基于海量数据的用户点击模式识别
2016-09-12林湘粤北京邮电大学信息与通信工程学院硕士研究生张昕宇北京邮电大学信息与通信工程学院硕士研究生
林湘粤 北京邮电大学信息与通信工程学院硕士研究生张昕宇 北京邮电大学信息与通信工程学院硕士研究生
基于海量数据的用户点击模式识别
林湘粤北京邮电大学信息与通信工程学院硕士研究生
张昕宇北京邮电大学信息与通信工程学院硕士研究生
移动互联网的高速发展,产生了大量的话单数据,其中蕴含的用户行为模式为移动运营商和人类信息社会的发展带来了机遇和挑战。本文介绍了基于云计算的海量数据挖掘技术下用户点击模式挖掘的过程,并分析了点击模式挖掘的结果及其带来的价值。
移动互联网;用户行为模式;先验算法;云计算;模式挖掘
1 引言
移动互联网的快速发展,带领中国走向了信息化时代。用户利用智能设备随时随地连接着移动互联网,并通过其产生了大量话单数据,大数据时代已经到来。移动互联网中的海量数据,反映着人们日常行为的方方面面,在大规模的用户通过智能手机产生的上亿规模流量的话单数据当中,如何从中挖掘出用户的行为特点,将用户的行为总结成行为模式用以描述用户的特征,是当前大数据应用的一个热点。
移动互联网用户的点击行为模式挖掘是将用户主动点击的网址链接总结成点击模式的过程。这些总结的点击模式能够反映用户真实的上网意图,反映用户真实的上网点击行为。用户点击模式的挖掘能够有助于理解用户真实的网站访问偏好,可以有助于商家对用户的有效推送,同时也能够利用识别的结果进行网页质量的分析。将移动互联网的点击信息采用处理、清洗和挖掘的方式,可以发现点击者的点击模式,提取出点击使用者的个人特点和喜好,为不同喜好类别的用户设计不同的网页页面,在恰当的网页页面为用户提供用户自己所喜欢的特定广告,并为用户推送和用户特点相匹配的商业资讯和新闻,从而增强商家的竞争力。用户点击模式挖掘具有极其高的商业价值和现实意义。
2 点击模式挖掘
随着移动互联网技术的发展和智能终端在市场上的扩张,越来越多的人们通过智能终端连接到移动互联网,人们访问移动互联网的相关信息蕴含着用户的相关喜好、用户的行为等,同时也蕴含着移动互联网本身的一些特征。所以越来越多的研究者采用原始的数据挖掘技术去挖掘移动互联网背后的潜在信息。然而大多数移动互联网数据挖掘的技术都是基于网页本身,只关注一些特殊文本和网页关键字,基于用户访问的URL本身的研究和挖掘很少。
首先,基于点击识别的算法,从大量的流记录话单中识别出了点击URL。为了进一步对URL的内部规律进行挖掘和研究,将点击URL的规则进行提取,用这些提取出来的点击URL规则代替点击URL,从而极大地缩小点击URL数据表的数量,节省存储空间,同时发现点击URL规则的内部规律。
2.1点击模式挖掘创新点
本文基于Apriori算法,并对其进行了改进,以适应点击模式挖掘算法。传统的利用Apriori算法的挖掘当中,最终展现序列的形式包含有序性、可重复性。在此方法中,为适应URL有序的且具有层级关系的数据结构,最终展示的序列还具有固定位置特性。即
原始Apriori算法包括两个部分:频繁项的产生和规则的发现。用户点击模式挖掘算法,只要产生了频繁序列项即是产生了规则,没有单独的规则发现阶段。
另外,对于候选项的产生方法中,和原始算法也有所不同。候选项的产生原则应当避免产生太多不必要的候选,同时必须确保候选项集的集合是完备的,此外还不应该产生太多重复候选项集。
在原始算法候选项的产生方法中,Fk-1*Fk-1方法:
在每两个频繁项合并产生新的候选项的时候,对产生的候选项直接筛选,原始算法只根据支持度计数方法过滤,点击URL识别算法不仅根据支持度计数方法过滤,还根据置信度进行过滤,而且根据两方面的置信度进行过滤。
2.2点击模式挖掘相关定义
