连续语音识别中基于Dropout修正线性深度置信网络的声学模型
2016-09-07陈雷杨俊安王龙李晋徽
陈雷,杨俊安,王龙,李晋徽
连续语音识别中基于Dropout修正线性深度置信网络的声学模型
陈雷1,2,杨俊安1,2,王龙1,2,李晋徽1,2
(1. 电子工程学院,安徽合肥230037;2. 电子制约技术安徽省重点实验室,安徽合肥230037)
大词汇量连续语音识别系统中,为了增强现有声学模型的表征能力、防止模型过拟合,提出一种基于遗失策略(Dropout)修正线性深度置信网络的声学模型构建方法。该方法使用修正线性函数代替传统Logistic函数进行深度置信网络训练,修正线性函数更接近生物神经网络的工作方式,增强了模型的表征能力;同时引入Dropout策略对修正线性深度置信网络进行调整,避免节点之间的协同作用,防止网络出现过拟合。文章利用公开语音数据集进行了实验,实验结果证明了所提出的声学模型构建方法相对于传统方法的优越性。
连续语音识别;深度置信网络;修正线性;过拟合;Dropout
0 引言
语音识别技术是指机器通过识别和理解把人类的语音信号转变为相应的文本或命令的技术。大词汇量连续语音识别(Large Vocabulary Continuous Speech Recognition,LVCSR)在公共安全、语音控制、可穿戴设备等领域有着广泛的应用,对连续语音识别展开深入研究对推动整个语音识别产业发展有着非比寻常的意义。相比于孤立词识别,连续语音识别系统更多地强调运用语言学知识,更加注重对上下文的关联信息的分析,能够有效地挖掘和利用语音数据的深层次信息。但是由于连续语音的发音更为随意,更易受协同发音、发音习惯、信道噪声的影响;训练过程中还需要考虑到切分(把输入的语料切分以得到可以处理的较小的部分)和强制对齐(使得每一帧特征严格对应到模型的各个音素上)等复杂技术。这使得连续语音识别的识别准确率和鲁棒性远不及孤立词和特定人识别,同时也使连续语音识别成为语音识别领域极具挑战性的研究课题[1]。
目前主流的语音识别系统主要由三部分组成:特征提取、声学模型以及解码[2]。特征提取的主要功能是从输入的原始语音中提取出有利于后续识别的语音特征。声学模型的主要作用是匹配输入的语音特征,进而识别出对应的语音单元,作为LVCSR系统中的核心模块,声学模型起到了底层支撑的作用,本文主要针对声学模型模块展开研究。
早期语音识别系统大多使用动态时间规整方法进行声学模型构建,这种方法消耗大量内存,计算量巨大;随后高斯混合模型(Gaussian Mixture Models,GMM)与隐马尔科夫模型(Hidden Markov Models, HMM)联合构成的GMM+HMM[3]在声学模型中得到了广泛的应用,一度成为LVCSR系统的标准配置。但是GMM+HMM仍然存在一些缺陷,包括表征能力不强、容易陷入局部最优、未考虑上下文相关信息等。
