基于空间短文本对象的检索策略
2016-10-13顾彦慧王道胜王永根龙云飞蒋锁良周俊生曲维光
顾彦慧 王道胜 王永根 龙云飞 蒋锁良 周俊生 曲维光
基于空间短文本对象的检索策略
顾彦慧1,2,†王道胜3王永根1,2龙云飞4蒋锁良1,2周俊生1,2曲维光1,2
1.南京师范大学计算机科学与技术学院, 南京 210023; 2.江苏省信息安全保密技术工程研究中心, 南京 210023; 3.南京师范大学文学院, 南京 210097; 4.香港理工大学电子计算学系, 香港; † E-mail: gu@njnu.edu.cn
针对传统空间文本检索策略中的效率和有效性问题, 对如何从给定的空间文本对象集合中快速有效地检索出top-个近似结果进行研究。基于一个空间检索的通用框架, 提出一种基于空间文本对象的快速策略, 用于满足用户对效率与有效性的要求。实验结果证明该策略优于现有方法。
空间文本对象; 语义相似; top-
在基于位置的应用中, 检索相似的空间文本对象是一个重要的研究课题, 如街旁、Foursquare服务等, 这里与位置信息有关的内容得到利用。在某个地图上, 对于一个查询, 检索系统需要找到与之最相关的空间文本对象集合, 对于集合中的每一个元素, 要同时考虑空间最相近并且语义最相似。在最近的研究中, 有很多研究致力于检索空间文本对象。总的说来, 空间对象的索引方式可以归纳为以下几类: 1)基于R-tree的策略[1-4]; 2)基于网格的策略[5]; 3)基于空间填充曲线的策略[6-7]。对于文本信息, 主要使用基于倒排文件的策略[1-2]和基于签名文件的策略[8]。为了检索相似的空间文本对象, 一种直接的方法就是融合空间索引以及文本索引。根据融合策略的不同, 大体上可以分为面向空间索引的策略[6]和面向文本索引的策略[9]。然而, 这些策略是一种松散的策略, 只是把空间索引和文本索引简单地融合在一起, 空间消耗比较大, 检索的效率也不高。为了克服松散融合的不足, 文献[1,2,7] 提出紧密融合的策略。
由于紧密融合策略能够无缝地将两种不同的索引(空间索引和文本索引)组合到一个统一的框架中, 因此在这个框架中, 每个顶点是两种相似度的组合(空间相似度与文本相似度)。文献[2]中引入一个新型的索引结构, 称为IR-tree, 每个R-tree的顶点与的子树对象内容的概要相关联。然而, 对于空间文本对象来说, 这种文本描述往往很短, 并且有时几乎没有相同词存在。对于空间文本对象来说, 文本信息比较短, 若使用传统的词频计算的方式来计算文本之间的相似度, 不能得到精确的结果[1-2], 因此传统的基于词频计算策略[10-13]不大适用于计算文本之间的相似度。考虑到空间文本对象的实际情况, 本文提出一种基于语义相似的文本相似度计算策略来融合相应的空间信息, 从而得到比较精确的检索结果。
本文提出一种快速有效地检索相似空间文本对象的策略, 其中心思想在于建立一个完整的结构, 能无缝地融合空间索引和文本索引。实验结果表明, 由于考虑了空间文本对象文本的属性, 本文提出的策略能有效地提高空间文本对象的检索精度, 并且能保持较高的速度。
1 问题的提出
1.1 准备知识
假设为一空间文本数据集合。每个空间对象∈被定义为一个对象对(.,.), 其中.是一个二维的地理位置(可以用经度和维度表示),.是一个文本描述, 也就是用户在某个地理位置的文本表达。算法要解决的问题是, 检索出与查询最相似的top-个空间文本对象。对于一个查询=〈.,.,〉, 在给定的空间文本对象集合中寻找个对象, 这些对象按照相似度进行排序(这里的相似度同时考虑了空间相似度和文本相似度), 即
具体地, 对于某查询, 对象的排序值可以用下式计算:
,
其中,S(.,.)是对象.与.之间的欧氏 距离,T(.,.)是这两个对象之间的文本距离,。
1.2 空间临近与文本相似
空间临近S被定义为标准化的欧氏距离, 即
dist(.,.)是查询对象与所有数据集中对象的欧氏距离。文本之间的相似度计算可以使用现有方法, 如语言模型[1], 余弦策略[9]或BM25[1]。因此, 文本之间的距离可以定义为
T= 1 − Sim(.,.)。
从前面的分析可以得知, 现有的基于词频以及共现的模式需要有很多相同的词出现在相似的文本中, 这种方式不适合计算两个短文本之间的相似度, 因为两个短文本之间虽然语义相似, 但往往只有很少的共同的词[10-13]。为了克服短句的不足, 很多研究致力于解决短文本相似度的计算问题, 总的来说可以分为基于知识的策略[12]、基于语料库的策 略[10-11]、基于语法的策略[11]以及混合策略[10,13]。
为了计算文本之间的相似度S(.,.), 我们使用最新的短文本相似度计算方法来组合不同的相似度计算策略[10,13]。需要强调的是, 短文本由词组成, 因此计算短文本间的相似度归根到底是计算词与词之间的相似度[10,13]。
1.3 通用框架模型
有很多工作致力于研究快速检索top-空间文本对象, 本文在其中选取一个最具代表性的工作[1]作为研究对象。文献[1]中使用一个混合索引结构IR-tree, 融合了空间信息以及文本信息。IR-tree本质上是一棵R-tree, 每个顶点关联一个倒排文件索引, 这个索引包含此顶点所有子树的信息。IR-tree的每个顶点能总结此顶点所有子节点的文本信息, 即此顶点能描述子节点的所有信息。同时, 此顶点能估计出查询与所有在子树中对象的相关程度, 并给出边界。因此, top-检索的结果使用最佳优先搜索和优先队列来实现。
2 本文提出的策略
考虑到文本的语义相似性, 本文提出一种快速有效的空间文本对象的检索方法。在介绍本文的策略之前, 首先讨论现有的集中空间文本对象的检索方法。
2.1 基准策略
若要快速有效地得到top-的空间文本对象, 主要的挑战在于如何对空间信息以及文本信息进行索引。一种简单的方法就是利用R-tree来计算对象的空间相近程度, 利用倒排文件的方式来计算文本的相似性[14]。然后, 把两种索引结合起来, 得到top-的空间文本对象。但是, 计算数据集中所有的候选对象是非常耗时的。另一种解决方法是基于倒排文件和R-tree来计算空间相近度以及文本相似度, 最终生成一个top候选对象的集合。然而, 这种方式也比较耗时, 因为在预先不知道查询的情况下, 不能在第一步确定需要计算多少个候选对象来满足最终的top-结果, 即不能保证第一步查找的对象能满足后面的值。
2.2 基于语义的策略
本文的主要目的是将语义信息融合到索引结构中, 并能很好地融合空间相近性与语义相似性。在文献[1]中, 由于紧密融合了倒排文件索引以及R-tree, 在文本信息与空间信息的融合上取得较好的效果。对于给定的两个短文本和, Sim(,)与短文本中代表性的词对有关。设1,2, …,t和1,2, …,t是和的词。如果≤, 则相似度值可以表示为
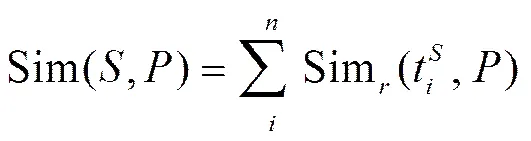
这里Sim表示代表性词对之间的相似度, 其值可以从代表性的词对之间获得。因此, 为文本信息建立的倒排表必须满足以下条件: 1)所有词都必须定义; 2)接续列表必须与词相关。然而, 如果一个查询包含多个词1,2, …,t, 如何从中获取相关词? 由于本文提出的策略是从倒排表中获取排序列表, 每个词与排序列表有关, 因此很容易应用阈值算法[15]来获得与查询最相关的文本。文献[1]中将空间索引与文本索引融合在同一索引结构中。根据索引建立的方式, 本文中融合文本的语义信息。