点击URL规则的提取,采用数据挖掘理论当中关联分析和频繁项集产生的方法进行提取和逐层发现。并没有完全照搬关联分析和频繁项集产生的Apriori算法,而是将算法进行了改进,研究出有层级顺序的规则提取算法,以适应URL当中每一项之间有特定顺序这一主要特点。同时,最终采取的URL规则是极大频繁项集。
首先,定义序列这个概念,它具有如下4个性质:
性质一:序列中的元素是有层级的。一个序列中的元素从前到后依次是第0,1,2,3……层级,一个元素在不同层级上代表着不同的序列,如
性质二:序列中的某一个层级的元素允许为空。如果某一个层级的元素为空,则用*代替。
性质三:序列中的元素是有序的,调换顺序,即产生新的一个序列,如
性质四:序列中的元素允许相同,如
(1)项(i):将URL以“/”分割,一个URL分割后的每一个元素,都是一个项。
(2)项集(iSets):由若干个项组成集合为一个项集。
(3)事务(t):每一个URL为一个事务。
(4)事务集(tSets):具有0个或多个事务的集合为一个事务集。
(5)层级(level):将URL以“/”分割,一个URL分割后的第i个元素,即是第i层级。层级针对一个项而言。
(6)长度(length):一个URL规则当中含有非空项的个数,即是该URL规则的长度。长度针对一个URL规则而言。
(7)支持度计数(σ):规则在事务集当中的出现次数。
(8)支持度。
(9)置信度(Confidence):确定新规则在包含原规则的事务集当中出现的频繁程度。
基于以上定义,序列中的每个元素就是项,每个URL抽象成的序列就是事务,项的位置序号代表着这个项的层级,一个序列中非空元素的个数是一个序列的长度,k-序列是长度为k的序列。序列中的元素的个数和序列的长度可以是不同的,如
2.3点击模式挖掘方法
首先,频繁项集的产生主要依靠支持度计数原则。在此频繁项集产生阶段,只产生长度为2的序列,并且此序列的第0个元素一定不为空。初始规则的产生分两个步骤:
(1)初始候选项的产生:产生每一个长度为2的子序列。
(2)初始候选项的筛选:设子序列的支持度为δ,该规则为频繁项的判断原则为:δ>δs。
然后,对点击模式进行扩展。长度为j+1的序列由长度为j的序列和长度为2的序列构成,一旦产生新的序列,产生它的两个父序列就可以由新的序列替代,即最后取得是极大频繁项。URL规则的扩展过程,采用边产生新规则边筛选的方法。假设规则G1层级为Level1,长度为Length1(Length1=j);规则G2层级为Level2,长度为Length2(Length2=2)。规则的扩展包括两个步骤:
(1)候选项的产生:G1与G2两个规则合并产生候选G3,且有如下原则:Level2>Level1。
(2)候选项的筛选:G3是新产生的规则,它被判别为频繁项的原则:(a)δG3>δs;(b)δG3/δG1>δc;(c)δG3/δG2>δc。
由之前的算法步骤产生了不同长度的序列,即不同长度的规则,由于一旦产生新的序列,产生它的两个父序列就可以由新的序列替代,即最后取得是极大频繁项,所以要对最后的所有规则进行筛选,筛选出极大频繁项,即极大长度的规则。
至此,点击url模式挖掘算法得以实现。
3 点击模式挖掘结果
3.1数据说明
所采集到的流量数据来自运营商,数据的采集地理位置在中国一个大型城市。该城市的人口数量有400万人左右,一天的数据量在1T左右。数据所采集的移动互联网骨干网的网络结构图如图1所示。在移动互联网当中,有3个主要的组成部分,即移动设备、接入网络、骨干网络。
研究所使用的数据集通过流量监控系统TMS设备进行采集,TMS设备连接着图中所示的Gn接口。将报文按照五元组{源IP,目的IP,源端口号,目的端口号,传输协议}的规则进行解析,流是一段时间内具有相同五元组的一系列报文的集合。由于数据量的巨大,解析好的流记录,会上传到Hadoop集群的分布式存储文件系统HDFS当中。
