基于可中断Option的在线分层强化学习方法
2016-10-13朱斐许志鹏刘全伏玉琛王辉
朱斐,许志鹏,刘全,伏玉琛,王辉
基于可中断Option的在线分层强化学习方法
朱斐1,2,许志鹏1,刘全1,2,伏玉琛1,王辉1
(1. 苏州大学计算机科学与技术学院,江苏苏州215006;2. 吉林大学符号计算与知识工程教育部重点实验室,吉林长春130012)
针对大数据体量大的问题,在Macro-Q算法的基础上提出了一种在线更新的Macro-Q算法(MQIU),同时更新抽象动作的值函数和元动作的值函数,提高了数据样本的利用率。针对传统的马尔可夫过程模型和抽象动作均难于应对可变性,引入中断机制,提出了一种可中断抽象动作的Macro-Q无模型学习算法(IMQ),能在动态环境下学习并改进控制策略。仿真结果验证了MQIU算法能加快算法收敛速度,进而能解决更大规模的问题,同时也验证了IMQ算法能够加快任务的求解,并保持学习性能的稳定性。
大数据;强化学习;分层强化学习;Option;在线学习
1 引言
在强化学习(RL,reinforcement learning)框架中,用户给出问题的目标,agent选择某一个动作,实现与环境的交互,获得环境给出的奖赏作为强化信号,agent根据强化信号和环境当前状态再选择下一个动作。Agent的目标是在每个离散状态发现最优策略以使期望的折扣奖赏和最大[1]。作为一种具有较高通用性的机器学习框架,强化学习得到了较为广泛的研究和应用[2]。然而,由于强化学习的算法需要通过不断地与环境交互来进行学习,同时还要保存经验数据,因此当问题规模扩大时,算法的复杂度往往会以指数级上升,导致算法的性能急剧下降,所以强化学习的经典算法很难直接用于解决数据规模比较大的问题。研究人员提出了多种改进的强化学习算法来解决大规模空间的“维数灾”问题,如分层强化学习[3,4]、核方法[5]、函数逼近方法[6]等。在这些方法中,分层强化学习被用于解决一些大数据环境的任务[7]。
在分层强化学习的算法中,通过分层处理,agent关注当前局部空间的环境以及子任务目标状态的变化,策略更新的过程限定于局部空间或者高层空间上,相应地,所需解决的问题规模被限定在agent当前所处的较小规模的空间或抽象程度较高、维数较低的空间。这样不仅可以加快学习的速度,而且可以降低对环境的依赖性。在动态变化的环境中,这种特性有助于解决问题,因此显得尤为重要。时间抽象的方法是分层强化学习的一类重要方法。利用时间抽象,agent可以关注更高层策略的选择,从而降低算法的复杂度,使算法能解决一些大规模的问题。抽象动作为时间抽象提供了广泛的框架,其代表性工作是由Sutton等[8]提出的使用“宏动作”作为抽象动作的Option框架。很多方法使用子任务来表达抽象动作,子任务构成了整个任务的一部分[9]。也有很多工作寻找与子任务对应的子目标点[10~12],以及直接从值函数中得到抽象动作[13,14]。
一般而言,大数据是指不能在可以容忍的时间内用传统信息科学的技术、软件和硬件完成感知、获取、管理、处理和服务的数据集合[15]。大数据具有体量大(volume)、多变(variability)、价值高(value)、高速(velocity)等特点。由于大数据体量大,因此很多机器学习的算法无法直接用来解决大数据问题。大数据的多变性也要求机器学习的算法在考虑数据体量的同时,考虑数据的动态变化性。在大数据问题中,当无法直接从整个问题空间上求解最优解时,如何充分利用已有抽象动作来求解是一个需要解决的重要任务。虽然,Sutton等[16]对此有过初步的研究,但是,由于其工作是基于模型已知的前提下进行规划,故而在模型未知或环境动态变化的情况下,算法性能和效果会很差,导致算法很难应用于模型无关的任务和在线学习的任务中,更无法在大数据和动态的环境中很好地学习到最优策略。本文的主要工作就是解决动态环境下如何利用时间抽象学习的问题,针对大数据体量大的特点,在Macro-Q算法的基础上提出了在线式更新的算法,加快了算法的收敛速度,提高了数据样本的利用率,同时针对大数据可变化的特点,提出了中断式动作抽象的概念,使之能很好地适应环境的变化,并在此基础上提出了一种基于中断动作抽象的无模型学习算法。
