一种基于网络学习行为的学习偏好分析与实现
2016-10-18曹雨翱袁新瑞
曹雨翱,袁新瑞,高 岭
(西北大学 现代教育技术中心,陕西西安710069)
一种基于网络学习行为的学习偏好分析与实现
曹雨翱,袁新瑞,高岭
(西北大学 现代教育技术中心,陕西西安710069)
学习偏好分析是个性化教学服务的基本功能要求,可选取学习者所访问的URL、访问量、访问频率、访问时间、访问内容类别、引用页等六个网络学习行为指标,来分析学习者的学习偏好。通过对学习者访问的URL和访问量两种数据的获取、分析和偏好分析实验验证,有效给出了学习者的学习偏好。
学习偏好;教学服务;学习行为分析
一、引言
“互联网+”时代下,在线学习成为一种具有发展前景的学习模式。据企鹅智酷和腾讯课堂在2015年7月联合发布的第32期《在线教育报告》显示:2014年国内共有167家在线教育创业公司获得投资,是前一年的2.6倍,预计到2017年中国的在线教育用户预计将突破1.2亿[1]。学校学习中,基于SPOC的混合式学习也成为高校普遍重视的学习模式。但是,无论是学校还是社会上的在线学习环境,都需要将提供个性化的学习服务作为最基本的功能。因此,如何获知学习者的学习需求和偏好,就成为一个值得研究的重要课题。
基于用户网络行为的用户偏好分析,给学习需求和偏好分析带来启示。MovieLens站点使用“协同过滤”技术,推荐用户可能欣赏的电影并帮助他们避开不喜欢的影视作品,该站点也会根据用户的收视率对没有浏览的影片生成个性化预测[2]。宋姜等人在研究网络社交偏好影响因素时,通过在线试卷调查,结构方程分析方法,得出:不擅长面对面交流的人跟倾向于网络社交手段,周围人群的社交普及率越高,人们自身约会倾向于社交网络等[3]。那么,如何通过网络学习行为分析用户的学习偏好呢。这需要从学习行为指标选取、数据获取、偏好分析三个环节开展研究,探索和实现行之有效的学习偏好分析方法并给出偏好表示,支撑进一步的学习内容推送服务。
二、学习偏好分析的行为指标选取
彭文辉在研究学习行为时利用系统科学对复杂事物的描述方法和学习的分层特性,对这种连贯的交互行为分类表示,提出了基于学习行为的OCCP层次化模型[4],如图1所示。在这个模型中,学习行为被高阶问题解决行为层和低阶操作圈定,中间又分为两层,由下到上分别是认知行为层和协作行为层,具体的讲,低阶的操作层指学习者接触信息时的听、说、读等动作,认知行为层指对知识内容的分析,差别等,协作行为层强调认知个体与他人的交流活动,如提问,答疑等,最高的问题解决行为层指运用知识,即对各种学问的综合提炼,自我设计等。
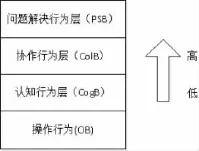
图1 基于学习行为的OCCP层次化模型
以上学习行为在网络学习中可演变为相应的网络操作行为指标,具体有:学习者访问的URL、访问量、访问频率、访问时间、访问的内容类别和引用页。
1.访问的网址类别特点
URL,称作统一资源定位符,线上学习的每种资源都有且仅有一个这样的标识符,由数字、字母和特殊字符构成,当用户访问网络资源时,服务器端会记录此用户的URL请求,它表明了用户的访问路径。URL能将各类网络内容表现成不同组合字段的形式,根据后台数据库和网站结构的差异,不同类别的网址表示的含义不同,为了将字符形式的URL与站点内容相联系,需要对站点进行编目。以西北大学教育资源云平台为例,7种类别资源的URL只有在末尾的catagoryID参数部分不同,其余字段均相同,编目如表1所示。既然URL对于资源来说代表了一种路径,那么当用户进行网络学习时,连贯的访问动作也可以反映在URL中,所以定义服务器端记录的URL为用户请求网络资源的路径指标。
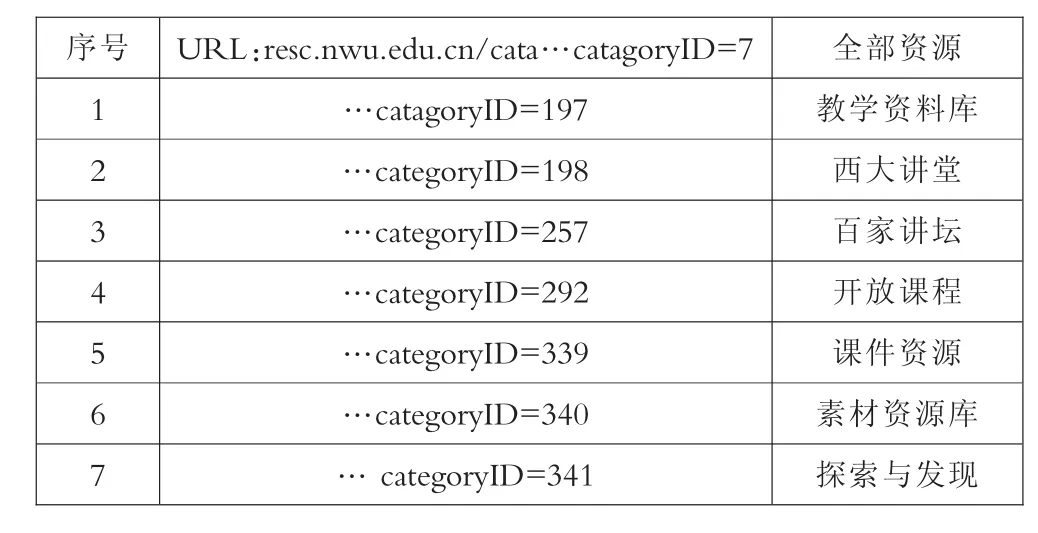
表1 编目
2.访问量
资源被访问的次数与用户的偏好成正比关系,对单一用户而言,某一方面资源访问量多是用户对这一方面知识感兴趣的必要非充分条件,所以定义访问量为用户浏览资源次数指标。