3.2点击模式挖掘结果评价
基于点击URL的识别结果,进行点击模式的挖掘。在支持度和置信度的选择上,选择在模式挖掘结果的F1值最大的时候所对应的支持度和置信度。所以,在本文中,点击URL的模式挖掘的支持度为0.1,置信度为0.5。在这个阈值设定下,点击的模式挖掘结果如表1~6所示。
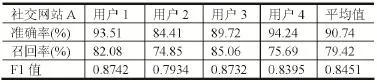
表1 社交网站A点击模式识别结果
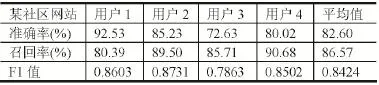
表2 某社区网站点击模式识别结果
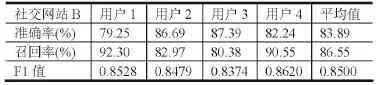
表3 社交网站B点击模式识别结果
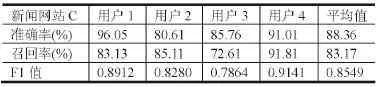
表4 新闻网站C点击模式识别结果
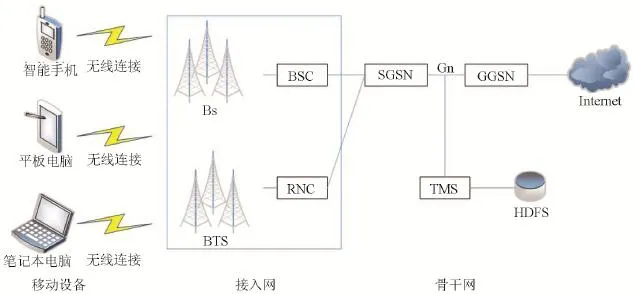
图1 2G和3G网络数据采集网络结构图
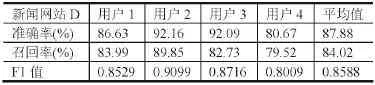
表5 新闻网站D点击模式识别结果
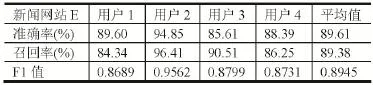
表6 新闻网站E点击模式识别结果
从试验结果可以看出某社交网站A的F1值平均为0.8451,某社交网站B的F1值平均为0.8500,某社区网站的F1值平均为0.8424,新闻网站C的F1值平均为0.8549,新闻网站D的F1值平均为0.8588,新闻网站E 的F1值平均为0.8945。可以看出,所有Host对应的F1值的平均值均在0.85左右,识别的结果较好。
4 结束语
随着移动互联网的快速发展和互联网上信息的爆炸式增长,网站和网页越来越成为人们在日常生活中分享信息,交流想法,休闲娱乐的重要平台。通过用户的行为规律为用户构建用户画像,发现他独特的喜好,改善商家所给出的业务和应用,具有极高的商业价值和现实意义。而用户上网的点击行为是移动互联网用户行为模式挖掘中相当重要的部分。
本文提供的点击URL模式挖掘方法改进了原有的Apriori算法,使新的方法能够适应URL的有序的同时是带有层级关系的数据结构。利用挖掘的点击模式,可以发现用户点击网页的真实意图,为移动运营商提供隐形的有意义的用户上网点击行为的信息和用户点击网页的兴趣点,对提升网页的质量有着至关重要的作用。
User click pattern recognition for massive data
LIN Xiangyue,ZHAN GXinyu
With the rapid development of the Mobile Internet,massive user data has been produced,in which the user behavior model has brought both challenges and opportunities.This paper details the process of user click pattern mining based on cloud computing.By the way,the result and the commercial valueit would brought have been given as well.
mobile internet;user behavior model;apriori algorithm;cloud computing;pattern mining
2016-04-10)
