一种基于词义降维的主题特征选择算法
2016-09-26粟武林
肖 雷 王 旭 粟武林
1(河北大学电子信息工程学院 河北 保定 071000)2(河北大学数学与计算机学院 河北 保定 071000)
一种基于词义降维的主题特征选择算法
肖雷1王旭1粟武林2
1(河北大学电子信息工程学院河北 保定 071000)2(河北大学数学与计算机学院河北 保定 071000)
在文本特征选择中,由于词语概率空间和词义概率空间的差异,完全基于词语概率的主题特征往往不能很好地表达文章的思想,也不利于文本的分类。为达到主题特征更能反映文章思想这一目的,提取出一种基于词义降维的主题特征选择算法。该算法通过在词林基础上构建“同义词表”,作为词到词义的映射矩阵,构造一个基于词义之上的概率分布,通过LDA提取文本特征用于分类,分类准确率得到了明显提高。实验表明,基于此种方法所建立的主题模型将有更强的主题表示维度,通过该算法基本解决文本特征提取中词语概率和词义概率之间差异的问题。
LDA主题模型主题表示维度
0 引 言
随着计算机对文本表示的不断深入,人们力求更具表现力的方式表达文本本身的语义信息,从早期的潜在语义分析就开始了这方面的探索[1],后来经过实践发现“主题模型”在文本特征表示上应用较为成功[2]。因为它存在坚实的数学基础,与传统的空间向量[3]模型比,通过考虑词语在文档中的共现概率而引入了“主题”维度,使文档表示从概率空间到语意空间得到了延伸。虽然这种“语意”是通过词语出现的概率来间接模拟的,但它容易被扩展,在文本挖掘和信息检索等实际任务中广泛应。而在实践中,如何使这种概率的间接表示更加接近语意的真实表达,主题内部的一致性更强是研究的主要方向。
1 相关工作
到目前为止,大批的学者对概率主题模型进行了各种拓展,实际运用效果大幅提升。以经典的概率主题模型LDA为列,学者们一方面是继续基于无监督主题模型的思想,以缩小文档训练背景为手段而使训练出的主题语意更加聚合。比如使用多粒度的主题建模方法[4],或者进一步简化模型,在句子上使用标准LDA[5]等。而另一个方面是引入弱监督学习,尤其在对新闻网站,博客或者商品的评论中,引入结构化的信息,人为通过先验知识设定标签,使得学习到的主题更加贴近人们实际所关心的方面[6,7],比如一个产品的各个特征,一个新闻事件的各种立场等。但是,由于弱监督学习的扩展性能差,不能在多领域中使用,存在一定的局限性,而无监督训练又存在主题语意聚合度低的缺点。通过认真总结无监督学习的训练规律,以及弱监督学习训练的约束方法,使主题在原有无监督学习的条件下,把底层词语标号修正为词义标号,使其达到弱监督学习中主题聚合度更强的效果。
基于此,本文提出了基于词义之上的概率主题模型,成功将文本中词语的概率相关性和语义相关性融合到一起。通过实验证明,模型的拓展能力进一步增强。
2 概率主题模型
