基于Spark的线性模型在广告投放系统中的应用研究
2016-10-17林穗,赵菲
林 穗, 赵 菲
(广东工业大学 计算机学院,广东 广州 510006)
基于Spark的线性模型在广告投放系统中的应用研究
林穗, 赵菲
(广东工业大学 计算机学院,广东 广州 510006)
针对在线广告投放中对实时性和高精确度的要求,对比了Hadoop和Spark两种主流平台在实现流程及效率方面的差异,提出了将线性模型结合Spark技术应用在广告投放系统中,并从数值特征、迭代和步长等方面对模型进行优化.经测试表明,调优后的精确度有5%至10%的提升.
Spark; 实时计算; 在线广告; 线性模型
互联网的发展及电子商务的兴起给越来越多的人带来巨大的商业价值,其中网络营销已经成为一种重要的推广品牌的手段.而在线广告便是一种网络营销的形式.通过用户对推送广告的点击来预测用户对其他广告点击的概率,投放被点击概率较大的广告,从而进行更好的营销推广.Google等大型互联网搜索引擎与Yahoo!的专门广告分析系统,通过对广告相关数据的批量处理用来改善广告的投放效果,以提高用户的点击量[1].通常用户的点击行为会被记录在日志文件中,随着数据量的指数级增长,需要用到大数据技术处理.目前,最流行的大数据技术是Apache的开源项目——Hadoop分布式存储计算框架.Hadoop适合对数据进行批量处理,先将数据存储至HDFS[2],然后再对存储的数据用Mapreduce编程模型进行集中计算,可以应用到日志分析、建立索引、词频统计、文档聚类等方面[3].这些都是对历史数据进行集中处理,但是在对待实时数据方面,在一些需要低延迟高响应的业务需求中,Hadoop难以实现.由此,Spark产生.Spark诞生于加州大学伯克利分校,是Apache旗下的开源项目[4].Spark力图打造全栈范式的高效数据流水线.目前已包括核心组件RDD,Spark Sql,Spark Streaming,Mllib和Graphx等程序包组件[5].传统的批量计算,通常是先将数据统一收集,存储在硬盘或者关系型数据库,当计算的时候,从文件或者数据库中加载数据,在内存中完成计算.而实时计算情况下,数据不需要存储,而是以流的形式存在,直接在内存中完成计算.Spark正是这种实现了流数据计算处理的技术.
1 基于Hadoop的广告投放
在线广告投放中的广告形态多样化,比较常见的形式包含以搜索引擎为基础的搜索广告和网页内容为基础的上下文广告.通常以浏览用户的行为特征为中心的行为定向等技术进行精准投放.精准与否在于计算广告的技术能否达到最优.Andrei Broder在2008年指出,计算广告是综合了大规模搜索、文本分析、最优化、统计模型、推荐系统等多个方向的交叉新兴学科,其核心挑战是解决用户、上下文与广告的最佳匹配的问题[6].本小节将详细介绍如何利用Hadoop技术针对用户的行为历史预测用户的兴趣和点击行为,从而进行广告计算.
通常广告日志的格式是由用户的ID,被点击广告的ID,被点击广告的标题,广告关键字、当前时间、IP地址、设备类型等一些特征组成.一条广告的关注度可用式(1)计算得到.
W=K×Log(N/T),
(1)
其中,W表示某条广告被关注的关注度,K表示某条广告被一个用户点击的次数,N表示所有广告被点击的次数,T表示某条广告被所有用户点击的次数.
通过Hadoop中的MapReduce计算模型[7](见图1),首先将用户的ID和广告关键字的ID提取出来,然后计算每个广告在每个用户的点击总数,并将所有的点击总数统计出.利用上面的计算结果,统计出每个广告被点击的总数.最后利用式(1)计算出每个广告的关注度,从而对关注低的广告进行删除.Hadoop适合处理批量的离线数据,对于在线广告日志数据的处理,可能会有至少一天的延迟.对于网络营销者来说,一天的时间不仅带来经济上的损失,也可能会给品牌的知名度的推广造成延迟.所以,实时计算迫在眉睫.当前主流实时计算技术主要包括Storm[8]、Spark等,这些技术都能做到实时计算并实现低延迟,而Spark更胜一筹,它不仅包含实时计算,更有机器学习等多个方面的应用,能更好地应用到更多的领域.
