基于标签和云模型的协同过滤算法
2016-11-01雷建云李白杨
雷建云,何 顺,李白杨
(1 中南民族大学 计算机科学学院,武汉 430074;2 云南大学 软件学院,昆明 650500)
基于标签和云模型的协同过滤算法
雷建云1,何顺1,李白杨2
(1 中南民族大学 计算机科学学院,武汉 430074;2 云南大学 软件学院,昆明 650500)
引入云模型改进基于标签的用户相似性和资源相似性度量方法,进而提出了基于标签和云模型的协同过滤算法.通过在MovieLens数据集上的实验表明:改进后的算法在precision, recall和F1-measure三个指标上均取得较好的推荐效果,推荐效率均优于传统的方法.
标签;协同过滤;云模型;相似性
冷启动和数据稀疏性[1]是推荐系统面临的重要问题,也是研究的热点.自进入Web2.0时代以来,用户可以根据自己的理解和喜好自由选择和添加标签.研究表明标签可以用于Blogs分类[2],信息检索领域[3,4]和推荐系统[5].为了降低冷启动和数据稀疏性对于协同过滤推荐性能的影响[6],将传统协同过滤算法扩展为基于标签的协同过滤算法.文献[7]首次将标签信息引入协同过滤算法中,利用标签标注情况扩展了用户资源评分矩阵,一定程度上提高了推荐的效果.文献[8]将标签信息融入到基于模型的协同过滤算法中,对于稀疏数据和冷启动问题获得较好的推荐效果.文献[9]提出一种基于标签语义相似度度量方法,相似性度量借助普林斯顿大学心理学家、语言学家和计算机工程师联合开发的基于认知学的英语词典WordNet,提高了最近邻选择的准确度,但其准确度依赖于词典.基于标签的相似性计算大多采用统计方法,通过标签对用户或资源的关联度求得[10-12].云模型是处理定性概念与定量描述的不确定转换模型,本文将云模型引入基于标签的协同过滤算法中,利用量化的标签关联度,计算用户或项目之间的定性概念相似度,提出基于标签和云模型的协同过滤算法.
1 基于标签和云模型的协同过滤算法
云模型是实现定性概念与定量数值之间不确定性转换的数学模型[13,14].由于其良好的数学性质,可以表示自然科学、社会科学中大量的不确定现象.每个云由很多云滴组成,(Ex,En,He)表示云的数字特征,分别是云期望、云熵和云超熵[14].
1.1改进的标签关联度度量
使用TF-IDF思想的关联度计算方法是一种统计型计算,计算时认为每个标签视为孤立的,即每个特征关联度向量是正交的、不相关的,但是实际上标签之间存在一定的语义关系,例如“教材”和“课本”两个标签是存在一定语义关系的.本文借鉴文本挖掘中AlessRB的TF-IWF[15]思想提出新的关联度计算方法.
1)用户标签关联度.
已知用户集合U={u1,u2,…,un},标签集合T={t1,t2,…,tm},任意标签tk(k=1,2,…,m)与任意用户ui(i=1,2,…,n)的关联度计算方法为:

(1)
其中N(ui,tk)表示用户ui使用标签tk的次数,N(ui,t)表示用户ui使用的所有标签的总次数,N(Utj)表示所有用户使用标签tj的总次数.
2)资源标签关联度.
已知资源集S={s1,s2,…,sp}, 标签集合T={t1,t2,…,tm},任意标签tk(k=1,2,…,m)对于任意资源si(i=1,2,…,p)关联度计算公式如下:
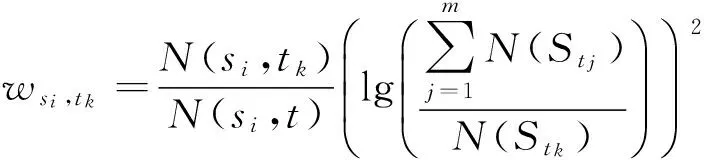
(2)
其中N(si,tk)表示资源si被标注为标签tk的次数,N(Stk)表示资源集被标注为标签tk的总次数.
1.2基于标签的云相似性度量
1) 用户标签云相似度.
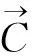

(3)

2)资源标签云相似度.
