基于主题模型的微博话题检测算法
2016-10-11黄华军谭骏珊秦姣华
黄华军,谭骏珊,秦姣华
基于主题模型的微博话题检测算法
黄华军,谭骏珊,秦姣华
(中南林业科技大学计算机与信息工程学院,湖南长沙410004)
微博数据的实时、大规模、短文本以及富含噪声等特征为话题检测带来新的挑战,传统向量空模型(VSM)表示文本无法很好地对其进行建模。基于此,提出一种基于主题模型的微博话题检测算法。首先,对微博数据构建文档词条矩阵和词语关联矩阵来提取主题词;然后,对主题词进行聚类,得到主题模型;最后,利用文本与主题模型相互匹配实现文本聚类,从而达到话题检测的目的。实验结果表示,该算法能有效地进行话题聚类并检测出话题,在最佳参数组合条件下,其各类别的平均值达到95%以上。
话题检测;主题模型;文档词条矩阵;词语关联矩阵
1 引言
在Web 2.0时代,以微博为典型代表的社交网络应用取代传统媒介,占据了信息传播的主导位置。微博门槛低、易使用、方便快捷等特点,吸引一大批网民用户,使其产生的网络在线数据呈爆炸性趋势增长[1]。一条信息通过微博平台能够在短时间传播并影响到数百万的用户。相比传统媒体,微博在信息传播过程中的传播时效与传播广度都大大的增强。与此同时,一些虚假信息通过社交网络平台的传播也能在短时间造成社会恐慌、用户财产损失等问题。社会上许多突发性话题,往往在微博应用上首发,凭借好友转发机制迅速传播,引起社会广泛共鸣,产生巨大的社会影响。因此,微博话题检测技术,对于社会热点话题发现、网民意见感知、舆情检测、应急处理具有积极意义[2]。
微博话题以140字以内的文本信息、图片、影音等多媒体内容,展示个人最新动态,话题分享。这些数据具有时效性、稀疏性、奇异性和冗余性等特点[3, 4]。同时,这些数据信息的表现形式也发生了变化且凌乱无序,许多有价值的信息都被湮没在大量冗余信息中,从而导致提取和管理有用信息越来越困难。对微博话题检测,不仅可以过滤无效信息、提高内容质量、改善用户体验,更能起到监测、舆情控制、观点挖掘的作用。
话题检测是一种信息挖掘技术,从大量数据中挖掘出相关信息,为后续研究提供基础[5]。传统方法对文本进行话题检测的一般思路是:主题词提取、文本表示、文本相似度计算、文本聚类、话题检测。1) 提取主题词。话题是由主题词来体现的,从文本中提取能表达主题的关键词集合到一起,能很好地表达出文本所描述的话题。其中,最常用的是TF-IDF权重计算算法[6];通过建立词库来进行主题词提取也是一种比较常见的方法[7]。2) 文本表示。目前,文本表示大都采用向量空间模型,通过主题词来组成向量表示文本,进而构成一个向量空间[8]。3) 文本相似度计算是度量文本间距离的一种有效途径,用向量空间模型表示文本后,一般采用余弦定理的方法来计算其相似度,也有不少学者采用其他方法来进行计算[9, 10]。4) 文本聚类是文本信息处理方面常用的一种方法,已比较成熟,其中,比较常用的有-means[11]、层次聚类[12]等。5) 话题检测的实质是文本聚类,也有一些话题模型,如最常用的LDA主题模型[13]。
传统向量空间模型忽视了中文的“同义”、“多义”及高维稀疏向量问题,因而,在微博话题检测过程中准确率和速度不尽人意。其次,传统的话题检测技术基本都是针对新闻报道进行研究的,这些新闻报道的文本格式比较规范,篇幅较为统一,与现在的微博数据特征差异很大,使传统的文本处理方法已经不再适合对微博数据进行处理。基于此,本文提出一种基于主题模型的文本聚类方法来进行话题检测,通过提取主题词来进行文本聚类,可以有效解决微博数据的话题检测。
2 微博文本预处理