2 Spark简介
2.1Spark架构
Spark是基于内存计算的大数据计算技术.Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价PC机之上,形成集群.Spark架构图如图2所示.和其他大数据技术相似,Spark采取了分布式计算中的主从架构.主节点是集群中含有Master进程的节点,从节点是集群中含有Worker进程的节点.主节点是整个集群的总控制器,负责集群的正常运行;从节点是计算节点,接受主节点命令与进行状况汇报;Executor负责执行作业;Client是用户的客户端,负责提交应用,Driver控制一个应用的执行[9].
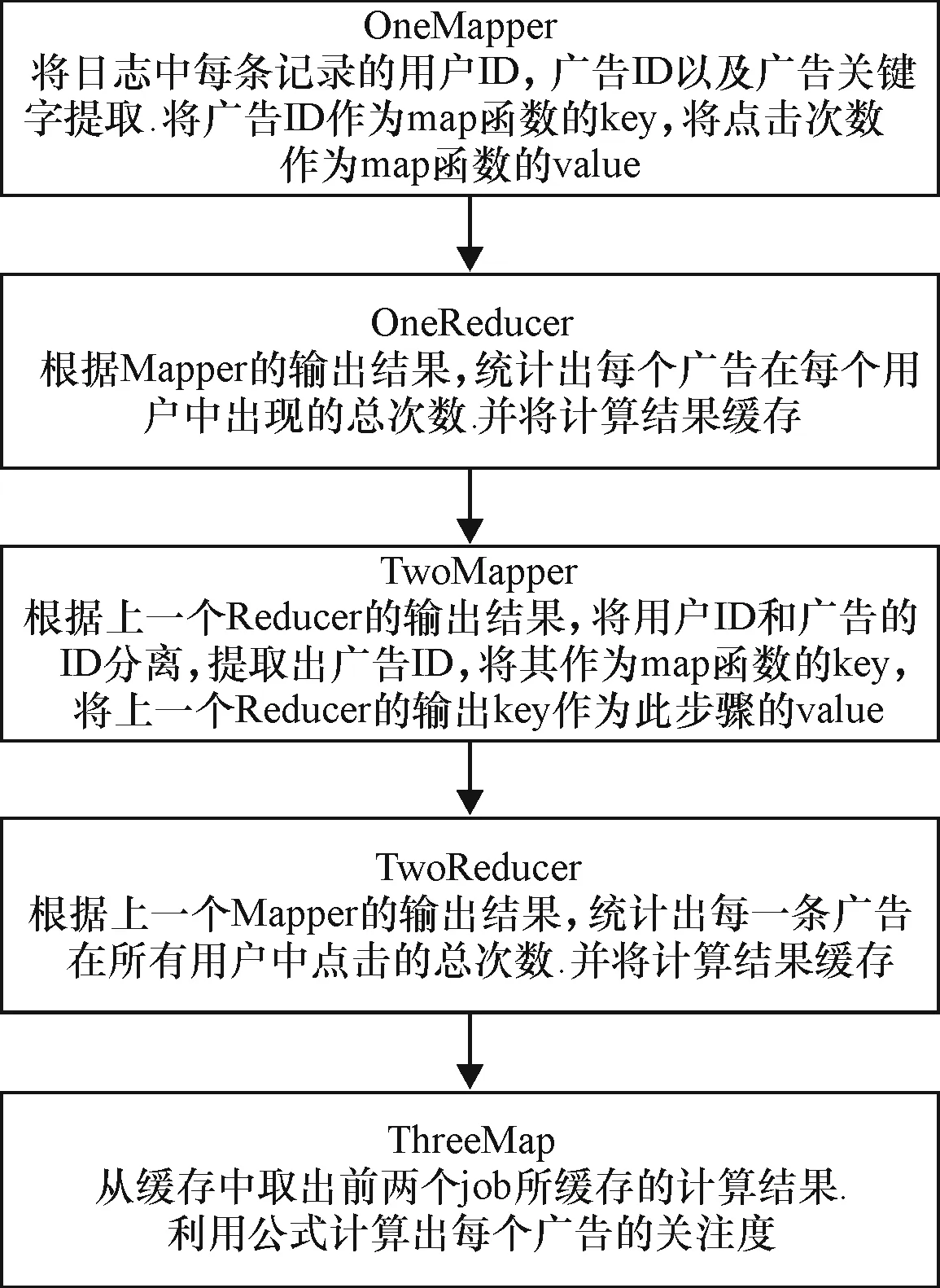
图1 广告关注度在Hadoop上的计算流程
Fig.1The computing process of the concern degree of advertisement on Hadoop
Spark中,整个执行流程在逻辑上会形成一个有向无环图.Action函数触发之后,所有累积的函数形成一个有向无环图,然后由调度器操控该图上的任务运算.Spark的调度方式和Mapreduce的不同之处在于,Spark根据RDD[10]之间不同的依赖关系切分成不同的阶段,一个阶段包含一系列函数执行的流水线.RDD的操作结果都可以Cache到内存中,以后的每个操作可以直接从内存中读取上一个RDD的数据集,从而省去了对磁盘的IO操作.

