基于GA-SVM的股指期货预测研究
2016-09-20张德江程习武梁元浩刘元梓四川大学计算机学院成都610065
张德江,程习武,梁元浩,刘元梓(四川大学计算机学院,成都 610065)
ZHANG De-jiang,CHENG Xi-wu,LIANG Yuan-hao,LIU Yuan-zi(College of Computer Science,Sichuan University,Chengdu 610065)
基于GA-SVM的股指期货预测研究
张德江,程习武,梁元浩,刘元梓
(四川大学计算机学院,成都610065)
0 引言
股指期货交易市场瞬息万变,投资人希望达到效益最大化,而其首先必须做到的就是对预定交易时刻指数的准确预测。但是目前大部分股指期货预测存在以下一些不足:一是各项预测以股指期货的技术指标作为基础数据,脱离交易本身所产生的交易信息进行预测;二是以反转点等指标作为预测目的,而不是直接对指数进行预测;三是使用默认参数的支持向量机对股指期货指数进行预测,效果不理想。
针对以上若干问题,本文采用某证券期货交易公司所提供的2010年4月16日至2014年3月4日的近3000万条沪深300股指期货成交明细数据,在对大量交易信息进行一系列数据处理后,使用GA-SVM进行回归预测研究。
1 实验设计思路
本实验的设计思路即为针对前文提出的几大不足做出改进,一是输入数据采用交易本身信息,如买卖价格,成交价格等;二是以股指期货的指数作为预测的目标;三是对SVM进行参数优化,达到最优预测。实验设计思路如图1所示。

图1 实验流程图
2 实验数据预处理
2.1原始数据采集
本文所采用的数据是由某证券公司提供的2010 年4月16日至2014年3月4日的沪深300股指期货当月合约TICK数据,通常也被称作股指期货当月合约成交明细数据。根据实验的需求,对上述的原始数据集进行了加工提取。选取每天最后一个TICK数据,即每天15:15:00的第二个TICK数据作为一天的收盘情况。从2010年4月16日至2014年3月4日,共取得924条数据。如表1所示。
成交价、当前价:表示目前交易成交时刻的最新价格(在本数据集中,两者相等)。其中,成交价即是所谓股指期货的“指数”,也是本文预测的目标。

表1 日数据集样例

表2 交易数据
买一量、卖一量:表示目前交易的挂单情况,单位为手。
买一价、卖一价:表示完成对应交易所需要支付的每手单价。
成交量:表示持续至当前时刻为止的成交总量。
持仓量:表示买卖双方未平合约的总量。持仓量能够反映市场上看多看空力量的大小、变化,以及多空力量的更新情况。
2.2输入样本选取
在本文实验数据集之中,共有10个维度的数据。其中,成交价是回归预测的目标变量。另外,对于日期与时间两个维度的数据,直接认定它们与成交价呈不相关关系。当前价与成交价完全相等,因此这个维度的信息也应该排除。有效变量的维度缩小到6维。令:
X=<买一价;买一量;卖一价;卖一量;成交量;持仓量>
Y=<成交价>。
因此回归模型的基本形式为:
<成交价>=f(<买一价;买一量;卖一价;卖一量;成交量;持仓量>)
假设数据集的最小时间间隔为t,即对于原始数据集,对于日数据集,t的长度为一天。那么:
对于模型Yt=f(Xt),显然只具有数学上的意义。由于f的映射过程需要一定时间的消耗,所以该模型仅仅有“回归”的作用,而起不到“预测”的效果。
因此,一个有意义的回归预测模型至少应该满足:
Yt+k=f(Xt)(k>0),即可以通过t时刻的X值,给出t+ k时刻的Y值。
在本文的实验中取k=1,因此一条基本的有意义的数据样本的格式应该满足:(<成交价>t+1,<买一价;买一量;卖一价;卖一量;成交量;持仓量>t),
例如,对于以下两条数据(如表2)。
可以得到一条有意义的输入数据为:

表3 交易数据
依此规则选取一定数量的数据样本,就能构成一个预测模型的训练集。
2.3数据归一化处理
由于样本中的各个维度的数据代表着不同的意义,每一维的数据带有的量纲也各不相同,如果直接使用这类数据,会导致与因变量在比例上相近的数据的影响因子变相加大,回归预测出现偏差甚至错误。因此,需要对各维度数据进行归一化处理,将其统一到某个固定区间,消除量纲带来的影响。本文采用最小-最大标准化(Min-Max Normalization)方法进行标准化处理,这种标准化通过数据的线性变换,能够把结果放缩到[a,b]的范围。转换公式表示如下:
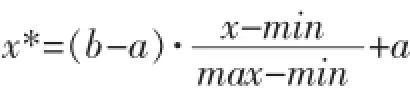
其中,x是初始输入值,x*是转换后的值,max、min分别对应输入样本中的最大值与最小值。实验对自变量X及因变量Y分别进行归一化处理:X的归一化范围为[-1,1];Y的归一化范围为[0,1]。自变量X归一化后的部分数据样例如表4所示。
2.4主城份分析
主成分分析(Principal Component Analysis,PCA),是一种统计学上对数据进行降维处理的常用方法。主成分分析通过将原来的数据向量按照一定计算规则重新组合为一组数量较少,并且相互之间独立的几个综合指标向量来替换原来的指标向量,这些综合指标能够反映原来数据所包含的主要信息。

