基于文本挖掘的用电客户诉求智能聚类研究
2016-09-08梁浩波
梁浩波
(广东电网有限责任公司东莞供电局,广东 东莞 523000)
基于文本挖掘的用电客户诉求智能聚类研究
梁浩波
(广东电网有限责任公司东莞供电局,广东 东莞 523000)
从95598供电服务热线来电内容中挖掘用电客户服务需求来提升95598客户服务能力,基于此,提出了1套基于文本挖掘技术的用电客户诉求的智能聚类模型并通过开源技术将其系统化实现,该系统能够将用电客户来电内容的文本信息进行智能聚类并归类到不同诉求主题,进而得到用电客户的诉求热点,为实现精准的客户服务提供决策支持。实验表明,该系统能够有效地进行客户诉求文本的智能聚类,具有较高的聚类准确率。
文本挖掘;文本聚类;中文分词;文本表示;客户诉求
95598供电服务热线是电力企业服务客户、展示形象、提升品牌价值的重要窗口和必要渠道。随着电力体制改革的推进,尤其是售电侧的逐步放开,对供电企业的客户服务能力提出更高的要求。
提升95598客户服务能力最直接的途径是以用电客户诉求为导向,提高主动、精准服务的能力。目前用电客户诉求分析面临以下挑战:客户诉求内容以文本数据为主,信息量大、非结构化,一般统计软件难以分析;现有的95598问题分类标准仍比较粗放,部分分类未具体到客户诉求点;客户诉求点多难以聚焦,未能准确把握客户诉求热点。
基于文本挖掘技术,本文提出一个客户诉求智能聚类模型,通过开源技术开发了1套客户诉求智能聚类系统,从95598服务热线来电内容中挖掘用电客户诉求热点,以实时获取客户服务需求,为实现主动、精准的客户服务提供决策支持,以提升客户服务能力。
1 文本挖掘相关概念
文本挖掘[1](text mining, TM),又称文本数据挖掘或文本知识发现,是指在大规模文本集合中抽取隐含的、以前未知的、潜在有用的模式过程。它是从分析文本数据,抽取文本信息,进而发现文本知识的过程。Feldman在1995正式提出文本挖掘概念[2],目前文本挖掘研究主要围绕文本挖掘模型[3-4]、文本挖掘算法[5-6]等方面展开。文本挖掘常用的方法有:
a) 文本分类。按照预定义的类别体系,根据文本内容,为语料库的每个文本赋予一个或多个类别标记的过程。文本分类是一种有监督的机器学习方法,需要一定数量有类别标记的训练数据进行先验指导。
b) 文本聚类。在没有预先定义类别的条件下,对文本集合进行组织或划分的过程,基本思想是要将相似的文本划分到同一类中。文本聚类能够用来发现大规模文本集合的分类体系以及为文本集合提供一个概括视图,是进行文本主题分析的强有力的工具,它在信息自动获取,Web数据挖掘等领域都有很多应用[7]。文本聚类是一种无监督的机器学习方法,不需要训练过程。
c) 文本总结[8]。从文档中抽取关键信息,用简洁的形式,对文档内容进行摘要和解释,使用户无须阅读全文就可了解文档或文档集合的总体内容。
2 基于文本挖掘的文本聚类关键技术
2.1中文分词技术
中文分词是文本挖掘首要解决的问题。中文自动分词[9]是指使用自计算机自动对中文文本进行词语的切分,即像英文那样,中文句子中的词之间有空格以标识,达到被计算机自动识别语义的效果。基于词典的分词算法流程[10]如图1所示。

图1 基于词典的分词算法流程
常用的中文分词工具有ICTCLAS汉语分词系统、IK Analyzer中文分词工具和Imdict-chinese-analyzer中文分词模块。
2.2文本表示技术
文本表示是指利用计算机、统计学和语言学等知识,将自然语言形式的文本转换成计算机内部可直接处理的数据模型的过程。文本表示的基本步骤如图2所示。