2 相关工作
2.1 强化学习
大多数的强化学习方法都是基于马尔可夫决策过程(MDP, Markov decision process)。一个MDP可以用一个5元组表示,其中,和分别表示有限的状态集和动作集,表示迁移概率,表示agent得到的立即奖赏,表示折扣因子。在每个时间步,agent观察到系统的状态后采取某个动作,然后以概率迁移到下一个状态,此时agent会得到一个立即奖赏。Agent的目标是通过最大化期望奖赏来找到最优策略。
在线学习是一种在学习的过程中需要及时处理收集的数据,进行预测并更新模型的学习方式[17]。在线式强化学习通过与环境实时的交互来获取样本,然后再通过这些样本更新策略。在线强化学习能够在保证学习效果的前提下,同时给出次优的学习结果,而且在线采样比离线采样更容易。相比之下,离线的算法要求样本已知,只有在样本学完后才能应用学习好的策略。在大数据环境下,由于数据体量大,无法完全装载到内存中处理,因此,大数据环境的很多任务都采用在线学习的方式完成。
2.2 抽象动作
本文使用马尔可夫抽象动作[1,18]来描述时间抽象的动作序列。马尔可夫抽象动作和元动作同样是由agent选择的,不同的是抽象动作的执行是一个时间段,是多步完成的,而元动作则是单步完成,所以元动作被视为一种基本动作。在抽象动作执行的过程中,遵循抽象动作的内部策略,直到满足抽象动作的终止条件。
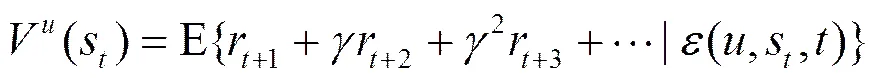
(2)
2.3 半马尔可夫决策过程
在强化学习中,满足马尔可夫性的强化学习任务就被称为MDP,而一个半马尔可夫决策过程(SMDP, semi-Markov decision process)可以由一个MDP和一个抽象动作集合组成。经典的SMDP理论是与动作相关的,其中,相关方法可以扩展到抽象动作中来。这样,对任意的抽象动作,若表示在时刻状态处开始的过程,那么对应奖赏的模型为
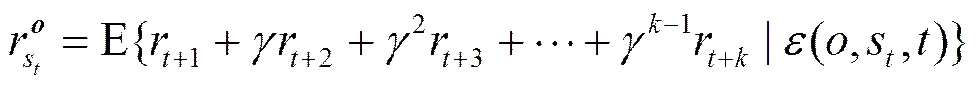
(4)
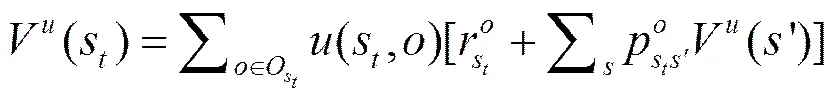
对应的动作值函数为
(6)
在值函数的基础上,可以得到最优值函数。在MDP中,选择的是最优的动作,而这里选择的是最优的抽象动作。使用来定义抽象动作集合,根据贝尔曼最优等式,可以得到最优值状态函数和最优动作值函数,分别如式(7)和式(8)所示。
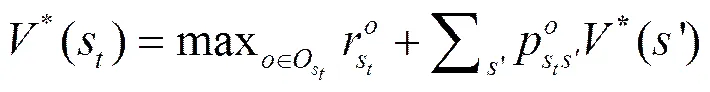
(8)
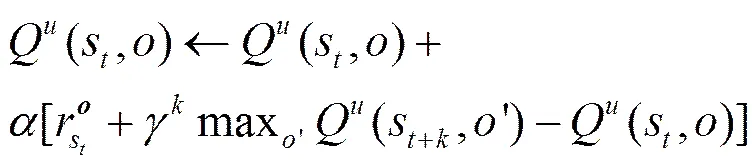
若抽象动作集合已经得到,那么就可以求出最优的状态值函数和动作值函数,最后得出最优策略。而且,标准的SMDP理论能够保证这样的过程能够收敛。
3 算法描述
3.1 可中断Option
抽象动作提高了agent探索的效率,从而使算法收敛速度更快[2]。利用抽象动作在解决相同领域的多任务时效果很好[10]。
传统应用抽象动作的SMDP方法通常是把抽象动作看作一个不透明、不可分割的整体。然而,要充分地发挥抽象动作的作用,需要改变抽象动作本身的结构。这里考虑使用中断抽象动作,即抽象动作在根据它的终止条件之前,如果有需要就中断抽象动作的执行。如在房间内导航的任务中,把agent从房间门入口进入到房间里这个动作序列建模成一个抽象动作,当agent执行这个抽象动作到刚刚准备踏入房间的那一瞬间,门突然关闭了,根据传统的SMDP中抽象动作的定义,此时抽象动作不应该终止,而应该继续执行,因为抽象动作的终止条件还不满足,而这就与门已经处于关闭状态形成了矛盾,导致agent的执行效率降低甚至失效。如果采用可中断Option,就可以解决这一问题。