表4 自变量X的归一化效果
使用主成分分析对自变量进行降维处理,能够有效提升支持向量机的预测精度。主成分分析的算法过程如表5所示。

表5 主成分分析算法流程
此处以表1数据为例进行主成分分析处理:
(1)求得的协方差系数矩阵为:
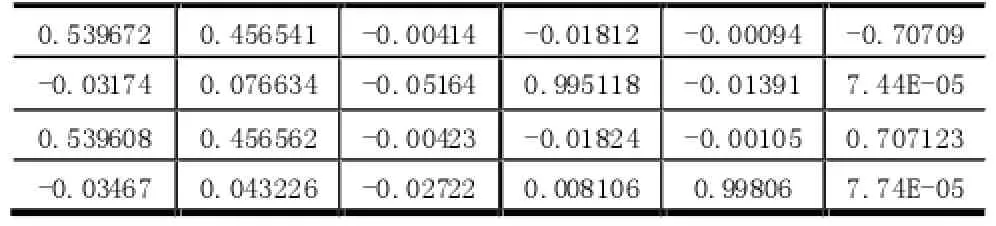
表6 协方差系数矩阵
(2)各个成分的贡献率分别为:
成分一 0.510674、成分二 0.262372、成分三0.106219、成分四0.09159、成分五0.028825、成分六0.00032。
(3)如图2所示,原本6个维度的数据在主成分取得95%的情况下降低到4个维度。
3 基于改进GA-SVM的日数据集预测研究
3.1遗传算法综述
遗传算法(Genetic Algorithms,GA),是源于人们对生物遗传行为原理的研究。达尔文的进化论、孟德尔的遗传理论还有魏慈曼的物种选择学说都对其产生起到了重要的借鉴意义。在近一百年到两百年的时间里,人们将物种进化论运用到各个的领域,例如医学、仿生学、机械工程、管理学、计算机等。二十世纪八十年代起,计算机领域的快速发展,多种类生物行为的智能研究如机器学习、神经网络等开始步入欣欣向荣的发展时期,各学科的交叉应用也越来越频繁,这恰恰给遗传算法的研究和应用带来了新的契机。1962年,密歇根大学的John Holland提出利用群体进化的思想。他指出“新的种群应基于当前种群的有效性而产生”,同时也给出了遗传算法中常用的一些概念,如使用交叉、复制、变异、选择等。此后,J.D.Bagley与1967年在他的博士论文中首次提到“遗传算法”一词,该词的用法也由此沿用至今。

图2 主成分分析成分图
3.2寻优目标确认
实验说明,当使用默认参数的支持向量机对股指期货指数进行预测时,预测效果较差。为了获得更合理的参数,需要对参数进行寻优。参数寻优最为简单的方法即是通过暴力查找的方式,对参数的每一个可能值进行尝试。这种算法的弊端显而易见,一是需要耗费大量的寻优时间;二是对于参数在取值范围内是连续值而非离散值的时候,不能覆盖所有的参数取值情况。由于遗传算法具有动态搜索的特性,能够克服暴力查找的缺点,此处使用遗传算法对支持向量机的参数进行寻优,构建GA-SVM预测模型。
对于RBF核函数所要寻优的参数有c、g。Poly核函数的参数较为复杂,实际研究中经常令d=3,r=1。剩余需要要寻优的参数同为c、g。
另外,参数ε对支持向量的个数有影响,支持向量的数量与预测模型有直接关系,因此,合理的寻优办法应该把ε也纳入寻优范围。综上所述,参数寻优的目标为参数对(c、g、ε)。
3.3结合参数寻优的预测流程
GA-SVM模型的预测流程如表7所示。