图2 文本表示的基本步骤
目前常用的文本表示模型有布尔模型和向量空间模型(vector space model ,VSM)。布尔模型的特征权重采用0或1的布尔值表示,如果该特征在文本中出现,则该特征的权重为1,否则为0。布尔模型表示简洁,无需对特征进行降维,但其特征权重计算不够精确;向量空间模型具有比布尔模型更精确有效的特征权重计算方法,是目前应用最为广泛的文本表示模型。该模型提取文本的单词作为文本特征,利用单词出现频数进行特征降维,利用传统的ξTFij-δIDFi[11]公式计算特征权重。ξTFij-δIDFi公式描述如下:
给定包含n个文本的文本集合D={d1,d2,…,dn},利用中文分词工具对文本进行分词、过滤停用词,然后从文本集合D中提取出p个互不相同的特征集合T={t1,t2,…,tp} 。
记ξTFij表示特征ti在文本dj中的词频(term frequency,TF),即特征ti在文本dj中出现次数。ηDFi表示特征ti的文本频率(document frequency, DF),即文本集合D中含有特征ti的文本数。δIDFi表示特征ti的逆文本概率(inverse document frequency, IDF)即
(1)
式中n为文本总数。
则特征集合中第i个特征ti在文本集合D中第j个文本dj中的特征权重
(2)
在实际应用中,需对ξTFij进行归一化处理,记λTFTij=ln(1+ξTFij),此时
(3)
2.3聚类分析技术
聚类分析是一个把数据对象集划分成多个组或簇的过程,簇内的任意两个对象之间具有较高的相似度,而属于不同簇的两个对象之间具有较高的相异度。相异性和相似性根据描述对象的属性值进行计算,最常采用的度量指标是对象间的距离。常见的聚类方法及特点见表1[7]。

表1 常见聚类方法及特点
3 95598客户诉求智能聚类系统技术路线
本文选取95598客户热线3 500多条关于“网上营业厅”的来电内容作为模拟分析数据,见表2。
表2关于“网上营业厅”的来话内容(节选)

来电内容客户咨询网上营业厅如何操作客户咨询网上营业厅如何操作客户咨询网上营业厅切换城市问题客户咨询网上营业厅找回密码事宜客户咨询网上营业厅登陆密码忘记了,该如何处理…
3.195598客户诉求智能聚类系统技术路线图
本文基于文本挖掘技术提出了客户诉求智能聚类模型,并通过开源技术将模型系统化,具体如图3所示。
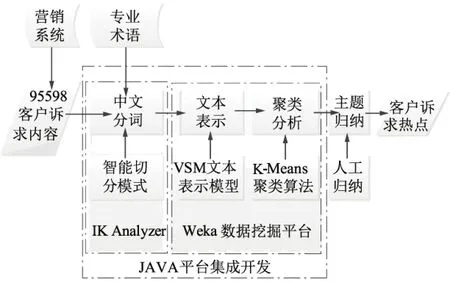
图3 95598客户诉求智能聚类系统技术实现图
从图3可知道,在技术实现过程中,主要按顺序进行4个阶段操作:中文分词、文本表示、聚类分析和主题归纳4个阶段,经处理后形成关于“网上营业厅”的客户诉求热点。
3.2中文分词技术实现
本文主要采用了IKAnalyzer实现文本的分词。IKAnalyzer是一个开源的、基于Java语言开发的轻量级的中文分词工具包,采用了特有的“正向迭代最细粒度切分算法”,支持细粒度和智能分词两种切分模式,同时支持用户词典扩展定义。
3.2.1分词词典扩展
在中文分词前,首先需要进行分词词典库的扩展,将95598的专业术语如“抄表”、“单笔”、“划扣”、“代扣”、“户号”等导入词典库,通过配置字典文件extendwords.txt实现。
3.2.2切分模式选择
IKAnalyzer支持智能分词和最细粒度2种切分模式,以下是2种切分方式的演示样例:
a) 文本原文。“客户咨询网上营业厅为何无法使用手机号码注册”;
b) 智能分词结果。 客户/咨询/网上/营业厅/为何/无法/使用/手机号码/注册/;
c) 最细粒度分词结果。客户/咨询/网上/营业厅/营业/厅/为何/无法/使用/用手/手机号码/手机号/手机/手/机号码/号码/注册/。
3.3文本表示技术实现
本文主要调用Weka中的StringToWordVector类实现文本表示模型的构建。Weka是一个开源的数据挖掘平台,集成了大量机器学习算法,包括对数据进行预处理、分类、回归、聚类、关联规则,是现今最完备的数据挖掘工具之一。下面详细分析文本表示的具体操作。
3.3.1特征选取
对3 500条文本数据进行分词后,每个单词均可作为标识文本的特征,各特征在整个文本集合中出现的次数ηDFi如图4所示。

