SQL-DFS:一种基于HDFS的海量小文件存储系统
2016-10-10马志强杨双涛张泽广
马志强,杨双涛,闫 瑞,张泽广
(内蒙古工业大学信息工程学院,呼和浩特 010080)
SQL-DFS:一种基于HDFS的海量小文件存储系统
马志强,杨双涛,闫 瑞,张泽广
(内蒙古工业大学信息工程学院,呼和浩特 010080)
针对Hadoop分布式文件系统(Hadoop distributed file system,HDFS)进行小文件存储时NameNode内存占用率高的问题,通过分析HDFS基础架构,提出了基于元数据存储集群的SQL-DFS文件系统.通过在NameNode中加入小文件处理模块实现了小文件元数据由NameNode内存到元数据存储集群的迁移,借助关系数据库集群实现了小文件元数据的快速读写,并对小文件读取过程进行优化,减少了文件客户端对NameNode的请求次数;通过将部分DataNode文件块的校验工作交由元数据存储集群完成,进一步降低了NameNode节点的负载压力.最终通过搭建HDFS和SQL-DFS实验平台,对HDFS和SQL-DFS 2种架构进行了小文件读写的对比测试,实验结果表明:SQLDFS在文件平均耗时(file average cost,FAC)和内存占用率方面均明显优于原HDFS架构,具有更好的小文件存储能力,可用于海量小文件的存储.
Hadoop分布式文件系统(HDFS);元数据存储集群;小文件;元数据;内存占用率
Hadoop[1]在云计算领域内的广泛使用,使得其已经成为海量数据并行处理的标准.Hadoop分布式文件系统(Hadoop distributed file system,HDFS)作为Hadoop的关键技术之一,其原型来自于谷歌公司(Google)的GFS文件系统,可用于构建大规模、可扩展、高容错的分布式存储平台.HDFS开源的特性允许用户根据自身的业务需求对HDFS进行开发和扩展,使得其在雅虎(Yahoo)、百度、阿里巴巴、FaceBook及Twitter等公司内得到广泛应用.
HDFS在设计之初目的就是为了解决大文件的存储与处理,取得的结果也令人满意.然而在实际的应用系统中存在着大量的小文件,直接采用HDFS进行存储存在以下问题:加载小文件的元数据信息需要占用NameNode节点的大量内存;用户在读取大量小文件时需要频繁地访问NameNode,严重影响NameNode节点的IO性能.
为解决上述问题,本文提出了一种基于关系数据库集群的海量小文件存储方案,通过将集群内小文件的元数据文件转化成数据库记录存储到数据库集群中,可以很大程度减少NameNode节点上元数据文件大小,降低节点的内存使用率,并且通过采用数据库主从复制、读写分离技术,实现元数据存储集群请求的负载均衡,缩短小文件元数据记录的查询时间,进一步提高小文件的读写效率.
1 相关工作
1.1HDFS文件系统
HDFS分布式文件系统采用Master/Slave架构,集群内通常由一个名称节点(NameNode)和多个数据节点(DataNode)组成,主要包括 3个部分:NameNode、DataNode和客户端,具体如图1所示.其中NameNode是整个分布式文件系统的管理者,主要负责管理文件系统的命名空间、集群配置信息、文件元数据信息和文件块的复制工作.DataNode负责存储文件块以及文件块的元数据信息,并定期向NameNode发送心跳和块报告.客户端则封装了文件的基本操作,是用户访问集群文件的接口[2-3].
HDFS这种主从式的设计很大程度上简化了分布式文件系统的结构,用户在读写文件时无需经过NameNode,直接与DataNode通信即可,并且集群内采用流式文件读写,在大文件的存储及处理上表现出优越的性能.然而也是这种架构设计导致了HDFS对海量小文件存储支持不足.首先HDFS集群在运行期间,所有文件的元数据都保存在NameNode的内存中,即使元数据的存储结构十分紧凑,但海量小文件的元数据信息仍占用大量的NameNode内存,导致了NameNode节点内存占用率高的问题.其次客户端在读取大量小文件时需要频繁地访问NameNode节点,以获取文件的元数据信息,严重影响 NameNode节点的 IO性能.而且DateNode节点文件块报告的检测同样需要占用NameNode节点资源.因此,HDFS集群内海量小文件的存在给HDFS的可扩展性和性能带来一定负面影响.
