一种改进的缺失数据协同过滤推荐算法*
2016-10-27周明升韩冬梅
周明升,韩冬梅
(1. 上海财经大学 信息管理与工程学院,上海 200433;2.上海外高桥保税区联合发展有限公司,上海 200131)
一种改进的缺失数据协同过滤推荐算法*
周明升1,2,韩冬梅1
(1. 上海财经大学 信息管理与工程学院,上海 200433;2.上海外高桥保税区联合发展有限公司,上海 200131)
协同过滤推荐算法是推荐系统研究的热点,近年来,在亚马逊、淘宝等商业系统中获得应用。在实际应用过程中,协同过滤推荐面临数据稀疏和准确性低的问题。作为推荐基础的用户-产品(项目)矩阵通常非常稀疏(存在大量缺失数据),从而导致推荐结果不准确。文章试图在缺失数据情况下提高协同过滤推荐的准确性,聚焦以下两个方面:(1)用户相似度、产品(项目)相似度计算;(2)缺失数据预测。首先,用增强的皮尔森相关系数算法,通过增加参数,对相似度进行修正,提高用户、产品(项目)相似度计算的准确率。接着,提出一种同时考虑了用户和产品(项目)特征的缺失数据预测算法。算法中,对用户和产品(项目)分别设置相似度阈值,只有当用户或产品(项目)相似度达到阈值时,才进行缺失数据预测。预测过程中,同时使用用户和产品(项目)相似度信息,以提高准确度。在模型基础上,用淘宝移动客户端的数据集进行了验证,实验结果表明所提算法比其他推荐算法要优异,对数据稀疏性的鲁棒性要高。
协同过滤;推荐系统;缺失数据预测;数据稀疏性
引用格式:周明升,韩冬梅. 一种改进的缺失数据协同过滤推荐算法[J].微型机与应用,2016,35(17):17-19.
0 引言
协同过滤推荐算法(Collaborative Filtering Recommendation Algorithm),通过收集相似用户或产品(项目)的评分信息来预测用户兴趣,从而进行产品(项目)的推荐。对用户或产品(项目)的相似性进行计算,通过用户-产品(项目)矩阵来预测用户偏好。根据角度不同,协同过滤推荐分为基于用户的方法和基于产品(项目)的方法。算法中,计算用户或产品(项目)之间的相似度是关键步骤,常见的相似度计算方法有:皮尔森相关系数算法(Pearson Correlation Coefficient Algorithm,PCC)[1]和空间向量相似度算法(Vector Space Similarity Algorithm,VSS)[2]。
实际应用中,因为用户-产品(项目)矩阵的稀疏性(存在大量缺失数据),造成推荐结果不准确,许多研究试图解决矩阵的数据稀疏性问题。Wang Jun等人构建了一种概率框架,通过已有数据来预测用户-产品(项目)矩阵中的值[3]。XUE G R等人提出了一种同时基于内容和建模的协同过滤框架,通过平滑算法,预测用户-产品(项目)矩阵中的缺失数据[4]。MA H等人提出综合考虑用户信息和产品(项目)信息来预测缺失数据的方法[5],对协同过滤算法进行了改进。这些方法可以取得比传统协同过滤算法更好的结果,但基于概率或聚类的平滑算法没有区分同一组内用户的差别。同时,预测用户-产品(项目)矩阵中的所有缺失数据也可能为当前用户的推荐带来负面影响。
为解决上述问题,本文采用增强的皮尔森相关系数来衡量用户间与产品(项目)间的相似性(并进行修正),综合考虑用户信息和产品(项目)信息,提出一种改进的缺失数据预测算法:当且仅当预测缺失数据会为当前用户的推荐带来积极影响时(相似度达到阀值)才进行缺失数据预测,否则不进行预测。在完成缺失数据预测后,进行协同过滤推荐。实验显示,本文所提方法比传统方法效果要好。
1 相似度计算及修正
1.1相似度计算
RESNICK P等人已经证明,基于皮尔森相关系数(PCC)的协同过滤,其效果通常比基于空间向量相似度算法(VSS)等方法要好,因为它考虑了不同用户打分标准不同的因素[1]。在基于用户的协同过滤算法[6]中,皮尔森相关系数(PCC)被用于定义有相同产品(项目)评分的不同用户a和u之间的相似度,如下:
Sim(a,u)=
(1)
其中,Sim(a,u)定义了用户a与用户u之间的相似度,产品(项目)i是用户a和用户u都评过分的产品(项目)。ra,i是用户a对产品(项目)i的评分,ra是用户a的平均评分。基于产品(项目)的方法[7]可以类似得出(本文不再赘述)。
1.2相似度修正