3.频率
称作某一时间内完成操作的次数,其作为一个比值,是描述客观物体周期性变化的频繁程度,稠密的网络资源给用户带来的益处就是获取内容的丰富,在图书馆,受喜好程度较高的书籍往往纸张皱褶,发软,等价到网络学习中,当用户对某一类资源的兴趣高于其他时,这些资源的访问度就高,若以用户从上线到下线为时间区,定义网络资源的被访问率指标,即为用户的访问频率。
4.时间
网络学习区别于线下学习的时间特征为分散性和短时性,当用户的行为不受固定时间约束时,他们学习所产生的时间则更倾向于真实需要的表述。用时间记录用户学习状态同样需根据不同资源内容来进行划分,若将总时长看作一个饼状结构,那么单一用户操作各类网络资源的时间则是形成完整“饼”的细分时间片,由此,时间片的长度受用户兴趣影响长短不一,所以定义用户操作资源的时长为分析他们兴趣偏好的时间指标。
5.内容类别
信息分类已经不是一个新概念,但是这种方式的益处却尤为明显,体现在网络化教学中也是个性化教育的一部分。学习来源于需要,不同学习目标的习得方式不一定相同,所需内容的呈现形式也不尽相同,得易于现有技术手段和资源的丰富,许多学科都有如文字,图片,视频等资料,当学习者参与到网络学习中,这些资料便被他们获取,而留在服务器中的行为记录则记录下了用户使用资源的类型,因此定义内容类别为用户线上学习的资源类型偏好指标。
6.引用页
网站的结构呈网状,即用户从一个页面到另一个页面的路径不止存在一种,站点越庞大,页面与页面的关联关系越复杂,如果以用户的点击动作为计量点,那么页面内容的更替则代表了当前点击动作结束后,下一跳的结果,如此“周而复始”的变化就是通过当前页与来源页的迭代,所以定义引用页为当前用户上一次访问的跳转指标。
三、基于字符串的指标获取与行为建模
为了验证这种分析方法的有效性,我们选取两个指标来实现学习偏好分析的过程,主要针对URL、访问量。
1.指标获取方法
用户的学习行为数据有两种存储类型,分别是文存储件形式和结构数据库存储形式,后者的数据提取不用划分,因为数据库已经对各类将要转入的信息进行了分类,当用户操作网络资源时,相关的动作就已经被有序地记录下来,而前者地记录是一个文本文件的形式,我们需要的内容是这个文本文件中的某些片段,为了达到这个目的,首先需要对用户的日志文件进行读取,然后将每一条记录分解成一个字符串,再提取字符串中有意义的数据源,最后把提取出来的数据以二维表的形式存储到数据库中,循环提取的过程,直到文件末尾。
用PHP语言描述如下,首先利用file()函数将用户行为日志文件读取到一个数组中,由于日志文件行的划分是固定的,即当文件记录了末尾字段的信息后会在日志中自动换行,再做记录,而用file()函数的益处在于它接收值后以数组形式返回并且数组中的每一个元素对应日志文件的每一行,如果我们定义一个数组变量filearray接收file()的返回值,那么filearray中的每一个数组值即为用户日志文件中的每一条记录,把存储在filearray数组里的值循环输出即可在浏览器里查看到所有记录。
以Apache的通用日志格式为例,用户请求获取资源的时间存储于一组中括号中,请求的URL存在于第一个“”中,且有些URL还包含请求的资源类型,引用页存在于第二个“”中,这些数据是用户偏好指标的源数据,所以有价值,但是这类源数据被不同的特殊字符划分,给提取造成了困难,使得用字符串函数匹配变得繁琐,然而也正是因为有特殊字符的标示作用,另一种模式匹配方法,正则表达式才能发挥更大的作用。IIS日志格式同理,但由于日志中特殊字符少,提取相对简单。