3.2 可中断Macro-Q算法
传统的强化算法agent通过与环境反复交互的方式来学习值函数和策略,但是随着问题规模的扩大,agent就需要大量的时间和经验来与环境进行交互以获得好的策略。使用分层强化学习方法,应用抽象动作能在一定程度上减少对环境的探索,从而加快算法收敛和保证算法学习前期性能的稳定性。经典的SMDP方法把抽象动作看作一个不可拆分的整体,一旦抽象动作开始执行,就必须执行到抽象动作终止,不能中途结束。事实上,这种方式会面临以下2个主要问题:首先,在动态的环境下,往往在抽象动作还没结束时,抽象动作就执行不下去,导致算法效果很差;其次,在抽象动作执行的过程中,在某些状态选择其他的抽象动作会获得更好的性能。针对这2种可能出现的情况,本文提出了一种可中断Macro-Q(IMQ, interrupting Macro-Q)算法。
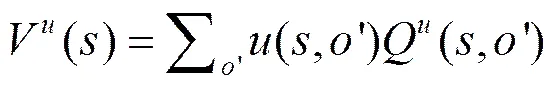
算法1 可中断Macro-Q算法
输入:折扣因子, 学习率, Option集合O
输出:值函数
1) 初始化值函数和队列
2) for 每个情节 do
3) 以s作为起始状态,初始化s
4) repeat
5) 根据策略从O中选择一个Option=<,,>
6) 执行
7) 根据(s)选择动作
11) 将s,,保存到队列中
12) if(’)=1 or=then
13) forindo
14) 以批量方式更新Q(,)
16) end if
17) else ifV()>Q(,)
18) forindo
19) 以批量方式更新Q(,)
20) 选择一个新的Option’
22) 终止执行
24) return
算法1是一种基于中断思想的无模型学习算法,能够很好地解决环境变化情况下,抽象动作无法整体使用的问题。
3.3 在线更新的Macro-Q算法
在线学习方法延伸模型的学习过程。在使用过程中,新数据的到来会引发模型的更新。而这种学习方法的一个直接负面影响是采样代价较高[19]。作为一种在线式的学习算法,经典的Macro-Q就需要花费完成采样。本文改进了Macro-Q算法,采用在线式in-place更新方法,在agent对抽象动作值更新的同时,对执行过的元动作也进行更新,如在线更新的Macro-Q(MQIU, macro-Q with in-place updating)算法所示。Macro-Q算法加快了值更新速率,从而加快算法的收敛速度。
算法2 在线更新的Macro-Q算法
输入:折扣因子, 学习率, Options 集合O
输出:值函数
1) 初始化值函数和队列
2) for 每个情节 do
3) 以s作为起始状态,初始化s
4) repeat
5) 根据策略从O中选择一个Option= <,,>
6) 执行
7) 根据(s)选择动作
11) 将s,,保存到队列中
13) forindo
16) end if
18) 终止执行
20) return
3.4 算法分析
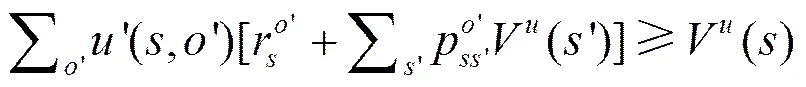
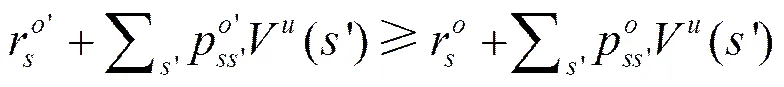
4 仿真实验
本文在格子世界实验的基础上,模拟动态和静态的环境进行仿真实验。通过与Q-learning做实验对比并给出实验结果来仿真验证IMQ的可行性和有效性。在仿真实验中,agent使用-greedy进行探索,初始探索概率,学习率,值都初始化为0,也可以被随机初始化。根据问题规模的不同,将提供不同的抽象动作集合。
4.1 动态环境的描述
