基于SDN的数据中心网络流量调度机制的设计与实现
2016-11-01王文涛王玲霞穆晓峰
王文涛,郑 芳,王玲霞,穆晓峰
(中南民族大学 计算机科学学院,武汉 430074)
基于SDN的数据中心网络流量调度机制的设计与实现
王文涛,郑芳,王玲霞,穆晓峰
(中南民族大学 计算机科学学院,武汉 430074)
针对SA算法中未考虑当前网络链路带宽资源引起的流冲突问题以及GFF算法中未考虑流带宽需求变化引起带宽资源分配不合理问题,提出了基于模拟退火遗传算法的按需自适应(SAGA-AO)流量调度机制.该机制首先依据流带宽需求变化筛选出网络中需要调度的流,然后利用模拟退火遗传算法(SAGA)根据当前链路带宽资源状况对需要调度的流进行全局调度路径搜索.仿真结果表明:SAGA-AO算法在大多数通信模型下平均对分带宽高于SA和GFF算法.
数据中心网络;流量调度;按需自适应;模拟退火遗传算法
数据中心网络为不断增长的云计算、多媒体存储、大数据分析等业务提供关键的带宽需求[1].现有数据中心网络存在以下几个问题,首先,网络拓扑采用二级或三级树形结构,这种网络拓扑的总带宽利用率受限于上层网络带宽,因此当网络规模越大,对上层网络设备的性能要求也越高[2];其次,ECMP静态路由方法不能很好地利用数据中心网络多路径的特性;最后,缺乏智能管理,不能根据网络实时状况对网络资源进行合理分配.
软件定义网络(SDN)技术的兴起,为解决数据中心网络问题提供了新思路.SDN是一种新型的网络架构,起源于美国斯坦福大学2006年Clean Slate研究项目[3],其核心思想是将控制平面从传统分布式网络的网元设备中分离出来,通过集中式网络操作系统对网元设备实现集中控制,而网元设备只负责简单的数据转发工作,集中式网络操作系统向上提供灵活的、开放的可编程接口,网络管理者可利用这些开放的可编程接口实现相关的网络管理应用服务[4].基于SDN上述特性,本文利用SDN技术对数据中心网络的流量调度问题展开研究,通过SDN控制器实现对数据中心网络的集中式管理,利用OpenFlow[5]协议统计数据中心网络流量信息,设计并实现基于模拟退火遗传算法的按需自适应(SAGA-AO)流量调度机制,达到合理利用网络带宽资源、提高网络带宽利用率的目的.
1 SAGA-AO流量调度机制
SAGA-AO流量调度机制系统架构图如图1所示,主要包括数据中心网络、SDN控制器两个部分.数据中心网络采用Fat-Tree网络拓扑,通过OpenFlow交换机互联而成.所有的OpenFlow交换机通过安全信道连接到SDN控制器.OpenFlow交换机将网络中的流量信息报告给SDN控制器,同时根据SDN控制器修改流表的消息更新自身流表.在SDN控制器中设计ECMP路由模块、SAGA-AO流量调度模块、链路带宽资源回收模块等三个模块管理数据中心网络中的流量和资源.当网络中的流量到达OpenFlow交换机时,首先默认采用ECMP路由算法转发.SAGA-AO流量调度模块周期性地根据网络状态对网络中的流量实时调度.当流传输结束时,由带宽资源回收模块进行带宽资源回收.

图1 系统总体架构图Fig.1 System architecture
1.1流量监测
SAGA-AO流量调度模块周期性监测数据中心网络的边缘交换机.流量监测的目的有两个,其一是筛选网络中的大象流(带宽大于链路容量的10%),其二判断筛选出的流是否为新监测到的流.流量检测模块由OpenFlow协议的Flow-States消息实现.该模块根据Flow-States消息计算流的实际传输速率,判断该流是否为大象流.
1.2带宽需求估计
本文采用文献[6]提出的带宽估计算法估算由流量检测模块筛选出的大象流的自然带宽需求.自然带宽需求表示网络中的流传输速率只受源主机和目的主机的网络接口设备(NIC)的限制,而不受到传输路径中链路可用带宽的限制所能达到的最大带宽需求.这里估算流的自然带宽需求原因在于流当前占用链路的带宽不能反映流的实际带宽需求.TCP的AIMD行为和公平队列实现了对流带宽的最大最小公平分配,因此在带宽需求估计过程中采用最大最小公平分配方法.