微博文本预处理主要包括无效微博过滤、文本提纯、中文分词并标注词性、过滤停用词等。具体步骤流程如图1所示。
无效微博过滤:在文献[2]中提到,微博中存在一些无效微博,即没有任何话题性、主题性的微博文本,此类微博文本通常由很少的字数组成,基本是由各种表情、符号或链接组成,如“❁❁❁❁很百搭http://weibo.com/5081446387”之类的微博。
文本提纯:微博文本中存在大量与主题无关的表情、符号、链接、图片等,如新浪微博中@用户名提到用户,并通知对方,//@用户名则表示转发某用户微博标记,这些符号都与微博内容无关,称这些为噪声数据,在文本处理中,这些噪声数据是与实验处理无关的数据,因此,需要去掉噪声数据,对文本进行提纯。
中文分词:由于中文文本处理的基本单位是词语,且中文文本并不像英文中单词之间都会用空格分开,中文文本中只有句子、单位之间才会用标点符号将其分开,因此,首先需要对中文文本进行分词操作。中科院ICTCLAS工具对文本进行分词操作,并标注词性。
过滤停用词:人类语言中通常包含很多功能词,与其他词相比,这些功能词没有特别实际含义,如汉语语言中的“的”、“啊”、“呀”等词。这些词通常用于连接句子成分或表达说话者的感情、强调语调等用途,因此称为停用词。停用词的存在不仅降低实验处理结果的正确率,且由于停用词数量众多,导致文本矩阵存在严重的高维稀疏等问题,从而影响实验的性能。因此,需要将停用词进行过滤,保留有用的词语作为特征词。停用词主要分为以下3类。
1) 语气词、无用词等:这些词在所有文本集中出现的频率都比较高,却没有实际的意义,如“的”、“啊”、“嗯”,“哦”,“为了”、“而且”等。这些词在文本中只是起到支撑文本句子或增强语调等作用,并不构成任何文本话题因素。
2) 话题性较小的词:由于词性的不同,其所包含的信息量也会有所不同。一条微博文本中的话题信息基本上都是由文本中的名词、动词和形容词所表示,因此,为了减少特征词的数量,提高算法的效率,实验选择保留名词、人名、地名、机构团体名、其他专名、动词、副动词、名动词、处所词、名形词这 10 类词性的词作为特征词,除此之外的其他词,都作为无用词过滤掉。
3) 出现频次过低的词:在所有文本分词后的词语集合中,有些词可能只在某一条微博文本数据中出现一次,可以将该词归为无效词,从而对这些无效词进行过滤。
3 话题检测模型
3.1 主题模型
关键词提取是构建主题模型的基础,主题模型的构建则是话题检测最重要的一步。主题模型,顾名思义,就是对文字中隐含主题的一种建模方法。例如,“苹果”这个词的背后既可以表示苹果公司的主题,也可以表示水果的主题。当苹果与乔布斯等词一起出现时,那此处苹果基本可以设定为苹果公司这一主题,从而认为它们是相关的。由此可知,通过词语之间隐含的一种相关性,可以将主题分类开来。受此启发,本算法利用主题词之间的关联性,生成词语关联矩阵,推断出词语之间的关联程度,找出不同的主题,从而实现对话题的检测目标。整个过程如图2所示。
1) 提取关键词
微博文本信息短小,限制在 140 字以内,且包含文本、图片、链接、视频、特殊符号等多种元素,使微博文本呈现为碎片化的信息、表达方式随意、内容多样,从话题角度分为有话题微博和无话题微博,从内容角度分为评论性微博与描述性微博。其中,无话题微博包括情感宣泄类、名言警句类等。而对于其他话题微博,通过对微博话题文本进行研究分析得出,话题类微博中通常会包含一些与话题相关的关键词,因此,在一定数量的话题微博下,这些关键词出现的次数必定会高于一些其他修饰词,而在对话题类微博进行话题检测时,常常就只需要对这些与话题有关的词进行分析,因此,首先提取出这些出现频次高的、与话题相关的关键词,可以有效降低数据处理的维度,并减少计算量,提升实验处理的效率等。图3是对实验测试数据中保留的高频词所做的一个词云,其中,词语显示越大,表明该词出现次数越多。选取阈值为100,当一个词语出现次数超过100时,则将其视作高频词,称为关键词。由此,可以给出关键词的定义如下。