2.2.1 索引建立
IRS策略 IRS策略是将语义信息融合到IR-tree中(即使用了语义相似度的IR-tree)。IRS的建立利用了在R-tree中普遍使用的插入操作[16]。此操作包含选择叶节点和分裂节点, 并保证节点的子节点包含节点中所有的文本信息。每个节点包含一个指向倒排表的指针。在IRS的索引结构中, 叶子节点包含一组实体, 记为(,,.), 这里为数据集中的空间文本对象,为对象的矩形边界,.是对象的文本描述。在子节点中, 存储指向倒排表的指针。非叶节点包含一组实体, 记为(,,.), 这里为子节点的地址,为包含所有矩形的最小边界矩形,.为此矩形的文本描述。本文融合了每个空间文本对象的语义信息, 所以在倒排表中, 每个词对应一组文本列表对象, 这些对象按照词语文本之间相似度的倒序排列。在IRS 中, 文本信息总结了所有子节点中的文本内容, 所以能预估与查询相关的范围。
DIRS策略 从IRS策略可以看出, 索引建立时只考虑空间信息, 即最小矩形是否与空间位置有关。在实际情况中, 对于一个查询, 距离查询最近的不一定是用户最终想得到的结果, 因此在索引建立时需要同时考虑空间信息和文本信息。与IRS策略相似的是, 非叶节点包含一组实体, 记为(,,.)。与R-tree操作相同, 对于一个新的空间文本对象, 为了选择合适的插入路径, DIRS同时考虑了空间信息和文本信息。记每个节点的条目为En1, En2, …, En。令new是新插入的空间文本对象, 在R-tree中, En的面积由于新空间文本对象new的加入而变大。本文使用一个衡量指标EnlargeRec(En)来描述面积的增加值:
EnlargeRec(En) = Rec(Ennew.) − Rec(En),
其中, Rec(Ennew.)是En融入了新空间文本对象new后的新实体。考虑了文本信息后, 面积增加可以用下式表示:
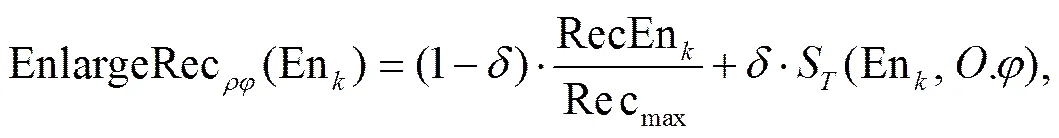
其中,是调节空间信息与文本信息的参数, Recmax是包含所有空间文本对象的最小边界矩形。
据报道,我国护理科研在心理护理、人文护理等的研究远远落后于发达国家,我国在对照顾者的护理方面与国外相比差距甚远[4]。因此,重视患者照顾者的早期心理状况,尽早介入照顾者的心理干预,能有效减轻照顾者的身心压力,有助于促进患者的康复。
不同于R-tree, 在建立DIR索引的插入操作中, 选取子树时要考虑文本信息, 使EnlargeRec(En)的值最小。同样, 在分裂操作中也需要考虑文本的信息, 即在建立索引的整个过程中同时考虑到空间信息与文本信息。
2.2.2 查询过程
最佳优先遍历算法[17]和优先队列用于存储访问过的顶点和空间文本对象。我们用min(,)表示查询与矩形之间的边界, Simdist(,)表示与每个空间文本对象之间的距离, 详细说明见表1。需要说明的是, Simdist(,)算法仅计算查询与算法遍历过的对象或矩形。我们用一个例子来说明DIRS与IRS策略的不同, 具体过程见表2和3。

表1 查询Q与对象以及矩形的距离值
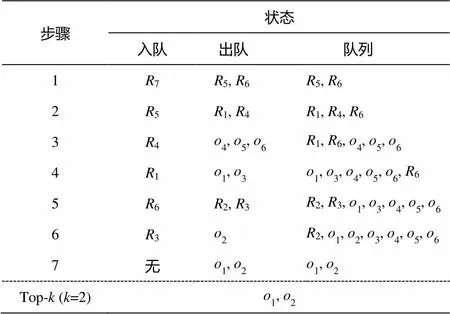
表2 基于IRS策略的查询过程
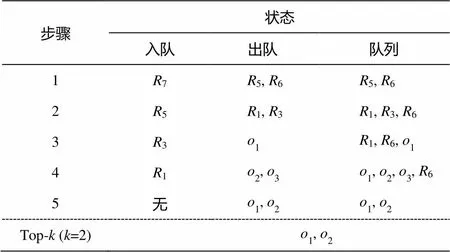
表3 基于DIRS策略的查询过程
从表2可以看出, 为了得到top-2对象2,1, IRS策略的检索过程遍历5,6,1,2,3,4, 也就是遍历整棵树中大部分的节点。这是因为IRS策略在建立索引的时只考虑空间信息, 忽视了文本的语义信息。