图4 各特征的ηDFi(节选)
3.3.2特征降维
在特征降维中,主要是去除一些对文本区分程度很少的特征以及与文本聚类关系不大的特征,以降低文本聚类的算法复杂度,主要包括以下情形:
a) 去除一些几乎在每条文本都出现的“特高频”词,如图4中的“客户”、“咨询”、“网上”、“营业厅”等在3 500多条文本数据中出现达3 200次以上的特征,它们不适合作为不同文本的标识。
b) 去除一些特殊的“高频”词,主要包括常见的结构、语气助词,如“为”、“于”、“以”、“是”、“的”等与文本聚类关系不大的特征。
c) 去除一些词频很小的特征,如“你们”、“今天”、“以前”、“什么”等在3 500多条文本数据中出现次数少于10的特征,此类特征也不适合作为不同文本的标识。
在实际操作中,对于情形a)和情形c)通过设置特征出现频率的阈值(上限、下限)来自动完成特征的降维;对于情形b)通过配置字典文件disablewords.txt来过滤一些常见的结构助词和语气助词。
3.3.3特征权重计算
本文采用VSM来表达文本表示模型,特征权重计算采用计算式(3)。
下面选取3 500条文本数据中的第j个文本dj,即“客户来电反映掌上营业厅无法登陆,一直显示密码错误,并已尝试找回密码,但仍然显示错误,登陆不到,并表示前两天有更新客户端,更新后就登陆不上。” 来演示某一文本特征权重计算全过程:
a) 计算特征的ξTFij,即计算保留下来的特征在文本dj中的出现次数,如图5所示。

图5 各特征的ξTFij(节选)
b) 计算特征的λTFTij,即指对ξTFij进行归一化处理,记λTFTij=ln(1+ξTFij),如图6所示。

图6 各特征的λTFTij(节选)
c) 计算特征的δIDFi,即计算各特征的逆文本概率,见式(1),如图7所示。

图7 各特征的δIDFi(节选)
d) 计算特征的wij,即计算各特征的权重,见式(3),如图8所示。
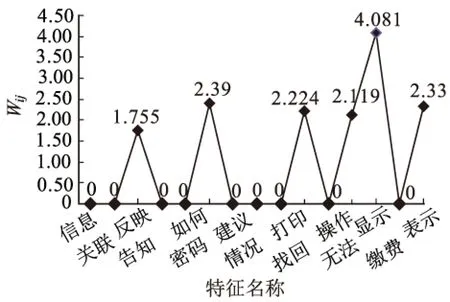
图8 各特征的wij(节选)
3.3.4文本表示模型
经过上述特征权重计算后,文本dj的VSM可以表示为
0,0,0,2.224,0,2.119,4.081,0,2.33,…,n)
对3 500条文本依次进行特征权重计算后,就可以得到表3的VSM。

表3 向量空间模型(VSM)
3.4聚类分析技术实现
上述VSM模型将3 500条文本转化成计算机内部可直接处理的数据模型(特征权重矩阵)。每条文本相当于一个对象,每个特征代表对象的属性,特征的权重代表属性值。该模型适用于基于距离的K均值聚类算法实现文本聚类。K均值算法主要思想可概括为[7]:
a) 算法。用于划分的K均值算法,其中每个簇的中心都用簇中所有对象的均值来表示。
b) 输入。簇数目K;包含n个对象的数据集D。
c) 输出。K个簇的集合。
d) 方法。从D中任意选择K个对象作为初始簇中心; repeat。根据簇中对象的均值,将每个对象分配到最相似的簇;更新簇均值,即重新计算每个簇中对象的均值;直到不再发生变化。
本文主要调用Weka中的SimpleKMeans类来实现聚类分析。SimpleKMeans类封装了K均值算法的实现过程,并提供设置该算法所涉及聚类数目K、距离函数、最大迭代次数、初始簇中心选取的随机算法的种子等核心参数的接口。在实际应用过程中,聚类数目K作为系统的输入,距离函数选择EuclideanDistance欧氏距离函数,其余参数保持默认值。
3.5主题归纳技术实现
主题归纳阶段主要由人工参与方式来实现。使用K均值算法完成文本聚类后,系统会自动计算出每个簇的中心,同时给出每个簇中心各特征对应的权重,见表4(为显示方便,现将簇的数目定义为3,并只节取部分特征的权重)。
在实际的主题归纳操作中,分别对每个簇中心按照特征权重的降序排列,将每个簇中心权重较高的几个特征进行组合,形成可理解的自然语言。每个簇中心就代表一个客户诉求热点问题。