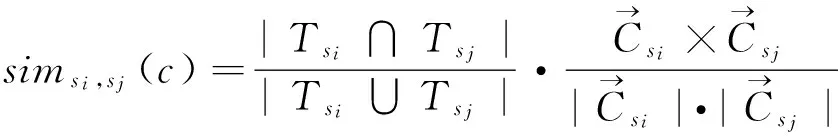
(4)
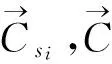
1.3基于标签和云模型的相似性度量
为更准确地度量用户或资源的相似性,将表征用户或资源的标签信息所表示的定性概念相似度即云相似度与基于标签关联度计算的相似度,通过引入权重因子λ进行加权组合,λ用于反映两种相似度对最终相似度的贡献,设定λ的取值为(0,1).计算方法见公式(5)和公式(6).
simui,uj(w,c)=(1-λ)simui,uj(w)+λsimui,uj(c),
(5)
(5)式为基于标签和云模型的用户相似性度量方法,其中simui,uj(w)是基于改进标签关联度公式(1)计算的用户相似度,simui,uj(c)为用户标签云相似度,计算参照公式(3).
simsi,sj(w,c)=(1-λ)simsi,sj(w)+λsimsi,sj(c),
(6)
(6)式为基于标签和云模型的资源相似性度量方法,其中simsi,sj(w)是基于改进标签关联度公式(2)计算的资源相似度,simsi,sj(c)为资源标签云相似度,计算参照公式(4).
1.4基于标签和云模型的协同过滤算法描述
根据上面提出的基于标签和云模型的相似性度量方法,提出新的基于标签和云模型的协同过滤算法,算法描述如下.
算法1.基于标签和云模型的协同过滤算法.
输入:用户-标签-资源记录,参数λ,目标用户u,用户最近邻数K,推荐的资源数N.
输出:目标用户u的TOP-N资源推荐.
方法:
1) 统计用户-标签-资源记录文件中每个用户对于每个标签的使用频度信息(或每个资源被标注为每个标签的次数信息);
2) 使用公式(1)计算用户标签关联度信息,得到用户标签关联度矩阵(或使用公式(2)计算资源标签关联度信息,得到资源标签关联度矩阵);
3) 根据关联度向量计算用户相似性simu(w)(或计算资源相似性sims(w));
4) 使用公式(3)计算用户标签云相似性simu(c)(或者使用公式(4)计算资源云相似性sims(c));
5) 将λ代入公式(5)计算用户基于标签和云模型的相似度simu(w,c)(或结合公式(6)计算资源基于标签和云模型的相似度sims(w,c));
6) 重复3),4),5)计算得到相似度矩阵Matrixsim;
7) 计算资源兴趣度,产生TOP-N推荐列表.
2 实验及分析
2.1实验数据集
实验采用的数据集由GroupLens站点提供的MovieLens数据集,它由美国 Minnesota 大学计算机科学与工程学院的 GroupLens 项目组创办,该数据集有多个版本,本实验选择MovieLens 20M作为实现对象,该数据集包括138000个用户,27000部电影和465000个标签记录.为保证实验的稳定性,对数据集进行了预处理.实验最终选取的数据集包含2606个用户,1278部电影和2636个标签.为保证实验结果的准确性,排除其他偶然因素的影响,本文将数据集随机划分为两部分,从每个用户标注过的电影集中选取80%作为训练数据,另外20%作为测试数据.