1.2小文件解决方案
目前针对HDFS小文件存储效率低的问题,研究的总体思路是将小文件合并为大文件,减少文件的个数,从而降低NameNode节点的内存占用率,同时利用索引和缓存技术提高文件的读取速率.主要研究方法分为基于HAR、SequenceFile与MapFile技术的小文件合并和基于数据库技术的小文件合并2类.
1)基于HAR、SequenceFile和MapFile的小文件合并方法
Mackey等[4]最早采用Hadoop Archive技术实现将小文件合并为大文件,有效地降低了HDFS中小文件的数量,然而Hadoop Archive不支持文件删除、修改和追加,当发生文件更改时需要重新创建归档文件,然而创建归档文件的过程需要占用大量的机器资源,频繁地创建归档文件将严重影响集群系统的性能.赵晓永等[5]将SequenceFile技术应用到了海量MP3音频文件的存储,很好地解决了小文件过多时NameNode的内存瓶颈问题,提高了MP3文件的访问效率;刘高军等[6]利用 Redis缓存和SequenceFile技术实现了HDFS中小文件的快速合并存储,并通过缓存保证了小文件的读写效率;余思等[7]采用SequenceFile技术将小文件以队列的形式合并为大文件,从而实现了节省NameNode节点所占内存空间的目的,同时也实现了对合并之后的小文件的透明操作.洪旭升等[8]通过将序列化后的小文件存储至MapFile容器,对小文件进行合并,并通过建立索引,有效降低了文件总数量和提高了文件的访问效率.
上述方案主要思路是通过将小文件合并成大文件同时对小文件索引,然后再将合并的大文件存储到HDFS中,通过这种合并的方式能够很大程度地减少NameNode节点上元数据文件的大小,有效降低NameNode的内存使用率,但难以满足低延迟要求,即使借助索引、缓存技术文件随机读写性能仍无法让人满意.
2)基于数据库的小文件合并
张海等[9]提出了一种基于关系数据库的小文件合并策略,通过append操作将小文件内容按用户追加到用户文件中,利用关系数据库记录小文件在用户文件中的位置,再通过seek操作实现小文件的读取.但目前HDFS对append和seek操作支持不足.刘小俊等[10]将小文件首先集中存储到关系库,当数据库文件达到一定大小再将数据库文件转存至HDFS,而当用户读取文件时,根据用户的请求信息RDBMS将动态地加载数据库文件,然后根据文件的位置信息再读取文件.上述2种解决方案都是借用传统的关系数据库去解决小文件的存储问题,其本质上还是文件合并的过程.朱晓丽等[11]利用新兴的列式数据库HBase进行海量图片的存储,实现了系统层对图片的合并、全局命名,并通过对HFile的Key-Value字节数组结构的完善,实现了图片读取时的自动纠错,提高了系统可靠性,然而基于HBase存储支持的文件大小范围极其有限.
基于上述研究基础,本文跳出小文件合并的思路,提出一种基于关系数据库集群[12-13]的海量小文件存储方案.通过在HDFS中加入小文件处理模块,对集群内的大小文件区分处理,小文件写入时产生的元数据信息转化成记录存储到元数据存储集群,避免了NameNode节点需要加载维持大量的小文件元数据文件,同时利用主从复制、读写分离技术构建高效的元数据存储集群进一步提高了元数据记录的查询速率,使得小文件的读写速率得到了提升.
2 SQL-DFS文件系统
SQL-DFS文件系统模型的核心思想:通过将小文件的元数据信息由NameNode内存迁移到元数据存储集群,从而降低NameNode节点的内存消耗;通过优化小文件读取过程,减少文件客户端对NameNode节点的访问次数;通过将DataNode块报告校验工作转移到元数据存储集群,降低NameNode节点的负载压力;通过建立元数据存储集群实现对小文件元数据记录的快速查询,提高小文件的读写效率.