2.1基本思想
概率主题模型是一种基于语料集合上高度抽象和降维的表示模型,是一种从文档中词语的概率空间基于词语共现概率关系人为映射到语意空间的经典模型。模型本身并没有引入任何语意信息和语法信息(不考虑词语顺序或者词义信息),词语在模型里是用一个编号代替,它的思想基础是,某些编号之间共同出现的概率作为唯一的相关性。这种模型充分压缩了原有统计语言模型的维度,且具有良好的统计基础和灵活性。
2.2LDA模型
以经典的LDA[6]模型为例:假设主题在特定文档的分布为P(z),那么特定的单词ω在主题中的分布为P(w/z)。一个文档包含T个主题z,由于每个主题中单词的权重不一样,则文档中的i号单词的可以表示如下:
(1)

布雷在2003年通过在两个多项分布上引入狄利克雷先验。即在文档的主题分布θ(z)和主题的词语分布φ(w)中分别引入Dirichlet先验,Dirichlet先验作为多项分布的共轭先验是一个比较好的选择,它简化了问题的统计推断,多项分布P=(P1,P2,P3,…,PT)之上的T维Dirichlet分布的概率密度可以定义为:
(2)
这样可以在θ(z)分布上引入带超参数α的Dirichlet先验,用来估计他的分布。这种估计方便了模型处理文档集之外的新文本,且便于了模型的参数推理,一个T维的Dirichlet随机变量θ因为它归一性,可以表示成T-1维,所以它有如下的概率密度:
(3)
同理也可以在Φ上引入Dirichet先验,这样整个过程可以简单表示如下:

(4)
图1中超参数α、β可以分别理解为在见到任何文档之前,主题被抽样的频数以及在见到文档集任何词汇之前从主题抽样获得词汇出现的频数。其中文档30给出了一些超参数α、β经验性取值的方法,其中α=50/T,β=0.1。当然也可以通过在主题分布上引入非对称先验和在主题的词分布上引入对称先验可以提高LDA模型对文本的建模能力[8],最后通过Gibbs Sampling[9]或者基于变分法的EM[10]可以求解该模型。

图1 LDA模型图形表示
3 同义词对主题语意聚合度的影响
主题的表示维度是指主题特征词(高概率词)的语意信息表示的广度。直观地说,文档的每个主题词所表达的意思能够概括该主题的更多方面。例如:在关于教育方面这样一个主题特征中:我们希望包含学校、老师、学生、家长、环境等多方面,而不是单纯的一些具有相近意思的高概率词,初中、小学、高中、大学、教师、老师、名师等。这其实只涉及到老师和学校两个方向,这样的主题特征维度较低不利于我们在下阶段的文本表示和分类。
在LDA模型中,模型识别的是词符号出现的权重,不同的词用不同词的序号表示,词语序号之间没有任何相关性,这样纯粹的数学表示有利于文档建模,推理和运算,但也存在一定的问题,比如说在对文档集训练结束后,通过吉布斯采样求解会得到一个词在主题上的分布。假设文档集共有T个主题和N个词汇,那么对于每个主题会被分配成一个N维的归一向量,第i维数代表着i号词对应该主题的权重。如表1所示aij表示第i号词在j号主题中的权重。其中:
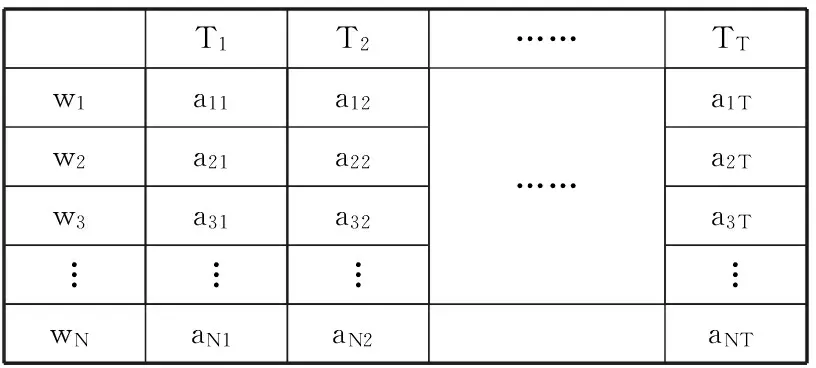
表1 基于词的主题表示
通常,在求解最后,将对每个主题对应的所有词的权重按由大到小排序,权重靠前的词汇为该主题最可能出现的词,作为该主题的特征词,而权重靠后的将被忽略(特征很不明显)。正由于存在这种排序和取舍,主题特征的表现是由权重较高的词汇所反映。在词语空间中,存在一些意思极度相近或者类似的词汇,由于词语的流行程度及个人用词习惯等因素的影响,会使意思极为相近的词在文档中出现的概率很不均等,或者有的语意会用很多相近的词语表达,而有的语意可能只由一个或者很少的词语表达。这种现象在训练数据集规模较大的时候尤为明显,这反映出在词语的概率空间和词义概率空间相比是存在很大差别的。在LDA训练过程中,唯一考虑的是词语出现的概率也即次数,所以这种表示会随着训练集的改变使得主题词汇表示波动较大,主题空间的表示过于数字化和符号化,主题空间和语意空间存在较大的差距。例如:词义X、Y分别有2个和1个词语表示:
词义X(词语A,词语B);
词义Y(词语C)。
假设C在某个主题中的权重为0.017,而A和B在该主题中的权重都为0.01。这样在对词的权重排序中,C是排序靠前的,A、B靠后可能会被舍去,不能作为该主题的特征。但是在词的意思表达空间里,词义1权重显然高于词义2,对主题而言词义2比词义1更加具有代表性。
在文档基于主题的建模中,最理想的表示方式是主题中每个词语所表示的权重能够充分反映该词的词义在主题空间的权重,而不单纯是单个词汇本身的权重,也即是说主题空间中的元素是词义而不单是词语。
从理论上讲,这样的主题空间表示将更加贴近语言的生成规律,拓展性将会更强,因为它不是单纯的词汇概率模型,而是词义的概率模型,在利用主题生成新文档时将更加适合语言的形成规律。基于这种思想,我们在主题空间的概率表示中引入语意信息,把意思相近的词语聚合为一个元素(词义),由原来该意思词语中权重较高的来表示,这样在降低了主题空间维数的同时,更能直观地表示文档,如图2所示。

图2 基于词义的主题建模
4 基于词林的词义聚类
在前面的研究中,利用同义词词林直接过滤文本中同义词的方法[13],虽然能有效地提高特征选择的约简率,但我们可以发现这种方法完全依赖于词林的精度,在提取特征中缺乏机器学习的过程。
