基于JNDD边界划分的立体视频深度编码
2016-11-03天津大学电子信息工程学院天津300072
(天津大学电子信息工程学院,天津300072)
基于JNDD边界划分的立体视频深度编码
(天津大学电子信息工程学院,天津300072)
针对编码后的深度图中边界区域失真导致的虚拟视图质量下降的问题,利用基于恰可察觉深度差异(JNDD)的边界提取方法,将深度图划分为尖锐的边界区域和平滑的非边界区域,并对划分后的区域分配不同的量化参数值进行深度编码.实验结果表明:本文提出的方法能够很好地保留深度图的边缘信息,有效地减轻虚拟视图绘制的失真;同时,绘制的虚拟视图能够保持较高的峰值信噪比(PSNR)和结构相似性测量参数(SSIM)值.
虚拟视点合成图;深度失真;立体视频编码
随着平面信息技术的日臻成熟,3D信息的完美再现必将成为新一代信息技术的发展方向和趋势.为了实现多视点自由立体显示[1-2],需要多个摄像机从多个视点拍摄场景,从而加大了对存储空间和传输带宽的要求.因此,必须要对视频数据进行高效的压缩.多视点视频+深度(multi-view video plus depth,MVD)[3]由彩色视频和相应的深度视频组成.MVD视频可以利用基于深度的视点绘制(depth imagebased rendering,DIBR)技术[4-6]在自由立体视频系统的终端生成虚拟视点视频,大大节省了存储空间和传输带宽,具有广阔的应用前景[7-8].
深度图中各像素点的值表示这点与摄像机之间的距离[9].DIBR技术利用深度图及相机参数来绘制虚拟视点图像,因此深度图的质量直接影响了绘制的虚拟视图的质量[10].
深度编码是多视点加深度视频编码的重要组成部分[11-12].在深度编码过程中,由于量化的原因,经过编码后深度图中像素点的值会发生改变,从而产生深度失真.这种失真在深度变化较大的边缘区域尤为明显.由于深度图的边缘对于区分场景中不同的物体、前景与背景以及虚拟视点绘制都有着重要的作用.因此,在深度编码过程中,保持深度图中的边缘信息具有重要的意义.
恰可察觉深度差异(just noticeable depth difference,JNDD)是指人眼能够感知到的深度差异的最小变化.本文以宏块为单位,提出了一种基于JNDD的边界提取方法.并且,通过对深度变化引起的虚拟视图失真以及深度编码造成的深度失真分析,提出了一种合理分配边界区域与非边界区域的量化参数QP值[13]的深度编码方法.通过比较本文方法获得的虚拟视图质量和HEVC方法获得的虚拟视图质量,可以发现,本文方法可以有效地保持深度的边界信息,同时降低了虚拟视点绘制的失真.
1 视图合成失真及深度编码失真
在DIBR中,错误的深度值会使得参考图像中的像素点映射到虚拟视点中错误的位置,从而使得绘制的虚拟视图产生几何失真.深度失真造成的虚拟视图的几何失真[8]

式中:Δx和Δy分别表示在水平方向和垂直方向的位置失真;d为深度图中的深度值;Δd为深度值的改变量;K′、R′、t′分别表示虚拟相机的内参矩阵、旋转矩阵和平移矩阵;t为参考相机的平移矩阵.
深度编码过程中由于量化引起的编码失真使得重构后的深度图像产生失真.为了比较明确地显示深度图编码之后容易产生失真的区域,在本文中对每个序列预先设定了一个可容忍的深度失真范围[14],当深度差异在此范围外时标记为255,反之则标记为0.
2 基于JNDD边界划分的深度编码
2.1基于JNDD的深度边界提取
深度图中每个物体区域的深度值都相对比较平滑,像素间的差异通常不会超过恰可察觉深度差异(just noticeable depth difference,JNDD)值,而物体间的边界区域通常为深度变化明显的区域,其像素间的差异远远超过了JNDD值.文献[11]给出了JNDD与深度之间的关系,为了降低复杂度,本文将JNDD值DJND取为18.
将深度图划分为大小为16× 16的宏块,并计算当前宏块MBij中的最小深度值mij.