2.1SQL-DFS系统模型
SQL-DFS的整体架构设计如图2所示,与HDFS架构相比在NameNode节点上新增加了小文件处理模块,整个集群附加了一个关系数据库集群. SQL-DFS包括如下4个部分:客户端、NameNode、元数据存储集群和DataNode.
客户端与NameNode、DataNode以及元数据存储集群进行通信来访问SQL-DFS文件系统.客户端与NameNode通信可访问集群内的元数据信息,SQL-DFS中对文件的读取和查找操作进行了如下优化:当用户进行文件读取和查找时,如果通过文件类型判定客户端请求的文件为小文件,本次元数据请求将不再经过NameNode,直接查询元数据存储集群,从而减少了客户端对NameNode的请求次数,减轻了NameNode的负载压力.在得到文件元数据信息的前提下,客户端与DataNode通信完成文件的读写.
NameNode仍是整个文件系统的决策者和全部元数据的持有者,只是将元数据由内存转存到了元数据存储集群,元数据转存的工作是由新增的小文件处理模块完成的.小文件处理模块的处理过程如下:
1)根据配置文件中的文件块大小设置,对用户写入的文件进行大小性质的判断,即是否属于小文件;
2)小文件写入时,接收NameNode返回的元数据信息并返回到客户端,待文件上传完成后将元数据信息同步到元数据存储集群;
3)文件读取时,如果读取的文件是小文件,则向元数据存储集群中的元数据管理模块请求元数据信息,并返回到客户端;
4)接收来自DataNode的心跳和块报告,将其中小文件相关的部分转发的元数据存储集群的元数据管理模块进行下一步处理.
关系数据库集群主要负责存储小文件的元数据记录,通过配置文件可以指定不同类型的关系型数据库.元数据存储集群通过元数据管理模块向上层提供元数据访问服务,具体处理过程为:
1)接收来自客户端的元数据查询请求;
2)接收NameNode的元数据记录同步请求;
3)接收来自NameNode的部分块报告,与数据库集群中的记录匹配对比,并将结果返回到NameNode.
2.2元数据存储集群
元数据存储集群的架构设计如图3所示,主要存储小文件信息、小文件与Block的对应关系和Block与DataNode节点的对应关系.集群通过元数据管理模块将数据库接口提供给客户端和NameNode,接收二者的访问请求.在接收到访问请求后,根据数据库语句的关键字判断该访问请求是读操作还是写操作.如果是读操作,则将该请求分发到相对空闲的从数据库处理;如果是写操作,则该请求只能由主数据库处理,而且必须以事务方式进行,主数据库在完成请求后对从数据库进行同步[14-15].
2.3SQL-DFS文件操作
在改进后的HDFS架构中,提供了对文件全面的操作支持,如文件上传、下载、查找、删除等常规操作.以文件上传和文件下载过程为例,分步骤对改进后的HDFS工作流程进行详细说明.
2.3.1写文件操作
客户端在写入文件时,NameNode首先根据文件大小对写入的文件进行判断,如果写入的文件属于小文件,则执行图4中的A、B、C、D、E和F步骤.否则,将执行A、G、H、D和I步骤.各个步骤如下:
步骤A 文件写入请求由文件判别模块进行判别处理,如果文件大小小于配置文件中设定的文件阈值,则判定该文件为小文件,否则判定为普通文件.
步骤B 将小文件转交由小文件存储模块进行存储,NameNode节点将为该文件分配空间.
步骤C 小文件存储模块元数据信息返回到客户端,完成文件写入的准备工作.
步骤D 客户端根据元数据信息将文件写入到指定的DataNode.
步骤E 客户端返回文件写入确认信息.
步骤F 小文件存储模块将小文件信息、元数据信息数据写入到数据库集群.
步骤G 普通文件由通用文件存储模块进行存储,NameNode节点将为该文件分配空间,并将产生的元数据信息写入到元数据文件.
