基于主题模型的短文本分类研究
2016-10-21王海林张雅君
王海林,张雅君
(山西财经大学 信息管理学院,太原 030006)
基于主题模型的短文本分类研究
王海林,张雅君
(山西财经大学信息管理学院,太原030006)
分本分类作为文本挖掘的分支,得到了广泛的关注和迅速的发展。基于主题模型,针对短文本分类进行研究,选取LDA和BTM主题模型和SVM、Bagging和AdaBoost分类方法进行短文本分类实验,并对实验结果进行评价。
主题模型;短文本分类;LDA;BTM
1 引言
随着信息技术的快速发展和网络的广泛使用,互联网中产生的信息显著增加。大量非结构化数据已经成为网络数据的主力军,可以占到总数据量的90%[1],短文本更是在社交网站中随处可见。主题模型作为特征选择的一种方法,常用于文本分类中。使用不同的分类方法,对比LDA和BTM模型对于短文本特征选择的效果。
2 主题模型
2.1主题模型思想
主题模型是一种层次结构的模型,用概率来表示各层之间的关系,常见的有 PLSA[2]、LDA[3]和 BTM[4]等,PLSA即潜在语义分析,是最早的主题模型,它使用条件概率描述单词和潜在类别间的关系,并使用最大期望的方法训练潜在类别。
2.2 LDA模型
由于PLSA模型的不完备和容易出现过拟合等缺陷[4],Blei等人提出了LDA模型,用概率来表示文档集合层、文档层和词语层之间的关系。
在LDA模型中:
(1)每篇文档主题词的个数N~Possion(ξ);
(2)文档中先验概率θ~Dir(α);
(3)每篇文档的第n个主题词wn:
主题Zn~Multinomial(θ);
主题词wn~Multinomial(wn|Zn,β)。
所以,LDA模型可以表示为:
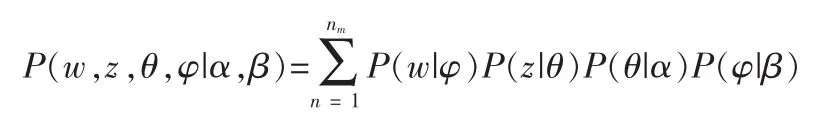
其中P(φ|β),代表主题概率,P(w|φ)P(z|θ)代表主题词概率,P(w|φ)P(z|θ)P(θ|φ)代表文档概率。
参数估计:
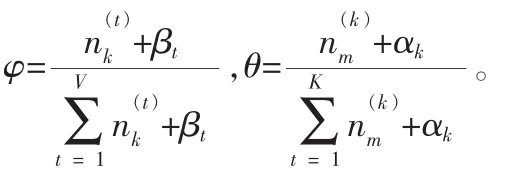
2.3 BTM模型
BTM是另一种三层贝叶斯结构模型,与LDA不同的是它用“词对”来代替词,从而克服了短文本中词少所带来的困难。BTM和LDA均使用Gibbs抽样方法进行参数估计。LDA的Gibbs updating rules为:
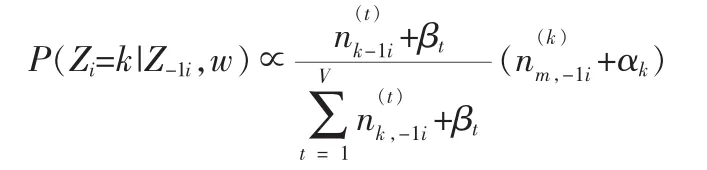
BTM的Gibbs updating rules为:

BTM模型参数估计:
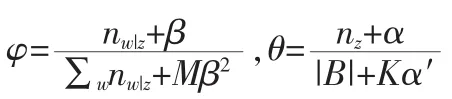
3 实验数据及评价
3.1实验数据及预处理
实验数据集来源于SODA上海开放数据创新应用大赛公开数据,数据集名称为网格化管理数据,该数据集用来统计城市居民对于市容市貌现象的反映,其中描述这个属性是对反映内容的简单叙述,平均字数少于100,类别是指反映现象所属类别。经过对数据的筛选,最终有988条数据,类别为暴露垃圾、跨门营业和占道无证经营。
3.2实验环境
分词处理:中科院中文分词系统ICTCLAS;
主题模型:Windows下的 JGibbs和 Ubuntu下的 BTM-master;
文本分类:Weka中的libsvm、Bagging和AdaBoost方法。
3.3实验及结果评价
选取 LDA和 BTM为主题模型,使用 libsvm、Bagging和 AdaBoost分类方法,将它们两两组合,同样的分类方法设置相同的参数,最终进行6次实验,并对实验结果进行评价。
以精确度 (Precision rate)、召回率 (Recall)和F值 (F-measure)为评价指标,BTM+libsvm最高,均为 0.967,LDA+ AdaBoost最低,分别为0.804、0.811和0.795。因此,对于短文本,BTM比LDA有更强的适用性,而对于分类,SVM更适合处理高维数据。
4 总结
从实验结果可以看出,对于短文本的分类,使用BTM作为主题模型,SVM作为分类方法,得到的效果最佳。当然,由于数据集的局限性,实验结果具有一定的片面性,未来的工作可以进一步选取多个实验数据集,以得到更普遍的结论。
主要参考文献
[1]Limeng Cui,Fan Meng,Yong Shi,etal.A Hierarchy Method Based on LDA and SVM for News Classification[C]//Proceedings of the 2014 IEEE International Conference on Data MiningWorkshop,2014:60-64.
[2]THofmann.Probabilistic L atent S emantic I ndexing[C]//Annual International SIGIRConference,1999.
[3]Blei D,Ng A,Jordan M.Latent Dirichlet Allocation[J].Journal of Machine Learning Research.2003(3):993-1022.
[4]董文.基于LDA和Word2Vec的推荐算法研究[D].北京:北京邮电大学,2015.
10.3969/j.issn.1673-0194.2016.19.098
TP311
A
1673-0194(2016)19-0174-02
2016-08-25
王海林(1962-),男,山西大同人,山西财经大学副教授,硕士研究生导师,主要研究方向:数据建模、大数据、分布式系统、数据可视化。