2) 文档词条矩阵
文档词条矩阵的行与列同样分别表示文本与词语,但是,该矩阵中的词语由经过提取后的关键词构成,且每一个元素的取值为0或1,当某元素所在列对应的词在所在行对应的文本中出现时,则该元素取值为1;否则为0,其含义表示的是文档中词语出现的情况。其定义与形式化的表格描述如下。
3) 词语关联矩阵
从上述提到的文档词条矩阵分析可知,从文档词条矩阵的列,即词语的角度考虑,对于每一个出现过该词语的文本,必定会出现一些其他关键词,这些关键词都与该词共同出现过,则表示这些词语具有相关性,称其相互关联。当2个词语在文档中共同出现的次数多时,表示其具有强关联性。由此可知,此处的词语关联矩阵的行和列都表示词语,那么,矩阵中每一个元素的值则表示该元素所在行对应的词语与所在列对应的词语同时出现在文档中的次数。其定义与形式化的表格描如下。
4) 主题词聚类
通过对话题微博内容分析可知,话题类微博包含的字数可多可少,这些微博中可能只包含一个或包含多个与话题相关的关键词;而对于类别相近的一些话题,可能存在一个关键词同时与2个话题的相关。包含多个关键词的话题微博可能具有两面性:一方面这些关键词更具有类别代表性;另一方面,这些关键词中存在与多个话题相关的词,导致话题类别不够明确。由此可知,对于同一类的微博话题,其文本中出现的词基本都是关联性强的词语;而对于不同类别的微博话题,文本中出现的词关联程度则会相当小。于是,可以通过提取这些关联性强的关键词,然后,对这些词进行聚类分析,就可以得到每一个类别对应的关键词,此时,称这些关键词为主题词,定义如下。
通过对话题主题词进行分析,可得以下3点性质。
①当一个话题出现多个主题词时,则这些主题词共同出现的次数必定比跟其他词出现的次数要高。
②当一个话题中只有一个主题词时,则其单独出现的次数比与其他任何词共同出现的次数要高出很多。
③当一个主题词同时出现在多个内容相近的话题中时,该词与这些话题中其他有区别性的主题词共现次数均多,则将此主题词定为无效主题词,不具备区分效果,将其除去,不作考虑。
定义5 当一个主题词和关联性最强的主题词所关联的次数除以与该主题词有关联的其他所有主题词数量之和的值不超过时,则定义该主题词为无效主题词。
对于每一个主题词,与其关联性强的主题词基本是属于同一话题,再设定阈值参数,对于每一个主题词,分别选取与其关联关系最强的前个主题词进行分析。对每一个主题词之间的强关联词集合进行交集运算,若交集不为空,则判断这2个主题词表示为同一话题;否则,表示不同话题。由此,实现对主题词的聚类操作,整个模型构建的具体流程如图4所示。

图4 主题模型算法流程
算法1 基于词语关联矩阵的主题词聚类
输出:聚类后的各类主题词集合
}else{
}
}
3.2 话题检测
文本聚类是话题检测的前提,话题检测技术的本质就是无监督的文本聚类,即在无人工干预的情况下,通过判断一个文本是否属于已有话题来进行归类。通过文本聚类后,找到聚类类别,从而提取话题,达到话题检测结果。由上述可知,主题模型创建后,可以得到各类别话题的主题词,因此,可以根据文本与各类话题的主题词匹配情况来确定各文本所属的话题类别,从而实现话题聚类。假设设定阈值参数,当文档中出现该类主题词的数量不小于时,该文档属于该类话题,从而实现话题检测。即通过利用中每一个文档的词语与这些归好类的主题词进行对比匹配,当时,定义该文本属于这个话题,其中,表示的是取交集后的个数。