步骤H 通用文件存储模块将元数据信息返回到客户端,完成文件写入的准备工作.
步骤I 客户端返回文件写入确认信息.
2.3.2读文件操作
文件读取时,NameNode首先根据请求信息对该请求进行判断,如果请求的文件属于小文件,则执行图5中A、B、C、D和E步骤,否则将执行A、F、G和E步骤.各个步骤解释如下:
步骤A 文件读取请求信息交由文件判别模块进行判别处理,如果文件大小小于配置文件中设定的文件阈值,则判定该文件为小文件,否则判定为普通文件.
步骤B 小文件存储模块接收文件请求信息,解析得到小文件的相关信息.
步骤C 从数据库集群查询得到小文件的元数据信息.
步骤D 将小文件元数据信息返回到客户端.
步骤E 客户端根据名称节点返回的元数据记录到指定的数据节点上读取文件.
步骤F 将文件请求信息转发到常规文件处理模块进行处理.
步骤G 从名称节点内存中查询得到元数据记录,并返回到客户端.
3 实验设计与结果分析
3.1实验环境与评价指标
为了验证SQL-DFS文件系统模型的性能,本文分别搭建了原HDFS文件系统和SQL-DFS文件系统,并将2种文件系统中的文件块大小均设置为64 MB,副本数为3,硬件配置情况如表1所示.实验所需的测试文件由程序生成得到,总数为500 000个,文件的大小在1 KB~5 MB之间,文件总大小为150.68 GB,文件平均大小为316 KB.

表1 实验环境配置Table 1 Experimental environment configuration
在上述环境中本文共进行了3组实验,分别是:文件写入实验、文件读取实验以及空闲时内存占用对比实验,并在每组实验内分别进行5次不同文件数量下的实验,文件数量依次为:100 000、200 000、300 000、400 000和500 000,文件均从测试文件中随机抽取得到.
本文将文件平均耗时(file average cost,FAC)和空闲时NameNode内存占用率指标作为实验的评价标准,其中文件平均耗时具体定义为
式中:sum为测试文件的总个数;ti为完成第i个文件处理所用时间.FAC代表集群对小文件处理操作的平均用时,FAC值越小说明集群对小文件的处理能力越好.而空闲时NameNode内存占用率通过free命令即可得到,由于NameNode机器仅安装运行HDFS和SQL-DFS,所以本指标可直接说明2种平台下的内存占用情况.
3.2文件写入实验
在文件写入实验中分别将不同数量的文件写入到HDFS和SQL-DFS文件系统中上传,并测得完成写入所需的总时间,表2中给出了实验测得的具体数据.
将表2中的实验结果,按照式(1)处理可得到不同数量的文件写入时的FAC值,将文件数量作为横轴,FAC作为纵轴,便可得到不同平台上传文件时随着文件数量的增加FAC的变化情况,如图6所示.
表2表明随着写入文件数量的增多,HDFS上传同样数量的小文件所需时间明显要多于SQLDFS,HDFS耗时增长更显著.通过图6同样可以发现在SQL-DFS中随着上传文件数量的增加,FAC值变化极为平缓,增速远低于HDFS,说明在SQL-DFS中新写入的文件对集群性能不会产生明显的负面影响,而在HDFS中,新写入的小文件对集群性能产生了明显的负面影响,如当文件达到50万时,SQLDFS的FAC为0.140 23 s,而 HDFS的FAC已达0.218 07 s,高出SQL-DFS 0.077 8 s.
SQL-DFS架构设计在文件数量少的情况下,文件写入性能并没有提高,相比原HDFS架构反而耗时更多,这是由于改进后的架构中加入了小文件判别模块,需要对用户上传的文件进行统一判别,但随着上传文件数量的增多,SQL-DFS架构表现出更好的性能,这是因为原 HDFS的架构设计需要在NameNode节点的内存中加载并维持文件的元数据信息,随着文件的增多元数据占据消耗更多的内存空间,使得系统整体性能下降.而在SQL-DFS中,NameNode节点的内存占用几乎没有变化,所有的元数据信息都转化成表记录存储到了数据库集群内.当上传的小文件约240 000个时,SQL-DFS架构在文件写入时的表现已经优于原HDFS架构,此时原HDFS架构中元数据文件大小为206.7 MB,而SQLDFS架构中元数据文件大小为32.5 MB.