表7 GA-SVM模型预测流程
GA-SVM详细流程图如图3所示。
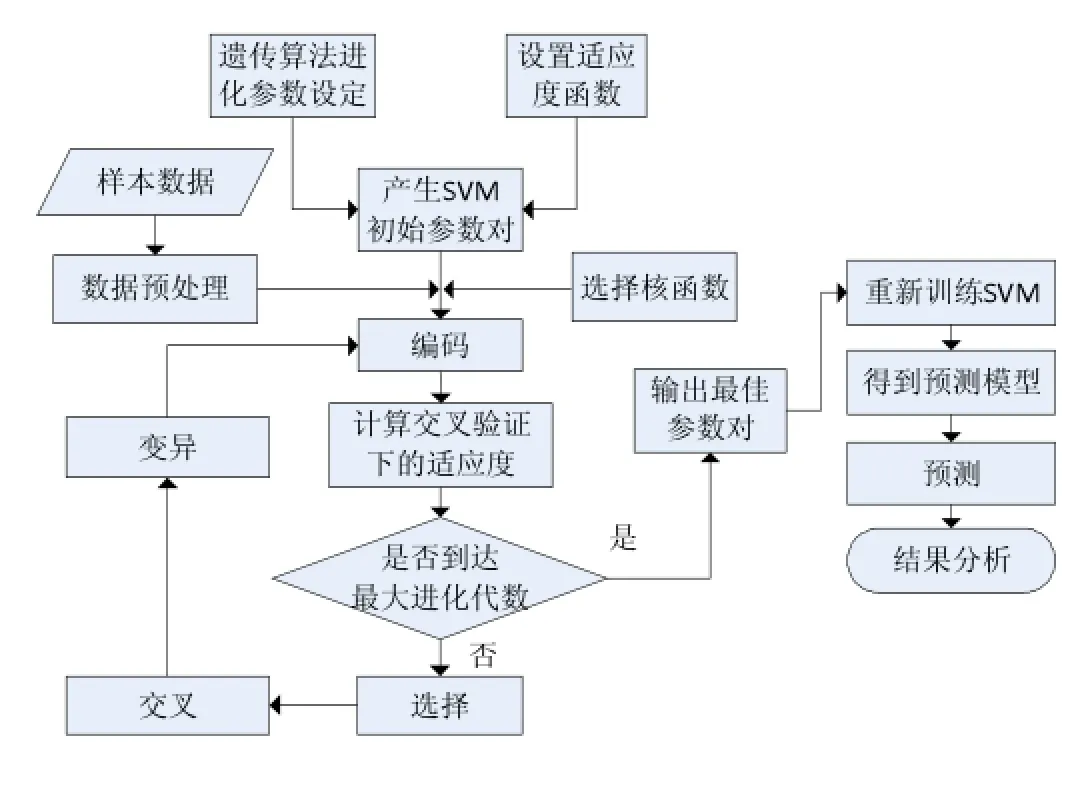
图3 GA-SVM详细流程图
3.4基于 GA-SVM 的参数寻优及预测效果结果为:
训练集MSE=0.000701,r2=0.986797;测试集MSE= 0.000295,r2=0.924759。