4 实验结果与分析
4.1 实验准备
实验数据取自中国计算机学会信息网科研数据平台,包含14个热点话题,共3 455条微博文本,各话题内容的数量如表1所示。

表1 微博话题及其数量
实验评估采用信息检测领域最常用的3个评价指标:准确率(precision)、召回率(recall)和综合评价指标值(-value)。准确率是指结果中有多少是准确的;召回率就是指所有准确的结果中有多少被检测出来。是准确率与召回率的综合评价参数,设1为检索到的正确文档数,为所有的正确文档数,为所有检索到的文档数。具体计算公式分别如下
4.2 结果分析
首先,读取微博文本数据,对其进行预处理,得到有效词4 987个,再提取文本的关键词,得到112个关键词,从而大大缩减了文本处理的维度问题。再根据关键词构造文档词条矩阵,此时,可知文档词条矩阵为一个3 455行、112列的二维矩阵,并由此可以得到一个112×112的词语关联矩阵。从矩阵大小来看,该算法能有效解决传统方法中存在的高维稀疏等问题。

表2 不同参数组合条件下各类话题的准确率、召回率和F值
图5给出了各参数组合条件下所有类别值的平均值曲线。由图5可知,该算法在不同的参数取值条件下,平均值的取值变动范围很大,通过实验数据得出,当参数取值组合为,,时,各话题类别的值取平均值最好,其平均值达到95.8。此时,各个类别的准确率、召回率与值取值情况如图6所示。

图5 各参数取值组合条件下F平均值取值情况
由上述知,通过关键词提取后,关键词的数量是112个,其按照出现的频次从大到小排列分别为:光大、证券、台风、北京、别墅、尤特、中国、李宗伟、楼顶、林丹、流星雨、强台风、龙王、外婆、事件、李天一、乌龙、婚礼、埃及、登陆、广东、影响、新闻、视频、网友、暴雨、出现、交易、地震、拆除、分享、姚贝娜、中心、记者、美国、书法、声音、表示、昌都、酒吧、期货、斯诺登、假山、曝光、冠军、支持、时间、张必清、马尔代夫、部门、高温、羽毛球、鸡蛋、问题、外孙、泰国、位于、进行、决赛、梦鸽、顶盖、消息、流星、风力、看到、预计、发生、世界、市场、地区、小时、安全、发布、微博、造成、报道、死亡、火焰山、关注、棱镜、郑钧、对手、系统、教授、西藏、刘芸、广州、暴涨、天气、股市、预警、工作、阳江、林育群、成为、律师、行动、进入、山庄、比赛、广西、海面、地表、人员、媒体、南海、小区、政府、投资、现场、同志、希望。得到最佳参数取值后,主题模型中得到的关于各个话题类别的关键主题词如表3所示。

表3 各个话题类别的主题词
由表3可知,每一个话题所对应的主题词均能很好地代表此类话题,表明该主题词的主题性非常明确。从上面关键词中看到,“中国”跟“事件”等出现频次很高的一些词没有出现在对应话题的主题词中,通过对这些主题词进行分析得到,这些均属于多话题性主题词,如“中国”一词,在话题#中国好外婆#、#姚贝娜vs林育群#、#光大证券乌龙事件#中均有出现,且出现次数不集中;“事件”一词分别在话题#光大证券乌龙事件#、#斯诺登棱镜事件#中出现,且出现次数差不多,此类词明显为多话题性主题词,不具备区分话题类别的价值,将其舍去。
在确定参数及性能后,采用通过欧氏距离计算得到的层次聚类及-means聚类方法对相同实验数据进行对比实验操作,各自的聚类结果分别如图7和图8所示,综合对比结果如图9所示。
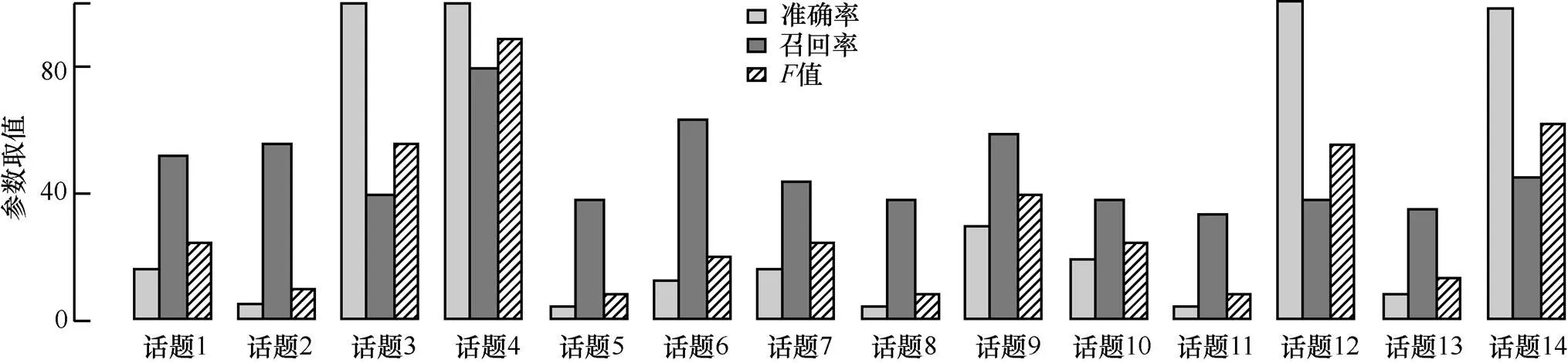
图7 层次聚类结果

图8 k-means聚类结果

图9 3个实验对比结果