近年来,深度置信网络(Deep Belief Network,DBN)的提出为建立更加有效的声学模型提供了新的思路,它具有诸多优点:对语音数据的内部结构和概率密度函数要求不严格;可对较长时间段的语音数据进行处理;对不同说话人的说话方式、口音、噪声等干扰的鲁棒性更强;在处理语音数据时,具有更强的建模能力。于是相关学者将DBN引入声学模型,构建了DBN+HMM声学模型[4],DBN的深层模型能够模拟人脑神经网络的工作机理对语音数据进行处理,同时能够完美地与HMM上下文相关三音子模型结合。
DBN+HMM声学模型表现出了诸多的优越性,但是寻求表征更强的模型构建方法始终是我们追寻的目标;同时当前训练模型中存在着过拟合现象,特别是当训练数据比较充足时过拟合现象尤为突出,这会严重影响模型的性能[5]。
相关学者已经将修正线性函数和Dropout策略引入深度神经网络中,并取得了较好的成果。文献[6]首先提出了Dropout策略,作者将Dropout策略应用于前馈神经网络以防止过拟合,在图像识别和英语语音数据集上的实验证明了该方法的有效性;文献[5]在深度神经网络(Deep Neural Networks, DNN)的基础上引入修正线性函数,该方法首先利用受限波尔兹曼机(Restricted Boltzmann Machine, RBM)进行预训练,随后使用贝叶斯方法对网络进行优化,在此基础上还结合了Dropout策略防止过拟合,文章的最后利用所提方法进行图像识别,取得了较好的识别性能;文献[7]使用修正线性节点来改进受限波尔兹曼机,在图像识别中取得了较好的性能;文献[8]使用修正线性节点进行稀疏自动编码机(Auto-Encoder,AE)的训练,在英语语音和图像测试集上取得了较好的识别效果。
针对DBN+HMM声学模型中存在的表征能力不强、过拟合的问题,本文提出一种基于Dropout RDBN(Rectified Deep Belief Network,RDBN)+ HMM的声学模型构建方法,该方法首先使用修正线性函数代替传统的Logistic函数作为激活函数来进行DBN训练,提高了模型的表征能力;同时引入Dropout策略避免模型的过拟合。最后利用Dropout RDBN+HMM声学模型在公开数据集上进行了实验,实验结果表明基于Dropout RDBN +HMM的声学模型构建方法相对于传统方法更有效。
1 基于Dropout RDBN+HMM的声学模型
1.1 DBN基本理论
一个典型DBN的结构图如图1所示。DBN虽然本质上仍然是一种多层感知器神经网络(Multi-Layer Perceptron neural networks, MLP),但是与传统的MLP构建方式不同,它是由一系列受限波尔兹曼机叠加而成的[9-10]。
一个典型的RBM如图2所示,它由两层神经元构建而成的:一层是显层神经元(一般为伯努利型或高斯型),另一层为隐层神经元(一般为伯努利型)。显层神经元和隐层神经元相互连接,但是同一层神经元相互之间没有连接。由于伯努利-伯努利RBM采用的是二进制方式,不能很好地对自然界的真实数据如语音进行建模,因此在实际应用中,一般采用高斯-伯努利RBM对语音进行建模,一个高斯-伯努利RBM的能量函数可以表示为
