基于核稀疏表示和AdaBoost算法的自然场景识别
2016-09-14陆迎曙贾林虎
陆迎曙,贾林虎
(河海大学 计算机与信息学院,江苏 南京 211100)
基于核稀疏表示和AdaBoost算法的自然场景识别
陆迎曙,贾林虎
(河海大学 计算机与信息学院,江苏 南京211100)
为了提升自然场景图像的识别精度,结合bag-of-visual word模型,提出了一种基于核稀疏表示的图像识别方法。该方法的图像描述部分主要利用核稀疏表示在高维度空间进行图像特征的匹配表示,识别部分采用AdaBoost分类器,对各个类别编码并在对应的核矩阵上进行划分,从而实现多类场景图像的识别能力。实验结果表明,该方法有效的提升了图像描述的准确度与对自然场景图像识别的精度。
bag-of-visual words模型;核稀疏表示;AdaBoost分类器;自然场景识别
图像描述模型bag-of-visual words(BOVW)在图像分类与识别中有着广泛的应用。该模型通过提取图像的SIFT特征[1]利用聚类算法生成字典,进而使得图像形成统一的字典表示。然而,这种方法未能考虑图像特征的空间信息和有效匹配的方式,在应对于较多类图像时其识别性能低下。因此,如果能充分挖掘SIFT特征的空间位置信息与匹配信息,能够有效地提升模型的分类识别能力。
目前针对提升图像分类识别性能的研究主要集中在图像描述模型和分类器算法这两个方面。文献[2]提出了空间金字塔匹配模型(SPM)来增加SIFT特征的空间位置信息,该模型在BOVW的基础上对图像递增式划分成若干子块从而形成具备空间信息的图像空间金字塔描述。文献[3]指出BOVW模型中的聚类算法不能有效的抓取图像的差异特征,所以提出了稀疏表示的方法来增强图像的字典表达能力。与此同时,核函数的方法在计算机视觉领域取得了优异成绩,它通过将特征向量映射到高维度的特征空间进行相似度匹配,从而获得在低维度空间不能取得的特征重构表示。性能较为优异的分类器算法,主要有线性的支持向量机(SVM)和AdaBoost算法,其中AdaBoost算法利用若干弱分类器的级联实现与SVM较为接近的分类识别性能,有着显著的优越性。
1 空间金字塔模型
空间金字塔模型是基于BOVW发展而来的具备空间位置描述能力的图像描述模型。在本文所提出的模型中(如图1所示),首先提取所有图像的SIFT特征,通过聚类算法生成一个长度为K的字典,然后将每个图像按照1×1,2×2,4×4划分成3层图像子块如图2,并为各层赋权值,根据文献[2]本文中的空间金字塔1-3层的权重依次为1/4,1/4,1/2。对每个子块的特征进行字典表达后,采用最大汇聚方法并串联成21K长度的字典表示。假定一个图像有M个SIFT特征,该图像可以表示为则字典系数矩阵则最大汇聚方法可表示为

其中r∈R1×(21K)为该图像的空间金字塔向量表示。
2 核稀疏表示
传统的BOVW模型中,K-MEANS算法被应用于图像特征的聚类从而生成长度为K的字典,相应字典表达同样采用向量量化(VQ)的方法,即求得图像特征与字典词汇间的最小欧氏距离,并计算字典的统计直方图得到图像的字典表达。然而这种方法,一方面未考虑到欧式距离并不适合作为统计特征SIFT的相识度准则,另一方面,VQ不能充分表达图像的差异化特征。为了减少特征编码过程中的信息损失,稀疏表示(SC)被提出来学习更加稀疏且更具鉴别性的特征编码。