2.2评价标准
推荐的准确度是评价推荐算法的最基本的指标.本文采用的评价指标包括准确率(precision)、召回率(recall)和F1-measure[16].准确率表示用户对推荐系统推荐资源感兴趣的概率.召回率表示一个用户喜欢的商品被推荐的概率.准确率和召回率越高,表示推荐效果越好.F1-measure综合了准确率和召回率的结果,当F1-measure较高时则说明实验方法比较理想.设R(u)是根据用户在训练集上的行为给用户做出的推荐列表,T(u)是用户在用户测试集上的行为列表.那么推荐结果的准确率为:

(7)
推荐结果的召回率计算公式如下:
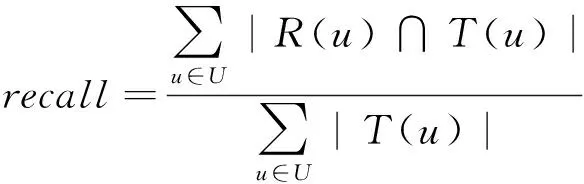
(8)
F1-measure定义为:
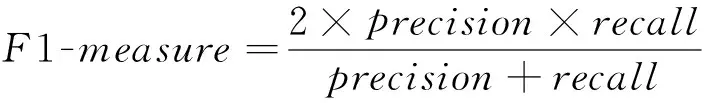
(9)
2.3实验结果
实验1 将推荐列表的长度N设为10,实验中设置的最近邻数目K从10 开始,依次增加,增至80.实验对比文献[7]和文献[11]中的方法,分别比较基于用户的协同过滤算法和基于资源的协同过滤算法.文献[7],[11]中基于用户的协同过滤算法分别记为UTCF,UTTCF,基于资源的协同过滤算法分别记为ITCF,ITTCF.基于本文中改进关联度计算的用户协同过滤算法和资源协同过滤算法分别记为UTMCF和ITMCF.基于本文提出的标签云相似性的用户协同过滤算法和资源协同过滤算法分别记为UTCCF和ITCCF.实验结果如表1~4所示.
从表1~4的实验结果值可以看出,对比同类型的协同过滤算法,基于改进关联度的协同过滤算法(UTMCF,ITMCF)和基于标签云相似度的算法(UTCCF,ITCCF)的推荐质量均有一定程度提高,优于文献[7]和文献[11]的方法.实验可发现,随着最近邻数量的增加,推荐的质量并不是一直增加,而是增大到某一值后逐渐减小的.其中在基于用户的协同过滤算法中算法UTMCF在最近邻为50时取得较好的推荐效果,在基于资源的协同过滤算法中算法ITMCF的precision值和recall值均较好些,且在最近邻数为60时取得较优的推荐效果.基于标签云相似度的算法UTCCF和ITCCF比文献[7]和[11]均有一定程度提高,但效果低于基于改进关联度的协同过滤算法.
表14种基于用户的协同过滤算法的precision值
Tab.1Precision of four kinds of user-based collaborative filtering algorithm

KprecisionUTCFUTTCFUTMCFUTCCF100.065480.111580.113530.11331200.076300.112310.116560.11450300.086470.112770.118830.11634400.091340.113960.120670.11872500.092430.114940.121210.11883600.092210.114180.119370.11753700.091340.114090.118750.11677800.090480.113880.118720.11522

表2 4种基于用户的协同过滤算法的recall值

表3 4种基于资源的协同过滤算法的precision值
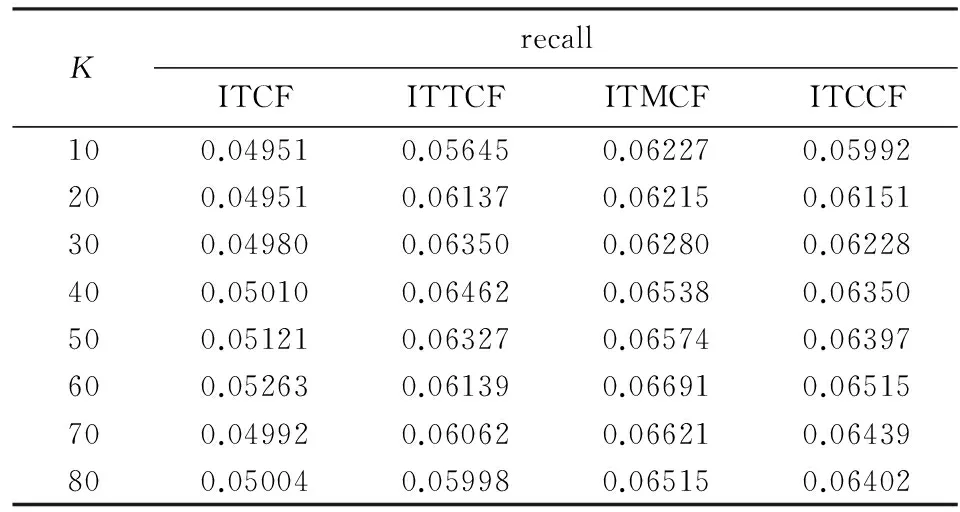
表4 4种基于资源的协同过滤算法的recall值
实验2将推荐列表的长度N设为10,最近邻数目K从10 开始,依次增加,增至80.基于标签和云模型协同过滤算法中λ为设定调节两种来源相似性的权重因子,选择合适λ值将影响推荐的精度,实验中将λ的值设为从0.1到0.9,每次增加0.1,分别测试λ对推荐结果的影响.对应的基于用户的协同过滤算法和基于资源的协同过滤算法分别记为UWTCF和IWTCF.
