改进的回归测试中测试用例优先级排序技术
2016-11-04张侹,吴强,王华
张 侹,吴 强,王 华
1.西安测绘研究所,陕西 西安,710054;2.地理信息工程国家重点实验室,陕西 西安,710054
改进的回归测试中测试用例优先级排序技术
张侹1,2,吴强1,2,王华1,2
1.西安测绘研究所,陕西 西安,710054;2.地理信息工程国家重点实验室,陕西 西安,710054
测试用例优先级排序技术是回归测试中提高测试效率的一种有效手段。针对回归测试中测试用例的选择和执行问题,改进了原有方法中仅从软件需求角度出发的测试用例排序技术,提出了一种基于软件质量信息的测试用例优先级排序技术,将上一轮测试结果中与软件质量信息相关的故障密度、问题密度、非法用例问题密度等方面的内容应用于测试用例的优先级排序中。实验结果表明,改进后的测试用例排序技术能够更快地提高软件缺陷检测率,降低测试成本。
测试用例; 回归测试; 优先级排序; 质量信息
1 引 言
回归测试是软件演化过程中一项频繁进行且开销巨大的任务,有研究表明,回归测试阶段的耗费甚至会占到软件维护总费用的三分之一以上[1]。随着软件规模的不断增大,回归测试的工作量也在不断增加,其测试周期和成本也在不断加大。目前,常见的回归测试类型包括全部回归、改错型回归等。其中,全部回归是重新测试以前所设计的全部测试用例,这种回归类型能够有效覆盖修改后的被测软件,对于系统规模较小的被测软件较为适用,但是对于测试数据较大、改动较小的被测软件而言,这一回归策略会造成大量的时间和人力资源浪费;改错型回归是针对软件测试过程中发现的错误进行的回归测试,该方法能够有效解决全部回归中资源浪费的问题,但却难以保证在被测软件修改后,软件中未修改的部分不会受到影响而产生新的问题。综上所述,由于工程实践中的回归测试行为与被测软件规模息息相关,且常受到时间和人员等资源的限制,因此,为了提高回归测试的效率,缩短测试周期,提升测试的有效性和准确性,就必须在回归测试中对测试用例的选择采用一定的策略,提高测试的执行效率。
目前,科研人员针对回归测试中测试用例的选择和使用问题展开了大量的研究工作,如:测试用例的选择、测试用例集约简以及测试用例优先级排序等。测试用例优先级排序技术作为提高回归测试效率的一种重要手段,是根据不同条件充分考虑测试用例的重要程度,赋予每个测试用例一个优先级,使测试人员可以依据优先级由高到低依次选择执行测试用例,从而能够在有限的资源下运行更多有效的测试用例,保证了软件质量。
2 测试用例的优先级排序
测试用例优先级排序问题是一种着重研究回归测试中测试用例使用策略的问题。测试用例优先级排序技术认为,不同测试用例对于发现软件缺陷和测试目标的完成有着不同的贡献程度,为了能够更快地达成测试目标,有必要将不同的测试用例进行比较和排序,然后优先执行相对重要的测试用例[2,3]。
文献[2]将测试用例优先级形式化的描述为:T是给定的测试用例集,PT是T上的全排列,f是PT到实数集的一个映射,测试用例优先级技术的研究目标就是找到一个排列T′,T′∈PT都有(∀T″)(T″∈PT∧T″≠T′)→[f(T″)≤f(T′)]。通常情况下,f是对排序目标的定量描述,用以度量排序的有效性,且f的值越大越好。
3 改进的回归测试用例优先级排序
目前,围绕回归测试用例优先级排序问题主要在寻找影响测试用例优先级的因素等方面展开[3]。其中,文献[4]、[5]从软件需求的角度将与软件需求相关的影响因素应用于测试用例的优先级排序;文献[6]从软件测试发现问题级别和类型等角度将与软件错误相关的因素应用于测试用例优先级排序。尽管这些方法在提高测试效率方面都取得了一定的成果,但是,上述这些排序方法仅从单方面研究了测试用例的优先级排序问题,忽略了软件本身的质量因素,没有充分考虑需求与已经执行用例结果之间的关系。
本文从软件需求、软件规模、测试用例数量类型以及所发现问题的角度出发,充分利用上一轮软件测试的结果,引入与软件需求中功能点成熟性、健壮性等质量信息相关的一种影响因素和两个影响因子,具体为:影响因素故障密度和影响因子问题密度及非法用例问题密度。
3.1故障密度
故障密度是反映软件成熟性的一个重要度量,是计算每一千行代码所产生的故障个数。故障密度值越大,说明该功能模块在上一轮测试中发现的问题越多,软件质量越低,因此,与该功能模块相关的软件测试用例执行的优先级也就越高。通过公式(1)可以量化得到第n个测试用例的故障密度FI,其取值范围为正数。
(1)
FIn计算了第n个测试用例所测试的软件需求中功能点在上一轮测试中每千行代码所发生的错误率,其中,FNn表示第n个测试用例在上一轮测试中其所在功能点所发现的问题总数,RTLn为实现对应功能点的代码行数。
3.2问题密度