表4 各簇中心的每个特征对应的权重(节选)
4 95598客户诉求智能聚类效果评估
评估聚类结果好坏的一个重要度量是各簇中所有对象与簇中心之间的误差的平方和ζSSE(sum of the squared error, SSE)
(4)
式中:K为簇数;L表示两个对象之间的欧氏距离;ci为簇i的中心,x为属于簇i的数据点集合。
不同于分类算法的类别数是固定的,簇数K是不确定的。确定K并非易事,因为“正确的”簇数常常是含糊不清。通常找出正确的簇数依赖于数据集的分布形状,也依赖于用户要求的聚类分辨率。
本文确定K时主要基于如下观察:增加K有助于降低ζSSE,提高聚类质量,因为更多的簇可以捕获更细的数据对象簇,簇中对象之间更为相似。然而,太多的簇一方面使得ζSSE边缘效应可能下降,因为将一个本身凝聚的簇分裂成两个只会引起ζSSE的稍微下降;另一方面会增加业务员在客户诉求热点主题归纳环节的工作量。因此,一种寻找正确的K的启发式方法是在实际业务需求和文本数据量的基础上,寻找ζSSE关于簇数曲线的拐点。
在实际应用中,首先根据实际业务需求以及文本数据量来初步确定可接受的簇数范围,如4个簇至14个簇,然后系统计算出每个簇数对应的ζSSE值,最后寻找ζSSE关于簇数曲线的拐点,拐点对应的簇数就是“正确的”簇数,如图9所示。

图9 ζSSE关于簇数的曲线
从ζSSE关于簇数的曲线不难看出,在簇数为10之后,继续增加簇数时ζSSESSE只是稍微降低,因此簇数10是相对较优的簇数。进而挖掘出关于“网上营业厅”的十大客户诉求热点问题,见表5。
表5各簇对应的客户诉求热点问题描述

簇号客户诉求热点问题归纳0来电咨询网上营业厅服务密码问题1来电咨询网上营业厅查询客户编号事宜2来电咨询网上营业厅注册或登陆问题3来电咨询网上营业厅如何注册及查询电费账单4来电咨询网上营业厅如何操作5来电反映网上营业厅无法注册或登陆6来电咨询网上营业厅如何打印电费清单事宜7其他问题8来电咨询网上营业厅查询电费问题9来电咨询网上营业厅如何找回密码
评估文本聚类效果主要是将聚类产生的簇标号关联到原文本数据中,再人工对原文本描述与归纳出的热点问题描述进行核查,得出相应的准确率,见表6。
表6聚类准确率统计