实验发现算法UWTCF对于不同的λ值,在最近邻数K=50时均取得较好推荐效果.当K=50时,随着λ的变化,算法UWTCF的F1-measure变化如图1所示;算法IWTCF对于不同λ值,在最近邻K=60时均取得较好推荐效果.当K=60时,随着λ的变化算法IWTCF的F1-measure指标变化如图2所示.图1中算法UWTCF(K=50)对应的F1-measure的变化曲线可以看出,当λ=0.2时算法的推荐性能是较好的;当λ的值大于0.2时F1-measure的值逐渐减小.从图2中算法IWTCF(K=60)对应的F1-measure的变化曲线可以看出,当λ=0.5时算法的推荐性能是较好的,随着λ取值大于0.5,F1-measure的值也逐渐减小.
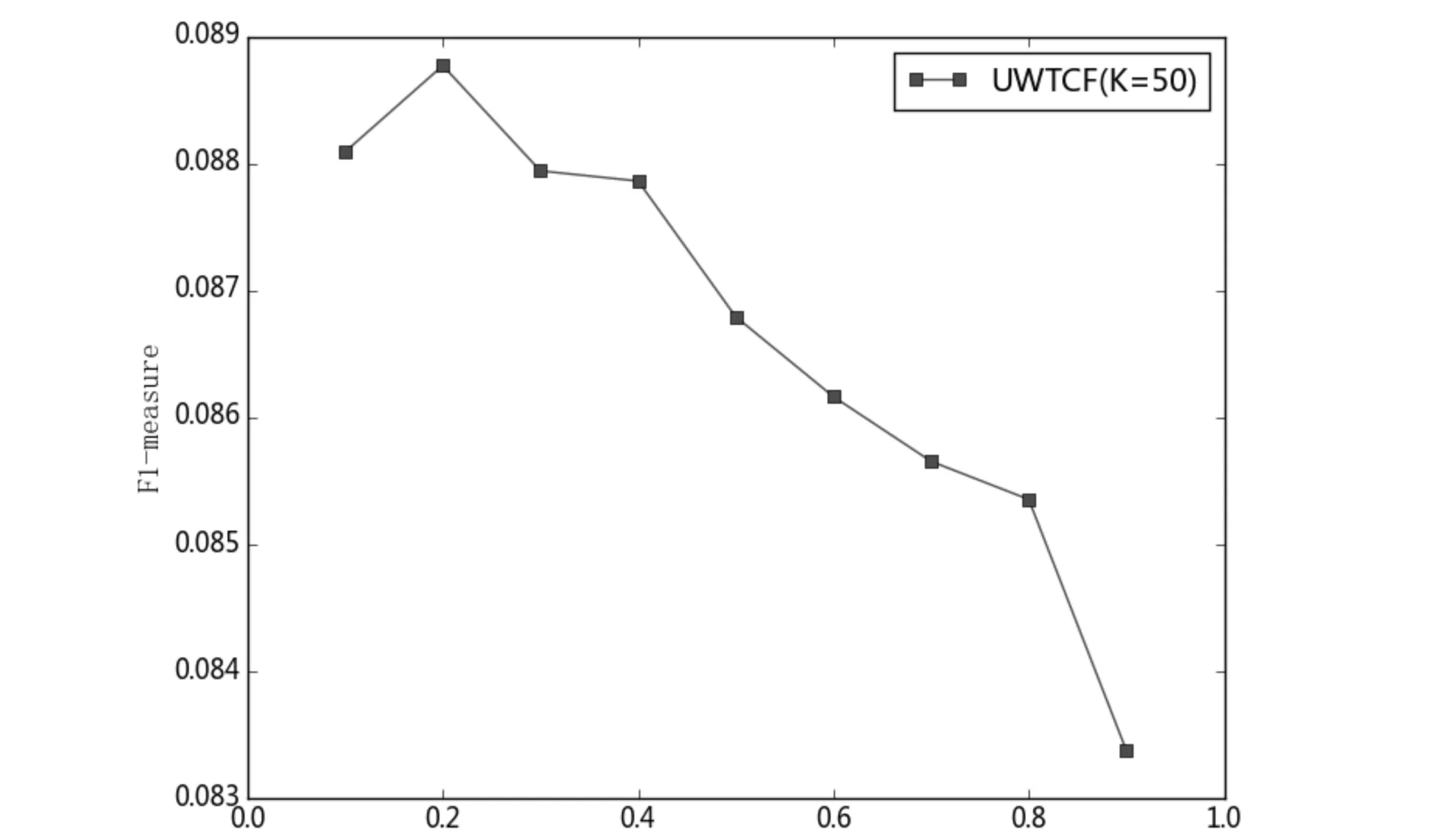
λ图1 λ对算法UWTCF(K=50)F1-measure的影响Fig.1 The effect of λ on the F1-measure of UWTCF (K=50)

λ图2 λ对算法IWTCF(K=60)F1-measure的影响Fig.2 The effect of λ on the F1-measure of IWTCF(K=60)
为验证算法的有效性,在同等数据集的基础上,UWTCF对比实验1中本文所提算法UTMCF,UTCCF,IWTCF对比算法ITMCF,ITCCF.将算法UWTCF中参数λ设置为0.2,IWTCF算法中参数λ设为0.5.
从表5可以看出3种基于用户的协同过滤算法均在最近邻数K=50时,取得较大的准确率(precision)和召回率(recall).实验发现最近邻数量较少时,不足以充分挖掘出与目标用户相似的用户.最近邻数量较大时,因为考虑了一些相似性较低的