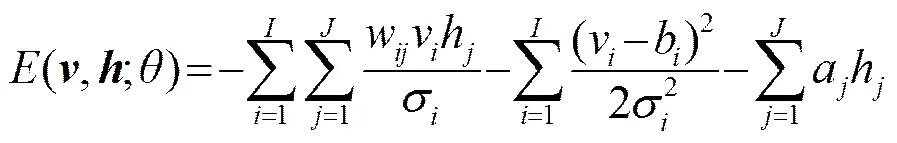
(2)
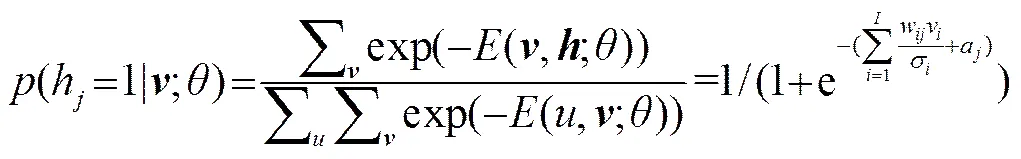
(4)

(6)
(7)
1.2 基于DBN+HMM的声学模型
基于DBN+HMM的声学模型能够对上下文相关的多元音素进行建模,从而得到对应于每一个状态的后验概率,由条件概率公式可以得到HMM状态的输出概率为:
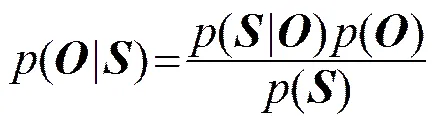
图3 DBN+HMM结构示意图
Fig.3 Schematic diagram of DBN+HMM
1.3 基于RDBN+HMM的声学模型
传统的网络拥有相似的多重前馈网络结构,这些隐含层通过Logistic函数执行近似线性操作。Logistic函数能够使用BP网络对参数进行较好的优化,同时能够挖掘数据的深层次非线性特征,因此一度被认为是深度神经网络的重要组成部分。但是Logistic函数的一些问题同样不容忽视:(1) 当概率较小时,函数近似一种泊松分布,但是当概率的取值逐渐趋近于1时,方差再次变小,这是我们所不期望看到的;(2) 对于小数值的概率,总体输入按概率以指数形式增长,相对于渐进式单元鲁棒性较差;(3) 在使用梯度下降法求取最优解时会遇到梯度消失的问题。因此寻求表征能力更强的模型便成为了进一步研究的方向。图4所示为Logistic 函数()和修正线性函数()。
(a) Logistic函数
(b) 修正线性函数
图4 Logistic函数和修正线性函数
Fig.4 Logistic function and rectified function
由图4可以看到Logistic函数更加平滑,同时有一个函数值上限。相比于传统的Logistic函数,修正线性函数能够拥有更加出色的性能,本文总结了以下几点原因:
(1) 修正线性的这种硬判决的形式更类似于人脑神经网络中神经元信息传递方式,更加具有仿生学特性,这带来了识别速度和准确率的提升[12]。
从函数图形上看,修正线性函数比Logistic函数更接近生物学的激活模型,如图5所示[13]。
(2) 在使用BP算法对网络进行微调优化时,反向传输的过程中使用简单的分段函数(修正线性函数的反函数)进行权重更新。
(3) 修正线性网络的另一个优势是它进行硬判决,即对于输入为负数时,输出取值为零。这使得神经网络仅有一小部分处于激活状态,便达到了神经网络所追求的稀疏特性。
(4) 随着的逐渐增大,修正线性的神经单元输出并不趋于饱和,这一特性是修正线性函数在深度结构中取得优异表现的重要原因——正是因为线性单元的引入,避免了梯度消失的问题。