图1 模型总体结构图Fig.1 Structure diagram of the proposed model
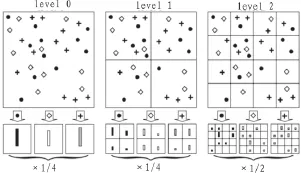
图2 空间金字塔映射示意图Fig.2 Schematic diagram of spatial pyramid mapping
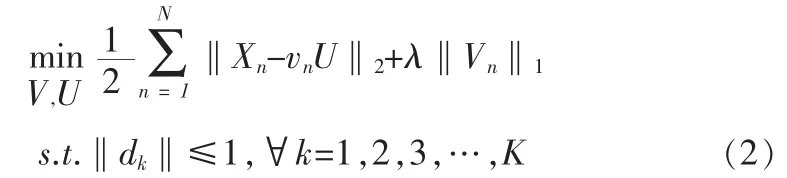
其中λ≥0是常量稀疏性系数,‖·‖2,‖·‖1分别是L1,L2约束。值得注意的是这里的稀疏字典是过完备的,即K>D。生成稀疏字典后,稀疏编码可重写为:
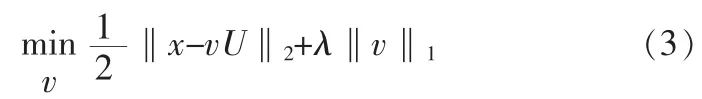
然而文献[4]指出学习一个高维度、过完备的稀疏字典是极其耗费计算资源与时间的,同时文献[5]经实验得出通过某种聚类算法得到固定字典作为稀疏字典同样能取得不错的效果。因此,文中提出应用K-MEANS++聚类[6]算法来替代等式(2)学习稀释字典。
与此同时,由于核函数的非线性生成性能与其在计算机视觉领域的成功应用,文献[7]引入了核作为特征的相识度匹配方法,提出了核稀疏表示。核稀疏表示的方法是通过将输入特征与字典基同时映射到高维或无限维的特征空间F中进行相似度匹配从而得到更具鉴别性的稀疏系数。假定φ(·)是映射函数,则,φ(U)∈RN×H,φ(x)∈RN×H(H≫D)分别作为映射后的特征集与稀疏字典。这样等式(3)可重写为:

同时,可改写为:

等式(5)似乎可以通过正交匹配追踪算法(OMP)来得到稀疏系数v,但是正如文献[8]所指出的,直接优化解决等式(5)是不现实的。一方面,如果特征空间F已知,由于映射后的特征维度H≫D,等式(5)计算复杂度将远超与于等式(4);另一方面,如果特征空间F未知,φ(U)和φ(X)并不能显性地得到。所幸的是,通过核函数的方法可以间接地在特征空间F进行特征的相似度匹配,所以等式(5)可改写为:

其中ξ为重构残差,上式等价于

其中Y=(K(x,U))1×K=φ(x)φ(U)T,Q=(K(ui,uj))K×K=φ(U)φ(U)T,K(·,·)为mercer核函数。由于文献[9]指出对于SIFT这样的统计特征,直方图相交核(HIK)相比于其他基于欧式距离的核函数更加有效,所以本文选取HIK作为核稀疏表示的核函数。最后对等式(6)通过OMP算法即可得到稀疏系数V。
3 AdaBoost分类算法
AdaBoost是自适应的boosting算法,该分类器通过训练若干弱分类器,并将弱分类器结果进行有权重的统计得到最终分类结果。在训练过程中,先将样本分为正负两类,并等值化样本权重,然后根据若分类器的错误率来赋予各自的权重(错误率越大,对应的分类器权重越小)。同时更新训练样本权重,使得正确分类的样本权重降低而错分样本的权重升高,这样经过若干次迭代,直到训练错误率为0或弱分类器的数量达到预设值为止。
为了使上述二元分类器应用于多类样本的识别问题,本文采用类别编码的方式,引入L个二元Adaboost分类器,则H类类别编码长度为L(L≥H)且需各不相同。若有4类待识别样本C1,C2,C3,C4,通过6个二元AdaBoost分类器,编码可为:
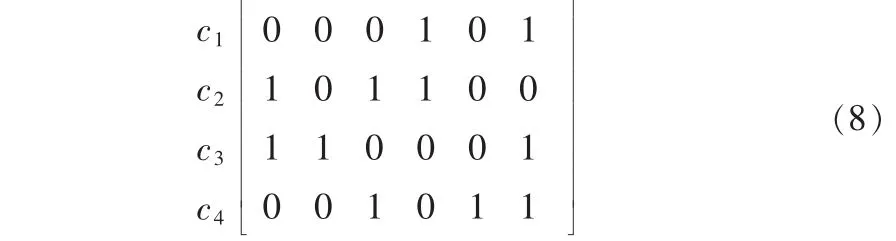
该矩阵的每行对应类的类标编码,其中0表示负样本,1为正样本,需要注意的是每类编码必须同时包含正负码。当未知样本输入该多类分类器后,分别计算输出码字与上述编码的汉明距离,这个样本就被分为距离最小的类别中。
AdaBoost分类器的传统应用是在图像经过本文图像描述模型生成空间金字塔向量上直接训练并划分类别。然而由于核函数方法的优异性能与广泛应用,本文再次采用核向量来代替空间金字塔向量表示。假定训练图像的空间金字塔向量表示为,测试图像为,经过核函数匹配后的训练图像表示为Ta=K(Ra, Ra)∈RNa×Na
测试图像为Te=K(Re,Re)∈RNe×Ne。这样,将Ta,Te分别替代原先的训练与测试图像向量集输入AdaBoost分类器中,使之能够在核空间完成分类识别任务。
4 实验结果与分析
文中的实验数据集采取文献[2]所提供的15类场景图像集(如图 3所示)。训练图像每类为50张,并在剩余的每类图像中各选取100张作为测试图像集。设定OMP算法中的重构残差ξ=0.001,核稀疏表示中的核函数为HIK,分类器中的核函数为高斯核函数(GK),二元分类器的个数为L=30,随机选取15个符合条件的编码作为类标编码。

图3 15类场景图像集Fig.3 Examples of 15 scene categories
在图像描述阶段,分别采用传统的BOVW,SPM和文中提出的核稀疏表示的SPM完成图像的向量表示;在图像分类识别阶段,前两种模型分别采用线性核(LK)与HIK的SVM分类器。字典长度分别为100,200,300,400,500。将训练图像集带入模型完成训练,然后将测试图像集输入已训练好的模型中。采取平均识别率(AP)作为衡量性能的标准,实验结果如表1所示。

其中wt表示识别正确的样本总数,W为实验样本总数。
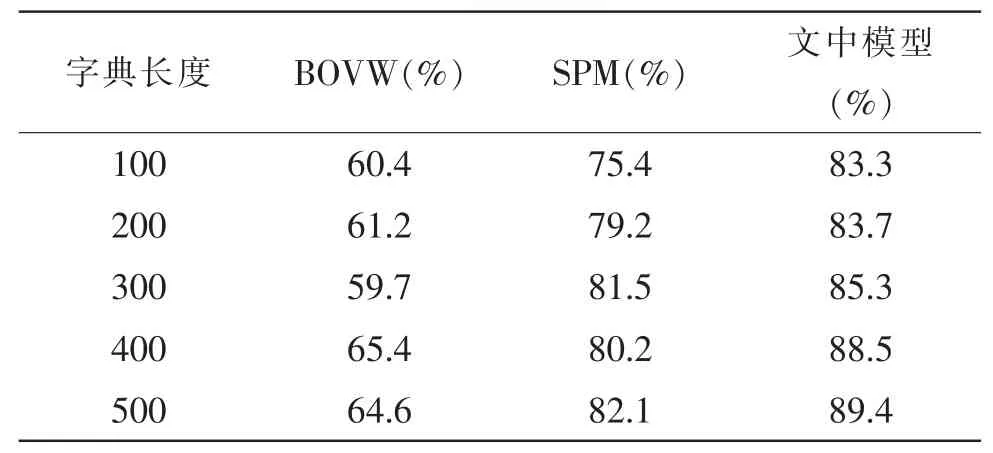
表1 传统模型与文中模型的识别率结果Tab.1 Recognition accuracy results of the traditional models and the proposed model
当稀疏字典长度L固定为200时,计算实验图像集中各类的正确识别率,实验结果表2所示。
从表1中可以看出文中在相同字典长度的条件下,所提出的识别模型的正确识别率远超传统图像识别模型,其最高识别率达到了89.4%。由此可见,文中提出的图像识别模型能够对自然场景图像得到较好的识别效果。同时,表2给出了L=200时每类的正确识别率,看以从中得出采用本文模型的识别率,15类实验图像中有12类的大于采用传统模型的识别率,占到整个实验图像集的80%,进一步验证了本文所提出模型的突出性能。
5 结 论
文中针对自然场景图像识别问题,提出了一种基于核稀疏表示和AdaBoost分类算法的图像分类识别模型。相较于其他模型,文中提出的图像描述模型能够通过核函数的方法在高维度特征空间完成特征的相似度匹配重构,减少了特征重构过程中的信息损失,提升了图像向量表示的鉴别性。通过对不同类别的编码与图像向量表示的再次映射匹配,文中的AdaBoost分类器能够在核矩阵中进行多类别目标的划分。实验结果表明,本文所提出的图像识别模型取得了较高的识别率,适合应用于自然图像的分类识别。