到目前为止,强化学习大多数的研究都用于解决一些简单的学习任务,如房间导航问题、平衡杆问题、直流电机问题、过山车问题等。但是这些问题大多都是设定为静态环境的。如房间导航问题中,只有固定的墙壁或障碍物。然而,在实际的应用环境往往是未知的或者会发生变化。相应地,房间导航问题的设定中,障碍物应该是随机出现的,而且出现的位置也应该是随机的。本文的一个目标就是在动态的、不断变化的环境中找到最优策略。
在图1(a)所示的动态格子世界的仿真实验中,共有21×21个网格,标记为“S”的格子表示agent的出发点,标记为“G”的格子表示agent的目标终点,标记为“O”的格子表示障碍物。动态格子世界环境是会动态变化的,包括2种变化的对象:agent和障碍物的位置。对比图1(a)和图1(b)可以发现,在不同的时间,障碍物的位置是不一样的。
4.2 MQIU在格子世界中的性能
为了衡量MQIU的性能,本文在仿真实验环境下同时实现了Macro-Q、Q-learning和MQIU。实验环境为一个11×11的格子世界,如图2(a)所示,agent的出发点设在左下方,用“S”表示,目标点设在格子顶部的中间,用“G”表示。Agent的任务是从“S”出发,以最快的方式到达目标点“G”,agent所能采取的元动作为上、下、左和右。在算法Macro-Q和MQUI中,agent所能采取的动作除了上、下、左、右这4个元动作外,对每个状态还有4个可选的抽象动作,分别沿4个方向移动,直到碰到墙为止。
从图2(b)可以看出,MQIU和Macro-Q比Q-learning收敛更快,而且在整个学习过程中MQIU和Macro-Q都保持了很好的性能,平均每个情节步数维持在50步内。对比Macro-Q可以看出,MQIU在前15个情节稍差,但是在第15个情节之后,MQIU算法的性能就好于Macro-Q。产生这种现象的原因是MQIU在对抽象动作更新的同时更新了元动作的值,从而会加快值的收敛速度。
4.3 IMQ在4房间静态格子世界中的性能
本文首先对IMQ在静态环境下的表现做了深入的说明,如图3所示。4个房间静态格子世界实验如图3(a)所示,其中,“S”代表出发点,“G”代表目标点。Agent从“S”出发,经过房间之间的通道到达“G”,则一个情节结束。为了更好地说明算法的性能,IMQ和Macro-Q所使用的抽象动作是完全一样的。实验中的抽象动作设为每个房间内2个,一共8个,每个抽象动作能够把agent从房内任意一点带到房间的出口处。
从图3(b)中可以看出,在4个房间格子世界中,IMQ和Macro-Q的算法性能比Q-learning好很多。Macro-Q性能较为稳定,在整个学习的过程中一直保持很低的学习步数,然而其收敛速度和Q-learning一样,在500个情节后收敛。IMQ注重探索,在前50个情节性能比Q-learning好,略差于Macro-Q,但是IMQ收敛效果很好,在200个情节的时候就达到了收敛,并且一直保持很稳定。
4.4 IMQ在4个房间动态格子世界中的性能
4个房间动态格子世界实验如图4(a)所示。由于在这个实验中,环境被设置为动态变化的,因此更能检验算法的性能。目标状态“G”被放置在右下角的房间,起始状态“S”被放置在左上角房间的角落里。每个情节会随机初始化25个障碍物“O”,用来表示随机的环境。元动作是4个方向的动作:上、下、左和右。Agent在贪心动作(元动作或者抽象动作)的选择概率为,其他方向上,元动作或者抽象动作的选择概率为。Agent每走一步的奖赏都是−1,到达目标点的奖赏是0。由于本文关注的重点是抽象动作在动态环境中的应用,因此这里的抽象动作是预先定义好的。实验中对比了IMQ和Q-learning,没有对比Macro-Q以及基于规划的中断方法,是因为在动态环境下,这2种算法性能都很差。Macro-Q没有引入中断机制,导致如果抽象动作的执行过程被破坏,那么将无法继续按照抽象动作的内部策略继续执行。而基于规划的中断方法用于在线的算法中并不是很合理,而且需要模型,因此这里没有对比这2种算法。