1.3基于带宽需求变化的调度流筛选策略
文献[6]提出全局首次适应(GFF)流量调度算法.GFF是一种贪心策略,该算法遍历每条流的所有可能路径,根据路径的剩余带宽信息找到第一条满足流带宽需求的路径.GFF算法在分配路径时虽然考虑了当前网络链路资源状况,但是其并没有考虑调度过程中流带宽需求的变化.对于带宽需求变化的流仍按照原分配路径转发,这是不合理的.针对该问题,本文提出基于带宽需求变化的调度流筛选策略.该策略根据带宽需求的变化,对网络中的流合理调度,筛选出网络中当前链路带宽不满足带宽需求的流和新到达的流,避免对所有的流频繁调度.基于带宽需求变化的调度流筛选策略如算法1所示.该算法首先遍历ElephantFlows中的每一条流,若该流是新监测的流,则将其加入到ScheduleFlows集合中;否则该流在之前的调度过程中已分配路径,判断该流的带宽需求是否发生变化.若流的带宽需求变小,则已分配路径链路带宽可以满足该流的带宽需求,不需要重新调度,收回该路径的多余带宽资源;若新的带宽需求变大,进一步判断当前路径的可用链路带宽是否满足流新的带宽需求.若路径带宽可以满足该流新的带宽需求,则不需要对该流重新调度,用新的带宽需求更新路径的剩余带宽;否则需要对该流重新调度,收回已分配路径的带宽资源,加入到ScheduleFlows集合中.该算法的时间复杂度为O(|F|).
算法1 基于带宽需求变化的调度流筛选策略
输入:当前网络大象流集合Elephantflows, 链路剩余容量FreeBW
输出:需要调度流集合ScheduleFlows
forallflowfinElephantflowsdo
iff.assigned =Falsethen
ScheduleFlows ←ScheduleFlows∪{f}
else
iff.new_demand < f.old_demand
foralllinklinf.pathdo
FreeBW[l] ← FreeBW[l] + f.old_demand - f.new_demand
elseiff.new_demand > f.old_demandthen
ifalllinksinf.pathsatisfyFreeBW > f.new_demand - f.old_demandthen
foralllinklinf.pathdo
FreeBW[l] ← FreeBW[l] +
f.old_demand - f.new_demand
else
foralllinklinf.pathdo
FreeBW[l] ← FreeBW[l] + f.old_demand
ScheduleFlows ← ScheduleFlows∪{f}
endif
endif
endif
endfor
2 基于SAGA的调度路径搜索算法
文献[6]提出模拟退火(SA)流量调度算法,该算法在每个调度周期都将网络所有链路看成空闲状态,对流进行调度路径分配时没有考虑当前网络链路资源状况,容易造成流冲突.针对该问题,本文提出基于SAGA的调度路径搜索算法,该算法根据网络当前链路带宽资源状况搜索流的调度路径.SAGA算法是一种将遗传算法(GA)和SA算法相结合的算法,对两者取长补短.
2.1算法模型
本文利用SAGA算法对ScheduleFlows中的流进行全局路径搜索,算法模型描述如下:将数据中心网络拓扑定义为G(S,L),其中S为网络中的交换机节点集合,S={s1,s2,…,sn},L为网络中链路集合,L={l1,l2,…,ll},链路容量C={cl1,cl2,…,cll}.设当前网络需要调度流集合F={f1,f2,…,fk}.给所有流分配路径集合P={(p1,bw1),(p2,bw2),…,(pk,bwk)},其中pi={li1,li2,…,lip}表示流fi被分配路径,bwi表示路径pi预留给流fi的带宽.本文设计算法优化模型为最大化所有流调度路径上的总链路带宽利用率,即:
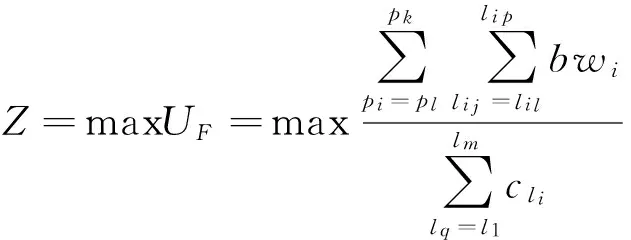
(1)
其中,分子表示所有流调度路径上每条链路的预留带宽之和,分母表示所有流调度路径上每条链路的容量之和;k表示当前网络需要调度的流的数目;p表示流被分配到路径上的链路数目;m表示所有流调度路径链路总和.
2.2算法步骤
(1) 初始化控制参数,包括种群大小,退火初始温度T0,交叉和变异概率.