图2 Spark架构
Sprak是Mapreduce的替代方案,而且兼容HDFS,Hive等分布式存储层,可融入Hadoop的生态系统,运行在Hadoop集群之上,以弥补缺失Mapreduce的不足.Spark扩展了Mapreduce模型,高效地支持各种计算模式,包括交互式查询、迭代算法、批处理、流处理.
Spark相比Hadoop具有优势,不仅因为Spark是基于内存的计算,更重要的是Spark简化了Hadoop的Shuffle过程.
Hadoop的Mapreduce过程,Map阶段在Map之后节点产生的中间结果首先会缓存到内存中,当内存不足时,启用线程将数据Spill到硬盘.数据在硬盘中还将经历一次写归并的过程.之后Reduce阶段会从各个节点取数据,这个过程需要消耗网络资源,拉取过来的数据达到Reduce节点之后还要合并写入硬盘.这一系列读写合并的过程以及网络的消耗,Spark在内存中全部完成.
2.2SparkStreaming
处理流计算有几种通用的技术,最常见的有如下两种[11]:(1) 单独处理每条记录,并在记录出现时立刻处理;(2) 把多个记录组合为小批量任务,可以通过记录数量或者时间长度切分出来.
SparkStreaming使用第2种方法,使用微批次的架构[12],把流计算当做一系列连续的小规模批处理对待.核心概念是离散化流,也叫DStream.一个DStream是指一个小批量作业的序列,每一个小批量作业表示为一个Spark RDD.离散化流是通过输入数据源和批量处理间隔的时间窗口来定义的.数据流被分成批处理间隔相等的时间段.流中每一个RDD将包含从SparkStreaming应用程序接收到的一个批处理时间段内的记录.如果所在时间段内没有数据产生,将得到一个空的RDD.
图3为SparkStreaming基于时间顺序批量处理数据流,所以引入一个概念叫做时间窗.时间窗函数计算在流上的滑动窗口中的数据转换.

图3 DStream处理流
窗口由窗口长度和滑动间隔定义.10 s的窗口和5 s的滑动间隔可以定义一个窗口,每5 s计算一次前10 s接收到的DStream数据.DStream被缓存在内存里,如果数据源本身是容错的并且持久化的,那么DStream就可以重新计算.如果数据流来源于网络,SparkStreaming的默认持久化方式就是复制数据到两个节点.这就保证了网络DStream可以在失败的情况下重新计算.
SparkStreaming将程序中对DStream的操作转为DStream有向无环图.对于每个时间片,DStream DAG会产生一个RDD DAG.在RDD 中通过Action算子触发一个Job,SparkStreaming将Job提交给JobManager(见图4).JobManager将Job插入维护的Job队列,JobManager将队列中的Job提交给Spark DAGScheduler,Spark调度Job,并将task分发到各个节点的executor上执行.

图4 SparkStreaming架构
3 基于Spark的线性模型在广告中的应用
相比于离线计算,在线学习是以对训练数据通过完全增量的形式顺序处理一遍为基础.当处理完每一个训练样本,模型会对测试样例做预测并得到正确的输出.在线学习背后的想法就是模型随着接收到新的消息不断更新自己,而不是像离线训练一次次重新训练.当数据量很大,或者生成数据的过程快速变化的时候,在线学习可以快速接近实时地响应,而不需要离线学习中昂贵的重新训练[13].