图4(b)显示了在100次重复实验的基础上,agent从起始状态到达目标状态的平均步数,对比了IMQ和Q-learning在动态的格子世界中的性能。从图中可以看出带有不同抽象动作集合的3种IMQ算法无论是在收敛速度还是在学习时的表现上均好于Q-learning。其中,IMQ with integrated Option在性能上略差于另外2个IMQ算法,IMQ with good Option的性能总体上和IMQ with key Option相当;但是从图4(c)可以看出,IMQ with key Option仅在前50个情节略差于IMQ with good Option,从长期学习来看,IMQ with key Option学习效率更高,收敛更快。仿真实验证明了算法在动态环境下的有效性。为了更精确地说明几种算法的性能对比,在表1中给出了4个房间动态格子世界中各算法性能的对比数据。

表1 4个房间实验中,不同抽象动作集IMQ和Q-learning的对比实验结果数据
4.5 IMQ在6个房间动态格子世界中的性能
作为IMQ的第3个实验,在更大规模的环境下进行实验验证。本文使用6个房间的动态格子世界来进行仿真实验。Agent的任务和前面描述的基本一样,从起始点状态“S”走到目标状态“G”。实验的环境如图5(a)所示,其中,起始状态“S”靠近左上角,目标状态靠近右边。随机环境以及元动作的设定和前面介绍的一样,随机生成25个障碍物,用“O”表示。提供的抽象动作和前一节介绍的一样,但是由于房间的增多,这里提供的抽象动作的数量也会相应的变化。
图5(b)显示了在100次重复实验的基础上,agent从起始状态到达目标状态的平均步数,这个图与4个房间实验中的图相比,区别在于状态的增多、环境的复杂度更高,导致agent在学习的前期到达目标点所需的步数的增加,同时收敛速度也有所减缓。从图5可以看出,随着环境规模的增大,各算法间的区别更加明显。实验图5(b)表明,3种IMQ算法表现均优于Q-learning,其中,IMQ with key Option达到收敛所需的总步数最少,情节数也最少,这说明,关键的抽象动作能够更有效地加快agent的学习效率。
5 结束语
本文的工作主要包括以下几个方面。首先,针对传统SMDP方法不能解决动态环境下的学习和控制问题,本文提出一种在线学习的使用可中断动作抽象的算法——IMQ。借助于分层强化学习的方法,IMQ算法能够有效解决大数据环境下一般强化学习算法由于时间复杂度过高而不能解决的问题。相比于离线算法,IMQ算法能够在线地进行学习和采样,从而在加快学习效率的同时又保证了算法的性能。实验结果表明,IMQ算法比Q-learning算法和Macro-Q算法具有更快的收敛速度。
其次,针对Macro-Q算法样本利用率不高的问题,本文提出了一种基于同步替代更新的算法——MQIU算法。在算法中,对抽象动作的值函数进行更新的同时,也更新元动作的值函数。实验结果表明,MQIU算法较Macro-Q效果略好,收敛速度上略快。
第三,针对传统的抽象动作不能很好地解决动态环境的问题,本文将中断的方式引入抽象动作的概念中,提出了中断式动作抽象的概念,使之能很好地适应环境的变化,并在此基础上提出了一种基于中断动作抽象的无模型学习算法。实验结果表明,在动态的环境下,适当地利用抽象动作能够加快任务的求解,并且有助于agent在学习的过程中保持性能的稳定。
然而,在本文中的抽象动作是预先定义好的,如何快速有效地自动发现合适的抽象动作来加快长期学习agent的学习效率,是将要研究的一个重要内容。另外,在动态的环境下,如何充分利用样本的模型学习以及如何将抽象动作用于多任务、多agent协作也是主要的一项工作。
[1] OTTERLO M V, WIERING M. Reinforcement learning and Markov decision processes[J]. Adaptation Learning & Optimization, 2012, 206(4):3-42.