从表3可以看出, DIRS策略的检索过程仅需遍历5,1,3就能得到最终的top结果。这是因为DIRS在索引建立时考虑了文本的语义信息, 使得索引结构更加准确, 查询的过程只需要遍历很少的节点, 即只需要5步, 少于IRS策略的7步。
3 实验分析
我们通过实验, 从效率和有效性两个方面检验本文提出的策略。实验在16-core Intel® Xeon® E5530服务器上进行, 操作系统为Debian 2.6.26-2, 所有程序使用C语言编写, 利用GNU gcc编译器编译。
本文使用文献[18]中使用的数据集。此数据集共有225098个用户, 22506721个唯一的空间文本对象(这里的对象既含有空间信息, 又含有文本信息)。为了检验本文所提策略的有效性, 将IR-tree没有融入语义信息作为基准策略, 记为baseline, 将IR-tree使用了语义信息记为IRS, 将文本信息索引加上语义融合记为DIRS。本文所用数据集的统计信息见表4。
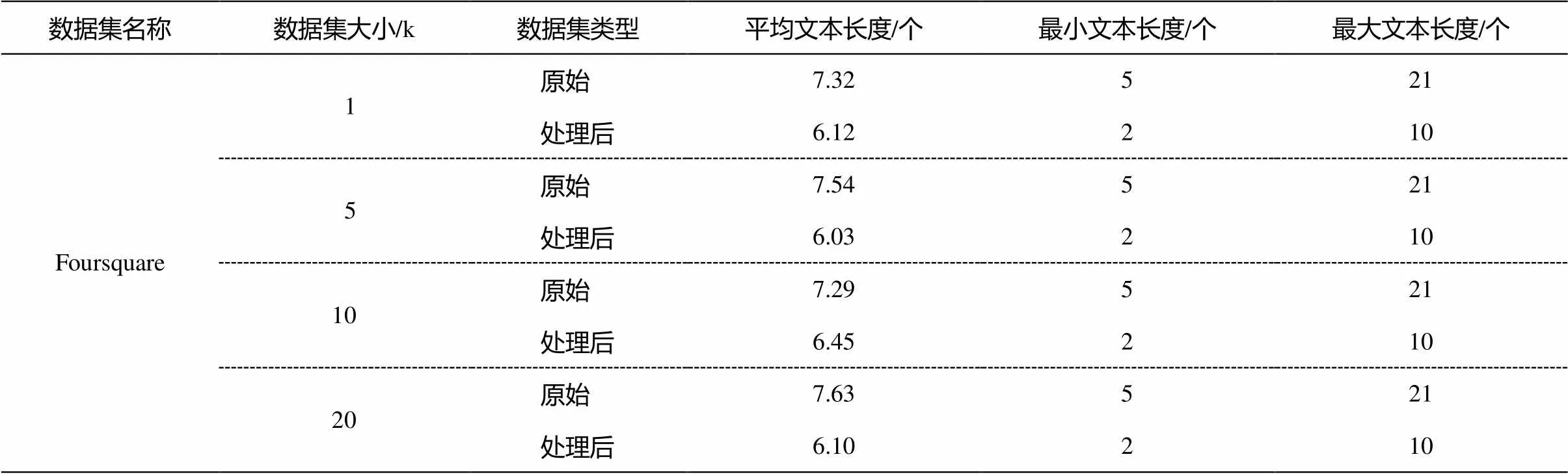
表4 数据集统计信息
说明: “原始”表示从原始的数据集中抽取的文本结果, 没有经过任何预处理; “处理后”表示去除停用词以及规则化后的结果。
3.1 有效性实验结果
在有效性试验中, 我们随机选择5个查询, 分别计算在基准策略、IRS以及DIRS三种策略下的精度。从前面的分析可以看出, 影响有效性的因素有两个。一个影响因素是在计算过程中调节融合空间相近程度与文本相近程度的参数, 这个参数的作用主要是调节空间相近与文本相似这两个因素的权重。这是由于在实际的系统中, 人们对空间相似度与文本相似的关心程度不同, 因此需要调节这个权重来计算出更加精确的结果。另一个影响因素是索引建立时, 用来调节文本加强程度的参数。由于本文所提策略在索引建立初期就考虑文本因素对于整个索引建立的影响, 因此就是为了调节文本因素对索引建立影响程度的参数。我们通过交叉验证实验, 选测和的最佳值。
和的取值都在0.1~0.9之间。从实验结果得到: 对于IRS,=0.68; 对于DIRS,=0.68,=0.2。有效性实验结果如表5所示, 可以看出, IRS策略和DIRS策略由于考虑了语义信息, 所以明显优于基准策略。
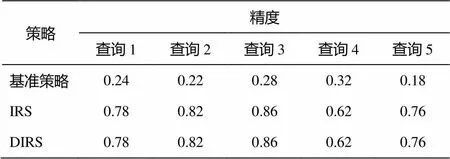
表5 有效性实验结果
3.2 不同参数下实验结果
由于本文的实验结果与两个重要的参数和有关, 因此我们分别选取和在0.1~0.9区间, 按照粒度0.1来验证, 结果如表6和7所示。可以看到, 相比于IRS策略, 由于DIRS策略在索引建立时已经考虑了文本之间的信息, 所以能大幅度减少访问时间。从表6和7还可以看出, 不同的和值对效率的影响主要表现在节点访问的顺序以及在某个节点访问的时间长短上, 所以和这两个参数对基准策略的影响不大, 而对IRS策略和DIRS策略有一定的影响。因此, 为了平衡有效性与效率之间的关系, 如何选取和参数值也是一个重要的研究课题。
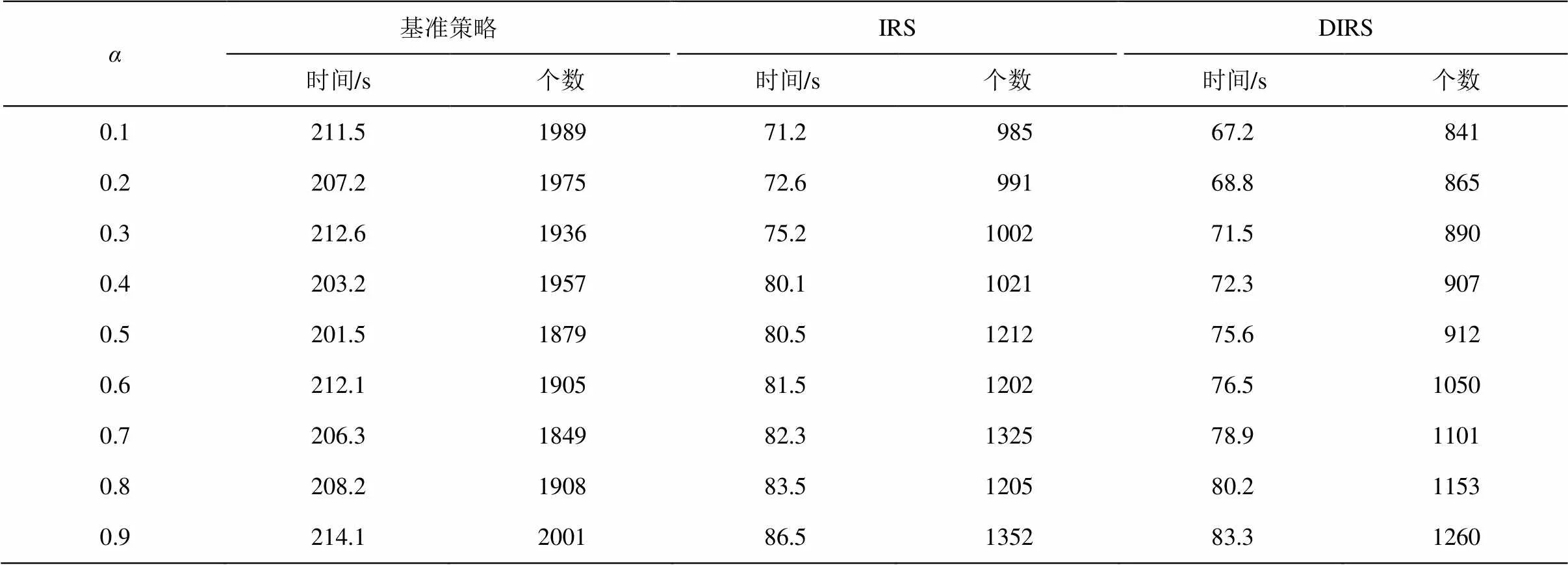
表6 不同α下效率实验结果
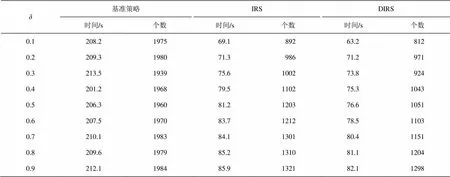
表7 不同δ下效率实验结果
3.3 效率实验结果
效率的比较使用有效性试验中最佳的参数配置, 通过以下的实验来检验: 不同的数据集大小以及不同的值。本文从数据集中随机抽取10个对象作为查询, 实验结果包括平均查询时间, 结果如图1和2所示。可以看出, 由于DIRS在索引建立时考虑了文本信息, 使得查询访问较少的节点就能得到最终的结果, 所以在性能上DIRS比IRS具优势。
4 总结
