云计算技术下的大数据用户行为引擎设计研究
2016-10-25张梅
张 梅
(阳泉高等师范专科学校 信息技术系,山西 阳泉 045000)
云计算技术下的大数据用户行为引擎设计研究
张梅
(阳泉高等师范专科学校 信息技术系,山西 阳泉 045000)
对云计算技术下的大数据用户行为引擎设计进行深入分析,涵盖了大数据系统管理、多用户流量设计等多个方面,并探究其系统测试的效果.
云计算;大数据;用户行为;引擎设计;计算机信息技术
近年来,我国的移动互联网技术得到了充分的发展,这使我国的互联网运营商面临着一个新的发展机遇,开始走向话务量经营向流量经营的道路,并对用户的行为规律进行深入分析,发掘市场与广大用户的真实需求.为了能够充分满足用户日新月异的需求变化,运营商必须不断开发、推出新产品,加强计算机技术的功能发挥.而云计算技术正是这样一种能够满足海量数据分析与处理的强大引擎系统.
1 云计算及用户行为分析技术概述
用户行为分析则是指通过某种途径对用户访问量情况进行挖掘,然后再对这些访问的数据进行有效的统计分析,以便获取用户访问的基本规律,然后对企业的网络营销策略进行相应的调整,以便与用户的网站访问规律相一致,使网络营销策略更加科学、有效.一般情况下,运营商只需通过对用户的行为监测,便可获得有效的动态数据,并对这些数据加以分析,掌握用户的心理与思考方式,判断客户的真正需求,然后将这些分析成果呈现给企业,为企业营销策略的制定与调整提供一个参考与借鉴,及时发现企业营销中存在的问题,进行适时的改进.尤其是在电商领域中,用户行为信息量之大令人难以想象,据有关资料显示,一个用户在选择一个产品之前,平均要浏览5个网站、36个页面,在社会化媒体和搜索引擎上的交互行为也多达数十次.如果把所有可以采集的数据整合并进行衍生,一个用户的购买可能会受数千个行为维度的影响.对于一个一天PU近百万的中型电商来说,这代表着一天近1TB的活跃数据.而放到整个中国电商的角度来看,更意味着每天高达数千TB的活跃数据.因此,可以说这种用户行为分析,实际上为企业的经营与发展指明了一个方向,能够在一定程度上提升企业的营销效率,增强企业竞争力[1].
2 云计算系统总体设计方案研究
2.1云计算系统的总体构架
在本次研究中,主要是利用云计算技术的海量数据计算能力,建立完善的移动互联网数据挖掘分析系统,实现对互联网用户行为引擎的分析,并根据用户的上网习惯与行为偏好,为用户提供具有针对性的个性化服务,使数据的采集、分析与服务类型、营销策略能够形成一个统一的有机整体,提升企业的营销效率.另外,云计算系统主要是借助FTP服务器来实现对数据的采集,然后在系统的接口处对数据进行分布式计算以及批量处理,并将这些大数据一并存入Hbase数据库,该系统不仅能够实现海量数据存储,而且对于那些非结构化的数据也能够存储[2].然后再经过Hive整合层与汇总层EIL处理,利用MapReduce数据分析模型,将处理的结果传入数据库,其系统总体构架见图1.
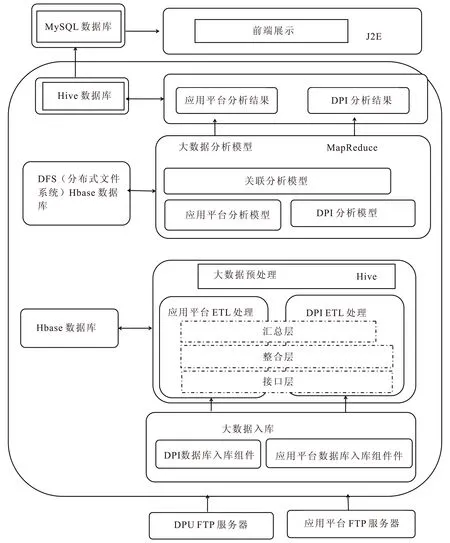
图1 云计算系统的总体构架
2.2系统拓扑与功能分布

图2 主节点服务器功能构架
系统的拓扑主要是指将一台服务器作为Hapdoop平台的主节点服务器,其他都作为Hapdoop平台的从节点服务器.一般情况下,从节点服务器可以根据实际需要进行动态扩展,而主节点服务器不仅要将任务与流量分配给从节点服务器,而且还要监督从节点服务器的工作执行情况,由多台从节点服务器共同参与完成任务,能够提升数据处理效率,主节点服务器的软件运行情况如图2所示.