图4 遗传算法寻优过程
②Poly核函数
使用Poly核函数寻优得到的最佳参数对(c,g,ε)= (0.4167,0.1404,0.0112),在该参数条件下的预测结果为:
训练集MSE=0.000908,r2=0.906647;测试集MSE= 0.000953,r2=0.883146。
对于使用RBF核函数和Poly核函数的GA-SVM,其预测性能都达到了十分优秀的水准,足以用于实际的预测。
4 实验结果与分析
本次实验得到的结果为:
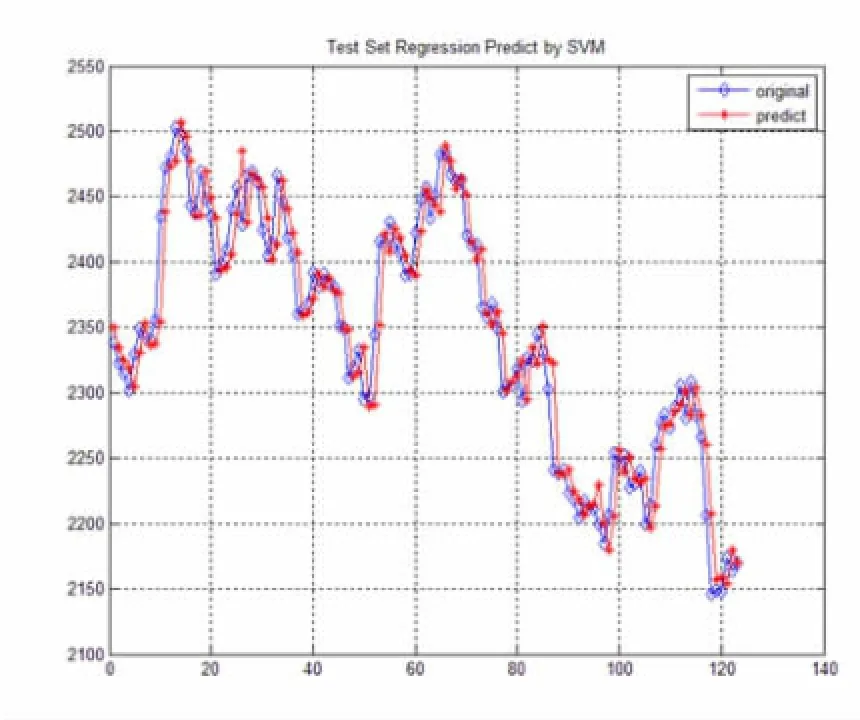
图5 RBF核函数预测结果
本实验使用前述的日数据集进行研究。将前800个数据作为训练集,后123个数据作为测试集。
①RBF核函数:
使用遗传算法的寻优过程如图4所示。
最终得到的最佳参数对(c,g,ε)=(2.7997,0.0673,0.0114),使用该参数对重新对训练集进行并进行预测,
其中,步骤2的设置情况如下:
①遗传算法:
进化代数=50,种群规模=20,交叉概率为0.7,变异概率为0.01,参数ε的范围设置为[0,1]。
前文对于c、g的范围做过定性测试,以之为参考:
对于RBF核函数,参数c的范围设置为[0,100],参数g的范围设置为[0,100]。
对于Poly核函数,参数c的范围设置为[0,10],参数g的范围设置为[0,10]。
适应度函数fitness=MSE。
①预测精度:从工程角度看,GA-SVM在日数据集上的预测MSE达到了10-3的数量级,这是一个十分准确的预测结果。完全可以用来进行实际操作。
②算法时间效率:在训练样本集容量为800,交叉验证折数为5的情况下,遗传算法耗费的时间分别为459.2283秒(RBF核)和417.1579秒(Poly核)。
图5为预测效果示意图,图中蓝色曲线为实际走势,红色曲线是根据预测算法计算后的预测曲线,从图中可看出预测曲线与实际走势基本一致,由于数据是随机选取的,所以可以得出结论,在股指期货的日数据集上,通过对原始交易数据的选取、归一化、主成份分析等预处理手段,采用经过遗传算法优化过参数的支持向量机对其进行预测,可以得到较好的预测效果。
[1]闻杰.沪深300股指期货对我国股票市场的影响分析[J].企业导报,2014,(11):14-15.
[2]罗文辉.力量天平倾斜 期指金额超现货.第一财经日报,2010.4,20.
[3]陈艳,褚光磊.关联规则挖掘算法在股票预测中的应用研究——基于遗传网络规划的方法[J].管理现代化,2014,34(3):13-15. DOI:10.3969/j.issn.1003-1154.2014.03.005.
[4]Manish Kumar.Forecasting Stock Index Movement:A Comparison of Support Vector Machines and Random Forest[C].Indian Institute of Capital Markets 9th Capital Markets Conference Paper.
[5]Dai S Y,Li N.Using SVM to Predict Stock Price Changes from Online Financial News[J].Mechatronics&Applied Mechanics,2012, 157-158:1586-1590.
[6]Publishing S R.Stock Market Prediction Using Heat of Related Keywords on Micro Blog[J].Journal of Software Engineering&Applications,2013,(3):37-41.
Quantitative Trading;SVM;Genetic Algorithm;Prediction
Prediction of Stock Index Future s Based on GA-SVM
1007-1423(2016)07-0026-05
10.3969/j.issn.1007-1423.2016.07.006
张德江(1985-),男,新疆乌鲁木齐人,在读硕士,助教,研究方向为计算金融
程习武(1985-),男,湖北天门人,在读硕士,助理工程师,研究方向为面向设计与制造的软件工程
梁元浩(1988-),男,福建厦门人,硕士,职员,研究方向为计算金融
刘元梓(1984-),男,重庆人,在读硕士,助理工程师,研究方向为信息安全
2016-01-05
2016-02-18
ZHANG De-jiang,CHENG Xi-wu,LIANG Yuan-hao,LIU Yuan-zi
(College of Computer Science,Sichuan University,Chengdu 610065)
近几年来,跨学科交叉融合日益发展,许多非金融业界的研究者也投入到证券预测之中,各种数学模型被用来进行投资预测,其中尤其以机器学习方法应用最为广泛。将对沪深300的交易信息进行数据加工,采用GA-SVM对股指期货进行交易预测,该方法能够有效地对股指期货日交易进行预测。
量化交易;支持向量机;遗传算法;预测
In recent years,with the growing of interdisciplinary integration,many non-financial industry researchers also predict into stocks among various mathematical models are used for investment forecasts,which especially the most widely used machine learning methods.Uses CSI 300 index for data processing,the use of GA-SVM prediction model for stock index futures trading can effectively predict the date of the transaction.