本文针对传统空间文本检索策略中的有效性问题, 对如何从给定的空间文本对象集合中快速有效地检索出top-个近似结果进行研究, 主要贡献如下。
1)以空间文本对象检索为研究对象, 提出一种基于语义的策略, 在空间文本兑现检索过程中考虑到语义信息, 通过建立综合的索引来无缝融合空间索引与文本索引。
2)提出一种快速有效的空间文本对象的检索算法, 这种算法对于实际应用系统非常重要, 因为用户更加倾向于找到语义相似的对象。
3)对实际数据的实验表明, 与现有策略相比较, 本文提出的策略在速度以及有效性方面有较大优势。
[1]Cong G, Jensen C S, Wu D. Efficient retrieval of the top-most relevant spatial web objects // Proceedings of the VLDB Endowment. Lyon, 2009: 337–348
[2]Li Z, Lee K C K, Zheng B, et al. IR-tree: an efficient index for geographic document search. IEEE Transac-tions on Knowledge and Data Engineering, 2011, 23 (4): 585–599
[3]Zhang D, Chee Y M, Mondal A, et al. Keyword search in spatial databases: towards searching by document // Proceedings of IEEE International Conference on Data Engineering. Shanghai, 2009: 688–699
[4]Zhou Y, Xie X, Wang C, et al. Hybrid index structures for location-based web search // Proceedings of Inter-national Conference on Information and Knowledge Management. Bremen, 2005: 155–162
[5]Khodaei A, Shahabi C, Li C. Hybrid indexing and seamless ranking of spatial and textual features of web documents // Proceedings of International Con-ference on Database and Expert Systems Applica-tions. Bilbao, 2010: 450–466
[6]Chen Y Y, Suel T, Markowetz A. Efficient query processing in geographic web search engines // Proceedings of ACM SIGMOD International Con-ference on Management of Data. Chicago, 2006: 277–288
[7]Christoforaki M, He J, Dimopoulos C, et al. Text vs. space: efficient geo-search query processing // Procee-dings of International Conference on Information and Knowledge Management. Glasgow, 2011: 423–432