(2) 采用随机方式初始化种群.本文通过目的主机与最高层交换机映射,将网络中的流调度到其目的主机映射的最高层交换机所在的路径上.具体染色体编码方式如下:对于一个k级Fat-tree拓扑结构,共有(k/2)2个核心交换机,设定核心交换机的编号为CoreSwich_ID={1,2,3,…,(k/2)2},共有k个Pod,每个Pod有k/2个汇聚交换机,以Pod为单位设定汇聚交换机的编号为AggSwitch_ID={1,2,…,k/2},设当前网络需要调度流的目的主机总数为n,设定目的主机的编号为DstHost_ID={1,2,…,n}.染色体的大小为n,n为当前网络流的目的主机数.染色体基因值为目的主机的编号DstHost_ID.根据(2)式将目的主机映射到对应的核心交换机或汇聚交换机:
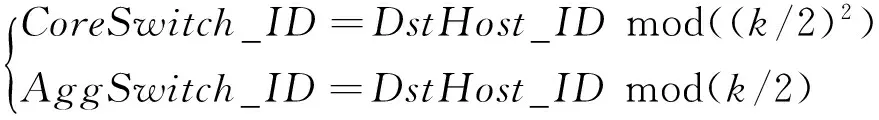
(2)
(3) 计算初始种群每个个体对应的调度路径和适应度函数值.根据本文算法设计的优化目标将所有流调度路径上的总链路带宽利用率作为适应度函数f=UF.
(4) 对种群进行选择、交叉、变异操作产生新种群.本文遗传算子采用偏置轮盘选择,根据个体的适应度函数值与群体适应度函数总和之比计算每个个体的选择概率,个体适应度函数值越大,被选中的概率越大;交叉算子采用单点交叉方法,将种群中相邻的两个个体的染色体随机选取一点以一定的交叉概率进行交叉,通过交叉算子使得目的主机映射的汇聚交换机和核心交换机发生改变,对应的传输路径也发生改变;变异算子则首先随机选择两个变异位置,然后以一定的变异概率将这两个变异位置的基因进行互换.
(5) 计算新种群每个个体对应的调度路径和适应度函数值,并根据Metopolis准则判断是否接受新个体.Metopolis准则如(3)式所示:
(3)
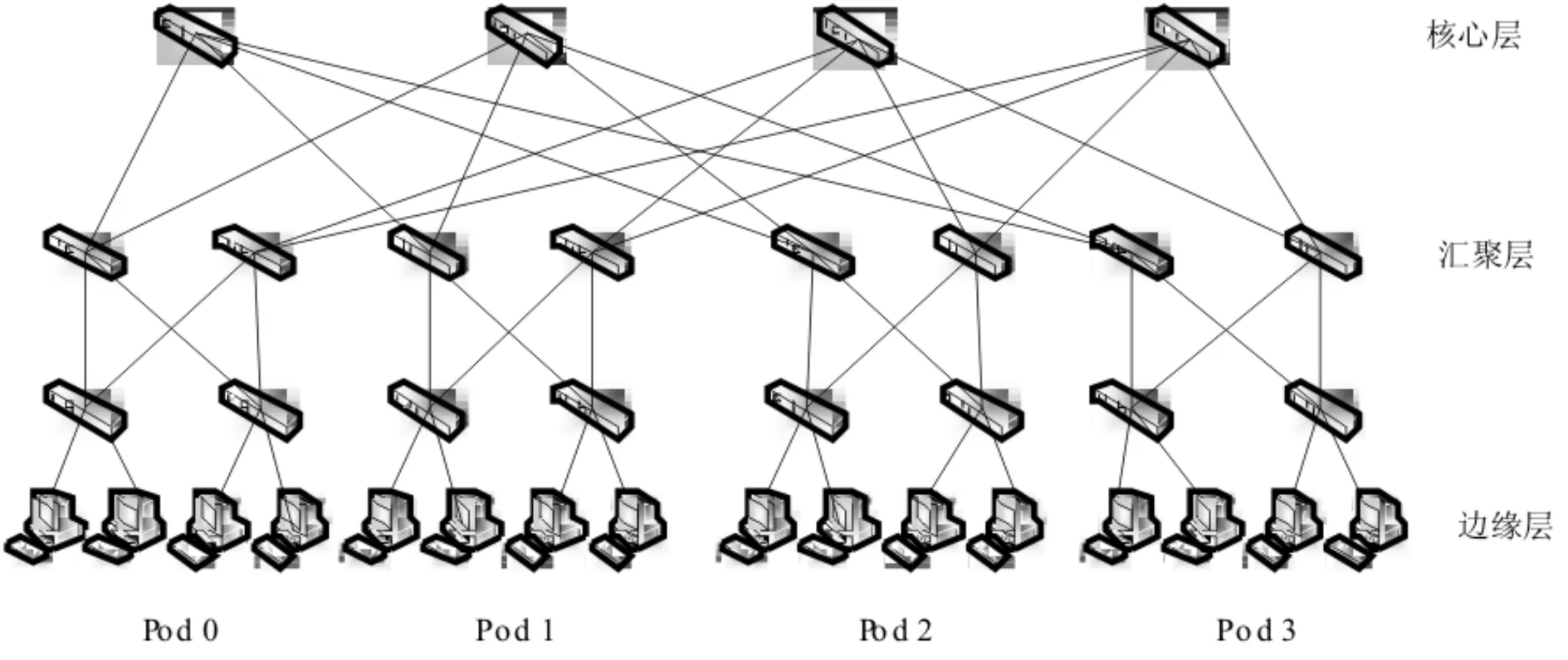
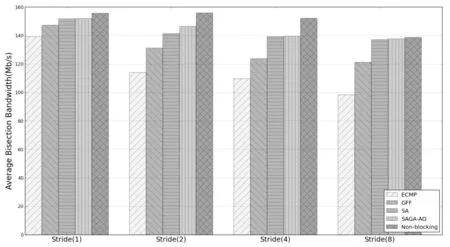
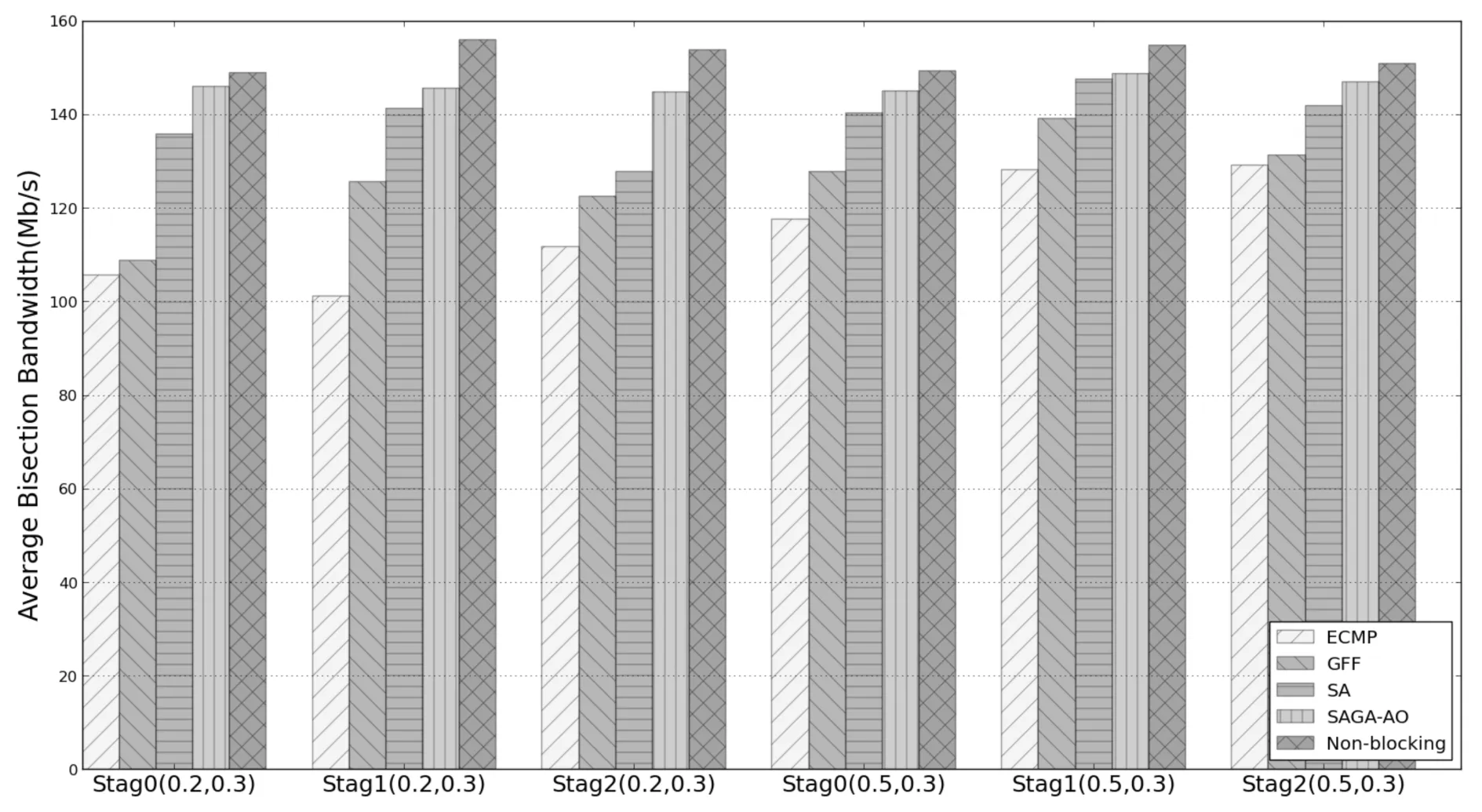
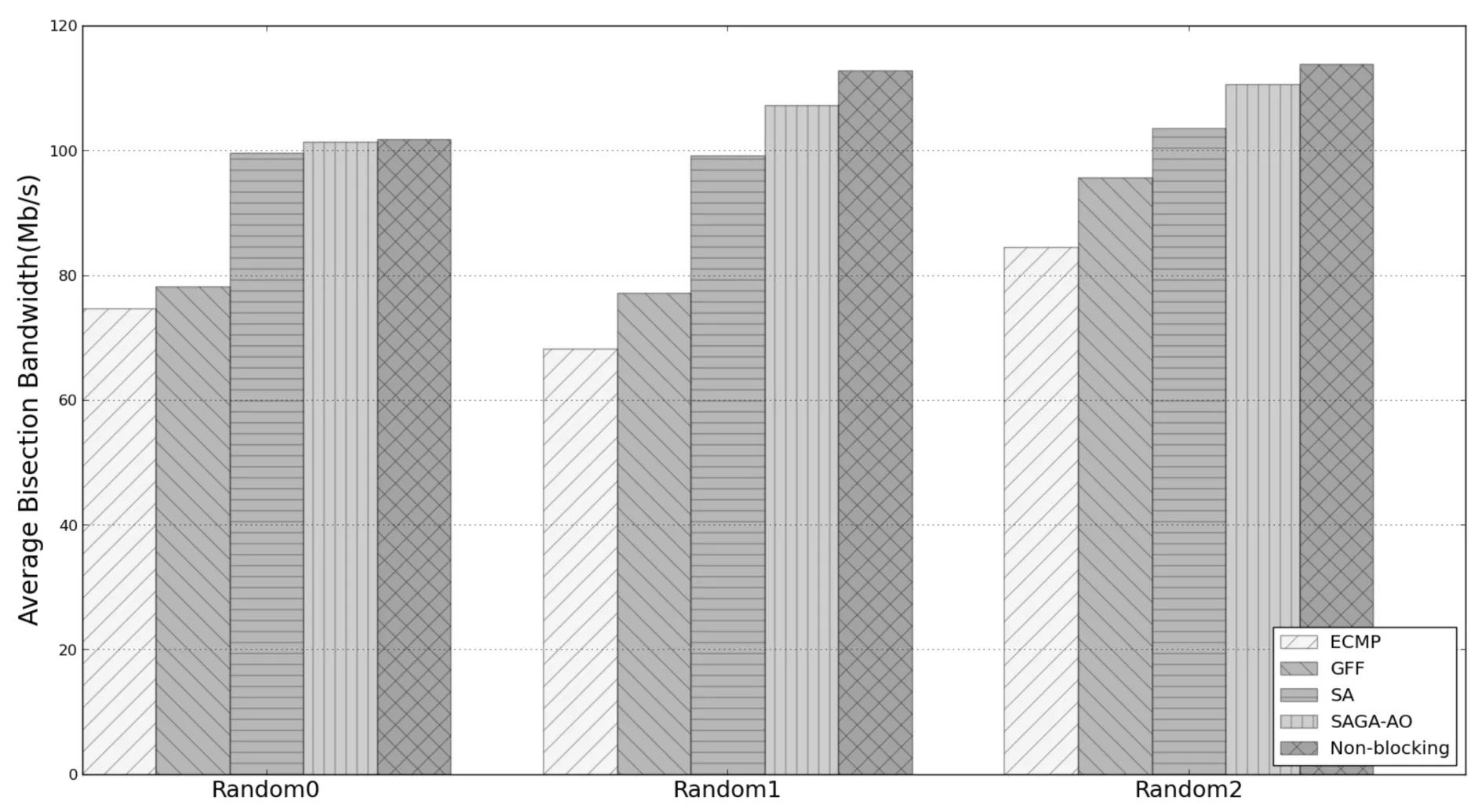
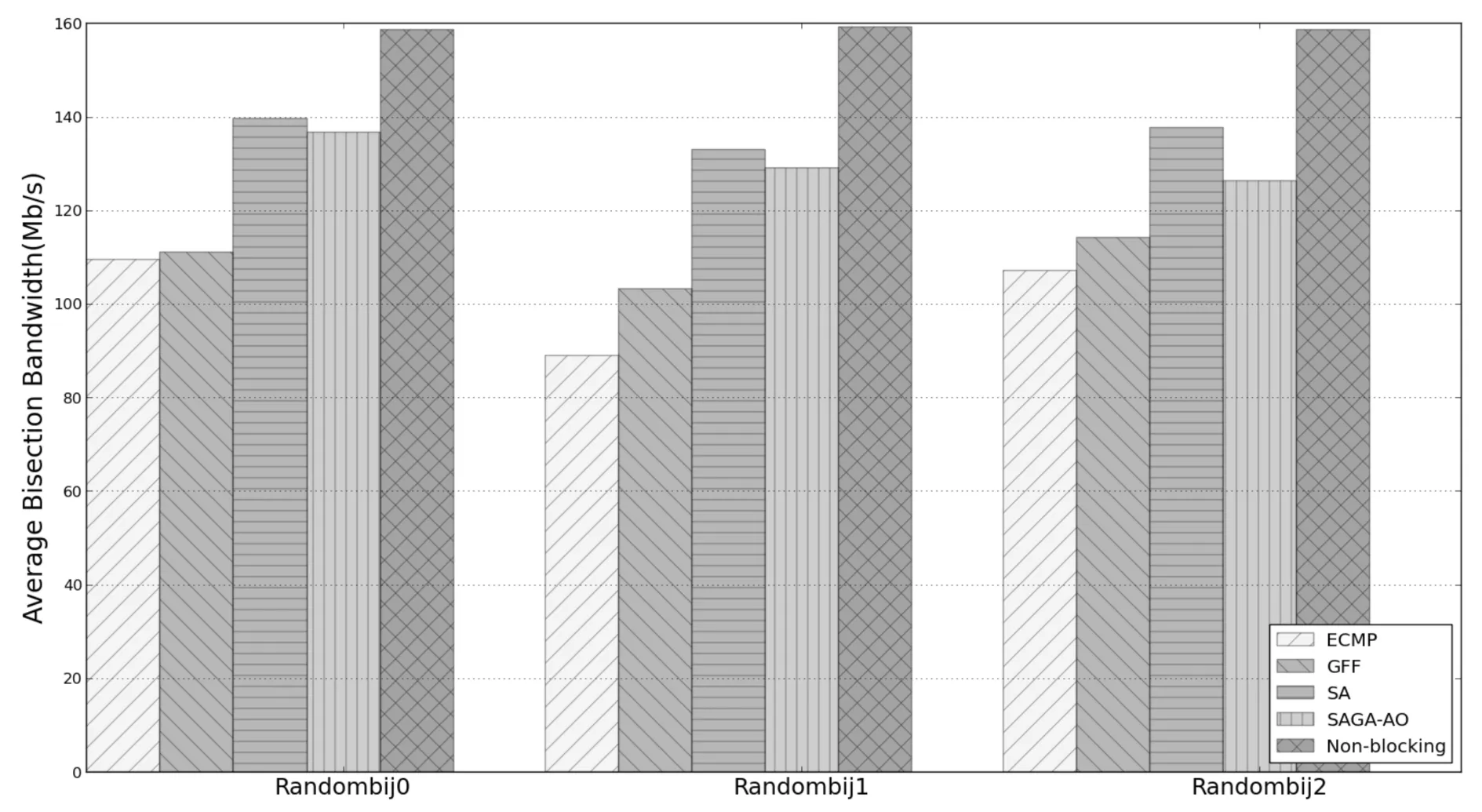