由于传统主题空间的元素是词汇,从词汇空间映射到词义空间我们需要构建一个词义相似度较高的同义词表,把意思相同或者相近的词汇聚合成一个元素(词义),这样主题空间由原来的主题→词汇,衍变为主题→词义→词汇,主题的空间维数将进一步降低,对文档的表示也将更符合语法规律,解决这个问题的关键在于针对特定文档生成一个恰当的同义词表。但因为词义在文档中存在太多不确定性,或者上下文中存在一词多义现象,简单的机器学习或者概率统计都难以解决这个问题,目前最常用的同义词识别方法有基于词林的方法[11]、基于知网[16,17]、百科词典的释意以及直接在句子运行LDA[12]等。最精准的同义词表构建方法还是通过人工观测的方法构建不定维数的同义词表,或者基于句法结构分析的同义词识别方法[15],但都不适合于针对于本试验中不断变化和壮大的训练集,这是以后有待研究的问题。为了验证这种设想的可行性,本实验基于哈工大信息检索研究中心同义词词林扩展版的基础之上,通过基于词义相似度的计算方法[11,18],设定词义相似度阈值,形成一个不定维数的同义词表,最后转换成如表2所示的多对一形式同义词表。虽然这种词典在精确度还有提高的余地,但足以证明在语义空间上主题建模的可行性。

表2 同义词词典列举
5 实现步骤
在本实验中,为了检查主题——词义模型的拓展能力,使用复旦大学中文文本分类语料库,从十个大类中各抽取100篇文档共1 000篇文档进行训练。文档建模求解方法采用Gibbs LDA的方法。
第一步分别从语料库的各个类别中抽取100篇文章作为原始文档集合,通过分词,去停用词等先期处理工作后得到一91 012个词组,18 461维的训练集D。
第二步基于哈工大信息检索研究中心同义词词林扩展版进行词义相似度计算[11,18],分别用不同的阈值进行试探,观察同义词表生成的精确度,由于词林本身是基于词义编码分类的,为尽量减小词义的发散程度,本实验阈值取1,生成一个如表2所示的多对一同义词表,共74 653组。
第三步针对训练集合D,利用生成的同义词词典,进行检索替换后得到一个13 151维的词义训练集D′。其维度减少了5510维。
第四步在D上和D′上运行Gibbs LDA,为了便于评价该改进后提取特征好坏,其中主题数取10,α=0.5,β=0.1,迭代次数为1000次,从得到model-final文件中主题特征的分布。
第五步设计一种分类器,分别基于两种主题特征分类进行比较,分析分类结果的好坏。具体过程图3所示。
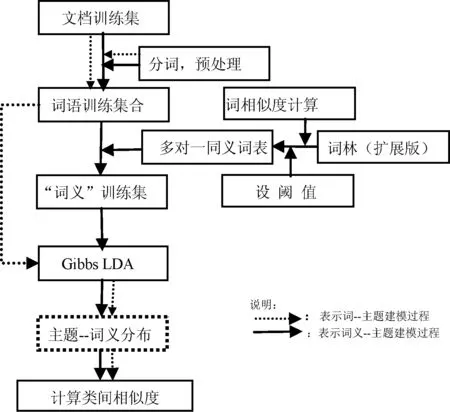
图3 实验流程图
6 实验数据及评价指标
6.1主题特征提取
由于LDA本身是一种文本特征提取方法,本实验主要为它添加了一个生成的同义词词典,因此我们可以通过基于高概率主题词的方法来评价它的好坏。由于每个主题最终会表示成一个N维的一元语言模型,我们对每个主题中的词语根据权重进行排序,权重较高的词汇作为该主题的特征。如表3所示。
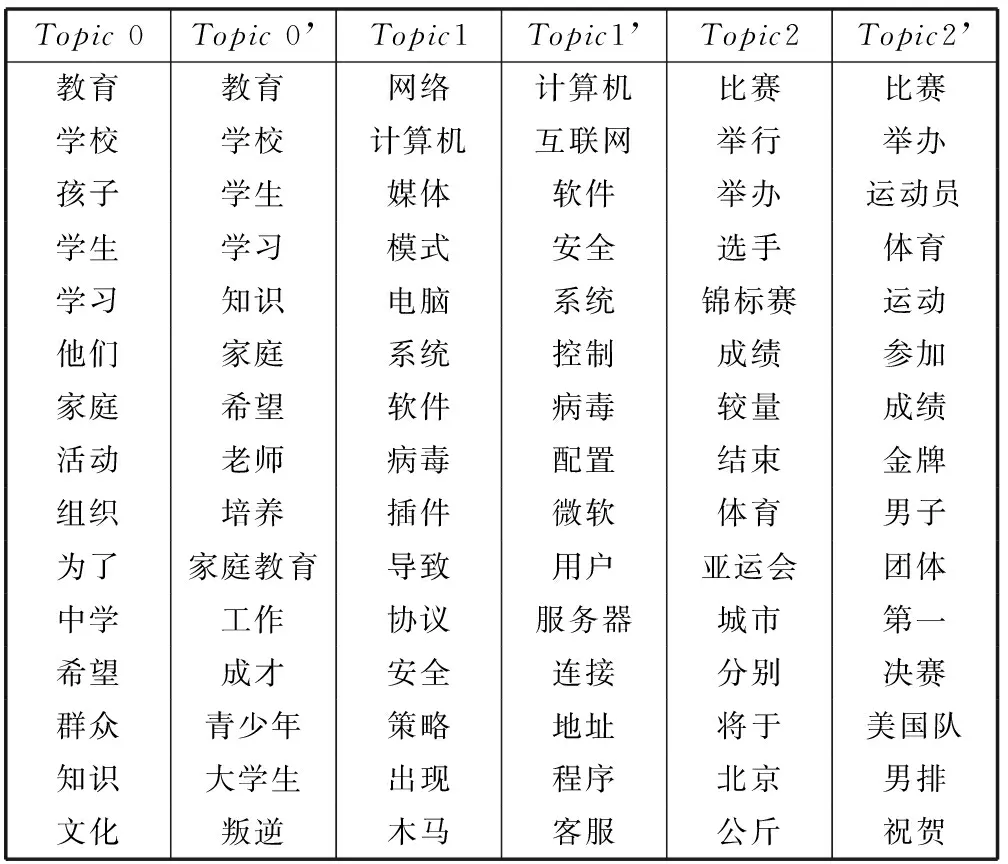
表3 基于词义的主题特征