2.2.1任务管理与调度
主要是用来控制任务调度,不仅能够提供任务创建功能,而且还具备任务的调整与删除功能,只要对业务的类型进行选择,设置科学的执行周期,对处理的逻辑进行相应的定义,对数据的抽取、整理与运行等各个项目进行有效的控制[3],便能够实现数据的自动化处理,另外还提供暂停、恢复等个性化的管理功能.
2.2.2大数据的入库与预处理
这一系统主要是对DPI用户的上网情况以及应用平台中有关用户行为信息数据的处理,它能够将这些数据传入系统的用户行为分析引擎,为数据的分析与模型挖掘提供一个数据参考与依据.
2.2.3大数据用户的行为分析
将所有汇聚到系统的移动互联网用户行为数据进行分析,主要借助了MapReduce用户行为分析模型资源,能够对用户的上网习惯、偏好,甚至包括用户的社会关系进行有效的分析,并提供全面的业务服务,给用户推荐具体的内容.一般来说,从节点服务器与主节点服务器在软件的结构上没有太大的差异,唯一不同的是从节点服务器不具备部署任务以及管理调度的功能[4].以搜狗公司数据分析为例,根据第三方互联网数据统计机构CNZZ公布的2015年9月的中国网民搜索引擎使用情况统计报告,搜狗搜索的市场份额已经达到15.68%,成为中国第三大互联网搜索公司,其用户行为数据分析格式如表1所示.

表1 云计算技术下的数据格式
3 大数据入库组件的基本设计
通常,对移动互联网用户的行为分析引擎的数据主要是通过应用平台数据与DPI数据两个渠道获取的,这两个数据源有着明显的不同.首先,应用平台数据比较集中,在一个访问行为表中就能够完整的呈现,每天表现为一个文件,且文件的大小以GB分级;DPI数据则是众多分散的小文件,这些文件一般都不超过10 MB,其最重要的一个特点就是文件的来源特别快,平均每2 min就能够接收到多个新文件,1个省1天可收集到1 TB左右的数据量,效率极高.针对这两种数据源的特点,分别采取了不同的设计方案.在获得用户访问基本数据信息的情况下,对这些数据进行统计分析,能够从中获取用户行为的基本特征与规律.采用Hadoop平台的用户行为分析系统对搜狗实验室提供的搜索引擎日志数据集进行分析处理,源文件大小共4.4 GB,行数为43 545 444行.用户查询关键词的排名、点击URL排名以及用户搜索记录、时间段等用户行为特征都能够有效的呈现出来,详见表2.

表2 各个用户行为特征的运行情况
3.1应用平台数据入库
该平台主要采用的是批量入库的方式,每天进行一次数据入库,文件的大小一般为GB级.通常对于大型数据文件多采用Hadoop平台进行入库,然而经过实践证明,MapReduce分布式处理Hbase入库效率普遍不高.因此,可对这一系统进行优化处理,在MapReduce分布处理的基础上,进而实行批量入库处理.在Hadoop系统应用过程中,多使用TextInputFormat,其在map中多显示的是文件的单行记录[5].因此,可采用NLineInputFormat类使其能够在MapREduce中实现批量入库,在这种系统的支持下,每个分片都会留下N行记录,然后通过适当的参数配置,实现每次可读取N行记录,进而在map中行批量入库的相关操作,能够在一定程度上提升数据分析的效率.
3.2DPI数据入库设计
DPI数据入库主要针对的是大量的小型数据文件,这些文件尽管所含数据量不大,但是数据来源的频率特别高,对这些文件的处理通常采用以下方式.首先,可采用SequenceFiles软件将这些小文件进行压缩打包,在文件打包的初期就要采取措施降低小文件的数量.然而,对其读取却会受到一定的限制,无论是Hadoop shell软件还是Map读取软件,都很难实现对数据的灵活读取.而采用HAR软件对小文件进行归档,这尽管能够在一定程度上减少小文件的数量,却仍然达不到数据的灵活读取,这很大程度上是由于HAP软件的读取性能较低.另外Hadoop append系统尽管能够将这些小文件追加到同一个文件中,然而,这些小文件的大小千差万别,且数据来源频率广,有峰值与低谷之分,因此对这些数据的控制也较为繁琐.除此之外还有Flume、FLumeNG以及Scribbe系统,这些系统能够对中间层的数据进行处理,有效降低小文件的数量,然而这两者传输与压缩文件功能不强,具有一定的缺陷.由此可见,以上这4种方式都不能实现数据文件的有效处理,因此,要对DPI数据的特征进行科学分析,对CombineFile InputFornt进行有效继承,将数据的分片大小进行设置,以便实现CreateRecordReader,这种方式也能够促进DPI大数据实现入库[6].