(5) 修正线性函数的引入使神经网络成为局部竞争网络,局部竞争网络由许多子网络构成,而且子网络之间的大量权重共享使网络更容易训练。如果网络中不存在子网络,训练一个由多个神经网络来完成简单任务将会非常困难:不仅需要全局门限机制,同时要对算法和目标函数进行修正以引入网络之间的竞争。在优化的阶段,子网络在训练的初始阶段使用较短的时间进行组织,使相似的样本拥有更多相同的参数。
图6所示的Maxout函数为一种局部竞争网络,可以想象自动加入一个“隐隐含层”。通过这种同一层节点之间的竞争作用,Maxout这种浅层神经网络取得了较好的识别性能,而本文的修正线性网络则是通过隐层节点与0的竞争作用达到了同样的效果。
由于以上原因,基于修正线性函数打破了传统的Logistic函数的垄断,成为了神经网络训练的主流方法。相关学者通过在语音识别、图像识别等领域的研究发现修正线性不仅能够取得识别准确率的提升,而且能够更方便、快捷地完成训练和识别。
修正线性函数有多种形式,诸如softplus函数(见图7)、过滤修正线性函数(Leaky Rectified Linear,LReL)、噪声修正线性函数(Noisy Rectified Linear Unit,NReLU)等。本节首先对softplus函数进行介绍。
(a) 修正线性函数
(b) Softplus函数
图7 修正线性函数和Softplus函数效果对比图
Fig.7 Rectified function and Softplus function
图7(b)所示为Softplus函数,作为修正线性函数的平滑版本,Softplus函数有许多出色性质,设同一层的单元有着相同的权重矩阵,偏置以固定的数值渐变。如果设置变化量为-0.5,-1.5,-2.5…那么总体的概率分布有一个很好的近似结果,如公式(9)所示:
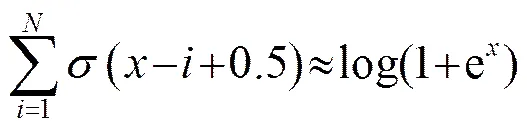
所有单元的总体活跃度接近于修正线性函数的一个噪声、整数、平滑的版本。尽管并不是指数函数族中的成员,但是仍然能够使用共享的权重和递变的偏置来构建它的模型,这种方法并没有引入额外的参数,同时提供了一种更出色的模型训练方法。
随着训练的深入进行,发现如下问题:首先,如果经过修正线性调整在原非零位置重构了一个零结点,在进行权重的反向传导的过程中重构结点无法进行梯度的传播,这使识别准确率大打折扣,严重影响系统性能;其次,由于修正线性输出无上限,权重传输不能应用常规BP网络所使用的方法进行处理。为解决上述问题,本文在DBN中引入噪声项,构建噪声修正线性结点(Noisy Rectified Linear Unit,NReLU)。
由此,训练过程中的公式(2)和公式(3)相应的用公式(10)和公式(11)表示:

(11)
使用BP网络进行优化的过程同样使用修正线性函数进行训练,不引入噪声项,以修正线性节点代替传统的二元节点进行训练,在误差反向传导的过程中使用公式(12)进行。

RDBN的训练流程如下:
(1) 参数初始化;
预训练:
(2) 使用公式(10)、(11)进行修正线性RBM训练;