MCLAUGHLIN M R等人研究发现,皮尔森相关系数(PCC)有时会高估用户之间的相似性,特别是当用户正好对一些产品(项目)打分相似,而整体相似度不同时[8]。为解决这一问题,本文引入相关性权重指标,对相似度计算进行修正,如下:
(2)
式(2)在一定程度上解决了数据稀疏性问题(仅有少量产品(项目)被用户评分),但当|Ia∩Iu|远比γ大时,相似度Sim′(a,u)将大于1,为此,笔者进行了变换,改进如下:
(3)
其中,|Ia∩Iu|是用户a和用户u都评价过的产品(项目)集个数。
2 缺失数据预测
基于用户的协同过滤算法通过相似用户的评分来预测缺失数据,根据不同情况,本文的预测方法如下:
模型1:当S(u)≠φ,且S(i)≠φ时,即用户相似度和产品(项目)相似度均达到阈值(分别为η和θ)时,缺失数据预测为:
(4)
其中λ的取值范围为[0,1]。
模型2:当S(u)=φ,但S(i)≠φ时,即产品(项目)存在相似产品(项目),但用户与其他用户的相似度小于阈值η时,缺失数据预测为:
(5)
模型3:当S(u)≠φ,但S(i)=φ时,即用户存在相似用户,但产品(项目)与其他产品(项目)的相似度小于阈值θ时,缺失数据预测为:
(6)
模型4:当S(u)=φ,且S(i)=φ时,即用户与其他用户的相似度小于阈值,且产品(项目)与其他产品(项目)之间的相似度小于阈值时,缺失数据预测为:
P(ru,i)=0
(7)
3 实验分析
3.1数据集
用淘宝移动客户端的数据进行试验分析,该数据集来自阿里巴巴天池大数据研究平台,为公开数据。数据集中有超过104万条记录,来自723个用户对53 383个产品(项目)的评分。用户-产品(项目)矩阵的稀疏度为:1 048 575/(723×53 383)=2.72%。本文随机获取500个用户数据,并将其分为两部分:取300个作为训练集,剩余的200个作为测试集(实际用户集)。对不同用户集,推荐产品(项目)数分别取10个、20个和30个。
3.2比较方法
用绝对平均误差(Mean Absolute Error,MAE)作为衡量指标。MAE被定义为:
(8)
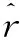
3.3实验结果
通过实验,本文改进的缺失数据协同过滤算法(IMDP)与其他推荐算法进行比较,包括:基于用户的皮尔森相关系数算法(UPCC)和基于产品(项目)的皮尔森相关系数算法(IPCC)、基于平滑和聚类的皮尔森相关系数算法(SCBPCC)[4]、相似融合算法(SF)[3]、特征模型算法(AM)[9]。
实验中,设定:用户相似性与产品相似性的权重系数λ=0.6,不同用户间同时评论的产品(项目)数参数γ=30,不同产品(项目)被同时评论的用户数参数δ=30,用户相似度阈值η=0.5,产品(项目)相似度阈值θ=0.5。
实验表明(如表1所示),本文算法综合考虑了用户相似度、产品(项目)相似度,对相似度进行了修正,设置了预测阈值,更加合理,在不同训练集、不用产品(项目)数情况下,推荐效果比其他方法要优异。本文算法在不同样本量、产品(项目)数下,MAE值均比较低,保持了较高的稳定性。
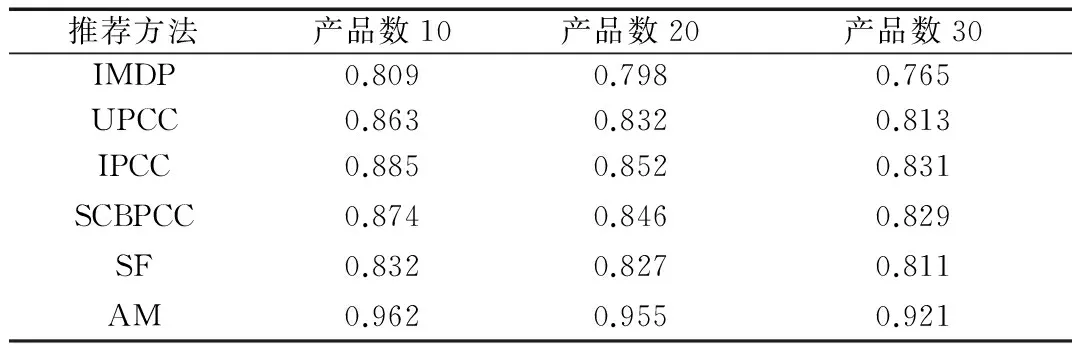
表1 本文算法与其他算法的MAE值比较
4 结论
本文提供了一种改进的缺失数据协同过滤方法。通过判断用户、产品(项目)是否有相似用户、产品(项目),决定是否预测缺失数据。如果需要预测,则同时考虑用户信息和产品(项目)信息,以提高预测准确度。用淘宝移动客户端数据进行了对比验证,实验结果显示,本文方法比其他推荐方法更加优异。
通过整合用户和产品(项目)信息,采用基于用户和产品(项目)的方法,得到了更好的预测结果。接下来,将从以下几个方面做进一步研究:(1)用户相似性和产品相似性的权重系数变化对预测结果的影响;(2)用户数、产品(项目)数参数变化对预测结果的影响;(3)用户相似度、产品(项目)相似度阈值的变化对预测结果的影响;(4)用户信息、产品(项目)信息之间关系的研究等。
[1] RESNICK P, IACOVOU N, SUCHAK M, et al. Grouplens: an open architecture for collaborative filtering of netnews[C]. Proceedings of ACM Conference on Computer Supported Cooperative Work, 1994:175-186.