[8]Felipe I D, Hristidis V, Rishe N. Keyword search on spatial databases // Proceedings of IEEE International Conference on Data Engineering. Cancun, 2008: 656–665
[9]Rocha-Junior J B, Gkorgkas O, Jonassen S, et al. Efficient processing of top-spatial key-word queries // Proceedings of International Symposium on Spatial and Temporal Databases. Minneapolis, 2011: 205–222
[10]Islam A, Inkpen D. Semantic text similarity using corpusbased word similarity and string similarity. ACM Transactions on Knowledge Discovery from Data, 2008, 2(2): 1-25
[11]Li Yuhua, McLean D, Bandar Z, et al. Sentence similarity based on semantic nets and corpus statistics. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(8): 1138-1150
[12]Tsatsaronis G, Varlamis I, Vazirgiannis M. Text relatedness based on a word thesaurus. Journal of Artificial Intelligence Research, 2010, 37(1): 1–40
[13]Gu Yanhui, Yang Zhenglu, Xu Guandong, et al. Exploration on efficient similar sentences extraction. World Wide Web, 2014, 17(4): 595-626
[14]Martins B, Silva M J, Andrade L. Indexing and ranking in GEO-IR systems // Proceedings of the Workshop on Geographic Information Retrieval. Bremen, 2005: 31–34
[15]Fagin R, Lotem A, Naor M. Optimal aggregation algorithms for middleware // Proceedings of ACM Symposium on Principles of Database Systems. Santa Barbara, 2001: 102–113
[16]Guttman A. R-trees: a dynamic index structure for spatial searching // Proceedings of ACM SIGMOD International Conference on Management of Data. Boston, 1984: 47-57