(3) 采用CD算法利用公式(5)~(7)调整权重和偏置;
(4) 逐层完成RBM训练,RBM初值调整完毕;
微调:
(5) 将预训练的权值赋给相同网络结构的BP网络;
(6) 权重反向传输过程使用公式(12)进行。
1.4 基于Dropout RDBN+HMM的声学模型
1.3节构建了RDBN+HMM的声学模型,识别效果取得了一定提升,但并未达到预期。深入分析过后发现,模型存在过拟合现象,特别是在RDBN中,修正线性函数的硬判决使网络的过拟合现象更为突出。
将为了得到一致假设而使假设变得过度复杂这种现象为过拟合。在DBN中,当训练样本相对于模型参数来说比较充裕的时候,可能产生的分类决策面不唯一的情况,需要多个结点协同对参数进行表示,独立的隐含层节点无法较好地对模型进行表征。这种协同作用在训练集中表现较好、具有较高的分类正确率。但是在测试集中往往表现不佳,因为在训练集上对网络的调整使参数具有了协同作用,在测试集上却无法进行类似的调整。同时,复杂的网络结构不可避免地带来训练速度的降低。
传统解决过拟合问题的主要方法为权值衰减,该方法每次迭代过程中加入一个与网络权值总量相应的惩罚项,进而保持权值较小,使学习过程向着复杂决策面的反方向进行。这种方法对网络的优化调整作用效果有限。
本文考虑从网络结构的角度出发对网络模型进行调整,引入Dropout策略对模型结构进行调整,进而防止过拟合。具体来说,Dropout中每一个结点随机以一定的概率被置零,这样网络结点不能够对其他结点的即时状态做出响应,权值的更新不再依赖于有固定关系的隐含结点的共同作用,阻止了某些结点仅仅在其他特定结点下发挥作用的情况。
从另一个角度来看,一个降低测试集上识别错误率的方法是对大量不同的网络进行训练,然后对训练结果求取均值。标准的方法是训练很多不同的网络结构,然后使用这些网络结构进行数据的测试。但是这种方法无论在训练还是测试阶段计算成本都十分可观。随机进行Dropout使得在同一时间对大量的不同的网络结构进行训练成为可能。对于每一次输入到网络中的样本,对应的网络结构都有差异,但这些网络结构同时共享隐含层结点的权值,从而达到了求取均值的目的。
本文将Dropout策略引入RDBN+HMM中,提出了基于Dropout RDBN+HMM的声学模型构建方法。Dropout RDBN+HMM训练的总体思路是:在每个训练样本训练时,对于每一个隐含层的每一个结点来说,都按照一个固定的概率决定它是否激活,若某个结点不幸没被激活,便视该结点的输出值为0。相比于RDBN+HMM,引入Dropout后网络结构应做如下调整:
(1) 训练阶段:前馈网络的部分权值的每一个隐含层结点的输出值以一定的百分比随机置零,这样便完成了Dropout前馈网络的构建;
(2) 训练阶段:由于前馈网络中使用Dropout,在微调部分权重反向传输的过程中要进行相应的调整,具体操作为网络计算结点误差时将误差以一定的几率置零;
(3) 测试阶段:前馈网络部分对于前馈网络的处理与训练阶段相同,以相同的百分比将权重置零。