Spark中提供了内建的流式机器学习模型.包含有线性回归模型.模型提供两个核心的方法,可以对数据流进行训练和预测.线性模型有广泛的应用,除了预测广告的点击概率,还可以应用在对网页等进行分类、点击欺诈检测[14]、垃圾邮件检测以及设备的故障检测等.
线性模型的思想是对样本的预测结果进行建模,即对输入变量应用线性预测函数.
y=f(wTx).
(2)
这里y是目标变量,是预测的输出,w是权重向量,x是输入的特征向量.通常情况,从广告标题和描述等角度考虑广告对用户的影响[15],所以本文采用用户ID,广告ID,广告关键字,广告标题变量构成一个特征向量.每一个特征向量可以看成是一个四元组对-1或者+1的映射.-1代表没点击,+1代表点击,4个元素是要研究的要素.
3.1模型的创建
一个线性模型是一个权值向量w和一个特征向量x的线性组合.数据生成器将使用固定的已知的权重向量和随机生成的特征向量产生合成的数据.它符合线性回归模型.
模型的创建一般包括如下几个步骤:
(1) 创建一个大小确定的数组,其中的元素通过正态分布生成.用这个函数来生成已知的权重向量w,它在生成器的整个生命周期中固定.权重向量能够对数据进行拟合.
(2) 创建一个随机的偏移值,权重向量和偏移值将会被用来生成流中的每一个数据.
(3) 需要一个函数生成确定数量的随机数据点.每一个活动包含一个随机的特征向量,通过计算已知向量及随机特征点积并加上偏移后的值对应的目标值.
(4) 模拟网络数据流.
(5) 创建流回归模型.建立大量的特征去匹配输入的流数据记录的特征.创建一个零向量来作为流回归模型的初始权值向量.选择合适的迭代次数和步长.
(6) 用map函数把流中的记录转换成LabelPoint实例,包含目标值和特征向量.
(7) 让模型在数据流上做训练,测试每一批数据的预测值.
以下是整个过程的相关代码:

generateRandomArray(n:Int)=Array.tabulate(n)(_=>random.nextGaussian())w=DenseVector(generateRandomArray(NumFeatures))intercept=random.nextGaussian()*10generateNoisyData(n:Int)={(1ton).map{i=> x=DenseVector (generateRandomArray(NumFeatures)) y:Double=w.dot(x) noisy=y+intercept (noisy,x) }zeroVector=DenseVector.zeros[Double](NumFeatures) model=newStreamingLinearRegressionWithSGD().setInitialWeights(Vectors.dense(zeroVector.data)).setNumIterations(1).setStepSize(sizeNum)labeledStream=stream.map{event=> split=event.split(" ") y=split(0).toDouble featres=split(1).split(",").map(_.toDouble) LabeledPoint(label=y,features= Vectors.dense(featres))}
3.2模型性能的评估以及调优
模型做预测的时候,可以通过ROC曲线来判定模型的性能好坏.ROC曲线是对分类器的真阳性率-假阳性率的图形可视化的解释.其中,真阳性:被正确预测的类别为1的样本.假阳性:错误预测为类别1的样本.真阴性:被正确预测的类别为0的样本.假阴性:类别为1却被预测为0的样本.真阳性率:是真阳性的样本数除以真阳性和假阴性的样本数之和.假阳性率:假阳性的样本数除以假阳性和真阴性的样本数之和.ROC曲线下的面积表示平均值,通常用AUC表示[16].当AUC为1.0时表示一个完美的分类器,0.5则表示一个随机的性能.一个模型的AUC为0.5时和随机的猜测效果是一样的.