4 大数据用户行为引擎组件设计

图3 大数据用户行为分析模型组件
对大数据用户行为的分析主要是通过Hadoop平台来实现的,它具有多种功能结构与部件,各个组件的关系见图3.首先,模型参数调整主要是完成对模型算法的变量设定,根据实际情况实现参数调整、样本空间规模设置等;模型评估系统主要是对所创建的模型进行校验,将通过模型所计算的结果与实际得出的数据进行比较,然后将校验的指标进行输出,并作出与模型相关的评价;多业务数据关联模型则是通过用户的互联网行为以及游戏业务平台的行为,对这两者进行有效分析,并对DPI用户的互联网行为偏好的关联性进行分析,从中发现用户互联网行为的规律,将这些规律录入系统,促进企业的营销的实现;个性化推荐则是利用计算机的过滤技术对有效的信息进行提取,并对产品的内容以及客户的行为进行综合分析,为用户提供个性化的推荐服务;另外,还能够通过DPI访问偏好的测定,对用户互联网行为进行分类,对用户的访问网页类型进行分析,从而获取用户的行为规律与偏好.社交关系挖掘这一模型不仅包含了用户的社交图谱,而且还拥有用户的兴趣图谱,这主要是通过用户的位置变化来确定的,通过对用户的定位分析,可以了解用户的社交场所与关系网,而兴趣图谱则能够在一定程度上使用户之间建立起共同的兴趣爱好联系.这些模型的构建都对MapReduce有着不同程度的应用,且在使用过程中,主要是通过map以及reduce这两种函数来实现的.首先由map完成对数据的输入与计算,然后以
5 结语
移动互联网大数据时代的到来,使企业的运行商面临着极大的挑战,本次研究对大数据背景下用户行为分析引擎提出了设计方案,有利于实现供应商新业务的开发.它能够对用户形成高效的跟踪,且运行成本低廉,在企业的营销中有着极大的应用价值,值得推广应用.
[1]陶彩霞,谢晓军,陈康,等.基于云计算的移动互联网大数据用户行为分析引擎设计[J].电信科学,2013(3):27-31.
[2]刘路.基于云计算的移动互联网大数据用户行为分析引擎设计[J].电子制作,2014(4):174-175.
[3]谢晓頔.大数据环境下云计算分布式数据管理和分析技术工具的研究[J].科技风,2015(19):51-51.
[4]李晓飞.基于云计算技术的大数据处理系统的研究[J].长春工程学院学报(自然科学版),2014,15(1):46-50.
[5]王宁,杨扬,孟坤,等.云计算环境下基于用户体验的成本最优存储策略研究[J].电子学报,2014,42(1):20-27.
[6]李进生,杨东陵.云计算环境下大型电气数据库存储性能分析与优化[J].电气应用,2015(6):76-79.
[7]尹天骄.云计算时代下的数据管理技术探讨[J].计算机光盘软件与应用,2015(3):179-180.
[8]潘梦云,李国玉,李燕.基于Hadoop云计算平台的数据处理系统的研究与设计[J].通讯世界,2015(14):224-225.
[责任编辑王新奇]
Research on the Design of Engine for Behavior of Large Data Userunder the Cloud Computing Technology
ZHANG Mei
(Department of Information Technology, Yangquan Teachers College, Yangquan 045000, China)
In this paper, In-depth analysis on the design of engine for behavior of large data user under the cloud computing technology is conducted. It covers many aspects such as the management of large data system and the design of traffic flow for multiple users, and explores the test results of its system.
cloud computing; large data; user’s behavior; design of engine; computer information technology
1008-5564(2016)03-0048-05
2015-11-16
张梅(1982—),女,山西阳泉人,阳泉高等师范专科学校信息技术系助教,主要从事云计算研究.
TP274
A