2 实验结果与分析
2.1 数据集
本文采用的数据集分为两部分:第一部分为普通话评测第四题数据集。训练集共包含语音76843句,共64.1小时;测试集含3720句,共2.6小时,两个集共含2000多个说话人。
第二部分数据集会话主题开放,表达方式较为随意、信道噪声复杂,是中文连续语音识别难度较大的任务之一,其训练集和测试集如表1、2所示。
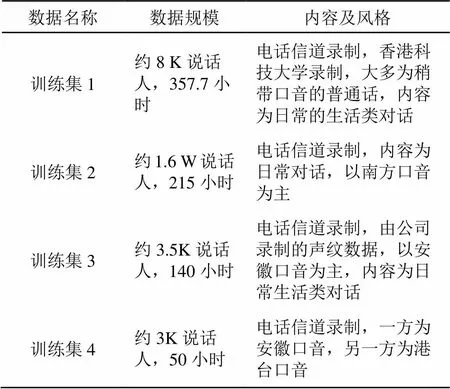
表1 训练集
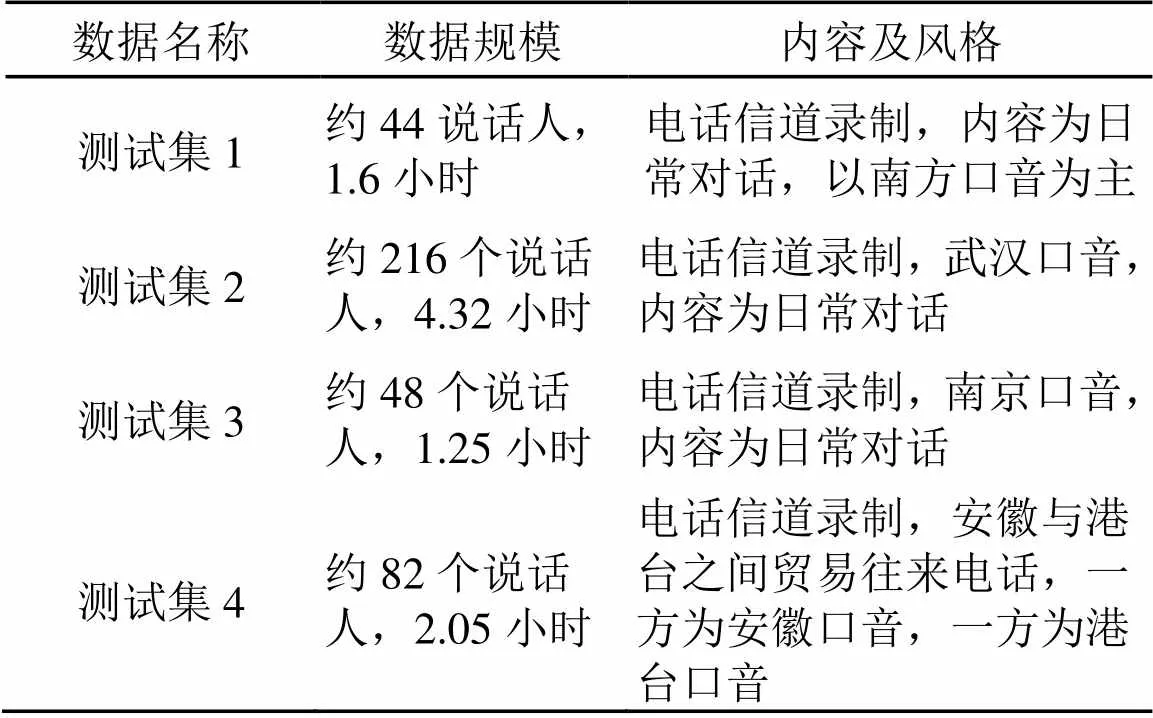
表2 测试集
2.2 实验系统构建
本文采用的语音识别基线系统为DBN+HMM音素识别系统。首先进行滤波器组特征提取,随后进行声道参数规整(Vocal Tract Length Normalization,VTLN VTLN),再进行DBN训练,采用72维的滤波器组特征[14]作为单帧特征(静态、一阶、二阶差分),考虑到4维音调特征,共79维,每一帧前后各扩展5帧得到11帧的音素作为每一维的输入。
滤波器组特征是对梅尔域倒谱系数特征(Mel Frequency Cepstral Coefficients, MFCC)特征的调整,图8为MFCC特征提取流程。
进行深入分析后发现,从信息的丰富程度来看,MFCC是经过了降维处理的,在降维过程中尽管只舍弃掉了离散余弦变换变换后一些不重要的维,但是这些维仍然包含一定的有用信息。因此,本文考虑采用降维之前的特征即经过Filter Bank滤波器组以后的输出替换MFCC用来训练DBN,Filter Bank特征提取流程如图9所示。
为了与MFCC尽可能相似,本文仍然使用了一阶差分、二阶差分和静态特征拼接在一起,并且拼接上了4维的Pitch特征。最终的特征网络变为79*11-[2048-2048-2048-43]-3936。
本文使用文献[15]给出的参数设置方法进行参数调节。权重以均值为0、方差为0.01的高斯分布取值;预训练过程中设定训练周期为200;批大小(Batch Size)为1024;迭代次数为10次。Momentum被用来加速训练,初始选取为0.5,通过20次迭代线性增长到0.9;L2正则惩罚因子为0.002;声学模型规整因子为1.2。
2.3 实验结果及分析
本文设计了三组实验来验证本文所提出的声学模型构建方法的有效性,实验1在规模较小的PSC数据集上对RDBN+HMM的学习速率和权重衰减系数进行调整;实验2对Dropout的置零率进行调整;实验3在以上实验的基础上对Dropout RDBN+HMM声学模型性能进行了验证。
本文使用词错误率(Word Error Rate, WER)作为评价标准。通过对比不同模型的WER对模型的性能进行评估。
2.3.1 实验1
首先,本文对预训练的学习速率进行了调整。具体实验结果如表3所示。

表3 预训练学习速率对词错误率的影响表