[2] BREESE J S, HECKERMAN D, KADIE C. Empirical analysis of predictive algorithms for collaborative filtering[C]. In Proceedings of the 14th Conference on Uncertainty in Articifical Intelligence, 1998:43-52.
[3] Wang Jun, DEVRIES A P, REINDERS M J T. Unifying user-based and item-based collaborative filtering approaches by similarity fusion[A]. Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval[C].USA:Seatole, 2006:501-508.
[4] XUE G R, LIN C, YANG Q, et al. Scalable collaborative filtering using cluster-based smoothing[C]. Proceedings 28th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2005:114-121.
[5] Ma Hao, KING I, LYU M R. Effective missing data prediction for collaborate filtering[C]. SIGIR 2007: Proceedings of the Intermational ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam the Netherlands, 2007:39-46.
[6] 黄创光,印鉴,汪静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369-1376.
[7] 邓爱林, 朱扬勇, 施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):1621-1628.
[8] MCLAUGHLIN M R, HERLOCKER J L. A collaborative filtering algorithm and evaluation metric that accurately model the user experience[C]. International ACM SIGIR Conference on Reseach and Development in Information Retrieral. ACM, 2004:329-336.
[9] HOFMANN T, HOFMANN T. Latent semantic models for collaborative filtering[J]. ACM Transactions on Information Systems, 2004, 22(1):89-115.
An improved collaborative filtering recommendation algorithm for missing data
Zhou Mingsheng1,2,Han Dongmei1
(1. School of Information Management and Engineering, Shanghai University of Finance and Economics, Shanghai 200433, China; 2.Shanghai Waigaoqiao Free Trade Zone United Development CO., LTD., Shanghai 200131, China)
Collaborative filtering recommendation algorithm has been widely studied, and widely applied in recent years in many business systems, such as Amazon, Taobao, etc. In practice, collaborative filtering recommendation algorithm faces the problem of data sparsity and low accuracy. The user-item matrix, which is the basic of collaborative filtering, is usually very sparse (with a large number of missing data), and this leads to inaccurate results. This paper attempts to improve the accuracy of collaborative filtering recommendation from two aspects: (1) the similarity between users and items ; (2) the prediction of missing data.Firstly, we used the enhanced Pearson Correlation Algorithm to improve the accuracy of user, item similarity calculation by increasing parameters. Then we proposed a new method for predicting missing data, which is based on both the information of users and the information of items. In our algorithm, we set similarity threshold respectively for the user and the item, and only when users or items similarity meet or exceed the threshold, the missing data is predicted. In the prediction process, we used both the user and the item similarity information to improve the accuracy of the algorithm. Finally, through the experimental analysis of the data set of Taobao mobile client, we found that our algorithm is superior to other collaborative filtering algorithms, and the robustness of data sparsity is much higher.
collaborative filtering; recommender system; missing data prediction; data sparsity
国家自然科学基金资助项目(41174007);上海财经大学研究生教育创新计划项目(CXJJ-2014-440)
TP391
ADOI: 10.19358/j.issn.1674- 7720.2016.17.005
2016-05-03)
周明升(1981-),通信作者,男,博士研究生,主要研究方向:决策支持、智慧城市。E-mail:simonzhou3000@163.com。
韩冬梅(1961-),女,博士后出站,教授,博导,主要研究方向:决策支持,经济分析与预测。