作为反映软件成熟性的另一个重要指标,问题密度是检测的软件失效个数和执行测试用例个数的一个比例。与故障密度的概念不同,问题密度中所涉及的软件测试问题是由软件通过执行测试用例后所体现出一种动态行为;而故障密度中所涉及的软件故障则是软件本身所客观存在的缺陷,是一个静态概念。
问题密度越大,说明上一轮测试中针对该功能模块设计测试用例所发现的问题也越多,这一组测试用例执行效率越高。通过公式(2)可以量化得到问题密度的影响因子ΦFI,其取值范围为[0,1]。
(2)
ΦFI计算了第n个测试用例所在软件需求中功能点在上一轮测试中的问题密度,其中,ENn表示第n个测试用例在上一轮测试中其所在功能点所发现的问题总数,TNn为针对该功能点所设计的测试用例的总数。
3.3非法用例问题密度
非法用例问题密度是反映软件健壮性的一个重要度量,使软件对未能避免故障模式的个数(即:未能通过的非法测试用例个数)进行计数,并与考虑到的故障模式的个数(即:设计的非法测试用例的个数)相比较。非法用例的问题密度越大,说明软件对非法输入的容错能力越差,软件的健壮性越低。通过公式(3)可以量化得到非法用例问题密度的影响因子ΦITEI,其取值范围为[0,1]。
(3)
ΦITEI计算了第n个测试用例所在软件需求中功能点在上一轮测试中的非法用例问题密度,其中,ITENn表示第n个测试用例在上一轮测试中其所在功能点所发现的非法测试用例对应的问题总数,ITNn为针对该功能点所设计的非法测试用例的总数。
3.4 测试用例排序算法
文献[5]从软件需求的角度给出了回归测试第n个测试用例的优先级取值RPn的计算公式,通过引入与软件质量信息相关的影响因子,将基于软件质量信息的优先级取值IRPn进行定义。
由于故障密度反映的是软件本身的质量特性,故将其作为优先级取值中的影响因素;而问题密度与非法用例问题密度反映了针对需求所设计测试用例的相关信息,故将其以影响因子的形式作为相关需求的系数引入计算公式中。具体计算方法如公式(4)所示:
IRPn=RDn+ΦFI*RIn+ΦITEI*RCn+RSn+FIn
(4)
回归测试前,根据测试用例优先级影响因素和相关影响因子,依据公式计算单个测试用例的优先级,并依据基于软件质量信息的回归测试用例排序算法进行计算。具体算法描述如下:
算法:基于软件质量信息的测试用例排序算法。
输入:程序P的测试用例集T;各功能模块的软件规模集L(即代码行数)、测试用例总数集TC、非法用例总数集ITC、问题总数集E。
输出:排序后的测试用例集T′。
Begin
T' = φ;
for(n = 1; n < |T|; t++)
{IRPn= RDn+φEI*RIn+φITEI* RCn+ RSn+ FIn}
Sort(IRPn);
T' = IRPn
Output(T');
End
4 度量标准及实验分析
4.1度量标准
为了对不同优先级排序方法所得到的测试用例集的测试效率进行评估,就需要通过采用缺陷检测加权平均百分比APFD(average of the percentage of faults detected)作为度量标准进行比较分析[2]。在通过APFD所绘制的测试用例执行情况图中,横坐标代表测试用例的执行情况,纵坐标代表测试用例执行后所发现的缺陷监测情况,通常情况下,APFD的值越大,说明对应的测试用例排序检测到缺陷的速度越快。
Elbaum等给出了APFD的计算方法[7],如公式(5)所示。
(5)
其中,n表示测试用例集T中所包含的测试用例总数,m表示缺陷集合F中所包含的缺陷数,TFi表示顺序集T′中第一个检测出错误i的测试用例的序号。通过公式(5)就可以计算出顺序集T′的APFD值,其取值范围是[0,1]。不同测试用例顺序集中,APFD的值越高表示对应测试用例顺序集检测错误的效率相对越高。
4.2实验分析
为了对改进后的回归测试用例排序技术的有效性进行分析,论文选取了某软件P进行测试与分析。根据软件需求,共设计测试用例164个,回归测试重复执行三次,分别是未排序的测试用例执行情况、采用文献[5]排序后的测试用例执行情况、改进方法排序后的测试用例执行情况。软件P三次回归测试用例集得APFD值分别为0.62,0.75和0.79,三次执行的缺陷发现情况如图1所示。
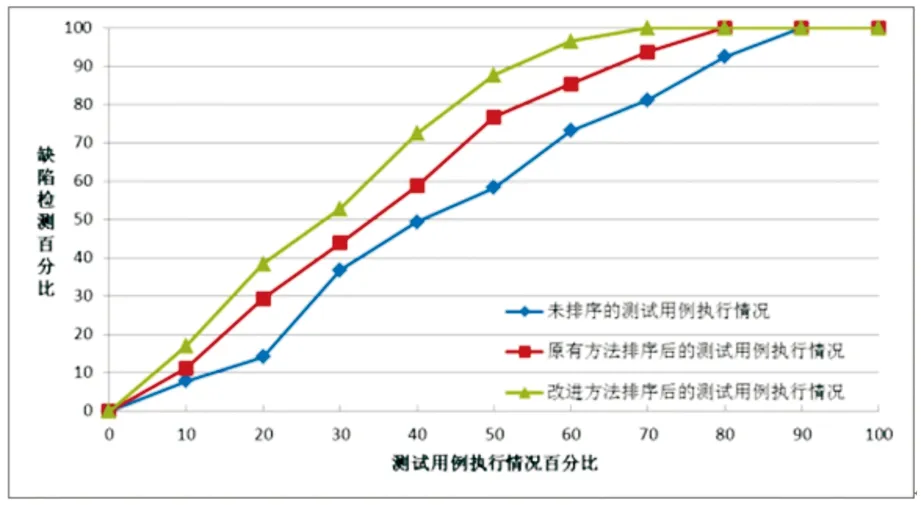
图1 软件P三次执行的缺陷检测情况图
通过实验发现:
(1)对于被测程序P而言,与不进行排序的测试情况相比,采用文献[5]和本文所提出的任意一种回归测试用例优先级排序策略后,测试用例集的执行效率都得到了明显的改善,能够提高缺陷的检测效率。
(2)在基于需求的回归测试用例排序技术中通过引入前一轮次的测试结果,即软件成熟性和健壮性的质量信息,基于软件质量信息的优先级排序算法比原有基于需求的优先级排序算法发现缺陷的效率有所改进。