其中f表示旧个体适应度值,fn表示新个体适应度值,T为退火温度,K为常数,P表示新个体接受概率.(3)式的含义是若fn≥f,则用新个体取代旧个体,即接受概率P=1;若fn (6) 若T>0,则T=T-1,转至步骤(4). (7) 否则,算法终止,获得全局最优调度路径. (8) 根据流的调度路径更新对应路径链路上的剩余带宽信息. 3.1实验平台 本文实验采用POX控制器和Mininet搭建网络仿真环境.POX控制器基于组件化设计,为软件组件提供定义良好的API,网络管理者可以有效地利用API创建新的网络管理和控制应用程序.Mininet是由Stanford大学开发的一套进程虚拟化网络模拟器,它使用轻量级的虚拟化技术在单个系统中模拟出拥有多个主机、交换机和链路的网络环境. 3.2实验设计 3.2.1实验网络拓扑 本文数据中心网络拓扑采用k=4的Fat-Tree拓扑结构,见图2.该网络拓扑分为核心层、汇聚层和边缘层.每条链路的带宽均设置为10Mbit/s,同时设置一组无阻塞网络拓扑(Non-blocking)作为理想状态进行对比实验.Non-blocking中16个主机通过一个交换机互联,因此该拓扑主机之间发送的流量不受中间链路的带宽限制. 图2 Fat-Tree拓扑结构Fig.2 Fat-Tree topology 3.2.2实验通信模型 实验仿真采用文献[6]提出的4种通信模型,利用Iperf工具产生流量数据. (1) Stride(i):下标为x的主机向下标为(x+i)mod(num_hosts)的主机发送数据. (2) Staggered(EdgeP,PodP):每个主机以概率EdgeP向与其在同一个边缘交换机的主机发送数据,以概率PodP向与其在同一Pod内的主机发送数据,以概率1-EdgeP-PodP向核心交换机发送数据. (3) Random:每个主机以等概率随机向网络中其他主机发送数据. (4) Randombij:每个主机按照一一对应的方式与其他主机进行通信.该通信模型是Random模型的特例,在某些集群计算应用中可能产生该类通信模型[7]. 3.2.3对比算法及评价指标 实验中将本文提出的SAGA-AO流量调度机制与只运用ECMP算法而没有进行流量调度的情况以及文献[6]提出的GFF算法和SA算法进行对比分析,并且将对分带宽作为各算法的性能评价指标.对分带宽是指将一个网络中的主机分为对等的两部分所需切断最小连接链路数的带宽总和,它是衡量数据中心网络带宽利用率的重要指标,对分带宽越大网络容量越高,对故障的容错能力越强[8].在实验中,通过带宽监测工具bwm-ng测量边缘交换机连接主机的端口发送速率并以此计算网络平均对分带宽. 3.3实验结果与分析 (1) Stride通信模型下的实验结果. 