3.2.1特征标准化优化
以上,只是简单地把原始数据送进了模型做训练,并没有把所有的数据都用在模型中,也没有对数值特征做进一步分析.数据在原始的情况下,并不符合标准的高斯分布.为了使数据更加符合模型的假设,可以对每个特征进行标准化,让每个特征是0均值和单位标准差.对每个特征值减去列的均值,然后除以列的标准差进行缩放.通过以下代码,用标准化的数据重新训练模型,计算出AUC的值为0.61,对比之前的0.5,精确度有了20%左右的提升.代码如下:

scaler=StandarScaler(withMean=true,withStd=true).fit(vectors)data=data.map(lp=>LabeledPoint(lp.label,scaler.transform(lp.features)))
3.2.2参数优化
1) 迭代优化
大多数机器学习的方法都需要迭代训练,迭代一定次数之后收敛到某个解,迭代次数的不同对结果也有很大的影响.通过迭代次数的不同算AUC的值来决定最优的.通过以下代码对不同的的参数进行测试,获得最优的AUC值.当参数分别选取1,10,20,30的时候,获得了不同的值,分别是0.649 1,0.666 9,0.667 0,0.668 3.结果如图5所示.可以看出,当参数为30时,AUC的值最大.并且,随着迭代次数的增加对结果的影响较小.代码如下:

result=Seq(1,10,20,30).map{param=>model=trainWithParams(scaledDataCats,0.0,param,SimpleUpdater,1.0)createMetrics(s”MYMparamiterations”,scaledDataCats,model)}iterRsults.foreach{case(param,auc)=>println(f”MYMparam,AUC=MYM{auc*100}%2.2f%%”)}

图5 迭代次数与AUC的关系
2) 步长优化
步长是用来控制算法在最陡的梯度方向上应该前进多远.大的步长收敛较快,但是步长太大可能导致偏离最优解.通过下边的代码对不同的步长做测试获得最优的步长,当步长分别选取0.001,0.01,0.1,1.0和10.0时,得到不同的结果,分别是0.649 3,0.650 1,0.654 4,0.655 8,0.617 7.如图6所示.图中数据结果表明,当步长选取1.0时AUC得到最大解,当步长再大时,AUC的值却降低.代码如下:

results=Seq(0.001,0.01,0.1,1.0,10.0).map{param=>model=trainWithParam(scaledDataCats,.0.,iteration,SimpleUpdater,param)createMetrics(s”MYMparamstepsize”,sccaledDataCats,model)}results.foreach{case(param,auc)=>println(f”MYMparam,AUC=MYM{auc*100}%2.2f%%”)}
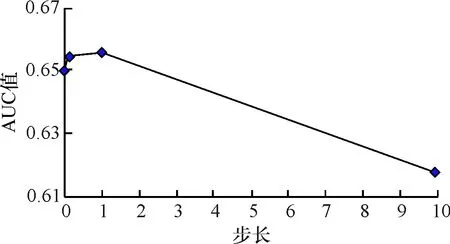
图6 步长与AUC的关系
4 结论
针对在线广告的投放效率,本文对比了Hadoop和Spark两种主流平台在实现流程及效率方面的差异,提出了将线性模型结合Spark技术应用在广告投放系统中,并从数值特征、迭代和步长等方面对模型进行优化,实现了广告投放的高精确度以及实时性.下一步的工作可以加入推荐算法,并接入实际生产中的数据,将其应用在实际生产中.
[1] 程学旗,靳小龙,王元卓,等.大数据系统和分析技术综述[J].软件学报,2014,25(9):1889-1908.
CHENG X Q,JIN X L,WANG Y Z, et al. Survey on big data system and analytic technology[J]. Journal of Software,2014,25(9):1240-1252.
[2] 林穗,黄健,姜文超,等.基于HDFS的安全云存储模型[J]. 广东工业大学学报, 2014,31(3): 49-54.
LIN S,HUANG J,JIANG W C, et al. A secure cloud storage model based on HDFS[J].Journal of Guangdong University of Technology,2014,31(3):49-54.
[3] 李成华, 张新访, 金海,等. Map Reduce:新型的分布式并行计算编程模型[J]. 计算机工程与科学, 2011, 33(3):129-135.
LI C H,ZHANG X F,JIN H, et al. Map Reduce:a new programming model for distributed parallel computing[J]. Computer Engineering and Science,2011, 33(3):129-135.
[4] The Apache Foundation. Spark official website[EB/OL].(2015-12-22)[2016-01-02].http:∥spark.apache.org/.
[5] 薛瑞, 朱晓民. 基于Spark Streaming的实时日志处理平台设计与实现[J]. 电信工程技术与标准化, 2015(9):55-58.
XUE R,ZHU X M. Design and implementation of a real time log processing platform based on Spark Streaming[J]. Telecom Engineering Technics and Standardization,2015(9):55-58.