正则表达式作为一种复杂模式的匹配方法,以参数的形式可见于相应计算函数中。介于我们要提取的源数据是日志信息中的多个字段值,所以要对它进行多次匹配,preg_match_all()正则表达式全局匹配函数可以解决这个问题,如果不需要全局匹配,可以用preg_match()函数。具体如下描述,假定一条日志数据由$str接收,则匹配URL,引用页的写法是preg_match_all(‘/”(.+?)”/’,$str,$m),匹配时间的写法是preg_match(‘/[(.+)]/’,$str,$n),输出URL,引用页,时间的写法分别是,echo$m[1][0],echo$m[1][1],echo$n[0],以上代码均验证通过。
2.行为建模
由URL,访问量、频率、时间、内容类别、引用页表示的用户偏好源数据以二维表的形式存储在结构数据库中,这些数据表征了不同的用户行为,本身就具有一定的数据结构,利用这些结构进行挖掘,就可以将学习行为这类复杂的动作量化表达,下面取URL,访问量两种源数据并对这两个指标建模。
(1)URL
一般来说,用户找到自己想要的文件需要进行多次单击操作,日志服务器能记录用户请求文件的URL,以西北大学教育资源云平台为例,如果一个用户依次点击了首页,百家讲坛,大观园里论诗才,则Web日志中会记录三个URL,如图2所示。

图2 Web日志中记录的三个URL
依据URL的唯一性,若将每个地址看做一个点,那么用户在某一个时段的访问行为就是一个关于这些点的集合。既然这些点表现了用户访问的页面或文件,那么在实际中,点与点之间必定存在一个方向,即用户的访问顺序。若将这些点分散在一个二位平面里,模拟一种情况,假设有五条URL,它们所代表页面的访问顺序如图3所示。
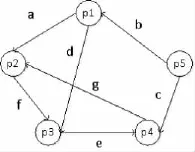
图3 页面的访问顺序
图中的a至g代表页面的访问权值,如果一个页面被多次访问,那么对于当前用户,此页面也具备较高的权值,页面内提供的信息也可能是用户学习最为需要和关心的内容。
将URL建模后,我们发现它的图形结构与数据结构中的图十分相似,而在数据结构中有一种称为邻接矩阵的方法用于图的存储和表示,且这种方法便于计算,尤其是判定图中任意两个顶点之间是否有边相连以及各个顶点的度,但是这种方法不适合对稀疏图进行存储,会浪费大量的空间,介于此,为了节省空间,我们希望使用一种只存有关联信息,而不保留不相邻接的点信息的构造,而图的邻接表表示法刚好可以解决这个问题。
(2)访问量
将资源看做目标对象,可知存储在网络上的各种资源有不同的分类标准和递进关系,但从本质结构上说,资源都是离散型数据,而且这种数据在分类上呈现树形结构。树形结构是一种非线性逻辑结构,这种结构中节点间后继的关系并不有唯一性,直观地看,树结构是指具有分支关系的结构,其分叉、分层的特征类似于自然界中的数。实际中,大多数学习类网站的资源分类呈现树形结构的森林状态,也就是说从顶级分类开始,资源呈现出一个由若干棵树构成的集合状态,但是这种资源由于子结点的多样性给存储和计算带来了困难,所以在数据处理前要对森林结构的资源进行优化。
因为任何树都可以转化为二叉树进行处理,因此二叉树作为一种简单而特殊的数可以对森林结构进行替换,在表示时,我们使用孩子兄弟法,即以二叉链表作为数的存储结构,链表中的每个结点设有两个域,分别指向该结点的第一个孩子结点和下一个兄弟结点。
若将用户与资源分别看做列标头与横表头,可以构造一个用户—资源访问表,表中的数据为每个用户对每种资源访问的次数,如表2所示。

表2 用户—资源访问表
表中A1,A2,A3…,B1,B2,B3…是将资源从森林状整理为二叉树后的先序遍历顺序,不用中序遍历和后续遍历是因为在我们对资源分类进行树形建模时,将父结点的优先级看做大于子结点的优先级,同级子结点的优先级相同,在这种前提下,先序遍历的生成的资源访问顺序符合结点间的优先级大小。
表中A,B,C…表示不同类型的资源,在表2中只作为逻辑展示,没有实际意义。
表中数据代表每位用户访问各种资源的次数,其数学建模方法如下:
若记访问频率的均值为X,每种学习资源为An1Bn2Cn3…Mnj,每个用户为Ui,则方差D(X)可以描述为用户对某一资源Ai访问频率波动的大小,公式为,其中为每种学习资源或 An1或Bn2…Mnj在Ui个用户访问下的平均访问量,公式为。方差的优势在于将数值中的波动扩大了,方差越大表明离散程度越大,方差越小表明离散程度越小。
四、数据分析
1.URL数据
Web日志数据来源于西北大学教育资源云平台我们使用的是IIS7.0日志服务器。
下面要对日志进行预处理,剔除如json传值,图片缓存等与用户学习偏好联系不大的请求,突出价值数据。为了方便描述,只取用户**.110.232进行说明,对预处理后的日志编目说明如图4所示。

图4 预处理后的日志编目说明
用户**.110.232的访问日志在进行预处理后,得到了20个关键页,这些页面分别代表了首页,视屏播放页,图片资源页以及压缩包资源页,将这些页面元素按照用户访问的顺序表示后如图5所示。
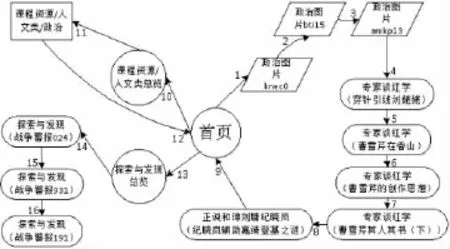
图5 页面元素按照用户访问的顺序表示
按照URL的建模方法,取相似资源访问次数为弧节点的数据域,建立用户学习偏好邻接矩阵如图6所示。

图6 用户学习偏好邻接矩阵
从邻接表的数据域可以得出以下结论:
(1)**.110.232用户更喜好百家讲坛的内容,而且是关于“红学”方面,其次是探索发现关于战争的内容,然后是政治方面的图片素材。
(2)**.110.232用户更喜好视频类资源,接下来是图片。需要说明的是,以上数据分析建立在用户某一个时段内,且当某资源页仅被用户打开一次时,这次动作由于次数低不作计量。
2.访问量
未使用教育资源云平台中数据是因为该平台正在做升级,用户量较少,不适合做多用户分析,而用户访问量可用随机模拟数据代替,下面是分析过程。为了方便描述与统计,将表2拆分,资源分类里只保留A类并将其分为5种资源,用户选取3个。若从资源角度出发,可以将用户的访问动作看成是随机事件,所以我们利用随机函数为每位用户生成他们的访问次数,并在随机函数的参数设定中选取1到10,建表3如下。

表3 模拟访问数据表
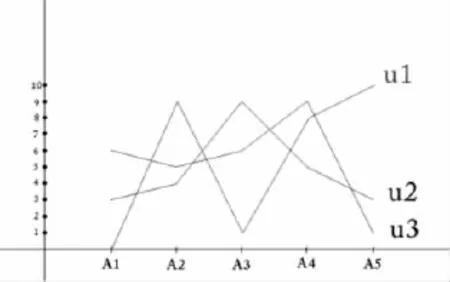
图7 三个用户的资源访问情况可视化
由图7可知u2用户的访问曲线起伏最小,峰值与谷值之差为4,u1用户的访问曲线起伏最大,峰值与谷值之差为10,u2居中,其峰值与谷值之差为8。用户u2在对A类资源访问时,他的学习行为更倾向于较为平均的访问状态,也就是说用户u2对A类资源中每个资源的偏好程度相差不大,若定义学习偏移量L_sft(X)为一个用户访问资源的方差D(X),根据D(u2)<D(u3)<D (u1),可以得到L_sft(u2)<L_sft(u3)<L_sft(u1),话句话说,用户u1表现出来对A类资源中某一个资源更强的偏好程度,相对与同类中的其他资源,这类被访问次数较高的资源对于用户u1更具有吸引力。
五、小结
本文就互联网学习,基于行为科学,学习理论和前人对网络学习行为分类的研究成果,选取了分析用户网络学习的行为指标。再者,通过字符串模式匹配方法说明了行为指标的获取途径,并对两类行为数据建模供以后文分析。最后的实验部分从用户访问的URL数据和资源访问量数据验证了用户偏好与行为之间的关系,结果表明该分析方法行之有效。介于实验部分的分析存在模拟数据,进一步的研究可以将此替换为真实数据,用作具体案例分析。
[1]企鹅智酷,腾讯课堂.在线教育报告第32期[EB/OL]. http://edu.qq.com/a/20150706/019734.htm#p=1.[2015-07-06].
[2]GroupLensResearch.www.movielens.org.
[3]宋姜,甘利人,吴鹏.网络社交偏好影响因素研究[J].情报杂志,2014,1(33).
[4]彭文辉.网络学习行为分类模型及概念模型[M].北京:科学出版社,2013.
(编辑:杨馥红)
G434
A
1673-8454(2016)09-0015-05