在Stride(i)通信模型下选取i=1,i=2,i=4,i=8四种情况进行实验对比分析.Stride(1)、Stride(2)、Stride(4)、Stride(8)等四种通信模型下各算法的平均对分带宽对比结果如图3所示.由图3可知,随着参数i的增大,各算法的平均对分带宽逐渐降低.原因在于随着参数i增大,Stride通信模型的Pod间的流量比率增大,导致核心层链路负载增加,部分链路产生拥塞.在这4种通信模式下,本文提出的SAGA-AO算法的平均对分带宽高于ECMP、GFF和SA三种算法.在Stride(8)通信模型下,SAGA-AO算法的平均对分带宽接近于理想状态下的平均对分带宽. 图3 Stride通信模型下平均对分带宽对比结果 Fig.3 Average bisection bandwidth for Stride communication pattern (2) Staggered通信模型下的实验结果. 在实验中每个通信模型各取3组实验,Staggered(0.2,0.3),Staggered(0.5,0.3)通信模型下各算法的平均对分带宽对比结果如图4所示,可以看出,在Staggered(0.2,0.3)和Staggerd(0.5,0.3)两种通信模型下,本文提出的SAGA-AO算法平均对分带宽均高于其他流量调度算法,原因在于Staggered通信以概率的方式产生流量,同一Pod内主机发送流量的目的主机存在随机性,因此SAGA调度路径搜索算法采用目的主机与最高层交换机随机映射的方法在Staggered通信模型下具有优势,可以更快地搜索到近似最优解,将流量调度到最佳路径,提高链路带宽利用率.同时从图4可以看到,Staggered(0.5,0.3)通信模型下各算法的平均对分带宽大于Staggered(0.2,0.3)通信模型下的平均对分带宽.原因在于Staggered(0.2,0.3)通信模型的Pod间流量产生概率较大,由核心交换机转发的流量多,核心交换机的负载大,链路带宽利用率低.但是这一特性对SAGA-AO算法的影响较小,在这6组实验中SAGA-AO算法的平均对分带宽均达到145Mbit/s左右. 图4 Staggered通信模型下平均对分带宽对比结果 Fig.4 Average bisection bandwidth for Staggered communication pattern (3) Random通信模型下的实验结果. Random通信模型下各算法的平均对分带宽对比结果如图5所示,在该组实验选取3组实验.