用户,使得推荐的资源产生误差,进而影响到推荐质量.虽然伴随着最近邻数量的变化,算法UWTCF(λ=0.2)准确率和召回率也在变动,但是推荐效果总是较优的.
表53种基于用户的协同过滤算法的precision和recall
Tab.5Precision and recall of three kinds of user-based collaborative filtering algorithm
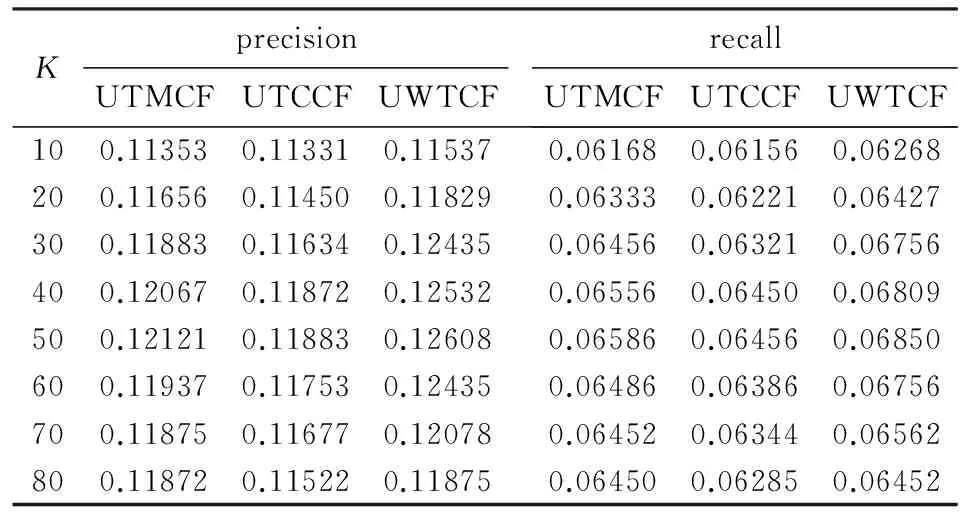
KprecisionUTMCFUTCCFUWTCFrecallUTMCFUTCCFUWTCF100.113530.113310.115370.061680.061560.06268200.116560.114500.118290.063330.062210.06427300.118830.116340.124350.064560.063210.06756400.120670.118720.125320.065560.064500.06809500.121210.118830.126080.065860.064560.06850600.119370.117530.124350.064860.063860.06756700.118750.116770.120780.064520.063440.06562800.118720.115220.118750.064500.062850.06452
表6中3种基于资源的协同过滤算法推荐性能指标随着最近邻数量的增加,先增大后减少,算法IWTCF(λ=0.5)总是能取得较好的推荐效果,且在最近邻数K=60时,推荐效果最佳.