由图9可知,主题模型算法针对该实验数据进行操作得到的结果明显优于层次聚类及-means聚类方法。通过对实验数据进行分析可知,在经过预处理后,根据这些短文本创建向量空间模型,再分别利用欧氏距离进行距离计算从而进行层次聚类和-means聚类,由于短文本数据具有很大的稀疏性,使其在利用向量空间模型进行计算过程中存在较大的误差,导致普遍准确率等都偏低。
5 结束语
针对传统话题检测技术处理微博数据的不足,提出了一种基本主题模型的文本聚类方法进行话题检测。以微博数据作为研究对象,详细分析了微博文本的特征,得到主题词在话题性微博文本中的重要性,从而推断可以从主题词的角度进行研究。首先,对预处理后的文本提取出关键词,降低文本表示的维度,减小计算量;然后,由提取的关键词构建文档词条矩阵,分析每一个关键词在文本中出现的情况;其次,由文档词条矩阵分析总结出共同出现的词语之间的关系,统计每一对共同出现的词语及其共现的次数,并以此构造一个词语关联矩阵;再次,根据同一话题中出现的词语关联性最强的特点,对词语关联矩阵中的强关联性词语集合取交集运算,将同一话题的主题词聚为一类,不同话题的主题词则分为不同类,此时主题模型构建完成;最后,利用文本与主题模型中已经归好类别的主题词进行匹配,即可得到文本的类别,从而实现话题检测。实验结果表明,该方法能取得较好的效果,在最佳参数组合的条件下,其各类别的平均值达到95%以上。由于现在网络技术的发展,有海量的短文本数据存在在线网络上,因此,下一步的研究工作将考虑在大数据环境下,对其进行话题检测技术的研究,并尝试将该方法运用到大数据平台下。
[1] 王仲远, 程健鹏, 王海勋, 等. 短文本理解研究[J]. 计算机研究与发展, 2016, 53(2):262-269.
WANG Z Y, CHENG J P, WANG H X, et al. Short text understanding: a survey[J]. Journal of Computer Research and Development, 2016, 53(2): 262-269.
[2] 贺敏, 杜攀, 张谨, 等. 基于动量模型的微博突发话题检测方法[J]. 计算机研究与发展, 2015,52(5):1022-1028.
HE M, DU P, ZHANG J. et al. Microblog bursty topic detection method based on momentum model[J].Journal of Computer Research and Development,2015, 52(5): 1022-1028.
[3] 刘全超, 黄河燕, 冯冲. 基于多特征微博话题情感倾向性判定算法研究[J]. 中文信息学报, 2014, 28(4): 123-131.
LIU Q C, HUANG H Y, FENG C.Multi-feature based sentiment orientation identification algorithm for micro-blog topics[J]. Journal of Chinese Information Processing, 2014, 28(4): 123-131.
[4] 程俊霞, 李芝棠, 邹明光, 等. 基于SVM过滤的微博新闻话题检测方法[J]. 通信学报, 2013, 34(Z2): 74-78.
CHEN J X, LI Z T, ZOU M G, et al. Novel topic detection method for microblog based on SVM filtration[J]. Journal of Communications, 2013, 34(Z2): 74-78.