簇号文本数量/条所占比例/%准确率/%01113.18951872.4951265018.637133319.49904170048.79451193.416861293.70937531.528282045.858691042.9898总计348810086.8
不难看出簇1“来电咨询网上营业厅查询客户编号事宜”的聚类准确率较低,经追溯原始文本数据进行分析发现影响簇1准确率的主要因素有:a)簇1的文本所含的字数普遍较长,冗余信息和干扰信息较多,一定程度影响聚类效果;b)簇1中不少文本提及“客户编号”只是用作客户的标识,而非客户真正咨询的问题。如文本数据“客户反映网上营业厅查询电费时,不论输入哪期都显示:此结算户在查询年月内没有账单信息!,但实际是有电费产生的(客户编号:0319******)”。
由于文本聚类的效果必然依赖于文本数据的质量,因此可通过制定95598客户诉求工单中 “来电内容”的填写规范,对同一业务的问题咨询制定统一的填写模板,并以简洁的语言聚焦客户的问题点,改进文本数据质量,以提高文本聚类的准确率,得到更为精准的客户诉求热点。
5 结束语
用电客户诉求智能聚类模型主要应用了文本挖掘中的三大核心技术:中文分词技术、文本表示技术和聚类分析技术,其中中文分词基于IKAnalyze开源Java工具包实现,文本表示和聚类分析利用Weka开源Java工具包实现,最后通过Java平台进行集成开发将文本聚类模型系统化(如图5所示)。该系统能从95598服务热线的来电内容中挖掘出用电客户的诉求热点,从而获取用电客户的服务需求,为实现主动、精准的客户服务提供决策支持。通过将3 500多条“网上营业厅”诉求文本作为测试数据,实验结果表明该系统能有效地进行客户诉求文本的智能聚类,具有较高的聚类准确率,对95598客户服务能力的提升有着重要意义。
[1]谌志群,张国煊.文本挖掘研究进展[J]. 模式识别与人工智能,2005,18(1):65-74.
CHENZhiqun,ZHANGGuoxuan.ResearchProgressofTextMining[J].PatternRecognitionandArtificialIntelligence,2005,18(1):65-74.
[2]FELDMANR,DAGANI.KnowledgeDiscoveryinTextualData-bases(KDT)[C]//ProceedingsoftheFirstInternationalConferenceonKnowledgeDiscoveryandDataMining(KDD-95).Montreal,Canada:AAAI, 1995:112-117.
[3]MOTHEJ,CHRISMENTC,DKAKIT.InformationMining-useoftheDocumentDimensionstoAnalysisInteractivelyaDocumentSet[C]//Proc23rdBCSEuropeanColloquiumonIRResearch.ECIR,Darmstadt:BCSIRSG, 2001:66-77.
[4]GHANEMM,CHORTARASA,GUOY,etal.AGridInfrastructureforMixedBioinformaticsDataandTextMining[J].ComputerSystemsandApplications, 2005, 34 (1) : 116 -130.
[5]CATHERINEDB,WANDAP.BETTERR.FewFeatures:ASemanticApproachtoSelectingFeaturesfromText[C]//Proceedingsof2001IEEEInternationalConferenceonDataMining(ICDM’01).SanJose,California:IEEE, 2001.
[6]MINORUK,HIROYUKIK.AnApplicationofTextMining:BibliographicNavigatorPoweredbyExtendedAssociationRules[C]//Proceedingsof33rdHawaiiInternationalConferenceonSystemSciences-volume2.Maui,Hawaii:IEEE, 2000.
[7]HANJW,KAMBERM.数据挖掘概念与技术[M]. 范明,孟小峰,译. 北京:机械工业出版社, 2013.
[8]薛为民,陆玉昌. 文本挖掘技术研究[J]. 北京联合大学学报(自然科学版),2005,19(4):59-63.
XUEWeimin,LUYuchang.ResearchonTextMiningTechnology[J].JournalofBeijingUnionUniversity(NaturalScienceEdition), 2005,19(4):59-63.
[9]冯智斌. 面向中文文挖掘的聚类算法研究[D]. 广州:华南理工大学,2013.
[10]李晓笛.Web文本挖掘技术研究及应用[D]. 北京:北京交通大学,2015.
[11]SAHONG,BUCKLEYB.Term-weightingApproachesinAutomaticTextRetrival[J].InformationProcessingandManagement,1998,24(5):513-523.
(编辑王夏慧)
Research on Intelligent Clustering for Electricity Customers’ Demands Based on Text Mining
LIANG Haobo
(Dongguan Power Supply Bureau of Guangdong Power Grid Co., Ltd., Dongguan, Guangdong 523000, China)
In order to promote customer service capacity of power supply service hotline 95598 by means of excavating electricity customers’ service demands from incoming calling messages of 95598, this paper proposes an intelligent clustering model for electricity customers’ demands based on text mining technology and tries to realize it systematically by means of open source technology. This model is able to cluster text information of incoming calling of electricity customers intelligently and classify them into different demand themes, and then get demand hot focus of electricity customers so as to provide decision-making support for realizing precise customer service. Experiment indicates that this model can effectively realize intelligent clustering for text messages of customers’ demands and has higher clustering accuracy.
text mining; text clustering; Chinese words segmentation; text representation; customer demand
2016-03-17
2016-05-24
广东电网有限责任公司科技项目(GDZC-031920160259)
10.3969/j.issn.1007-290X.2016.08.009
TP391
B
1007-290X(2016)08-0045-06
梁浩波(1988),男,广东东莞人。工程师,理学硕士,从事信息安全系统维护、数据挖掘的应用研究。