依照文献[14]构造的语言模型采取人工评测的方法,主要考虑两个方面,第一是主题内部的一致性,即聚合度。第二个方面是文档内部主题分布的一致性。对于这两个任务都是人工评估检查出随机添加词或者主题的难易程度。通过仔细对比我们可以发现,改进后的主题特征聚合度要略高于改进前,改进后的方法主题语意将更加集中,且不存在意思的重复,更有利于提高用户在特征提取和文本分类上的精确度。
6.2分类实验
为了进一步检验基于词义概率模型提取主题特征的效果,我们设计了如下的分类实验:
在测试集相同的基础之上,以SVM分类器作为参考,设计了改进的K近邻分类算法,分别基于词的LDA模型与基于词义的LDA模型提取文本特征,通过计算待测文本和样本集特征的欧氏距离作为文本的相似度,设定相似度阈值,取阈值范围内的个数为K,通过对K个样本集中各类标签的个数排序,确定待测文本的类别。此实验中SVM分类器使用LiSVM,核函数使用线性核,主题数量为10,我们通过不断扩大训练集来检验两种模型分类的准确率,实验结果如图4、图5所示。
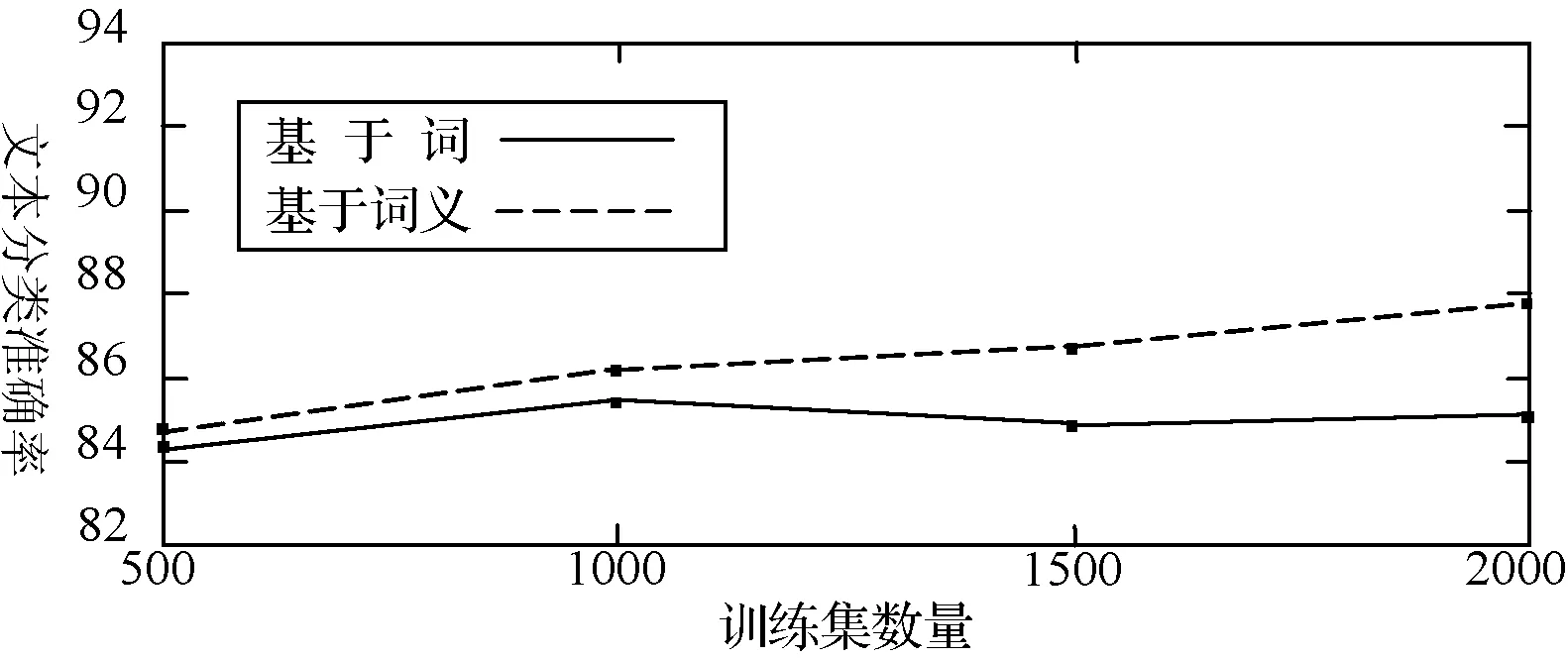
图4 基于词和词义的提取的特征运用SVM分类准确率对比

图5 基于词和词义的提取的特征运用k近邻分类准确率对比
从图4、图5中可以看出,和基于词的LDA特征提取,无论运用哪一种分类器,基于词义的特征提取使得文本的分类准确率有了提高。当训练集的数量比较小时,基于词的主题建模和基于词义的主题模型,两种模型的分类准确率相近,但当随着训练集的变大,基于词义的主题模型优势将越来越明显。这是由于随着训练集的扩大,一义多词的现象越来越严重,可替换的同义词越来越多,每个词和词义在文章中出现的次数越来越不均等,而基于词义的主题建模很好地平衡了这种差距,也更接近于语言的生成规律。
在分类算法上,通过改进K近邻,运用确定的相似度阈值替代了K值,通过这种方法能够进一步克服文本类别之间模糊性,在阈值之外的新类别不会强迫进入K的范围而影响分类器判断,这样得到的文本类之间将具有更高的相似度。
7 结 语
总的来说,此种改进并没有改变模型的整体架构,运算的复杂程度没有增加,只是改变了最底层的元素。但是,从改进的算法可以看出,基于词义建模的方法要远比基于词语更加贴近语言的形成规律,尤其在文本分类中,当语料库规模较大候,通过基于词义的降维进一步简化了运算量。
本实验力求证明在语义空间上运用概率建模的可行性,所以使用了基于同义词词林相似度计算形成的同义词表。由于词义的表示依赖于语言环境,用词习惯等诸多因素,所以在实际应用中高精度同义词表的生成是下阶段研究的主要方向。
[1] Thomas K Landauer,Peter W Foltz,Darrell Laham.An Introduction to Latent Semantic Analysis[J].Discourse Processes,1998(25):259-284.