3.3文件读取实验
在文件读取实验中,分别从HDFS、HDFS-HAR以及SQL-DFS文件系统中读取不同数量的文件,并测得读取全部文件所需的总时间,表3给出了实验测得的具体数据.其中HAR列指的是对HDFS中的文件执行归档命令以后再进行文件读取的耗时.
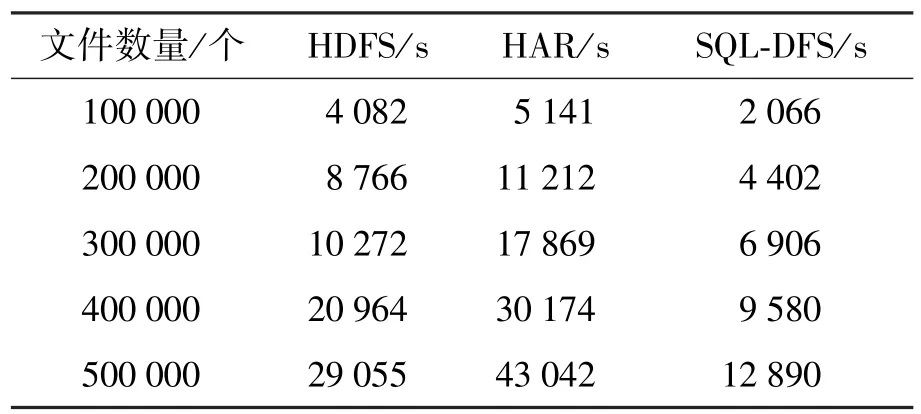
表3 不同平台下文件的读取耗时Table 3 Reading time of the file on different platforms
将表3中的实验结果,按照式(1)处理可得到不同数量文件读取时的FAC值,将文件数量作为横轴,FAC作为纵轴,便可得到不同平台读取文件时随着文件数量的增加FAC值的变化情况,如图7所示.
通过图7可以发现,SQL-DFS在文件读取方面性能有了显著的提高,用时明显低于同等文件数量下的HDFS以及归档操作后的HDFS.归档操作后的HDFS虽然节省了NameNode节点内存,但由于需要读取2层索引文件导致其在文件读取性能上表现是最差的.在图7中,SQL-DFS的FAC变化最为平缓,测试文件数量由100 000增加到500 000,FAC值仅增加0.005 1 s,FAC均值约为0.023 1 s,相比HDFS均值(0.048 6 s)降低了0.025 5 s,比HDFSHAR均值(0.065 9 s)低了0.042 8 s.
3.4空闲时内存占用对比实验
每次实验后,通过执行free命令查看到系统的内存占用率情况,具体如图8所示.
通过图8可以发现,SQL-DFS在NameNode内存消耗上表现也是最好的,当文件数目达到了500 000时,原HDFS中NameNode节点内存使用率达33.4%,而SQL-DFS中NameNode节点内存使用率仅有12.5%.
3.5普通文件与大文件读写对比实验
为了验证SQL-DFS在存储普通文件与大文件时的性能,在实验平台上进行了SQL-DFS与HDFS文件系统的对比实验,分别为文件写入实验和文件读取实验.其中实验数据为50个视频文件,文件总大小为62.65 GB,文件平均大小为1.253 GB,过程同小文件对比实验过程一致.
由表4可知,当普通文件与大文件写入时,SQLDFS上传同等数量的文件所需时间比原HDFS文件系统耗时要多,二者的差值仅占总上传时间的2%左右,这是由于SQL-DFS文件系统上传普通文件时,所有上传文件需要统一经由文件判别模块进行文件大小的判定,从而导致了耗时差值.
