地址进行的数量统计;下载(ts)切片数是指只有下载ts流的记录数量统计;收听IP数是指下载ts切片的IP地址数量统计;收听时长是指ts切片数的10倍除以3600得到的小时数。通过分析表2和表3,断层处理后压实了孔隙,有助于清楚地了解实际收听情况。
6.2每小时的切片数和收听时间
若需要了解每档节目的收听情况,就不可避免地需要统计每小时的数据对象。通过对这些数据对象一周内的波动情况,了解某个节目的收听趋势,从而做出相应地调整。
通过数据断层理论分析系统,可以得到所选的服务器在00:00-24:00之间每个小时的统计数据。一周内不同时间段的数据是三台服务器统计数据的总和。因此,分别统计三台服务器的数据,然后进行汇总,得到如表4所示的统计结果。
表4中,北京时间22:00-24:00时间段的平均收听时长占比较低,而在该时间段内的收听时长和用户(听众)数量却处于较高水平。这说明总时长增长的比率远远赶不上用户(听众)增长的比率,较多的用户(听众)在该时间段内通过移动设备收听节目,但收听时间较短。平均收听时长占比最高的19:00-20:00区间上,收听时长不高,但是用户(听众)人数明显下降,所以收听时长占比反而提高。
综合分析表4,在北京时间15:00和23:00左右,用户通过移动客户端收听电台的收听时长和用户(听众)数量达到较高峰。这两个时间点分别对应于接近下班的时间和临睡觉的时间,人们通过手机等智能移动客户端设备收听电台,也符合当前人们的生活作息时间。尽管北京时间2:00-6:00是节目停播时间,但是仍然存在有用户收听的情况,原因在于用户在移动设备上没有关闭动感101的客户端。即便此时没有节目信息,应用程序仍然在后台运行,从服务器下载的切片处于忙碌状态。

表4 一周不同时间段的统计表

续表4
6.3其他情况
除了以上情况之外,还存在着其他各种数据断层的情况,例如三台服务器出现故障的情况,可能的原因是编码器到流媒体服务器的网络中断或者流媒体服务器服务中断。具体在日志文件中会有所体现,即一段时间内没有新的ts流文件被下载。但是服务器出现故障的情况一年不会超过5次,属于特殊情况,本论文不作详细分析。
7 结 语
本文以上海“动感101”电台移动客户端的日志访问记录数据为分析对象,构建了数据断层理论分析系统。分四个模块对数据对象进行处理和分析,检测数据对象中存在的显、隐断层。然后进行数据压实和数据压溶操作,得到高质量的数据对象。最后针对不同的需求,对数据对象进行分析得到有用的决策辅助信息。
数据断层理论分析系统的具体实践表明,在广播电台数据这样实时性较强的数据处理应用中,数据断层理论具有较好的科学性和有效性。
[1] Yi Sun,Yang Guo,Xiaobing Zhang,et al.The Case for P2P Mobile Video System over Wireless Networks:A Practical Study of Challenges for A Mobile Video Provider[J].IEEE Network,2013,27(2):22-27.
[2] Francesco Bonchi,Fosca Giannotti,Cristian Gozzi,et al.Web Log Data Warehousing and Mining for Intelligent Web Caching[J].Data and Knowledge Engineering,2001,39(2):165-189.

[4] 夏骄雄.数据资源的聚类预处理[M].上海:上海科学普及出版社,2011.
[5] 夏骄雄,汪晶玲,严琛琼,等.数据断层现象的研究[J].计算机应用与软件,2013,30(8):9-13,77.
[6] Philippe Perebinossoff,Brian Gross,Lynne Schafer Gross.Programming for TV,Radio,and the Internet:Strategy,development,and evaluation[M].Burlington,MA:Focal Press,2005.
[7] Gene Youngblood.Secession from the Broadcast:The Internet and the Crisis of Social Control[J].Millennium Film Journal,2013(58):174-189.
[8] Naga Lakshmi,Raja Sekhara Rao,Sai Satyanarayana Reddy.An Overview of Preprocessing on Web Log Data for Web Usage Analysis[J].International Journal of Innovative Technology and Exploring Engineering,2013,2(4):274-279.
APPLICATION OF DATA FAULTAGE ANALYSIS IN RADIO DATA PROCESSING
Xu Jun1,2Xia Jiaoxiong2,3Zhou Shiqiang2
1(Technical Center,Radio and Television Shanghai,Shanghai 200051,China)2(SchoolofComputerEngineeringandScience,ShanghaiUniversity,Shanghai200444,China)3(InformationCentre,ShanghaiMunicipalEducationCommission,Shanghai200003,China)
With the increasing heating up of big data,analysis and process on data faultage phenomena has become the important ways and means in data mining field.Data faultage theory,as the analysis theory describing the tendency of partial displacement between data objects,has the extremely instructive significance on data preprocessing.Based on the preliminary description on the rationale of data faultage theory,we took the log data of mobile client application on “Shanghai Music Radio FM 101.7” as an example and built an analysis system of data faultage theory to deal with the data faultage phenomena in radio log data so as to improve the quality of data objects preprocessing,and gained the effective auxiliary information of radio decision-making.Therefore,the scientific property and effectiveness of data faultage theory are fully explained,this lays the sound foundation for further studies.
Data faultageData miningData preprocessingLog data analysisMobile client application
2015-04-06。国家自然科学基金项目(40976108,61303097);上海市重点学科建设项目(J50103);上海大学研究生创新基金项目(SHUCX070037,SHUCX120105)。徐俊,工程师,主研领域:数据挖掘,智能决策支持系统。夏骄雄,研究员。周时强,助理工程师。
TP311.131G202
A
10.3969/j.issn.1000-386x.2016.09.009