[2] VAN H H. Reinforcement learning: state of the art[M]. Berlin: Springer, 2007.
[3] 沈晶, 顾国昌, 刘海波. 未知动态环境中基于分层强化学习的移动机器人路径规划[J]. 机器人, 2006, 28(5):544-547. SHEN J, GU G C, LIU H B. Mobile robot path planning based on hierarchical reinforcement learning in unknown dynamic environment[J]. ROBOT, 2006, 28(5): 544-547.
[4] 刘全, 闫其粹, 伏玉琛, 等. 一种基于启发式奖赏函数的分层强化学习方法[J]. 计算机研究与发展, 2011, 48(12): 2352-2358. LIU Q, YAN Q C, FU Y C, et al. A hierarchical reinforcement learning method based on heuristic reward function[J]. Journal of Computer Research and Development, 2011, 48(12): 2352-2358.
[5] 陈兴国, 高阳, 范顺国, 等. 基于核方法的连续动作Actor-Critic学习[J]. 模式识别与人工智能, 2014(2): 103-110. CHEN X G, GAO Y, FAN S G, et al. Kernel-based continuous-action actor-critic learning[J]. Pattern Recognition and Artificial Intelligence, 2014(2):103-110.
[6] 朱斐, 刘全, 傅启明, 等. 一种用于连续动作空间的最小二乘行动者-评论家方法[J]. 计算机研究与发展, 2014, 51(3): 548-558 ZHU F, LIU Q, FU Q M, et al. A least square actor-critic approach for continuous action space[J]. Journal of Computer Research and Development, 2014, 51(3): 548-558.
[7] 唐昊, 张晓艳, 韩江洪, 等. 基于连续时间半马尔可夫决策过程的Option算法[J]. 计算机学报, 2014(9): 2027-2037. TANG H, ZHANG X Y, HAN J H, et al. Option algorithm based on continuous-time semi-Markov decision process[J]. Chinese Journal of Computers, 2014(9): 2027-2037.
[8] SUTTON R S, PRECUP D, SINGH S. Between MDPs and semi-MDPs: a framework for temporal abstraction in reinforcement learning[J]. Artificial Intelligence, 1999, 112(1): 181-211.
[9] MCGOVERN A, BARTO A G. Automatic discovery of subgoals in reinforcement learning using diverse density[J]. Computer Science Department Faculty Publication Series, 2001(8):361-368.
[10] ŞIMŞEK Ö, WOLFE A P, BARTO A G. Identifying useful subgoals in reinforcement learning by local graph partitioning[C]//The 22nd International Conference on Machine Learning. ACM, c2005: 816-823.
[11] ŞIMŞEK Ö, BARTO A G. Using relative novelty to identify useful temporal abstractions in reinforcement learning[C]//The Twenty-first International Conference on Machine Learning. ACM, c2004: 751-758.
[12] CHAGANTY A T, GAUR P, RAVINDRAN B. Learning in a small world[C]//The 11th International Conference on Autonomous Agents and Multiagent Systems-Volume 1. International Foundation for Autonomous Agents and Multiagent Systems. c2012: 391-397.
[13] SUTTON R S, SINGH S, PRECUP D, et al. Improved switching among temporally abstract actions[J]. Advances in Neural Information Processing Systems, 1999: 1066-1072.
[14] CASTRO P S, PRECUP D. Automatic construction of temporally extended actions for mdps using bisimulation metrics[C]//European Conference on Recent Advances in Reinforcement Learning. Springer-Verlag, c2011: 140-152.
[15] 何清, 李宁, 罗文娟, 等. 大数据下的机器学习算法综述[J]. 模式识别与人工智能, 2014, 27(4): 327-336.