表63种基于资源的协同过滤算法的precision和recall
Tab.6Precision and recall of three kinds of item-based collaborative filtering algorithm
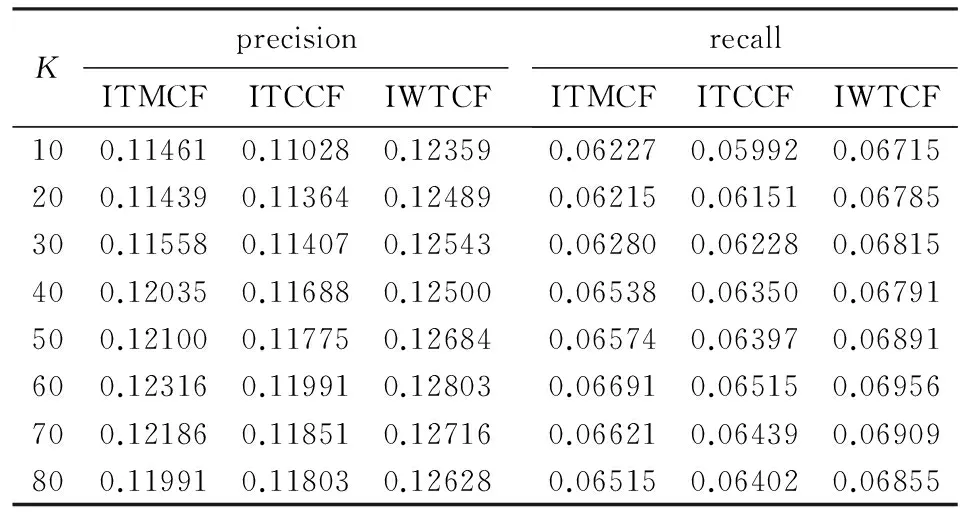
KprecisionITMCFITCCFIWTCFrecallITMCFITCCFIWTCF100.114610.110280.123590.062270.059920.06715200.114390.113640.124890.062150.061510.06785300.115580.114070.125430.062800.062280.06815400.120350.116880.125000.065380.063500.06791500.121000.117750.126840.065740.063970.06891600.123160.119910.128030.066910.065150.06956700.121860.118510.127160.066210.064390.06909800.119910.118030.126280.065150.064020.06855
从表5和表6 中可以看出算法UWTCF(λ=0.2)和算法IWTCF(λ=0.5)分别在最近邻数为50和60时取得较好的推荐效果.同类型算法在同等的最近邻数目下的F1-measure取值对比,如图3和图4所示.

图3 K=50时,同类型基于用户的协同过滤算法的F1-measureFig.3 When K=50, the same type of user-based collaborative filtering algorithm in F1-measure
从图3和图4可以看出,算法UWTCF,IWTCF在同类型算法中F1-measure的值均较大,即具有更好的推荐效果.

图4 K=60时,同类型基于资源的协同过滤算法的F1-measureFig.4 When K=60, the same type of item-based collaborative filtering algorithm in F1-measure
综上所述,本文所提基于标签和云模型的协同过滤算法比其他两种改进方案在一定程度上具有更好的推荐效果,通过权重因子λ加权标签信息所表示的云相似性与基于标签关联度计算的相似度更能准确挖掘相似用户或相似资源,实验表明本文所提方案在准确率(precision),召回率(recall)和F1-measure三个指标上均取得较优值,更能准确发现用户感兴趣的资源,更好地进行个性化推荐.
3 结束语
本文首先介绍了基于标签的协同过滤算法,对算法中常用的相似性度量方法进行简单介绍,提出改进的标签关联度计算方法;然后将云模型引入到基于标签的协同过滤算法中,考虑用户或资源间的标签所提供的定性信息,提出云相似性计算方法,并从基于用户和基于资源两个角度,提出基于标签和云模型的协同过滤算法.通过实验对比同类型算法并结合3种评价指标,结果表明本文提出的方案均能取得较好的推荐质量和效果.