将当前宏块中与mij的差值大于DJND的位置标记为1,并统计标记矩阵a(s, k)中1的个数,即为当前宏块中深度值与mij的差值大于DJND的个数N.a(s, k)和N的表达式为

若N≥162/2,则判定该宏块为边界宏块,否则为非边界宏块.利用本文提出的方法获得边界宏块如图1所示.

图1 本文算法提取的边界宏块Fig.1Boundary macro block extracted by the proposed method
2.2基于边界划分的比特分配
从图1中可以看出,在深度编码的过程中深度变化较大的边界区域更容易产生失真.图2分别为Lovebirds1和Kendo序列编码后边界区域和非边界区域与对应的原始视频帧之间的均方误差MSE随量化参数QP变化的曲线,其中均方误差MSE越大则表明失真越严重.

图2 MSE随QP值变化曲线Fig.2MSE curve varying with QP
从图2可以看出来,随着QP值的增大,边界区域的均方误差曲线的斜率一直在增大,而非边界区域的均方误差曲线却比较平滑.因此,在深度编码时,可以给边界区域分配更多的比特来减轻深度边界的失真,对于平滑的非边界区域分配更少的比特来提高深度编码的压缩效率.
3 实验结果及分析
本文以编码参考软件HEVC和虚拟视点合成软件VSRS3.0为实验平台,利用日本Tanimoto实验室提供的Balloons和Kendo以及德国HHI研究所提供的Lovebird1和Book-arrival 4组测试序列进行实验验证.本文对易失真的边界区域分配较小的QP值,对平滑的非边界区域分配较大的QP值.为降低算法的复杂度,本文设提取的边界区域的QP值为22,而非边界区域的QP值为47.表1给出了QP=37时的HEVC深度编码的比特率及本文方法的编码比特率.根据先验知识可得编码比特率越高表示编码性能越优越.图3、图4和图5给出了利用未压缩、本文方法及QP=37的HEVC方法获得的深度图合成的虚拟视图的对比结果.

表1 设定的编码比特率Tab.1Encoding bit rate assigned
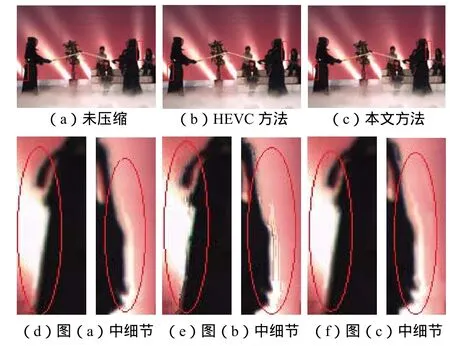
图3 Kendo序列虚拟视图比较Fig.3Comparisons of virtual views for Kendo sequence