HE Q, LI N, LUO W J, et al. A survey of machine learning algorithms for big data[J]. Pattern Recognition and Artificial Intelligence, 2014,27(4): 327-336.
[16] SUTTON R S, PRECUP D, SINGH S P. Intra-option learning about temporally abstract actions[C]//ICML. c1998, 98: 556-564.
[17] 石川, 史忠植, 王茂光. 基于路径匹配的在线分层强化学习方法[J]. 计算机研究与发展, 2008, 45(9): 1470-1476 SHI C, SHI Z Z, WANG M G. Online hierarchical reinforcement learning based on path-matching[J]. Journal of Computer Research and Development, 2008, 45(9): 1470-1476.
[18] BOTVINICK M M. Hierarchical reinforcement learning and decision making [J]. Current Opinion in Neurobiology, 2012, 22(6): 956-962.
[19] 王爱平, 万国伟, 程志全, 等. 支持在线学习的增量式极端随机森林分类器[J]. 软件学报, 2011, 22(9):2059-2074. WANG A P, WAN G W, CHENG Z Q, et al. Incremental learning extremely random forest classifier for online learning[J], Journal of Software, 2011, 22(9):2059-2074.
Online hierarchical reinforcement learning based on interrupting Option
ZHU Fei1,2, XU Zhi-peng1, LIU Quan1,2, FU Yu-chen1, WANG Hui1
(1. School of Computer Science and Technology, Soochow University, Suzhou 215006, China; 2. Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education, Jilin University, Changchun 130012, China)
Aiming at dealing with volume of big data, an on-line updating algorithm, named by Macro-Q with in-place updating (MQIU), which was based on Macro-Q algorithm and takes advantage of in-place updating approach, was proposed. The MQIU algorithm updates both the value function of abstract action and the value function of primitive action, and hence speeds up the convergence rate. By introducing the interruption mechanism, a model-free interrupting Macro-Q Option learning algorithm(IMQ), which was based on hierarchical reinforcement learning, was also introduced to order to handle the variability which was hard to process by the conventional Markov decision process model and abstract action so that IMQ was able to learn and improve control strategies in a dynamic environment. Simulations verify the MQIU algorithm speeds up the convergence rate so that it is able to do with the larger scale of data, and the IMQ algorithm solves the task faster with a stable learning performance.
big data, reinforcement learning, hierarchical reinforcement learning, Option, online learning
TP181
A
10.11959/j.issn.1000-436x.2016117
2015-04-03;
2016-04-12
伏玉琛,yuchenfu@suda.edu.cn
国家自然科学基金资助项目(No.61303108, No.61373094, No.61272005, No.61472262);江苏省高校自然科学研究基金资助项目(No.13KJB520020);吉林大学符号计算与知识工程教育部重点实验室基金资助项目(No.93K172014K04);苏州市应用基础研究计划基金资助项目(No.SYG201422);苏州大学高校省级重点实验室基金资助项目(No.KJS1524);中国国家留学基金资助项目(No.201606920013)
The National Natural Science Foundation of China (No.61303108, No.61373094, No.61272005, No.61472262), The High School Natural Foundation of Jiangsu Province (No.13KJB520020), The Key Laboratory of Symbolic Computation and Knowledge Engineering of Ministry of Education of Jilin University(No.93K172014K04), Suzhou Industrial Application of Basic Research Program (No.SYG201422), Provincial Key Laboratory for Computer Information Processing Technology of Soochow University (No.KJS1524), The China Scholarship Council Project (No.201606920013)
朱斐(1978-),男,江苏苏州人,博士,苏州大学副教授,主要研究方向为机器学习、人工智能、生物信息学等。
许志鹏(1991-),男,湖北荆州人,苏州大学硕士生,主要研究方向为强化学习、人工智能等。
刘全(1969-),男,内蒙古牙克石人,博士后,苏州大学教授、博士生导师,主要研究方向为多强化学习、人工智能、自动推理等。
伏玉琛(1968-),男,江苏徐州人,博士,苏州大学教授、硕士生导师,主要研究方向为强化学习、人工智能等。
王辉(1968-),男,陕西西安人,苏州大学讲师,主要研究方向为强化学习、人工智能等。