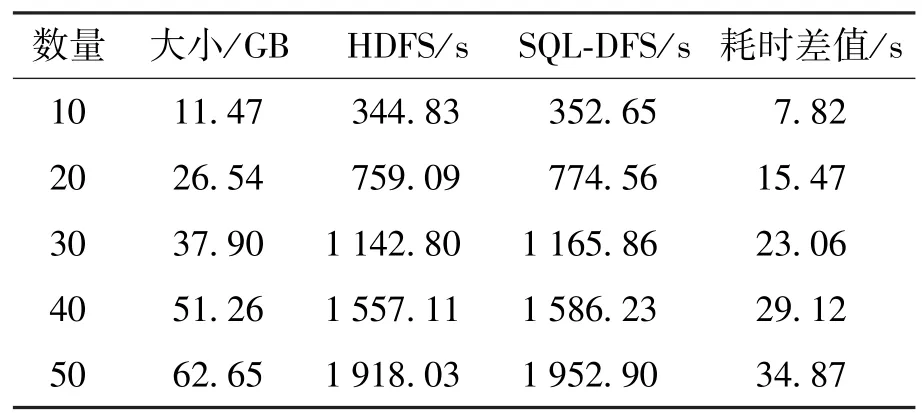
表4 不同平台下普通文件的写入耗时Table 4 Writing time of the ordinary file on different platforms
将表4中的实验结果,按照式(1)处理可得到不同数量的文件读取时的FAC值,将文件数量作为横轴,FAC作为纵轴,便可得到不同平台写入普通文件时随着文件数量的增加FAC的变化情况,如图9所示.
由图9可知,文件数量的增多及文件系统中文件块的增多,导致SQL-DFS和HDFS写入普通文件的平均耗时均有所增加,增加速度都极为平缓,并且二者的差值极小,说明SQL-DFS文件系统中的文件判别模块对普通文件以及大文件的写入带来了极小的负面影响,可忽略不计.在普通文件以及大文件读取时,文件判别模块带来了同样的负面影响,在读取实验的结果中也得到了验证,本文不另作陈述.
4 结论
1)通过在HDFS的NameNode中加入小文件处理模块,将HDFS中部分DataNode文件块的校验工作交由元数据存储集群完成,给出了一种基于元数据存储集群的SQL-DFS文件系统,实现了海量小文件的快速读写.
2)构建了SQL-DFS文件系统,并与HDFS系统进行了多组对比实验,实验结果表明:SQL-DFS文件系统在小文件的读写性能上表现均优于HDFS,可以用于海量小文件的存储.
[1]Apache.Welcome to apache hadoop[EB/OL].(2010-02-27)[2015-04-12].http:∥hadoop.apache.org.
[2]BORTHAKUR D.The hadoop distributed file system:architecture and design[J].Hadoop Project Website,2007,11(11):1-10.
[3]SHVACHKO K,KUANG H,RADIA S,et al.The hadoop distributed file system[C]∥Mass Storage Systems and Technologies(MSST),2010 IEEE 26th Symposium on. Incline Village:IEEE,2010:1-10.
[4]MACKEY G,SEHRISH S,WANG J.Improving metadata management for small files in HDFS[C]∥ Cluster Computing and Workshops,2009.CLUSTER’09.IEEE International Conference on.New Orleans:IEEE,2009:1-4.