图4 Book-arrival序列虚拟视图比较Fig.4Comparisons of virtual views for Book-arrival sequence
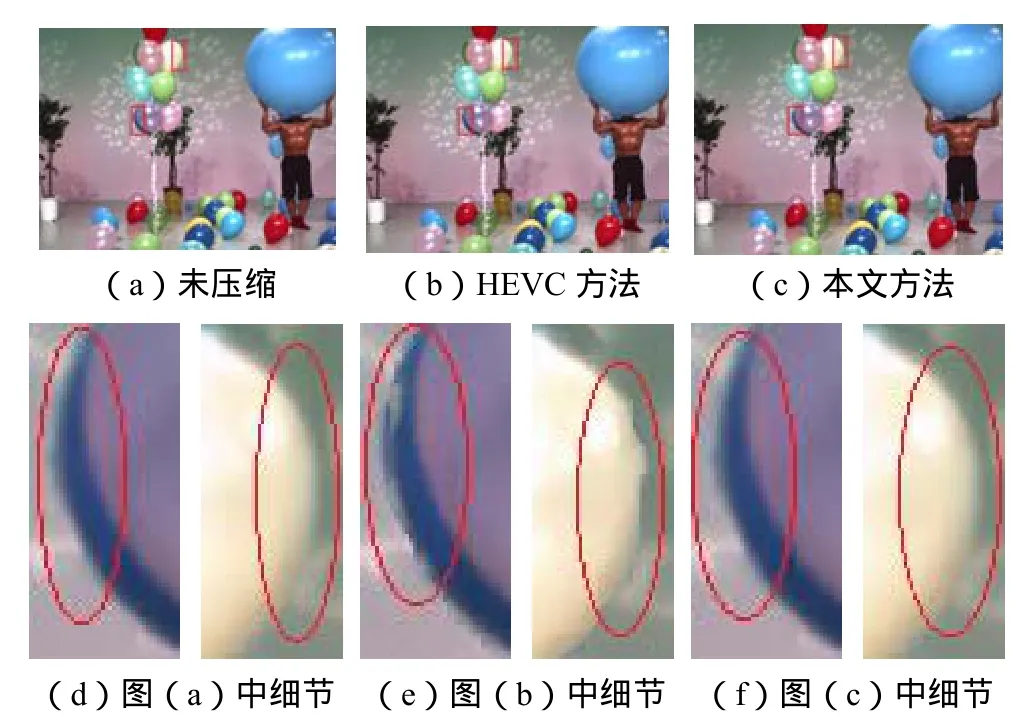
图5 Balloons序列虚拟视图比较Fig.5Comparisons of virtual views for Balloons sequence
从图3、图4和图5中的放大部分可以看出,采用全局QP=37的HEVC方法进行编码后得到的虚拟视图,在边界处明显存在伪影、断裂以及拖尾等问题.如图3(e)中击剑者的衣服边界处存在拖尾和锯齿效应,图4(e)中人的鼻子和下巴等面部部分存在明显的削平和缺失现象,图5(e)中气球的边缘存在明显的破裂及不平滑.而利用本文方法压缩后的深度图由于很好地保留了边界信息,避免了绘制视图中上述问题的发生.
为了进一步比较本文方法的性能,本文引入了客观质量评价方法,即峰值信噪比(PSNR)[13]和结构相似性测量参数(SSIM)[15]2种评价方法.图6和图7以虚拟视点位置的标准视图为基准,分别给出了利用未压缩的深度图、本文方法编码后的深度图以及QP=37的HEVC方法编码后的深度图绘制的虚拟视图与基准视图之间的PSNR和SSIM曲线.同时,表2分别列出了采用不同的编码方法绘制的虚拟视图的PSNR和SSIM的均值.