从图5可以看出,在Random通信模型下,本文提出的SAGA-AO算法平均对分带宽均高于其他流量调度算法.Random通信模型同一Pod内主机发送流量的目的主机也存在随机性,因此在该模型下SAGA调度路径搜索算法的目的主机与最高层交换机随机映射方法具有优势,能有效地搜索当前网络流调度路径的近似最优解,提高链路带宽利用率.Random通信模型的流量类型存在随机性,且存在多个源主机发送到同一目的主机的流量.这种情况下,流的自然带宽需求大大减小,带宽利用率也随之减小.因此,与图3和图4相比,在Random通信模型下,各算法平均对分带宽均低于Stride(i)和Staggered通信模型. 图5 Random通信模型下平均对分带宽对比结果 Fig.5 Average bisection bandwidth for Random communication pattern (4) Randombij通信模型下的实验结果. Randombij通信模型下各算法的平均对分带宽结果如图6所示,在该通信模型下选取3组实验.从图6可以看出,在Randombij通信模型下,本文提出的SAGA-AO算法平均对分带宽高于ECMP和GFF算法,但是低于SA算法.原因在于Randombij通信模型发送流量采取一一映射方式,SA算法采用的同一Pod目的主机与核心交换机一一映射方法在该通信模型下具有优势,该方法可以将到达同一Pod内的目的主机发送的流量分配到不同的核心交换机,均衡核心交换机的负载,增大链路带宽利用率.而本文提出的基于SAGA的流量路径搜索算法采取目的主机与最高层交换机随机映射方法,增大了在此通信模型下流量路径的搜索空间,因此在一定的迭代次数下不能得出较优的近似解,平均对分带宽低于SA算法. 图6 Randombij通信模型下不同流量规模平均对分带宽对比结果Fig.6 Average bisection bandwidth for Randombij communication pattern 针对Hedera流量调度机制中SA算法的流冲突问题以及GFF带宽资源分配不合理问题,本文提出了SAGA-AO流量调度机制.该机制通过实现ECMP路由模块、SAGA-AO流量调度模块和链路带宽资源回收模块,对数据中心网络中的流量和资源进行管理.随后通过POX控制器和Mininet模拟器实现了该机制并进行实验仿真分析.仿真结果表明:本文提出的基于模拟退火算法的按需自适应流量调度机制在Stride、Staggered和Random三种通信模型下对分带宽均高于ECMP、GFF和SA算法,而在Randombij通信模型下对分带宽低于SA算法. [1]李丹,陈贵海,任丰原,等. 