[17]Hjaltason G R, Samet H. Distance browsing in spatial databases. ACM Transactions on Database Systems, 1999, 24(2): 265-318
[18]Cheng Z, Caverlee J, Lee K, et al. Exploring millions of footprints in location sharing services // Procee-dings of International Conference on Web and Social Media. Barcelona, 2011: 81–88
Similar Spatial Textual Objects Retrieval Strategy
GU Yanhui1,2,†, WANG Daosheng3, WANG Yonggen1,2, LONG Yunfei4, JIANG Suoliang1,2, ZHOU Junsheng1,2, QU Weiguang1,2
1. School of Computer Science and Technology, Nanjing Normal University, Nanjing 210023; 2. Jiangsu Research Center of Information Security & Privacy Technology, Nanjing 210023; 3. School of Chinese Language and Culture, Nanjing 210097; 4. Department of Computing, The Hong Kong Polytechnic University, Hong Kong; † E-mail: gu@njnu.edu.cn
Based on the efficiency and effectiveness issue of traditional simiar spatial textual objects retrieval, a semantic aware strategy which can effectively and efficiently retrieve the top-similar spatial textal objects is proposed. The efficient retrieval strategy which is based on spatial textual objects is built on a common framework of spatial object retrieval, and it can satisfy the efficiency and effectiveness issues of users. Extensive experimental evaluation demonstrates that the performance of the proposed method outperforms the state-of-the-art approach.
spatial textual object; semantic similar; top-
10.13209/j.0479-8023.2016.008
TP391
2015-06-19;
2015-09-03; 网络出版日期: 2015-09-30
国家自然科学基金(61272221, 61472191)、国家社会科学基金(11CYY030, 10CYY021)、江苏省社会科学基金(12YYA002)和江苏省高校自然科学基金(14KJB520022)资助