5 结束语
改进后的回归测试用例优先级排序技术,从上一轮软件测试所获取软件质量信息的角度出发,通过在基于需求的优先级排序算法中分别引入影响因素和影响因子,对回归测试用例集中无序混乱的测试用例进行优先级排序,得到测试用例的优先级执行取值,再通过执行排序后的测试用例,可以有效提升测试效率,改善测试效果。在后续的工作中,可以在测试执行时动态调整优先级算法等相关领域进行研究。
[1]Rothermel G, Harrold M J. Analyzing Regression Test Selection Techniques [J]. IEEE Transactions on Software Engineering, 1996, 22(8): 529-551.
[2]Rothermel G, Untch R H, Chu C Y, et al. Prioritizing Test Cases for Regression Testing [J]. IEEE Transactions on Software Engineering, 2001, 27(10): 929-948.
[3]屈波, 聂长海, 徐宝文. 回归测试中测试用例优先级技术研究综述[J]. 计算机科学与探索, 2009, 3(3): 225-233.
[4]杨广华,包阳,李东红等. 基于需求的测试用例优先级排序[J]. 计算机工程与设计, 2011, 32(8): 2724-2728.
[5]李华莹, 柴丽雅. 由需求得到回归测试用例排序技术[J]. 计算机技术与发展, 2013, 23(11): 70-73.
[6]李华莹, 胡兢玉. 回归测试用例优先级排序技术研究[J]. 计算机仿真, 2013, 30(10): 298-301.
[7]Elbaum S, Rothermel G, Kanduri S, et al. Selecting a Cost-effective Test Case Prioritization Technique [J]. Software Quality Journal, 2004, 12(3): 185-210.
Improved Technique of Test Case Prioritization in Regression Testing
Zhang Ting1, 2, Wu Qiang1, 2, Wang Hua1, 2
1. Xi’an Research Institute of Surveying and Mapping, Xi’an 710054, China 2. State Key Laboratory of Geo-information Engineering, Xi’an 710054, China
Test case prioritization technique is an effective way to improve the efficiency of regression testing. To solve the problem of test case selection and execution in regression testing, the old prioritization technique based on software requirements is improved, and a new technique based on software quality information is put forward. With the new method, the densities of faults, errors and illegal test cases connected with the software quality information of last round of test results are taken into account in the test case prioritization. The experiment result shows that the improved technique can increase the efficiency of error detection and reduce the testing cost.
test case; regression testing; prioritization; quality information
2015-09-11。
张侹(1984—),男,工程师,主要从事软件测评研究。
TP751.1
A