[1]雷建云,何顺,王淑娟. 一种改进的基于用户项目喜好的相似度度量方法[J]. 中南民族大学学报(自然科学版),2015(4):94-97.
[2]Brooks B C H, Montanez N. An analysis of the effectiveness of tagging in blogs, in: Computation Approaches to Analyzing Weblogs. Papers from the 2006 AAAI[J]. Ultramicroscopy, 2012, 23(2):234.
[3]Lamere P. Social tagging and music information retrieval[J]. Journal of New Music Research, 2008, 37(2):101-114.
[4]Morrison P J. Tagging and searching: search retrieval effectiveness of folksonomies on the World Wide Web[J]. Information Processing & Management, 2008, 44(4): 1562-1579.
[5]Kim H N, Ji A T, Ha I, et al. Collaborative filtering based on collaborative tagging for enhancing the quality of recommendation[J]. Electronic Commerce Research & Applications, 2010, 9(1):73-83.
[6]Huang C L, Lin C W. Collaborative and content-based recommender system for social bookmarking Website[J]. World Academy of Science Engineering & Technology, 2010(68):748.
[7]Tso-Sutter K H L, Marinho L B, Schmidt-Thieme L. Tag-aware recommender systems by fusion of collaborative filtering algorithms[C]//ACM.Proceedings of the 2008 ACM symposium on Applied computing. New York: ACM, 2008: 1995-1999.
[8]Zhen Y, Li W J, Yeung D Y. TagiCoFi: tag informed collaborative filtering[C]// ACM.ACM Conference on Recommender Systems. New York: ACM, 2009:69-76.
[9]Zhao S, Du N, Nauerz A, et al. Improved recommendation based on collaborative tagging behaviors[C]//ACM.Proceedings of the 2008 International Conference on Intelligent User Interfaces.New York:ACM, 2008:413-416.
[10]蔡强,韩东梅,李海生,等. 基于标签和协同过滤的个性化资源推荐[J]. 计算机科学,2014,01:69-71,110.
[11]Huang C L, Yeh P H, Lin C W, et al. Utilizing user tag-based interests in recommender systems for social resource sharing websites[J]. Knowledge-Based Systems, 2014, 56(C):86-96.
[12]Larrain S, Trattner C, Parra D, et al. Good times bad times: a study on recency effects in collaborative filtering for social tagging[C]// ACM. ACM RecSys 2015. New York: ACM, 2015:269-272.
[13]李德毅, 刘常昱, 杜鹢,等. 不确定性人工智能[M].北京:国防工业出版社, 2014:123-128.
[14]李德毅, 刘常昱. 论正态云模型的普适性[J]. 中国工程科学, 2004, 6(8):28-34.
[15]Aless R B, Moschitti A, Pazienza M T. A text classifier based on linguistic processing[C]//IJCAI. International Joint Conference on Artificial Intelligence. San Francisco: Morgan Kaufmann,1999:163-168.
[16]Hao F, Zhong S. Tag recommendation based on user interest lattice matching[C]//IEEE. IEEE International Conference on Computer Science and Information Technology. Budapest: ICC,2010:276-280.
Collaborative Filtering Algorithm Based on Tag and Cloud Model
LeiJianyun1,HeShun1,LiBaiyang2
(1 College of Computer Science, South-Central University for Nationalities, Wuhan 430074, China;2 College of Software,Yunnan University,Kunming 650500)
In order to use the tag information more accurately reflect the characteristics of users and resources, the cloud model was introduced to improve the user similarity and resource similarity measurement method based on tags,and a collaborative filtering algorithm based on tag and cloud model was proposed. Experiments on the MovieLens data set showed that the improved algorithm has better recommendation effects on three evaluation metrics which are precision, recall and F1-measure, the effectiveness of the recommendation is better than traditional method.
tag; collaborative filtering; cloud model; similarity
2016-06-27
雷建云(1972-),男,博士,教授,研究方向:信息安全,数据库技术,E-mail: leijianyun@mail.scuec.edu.cn.
湖北省自然科学基金资助项目(2013CFB445);中南民族大学研究生创新基金资助项目(2016sycxjj207)
TP393
A
1672-4321(2016)03-0117-06