表2 传统模型与文中模型的每类正确识别率Tab.2 Recognition accuracy results of each category using traditional models and the proposed model
[1]LOWE D G.Distinctive image features from scale-invariant keypoints[J].International journal of computer vision,2004,60(2):91-110.
[2]Lazebnik S,Schmid C,Ponce J.Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories[J].Computer Vision and Pattern Recognition,2006:2169-2178.
[3]YANG J C,YU K,GONG Y H,et al.Linear spatial pyramid matching using sparse coding for image classification[J].Computer Vision and Pattern Recognition,2009:1794-1801.
[4]Lee H,Battle A,Raina R,et al.Efficient sparse coding algorithms[J].Advances in Neural Information Processing Systems,2006:801-808.
[5]WANG J,YANG J,YU K,et al.Locality-constrained linear coding for image classification[J].Computer Vision and Pattern Recognition,2010:3360-3367.
[6]Arthur D,Vassilvilskii S.k-means++:The advantages of careful seeding[J].Society for Industrial and Applied Mathematics,2007:1027-1035.
[7]GAO S H,TANG I W,CHIA L T.Sparse representation with kernels[J].Image Processing,2013,22(2):423-434.
[8]ZHANG L,ZHOU W D,CHANG P C,et al.Kernel sparse representation-based classifier[J].Signal Process,2012,60 (4):1684-1695.
[9]Wu J X,REHG J M.Beyond the Euclidean distance:Creating effective visual codebooks using the histogram intersection kernel[J].Computer Vision,2009:630-637.
Natural scene recognition based on kernel sparse representation and AdaBoost algorithm
LU Ying-shu,JIA Lin-hu
(College of Computer and Information,Hohai University,Nanjing 211100,China)
In order to improve the accuracy of natural scene recognition,this paper combining with the model of bag-of-visual words proposes the method for image recognition based on the kernel sparse representation.The section of image description in the method mainly uses the kernel sparse representation to match the features of the images in the high-dimensionality feature space,and for the recognition section,AdaBoost classifier is adopted in which the categories are encoded for the ability of multi-categories recognition.Finally,the experimental results show the increasing effectiveness of the image description and the improvement of the recognition accuracy.
bag-of-visual words;kernel sparse representation;AdaBoost classifier;natural scene recognition
TN919.82
A
1674-6236(2016)02-0172-04
2015-03-12稿件编号:201503169
陆迎曙(1992—),男,江苏滨海人,硕士研究生。研究方向:信号与信息处理,数字图像处理。