[5]赵晓永,杨扬,孙莉莉,等.基于Hadoop的海量MP3文件存储架构研究[J].计算机应用,2012,32(6):1724-1726.ZHAO X Y,YANG Y,SUN L L,et al.Hadoop-based storage architecture for mass MP3 files[J].Journal of Computer Applications,2012,32(6):1724-1726.(in Chinese)
[6]刘高军,王帝澳.基于Redis的海量小文件分布式存储方法研究[J].计算机工程与科学,2013,35(10):58-64. LIU GJ,WANGDA.ResearchofRedisbased distributed storage method for massive small file[J]. Computer Engineering&Science,2013,35(10):58-64. (in Chinese)
[7]余思,桂小林,黄汝维,等.一种提高云存储中小文件存储效率的方案[J].西安交通大学学报,2011,45 (6):59-63. YU S,GUI X L,HUANG R W,et al.Improving the storage efficiency of small files in cloud storage[J]. Journal of Xi’an Jiaotong University,2011,45(6):59-63.(in Chinese)
[8]洪旭升,林世平.基于MapFile的HDFS小文件存储效率问题[J].计算机系统应用,2012,21(11):179-182. HONG X S,LIN S P.Efficiency of storaging small files in HDFS based on MapFile[J].Computer Systems& Applications,2012,21(11):179-182.(in Chinese)
[9]张海,马建红.基于HDFS的小文件存储与读取优化策略[J].计算机系统应用,2014,23(5):167-171. ZHANG H,MA J H.Optimizational strategy of small files stored and readed on HDFS[J].Computer Systems& Applications,2014,23(5):167-171.(in Chinese)
[10] 刘小俊,徐正全,潘少明.一种结合 RDBMS和Hadoop的海量小文件存储方法[J].武汉大学学报(信息科学版),2013,38(1):113-115. LIU X J,XU Z Q,PAN S M.A massive small file storage solution combination of RDBMS and hadoop[J]. Geomatics and Information Science of Wuhan University,2013,38(1):113-115.(in Chinese)
[11]朱晓丽,赵志刚.一种基于HBase的海量图片存储技术[J].信息系统工程,2013(8):22-24. ZHU X L,ZHAO Z G.A massive image storage technology based on HBase[J].Information System Engineering,2013(8):22-24.(in Chinese)
[12]MONTANER H,SILLA F,FRÖNING H,et al.A new degree of freedom for memory allocation in clusters[J]. Cluster Computing,2012,15(2):101-123.
[13]谷震离.关系数据库查询优化方法研究[J].微计算机信息,2006(15):162-164. GU Z L.Research on optimization method for queries in relational database[J].Control&Automation,2006 (15):162-164.(in Chinese)
[14]AKAL F,BÖHMK,SCHEKHJ.OLAPquery evaluation in a database cluster:a performance study on intra-query parallelism[C]∥Advances in Databases and Information Systems.Berlin:Springer,2002:218-231.
[15]CATTELL R.Scalable SQL and NoSQL data stores[J]. Acm Sigmod Record,2011,39(4):12-27.
(责任编辑 吕小红)
SQL-DFS:A Massive Small File Storage System Based on HDFS
MA Zhiqiang,YANG Shuangtao,YAN Rui,ZHANG Zeguang
(School of Information Engineering,Inner Mongolia University of Technology,Hohhot 010080,China)
In order to solve the problem of high occupancy rate of NameNode memory while using Hadoop distributed file system(HDFS)to store massive small files,this paper analyzed the HDFS storage structure and presented a SQL-DFS file system based on metadata storage cluster.In SQL-DFS,in order to move small file metadata from NameNode memory to metadata storage cluster a small file processing module was added in NameNode.In order to improve the reading and writing speed of the metadata,relational database cluster was used,and in order to reduce the time of request for NameNode the reading process of the small file was optimized.To further reduce the load pressure of NameNode,the checking of file block from DataNode was completed by metadata storage cluster.Finally the contrast experiments were carried out between HDFS and SQL-DFS experimental platform.The experimental results show that SQL-DFS in the file average cost(FAC)and memory occupancy rate are significantly better than that of the original HDFS architecture and has better small file storage capacity.It can be used for the storage of massive small files.
Hadoop distributed file system(HDFS);metadata storage clusters;small files;metadata;memory occupancy
TP 391
A
0254-0037(2016)01-0134-08
10.11936/bjutxb2015060040
2015-06-12
国家自然科学基金资助项目(61363052);内蒙古自治区自然科学基金资助项目(2014MS0608);内蒙古自治区高等学校科学研究项目(NJZY12052)
马志强(1972—),男,副教授,主要从事机器学习、数据挖掘、搜索引擎方面的研究,E-mail:mzq_bim@163.com