数据中心网络的研究进展与趋势[J].计算机学报,2014,37(2):259-274. [2]魏祥麟,陈鸣,范建华,等. 数据中心网络的体系结构[J].软件学报,2013,24(2):295-316. [3]张朝昆,崔勇,唐翯祎,等. 软件定义网络(SDN)研究进展[J].软件学报,2015,26(1):62-81. [4]Farhady H, Lee H, Nakao A. Software-Defined Networking: A survey[J].Computer Networks,2015,81:79-95. [5]Mckeown N, Anderson T, Balakrishnan H, et al. OpenFlow: enabling innovation in campus networks[J]. ACMSIGCOMM Computer Communication Review, 2008, 38(2): 69-74. [6]Al-Fares M, Radhakrishnan S, Raghavan B, et al. Hedera: dynamic flow scheduling for Data Center Networks[C]//ACM. Proceedings of the 7th USENIX conference on Network Systems Design and Implementation (NSDI). New York: ACM, 2010: 19-24. [7]Cui W, Qian C. DiFS: Distributed flow scheduling for Data Center Networks[C]//ACM. Proceedings of the tenth ACM/IEEE Symposium on Architectures for Networking and Communications Systems(ANCS). New York: ACM, 2014: 53-64. [8]陆菲菲,罗兴国,谢向辉,等. 面向大规模数据中心的常量度数互连网络研究[J].计算机研究与发展, 2014,51(11):2437-2447. Design and Implementation of Flow Scheduling Mechanism Based on SDN for Data Center Network WangWentao,ZhengFang,WangLingxia,MuXiaofeng (College of Computer Science, South-Central University for Nationalities, Wuhan 430074, China) SA algorithm has the flow conflict problem because it does not consider the current network link bandwidth resources, and GFF algorithm easily lead to the irrational distribution of bandwidth resources because of not considering the change of flow demand. To solve the two problems, we proposed an adaptive on-demand flow scheduling mechanism. First, the mechanism filtered the flows needed to be scheduled based on the changing of demand. Second, it globally searched scheduling path for these flows using the simulated annealing genetic algorithm(SAGA) based on the available link bandwidth resources. The simulated results showed that the mechanism we proposed outperform GFF and SA in the majority of communication patterns. data center network; flow scheduling; adaptive on-demand; SAGA 2016-04-01 王文涛(1967-),男,副教授,博士,研究方向:智能网络与信息处理,E-mail:wangwt@mail.scuec.edu.cn 国家民委教改基金资助项目(15013);中南民族大学研究生创新基金资助项目(2016sycxjj199) TP393 A 1672-4321(2016)03-0135-063 系统验证
4 结束语