图6 虚拟视图PSNR比较Fig.6Comparisons of PSNR for virtual views

图7 虚拟视图SSIM比较Fig.7Comparisons of SSIM for virtual views

表2 虚拟视图客观质量比较Tab.2Comparison of objective quality of virtual views
从图6和图7所示的PSNR曲线和SSIM曲线可以明显地看出利用本文方案获得的深度图所绘制的虚拟视图更接近在深度图无压缩的情况下所绘制的虚拟视图.同时,结合表1和表2可以得出,在编码比特率相同的情况下利用本文方案所获得虚拟视图的PSNR和SSIM值比在QP=37的HEVC方案情况下要高,因此本文方案能够更好地保证绘制视图的质量.
4 结 语
为减轻深度压缩后深度图的失真对视图合成质量的影响,本文提出了一种基于边界划分的深度编码方法.在该方法中,设计了一种以宏块为单位的基于JNDD的边界提取算法,能够很好地提取出深度编码中容易发生失真的边界区域.同时,在深度编码的过程中对划分的不同区域分配不同的QP值来确保深度编码后深度图的质量.对绘制的虚拟视图进行主观比较以及客观质量评价,结果表明该方法能够很好地保持深度的边界,获得较高质量的虚拟视点图像.
[1]侯春萍,许国,沈丽丽.基于狭缝光栅的自由立体显示器视区模型与计算仿真[J].天津大学学报,2012,45(8):677-681. Hou Chunping,Xu Guo,Shen Lili.Calculation and simulation of viewing zone based on parallax barrier autostereoscopicdisplay[J].JournalofTianjin University,2012,45(8):677-681(in Chinese).
[2]岳斌,侯春萍.立体视差调整的快速估计方法[J].天津大学学报:自然科学与工程技术版,2013,46(7):571-578. Yue Bin,Hou Chunping.A rapid stereo disparity adjustment estimate method[J].Journal of Tianjin University:Science and Technology,2013,46(7):571-578(in Chinese).
[3]Shao Feng,Jiang Gangyi,Yu Mei,et al.View synthesis distortion model optimization for bit allocation in three-dimensional video coding[J].Optical Engineering Letters,2011,50(12):895-900.
[4]Xu X Y,Po L M,Ng K H,et al.Depth map misalignment correction and dilation for DIBR view synthesis[J].Signal Processing Image Communication,2013,28(9):1023-1045.
[5]Fehn C.Depth-image-based rendering(DIBR),compression,and transmission for a new approach on 3DTV[C]//Proceedings of SPIE Conference on Stereoscopic DisplaysandVirtualRealitySystems.Berlin,Germany,2004:93-104.
[6]Battisti F,Bosc E,Carli M,et al.Objective image quality assessment of 3D synthesized views[J].Signal Processing:Image Communication,2015,30(c):78-88.
[7]Daribo I,Saito H.A novel inpainting-based layered depth video for 3DTV[J].IEEE Transactions on Broadcasting,2011,57(2):533-541.
[8]Zhang Qiuwen,Tian Liang,Huang Lixun,et al. Rendering distortion estimation model for 3D high efficiency depth coding[J].Mathematical Problems in Engineering,2014(Suppl):1-7.
[9]侯春萍,李桂苓,雷建军.3D技术知识解读[M].北京:人民邮电出版社,2013. Hou Chunping,Li Guiling,Lei Jianjun.Interpretation of 3D Technical Knowledge[M].Beijing:The People's Posts and Telecommunications Publishing House,2013(in Chinese).
[10]Liu Shujie,Lai Polin,Tian Dong,et al.New depth coding techniques with utilization of corresponding video[J].IEEE Transactions on Broadcasting,2011,57(2):551-561.
[11]Jung S W,Ko S J.Depth sensation enhancement using thejustnoticeabledepthdifference[J].IEEE Transactions on Image Processing,2012,21(8):3624-3637.
[12]冯坤.多视点视频编码码率控制及比特分配研究[D].天津:天津大学电子信息工程学院,2014. Feng Kun.Research on Rate Control and Bit Allocation of Multi-View Video Coding[D].Tianjin:School of Electronic Information Engineering,Tianjin University,2014(in Chinese).
[13]Li Xiangjun,Cai Jianfei.Robust transmission of JPEG2000 encoded images over packet loss channels[C]//2007 IEEE International Conference on Multimedia and EXPO.Beijing,China,2007:947-950.
[14]Zhao Yin,Zhu Ce,Chen Zhenzhong,et al.Depth nosynthesis-error model for view synthesis in 3-D video[J].IEEE Transactions on Image Processing,2011,20(8):2221-2228.
[15]Cadik M,Herzog R,Mantiuk R,et al.New measurementsrevealweaknessesofimagequality metricsinevaluatinggraphicsartifacts[J].ACM Transactions on Graphics,2012,31(6):1-10.
(责任编辑:王晓燕)
Stereoscopic Video Depth Coding Based on JNDD Boundary Segmentation
Wang Laihua,Hou Chunping,Zhu Tao,Wang Baoliang,Yan Weiqing
(School of Electronic Information Engineering,Tianjin University,Tianjin 300072,China)
The distorted edge regions in depth map caused by depth coding will result in the quality of virtual view reduced.Depth map is divided into sharped boundary regions and smoothed non-boundary areas through the method that boundary segmentation is based on the just noticed depth difference(JNDD)and assign the different quantization parameters to the segmented regions,respectively.The experimental results show that the proposed method can well retain the edge information of depth map and effectively reduce the distortion of rendered virtual view.The rendered virtual view can also maintain high values of peak signal to noise ratio(PSNR)and structural similarity measurement parameters(SSIM).
renderedvirtual view;depth distortion;stereoscopic video coding
TP391
A
0493-2137(2016)09-0967-05
10.11784/tdxbz201506070
2015-06-19;
2015-09-16.
国家高技术研究发展计划(863计划)资助项目(2012AA03A301);国家基金重大研究计划重点资助项目(91320201);国家自然科学基金资助项目(61471262);教育部博士点基金资助项目(20130032110010).
王来花(1988—),女,博士,wlh@tju.edu.cn.
侯春萍,hcp@tju.edu.cn.