[6] 宋乐怡, 宫学庆, 张蓉,等. 在线广告投放系统及技术的演变[J]. 华东师范大学学报(自然科学版), 2013(3):106-117.
SONG L Y,GONG X Q,ZHANG R,et al.Online advertising systems and related technology evolution[J]. Journal of East China Normal University(Natural Science Edition), 2013(3):106-117.
[7] 覃雄派,王会举,杜小勇,等.大数据分析——RDBMS与MapReduce的竞争与共生[J].软件学报, 2012,23(1):32-45.
QIN X P,WANG H J,DU X Y,et al. Big data analysis—competition and symbiosis of RDBMS and MapReduce[J]. Journal of Software,2012,23(1):32-45.
[8] 邓立龙,徐海水.Storm实现的应用模型研究[J]. 广东工业大学学报, 2014,3(13): 114-118.
DENG L L,XU H S. Research on applied models based on Storm[J]. Journal of Guangdong University of Technology,2014,3(13): 114-118.
[9] 高彦杰.Spark大数据处理:技术、应用与性能优化[M]. 北京:机械工业出版社,2014.
[10] 胡俊, 胡贤德, 程家兴.基于Spark的大数据混合计算模型[J]. 计算机系统应用, 2015(04):214-218.
HU J,HU X D,CHENG J X .Big data hybrid computing mode based on Spark[J]. Computer System Applications,2015(04):214-218.
[11] 孙大为, 张广艳, 郑纬民.大数据流式计算:关键技术及系统实例[J]. 软件学报, 2014,25(4):839-862.
SUN D W,ZHANG G Y,ZHENG W M.Big data stream computing:technologies and instances[J]. Journal of Software,2014,25(4):839-862.
[12] Holden Karau.Spark快速大数据分析[M].王道远,译. 北京:人民邮电出版社,2015.
[13] Nick Pentreath. Spark机器学习[M]. 蔡立宇,译. 北京:人民邮电出版社,2015.
[14] 李爱春, 滕少华. Web挖掘在网络广告点击欺诈检测中的应用[J]. 计算机工程与设计, 2012, 33(3):957-962.
LI A C,TENG S H. Application of web mining technology to click fraud detection[J].Computer Engineering and Design, 2012, 33(3): 957-962.
[15] 王海雷, 贺一骏, 俞学宁,等.搜索引擎广告用户行为预测与特征分析[J].计算机应用研究,2013, 30(5):1413-1418.
WANG H L,HE Y J,YU X N,et al. User behavior classification and feature analysis in search advertising[J]. Application Research of Computers,2013, 30(5):1413-1418.
[16] 朱丽辉, 谢瑾奎, 潘书敏,等.在线广告中改进数据分层的动态点击率评估算法[J].小型微型计算机系统,2015(7):1492-1497.
ZHU L H,XIE J K,PAN S M,et al. Dynamical click-through rate estimation algorithm by improving data hierarchy in online advertising[J]. Journal of Chinese Computer Systems,2015(7):1492-1497.
An Application Research of Linear Model in the Advertising System Based on Spark
Lin Sui, Zhao Fei
(School of Computers,Guangdong University of Technology, Guangzhou 510006, China)
The online advertisement is the most important model of Internet profit. It makes the computing advertising a hot point of current research. For the real-time requirement and the high accuracy requirement in the online advertising system, the difference between the implementation and efficiency is compared based on the two popular platforms of Hadoop and Spark. And then a linear model is proposed combined with the technology of Spark to be applied in the advertising system. Finally the linear model is optimized from the aspect of numerical characteristics, iteration and step size. The testing result shows that the accuracy has a 5% to 10% increase after the optimization.
Spark; real time computing; online advertisement; linear model
2016- 03- 10
广东省科技计划项目(2014B090901053);广州市科技计划项目(2013Y2-00074)
林穗(1972-),女,副教授,主要研究方向为操作系统、云计算.E-mail:linsui@gdut.edu.cn
赵菲(1989-),女,硕士研究生,主要研究方向为云计算.E-mail:zflb2008@126.com
10.3969/j.issn.1007- 7162.2016.05.006
TP311.1
A
1007-7162(2016)05- 0028- 06