[2] Mark Steyvers.Probabilistic Topic Models[D].Uniwersity of California,2005.
[3] Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Commun.ACM,November,1975,18(2):613-620.
[4] David M Blei,Jon D McAuliffe.Supervised topic models[C]//NIPS,2007.
[5] Samuel Brody,Noemie Elhadad.An unsupervised aspect-sentiment model for online reviews[C]//Human Language Technologies:The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics,Stroudsburg,PA,USA,2010,HLT’10,2010:804-812.
[6] Ivan Titov,Ryan McDonald.A joint model of text and aspect ratings for sentiment summarization[C].Columbus,Ohio,June 2008,In Proceedings of ACL-08:HLT,2008:308-316.
[7] Branavan S R K,Chen H,Eisenstein J,et al.Learning document-level semantic properties from free-text annotations[J].Journal of Artificial Intelligence Research,2009,34(1):569-603.
[8]HannaWallach,DavidMimno,AndrewMcCallum.Rethinkinglda:Whypriorsmatter[J].AdvancesinNeuralInformationProcessingSystems22,2009:1973-1981.
[9]GriffithsTL,SteyversM.Findingscientifictopics[J].ProceedingsoftheNationalAcademyofSciences,April2004,101(Suppl.1):5228-5235.
[10]ThomasPMinka.Expectationpropagationforapproximatebayesianinference[C]//Proceedingsofthe17thConferenceinUncertaintyinArtificialIntelligence,SanFrancisco,2001,UAI’01,2001:362-369.
[11] 田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报:信息科学版,2010,28(6):602-608.
[12] 唐国瑜,夏云庆,张民,等.基于词义类簇的文本聚类[J].中文信息学报,2013,27(3):113-119.
[13] 郑艳红,张东站.基于同义词词林的文本特征选择方法[J].厦门大学学报:自然科学版,2012(2):200-203.
[14]JonathanChang,JordanBoyd-Graber,ChongWang,etal.Readingtealeaves:Howhumansinterprettopicmodels[C]//NIPS,2009.
[15] 于娟,尹积栋,费庶.基于句法结构分析的同义词识别方法研究[J].现代图书情报技术,2013,29(9):35-40.
[16] 肖志军,冯广丽.基于《知网》义原空间的文本相似度计算[J].科学技术与工程,2013,29(3):8651-8655.
[17] 冯新元,魏建国,路文焕,等.引入领域知识的基于《知网》词语语义相似度计算[C]//第十二届全国人机语音通讯学术会议,贵阳:[出版者不详],2013.
[18] 吕立辉,梁维薇,冉蜀阳.基于词林的词语相似度的度量[J].现代计算机,2013(1):3-6.
ATHEMEFEATURESELECTIONALGORITHMBASEDONWORDSMEANINGDIMENSIONREDUCTION
XiaoLei1WangXu1SuWulin2
1(College of Industral and Commercial,Hebei University,Baoding 071000,Hebei,China)2(College of Mathematics and Computer,Hebei University,Baoding 071000,Hebei,China)
Intextfeatureselection,duetothedifferencebetweenwordsprobabilityspaceandwordsmeaningprobabilityspace,thethemefeaturesentirelybasedonwordsprobabilityusuallycannotwellexpresstheideaofthearticle,norbeconducivetotextclassification.Toachievethepurposethatthethemefeaturescanbetterreflectthearticlethoughts,weextractedathemefeatureselectionalgorithmwhichisbasedonwordsmeaningdimensionreduction.Byconstructinga"synonymtable"basedonwordsdictionaryasthemappingmatrixofwordstowordsmeaning,thealgorithmconstructsawordsmeaning-basedprobabilitydistribution,andextractstextfeaturesbyLDAforclassification,theaccuracyofclassificationissignificantlyimproved.Experimentsshowthatthethememodelbuiltbythismethodwillhaveastrongerthemerepresentationdimension,throughthealgorithmtheproblemofdifferencebetweenwordsprobabilityandwordsmeaningprobabilityintextfeatureextractionisbasicallysolved.
Lineardiscriminantanalysis(LDA)ThememodelThemerepresentationdimension
2014-05-21。国家自然科学基金项目(60903089);河北大学博士项目(Y2009157)。肖雷,硕士,主研领域:模式识别与文本分类。王旭,硕士。粟武林,硕士。
TP3
ADOI:10.3969/j.issn.1000-386x.2016.03.057