[5] NIST. The 2003 topic detection and tracking task definition and evaluation plan[EB/OL]. http://www.nist.gov/speech/tests.tdt/tdt2003/ evalplan.html.
[6] 周学广, 高飞, 孙燕. 基于依存连接权VSM的子话题检测与跟踪方法[J]. 通信学报, 2013, 34(8): 1-9.
ZHOU X G, GAO F, SUN Y. Sub-topic detection and tracking based on dependency connection weights for vector space model[J]. Journal of Communications, 2013, 34(8):1-9.
[7] 付艳, 周明全, 王学松, 等. 面向互联网新闻的在线事件检测[J]. 软件学报, 2010, 21(Z): 363-372.
FU Y, ZHOU M Q, WANG X S, et al. On-line event detection from web news stream[J].Journal of Software,2010, 21(Z): 363-372.
[8] 郝文宁, 冯波, 陈刚, 等. 基于领域本体的文档向量空间模型构建[J]. 计算机应用研究, 2013, 30(3): 764-767.
HAO W N, FENG B, CHEN G, et al. Document vector space model construction based on domain ontology[J].Application Research of Computers, 2013, 30(3): 764-767.
[9] PHUVIPADAWAT S, MURATA T. breaking news detection and tracking in twitter[C]//2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Toronto. c2010: 120-123.
[10] YANXIANG H, YE T, QIANG C, et al. Summarizing microblogs on network hot topics[C]//2011 International Conference on Internet Technology and Applications. c2011: 1-4.
[11] 谢娟英, 高红超. 基于统计相关性与-means的区分基因子集选择算法[J]. 软件学报, 2014, 25(9): 2050-2075.
XIE J Y, GAO H C. Statistical correlation and-means based distinguishable gene subset selection algorithms[J]. Journal of Software, 2014, 25(9): 2050-2075.
[12] DAI X Y, CHEN Q C, WANG X L, et al. Online topic detection and tracking of financial news based on hierarchical clustering[C]//2010 International Conference on Machine Learning and Cybernetics, Qingdao. c2010: 3341-3346.
[13] ZHAO W X, JIANG J, WENG J, et al. Comparing twitter and traditional media using topic models[M]//Advances in Information Retrieval. Berlin: Heidelberg, 2011: 338-349.
Micro-blog topic detection algorithm based on topic model
HUANG Hua-jun, TAN Jun-shan, QIN Jiao-hua
(College of Computer and Information Engineering, Central South University of Forestry & Technology, Changsha 410004, China)
Micro-blog data has the characteristic of real-time, volume, short-text, and noise-rich. So it is a challenge for the traditional topic detection technology. A novel micro-blog topic detection algorithm based on topic model was proposed. Firstly, the micro-blog data was expressed as text word matrix and word relation matrix. The topic word was extracted from the two vectors. Secondly, the topic model was obtained with clustering. Finally, the topic detection of micro-blog was obtained by clustering text and topic model. Experimental results show that the algorithm proposed can effectively detection the text topic, and with the best parameter group of precision, recall rate,, and the valueis about 95%.
topic detection, topic model, text word matrix, word relation matrix
The National Natural Science Foundation of China (No.61304208), The Natural Science Foundation of Hunan Province (No.13JJ2031),Youth Scientific Research Foundation of Central South University of Forestry &Technology (No.QJ2012009A)
TP391
A
10.11959/j.issn.2096-109x.2016.00049
2016-04-13;
2016-05-06。
黄华军,hhj0906@163.com
国家自然科学基金资助项目(No.61304208);湖南省自然科学基金资助项目(No.13JJ2031);中南林业科技大学青年科学研究基金资助项目(No.QJ2012009A)
黄华军(1978-),男,湖南宜章人,博士,中南林业科技大学教授、硕士生导师,主要研究方向为网络与信息安全、网络钓鱼防御。

谭骏珊(1963-),男,湖南益阳人,博士,中南林业科技大学教授、博士生导师,主要研究方向为数据库信息与管理、数据挖掘。
秦姣华(1973-),女,湖南益阳人,博士,中南林业科技大学教授、硕士生导师,主要研究方向为网络与信息安全、加密图像检索。