可见,当学习速度较大时,会导致整个训练过程不收敛,从而出现无法进行训练的情况,而学习速度为0.0125时就出现了不收敛的现象。从表3结果来看,学习速度对整个预训练过程的影响较小,学习速度取在0.01时能够取得最优性能,在后续的训练中将学习速度统一设置为0.01。
随后,本文进行了权重衰减系数的调整,测试不同预训练权重衰减系数对识别性能的影响,具体实验结果如表4所示。
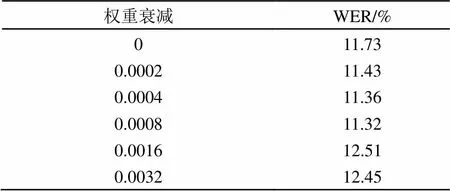
表4 不同权重衰减对词错误率的影响
权重衰减在每次迭代过程中以小因子降低每个权值,加入一个与网络权值的总量相应的惩罚项,保持权值较小,从而使学习向着复杂决策面的反方向进行,有效地防止过拟合。从表4识别结果可以看出,较小的权重衰减能够从一定程度上防止过拟合,提升识别性能,但是当权重衰减较大时,网络反而不能达到所需的精度,识别性能开始下降。权重衰减系数为0.0008能够达到最优的性能。因此,本文中采用0.0008的权重衰减系数。
2.3.2 实验2
在试验2中本文重点研究Dropout置零率对系统识别性能的影响,实验中置零率分别设置为0、0.1、0.2、0.3、0.4、0.5、0.6、0.7。在测试集2上测试的结果表5所示。
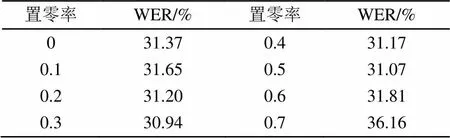
表5 不同置零率对词错误率的影响
通过实验,Dropout的置零率在0.3时系统取得最优效果,过高或过低的置零率都会带来识别准确率的下降,因此本文在后续实验中Dropout置零率统一设置为0.3。
2.3.3 实验3
在上述实验的基础上,本实验针对本章所提出的基于Dropout RDBN+HMM声学模型进行实验验证,分别建立了传统基于DBN+HMM的声学模型、基于RDBN+HMM的声学模型、基于Dropout DBN+HMM的声学模型以及基于Dropout RDBN+HMM的声学模型,在数据集2上对上述模型进行验证,实验结果如表6所示。
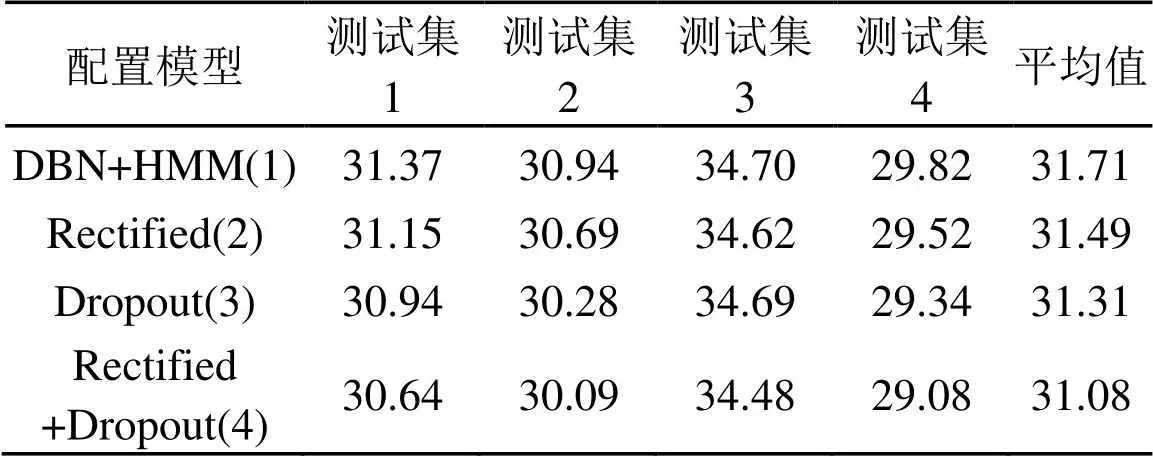
表6 不同声学模型的识别性能对比
通过实验发现:①模型(1)和模型(2)实验结果表明,在不同的数据集上,基于RDBN+HMM的声学模型相对于传统的DBN+HMM的声学模型均取得了效果的提升,符合实验预期,表明了基于RDBN+HMM的声学模型是一种表征能力更强的声学模型构建方法;②模型(1)和模型(3)的实验结果表明:Dropout DBN+HMM相对于传统的DBN+ HMM取得了一定的词错误率提升,Dropout策略能够防止过拟合;③模型(4)有着最佳的实验结果,证明了Dropout策略能够与修正线性网络协同作用于DBN+HMM,这使得基于Dropout RDBN+HMM的声学模型在拥有较强表征能力的同时,能够利用Dropout策略防止模型过拟合。
修正线性结点的硬判决有助于识别速度的提升,能够抵消Dropout策略的引入给模型训练速度带来的负面影响。考虑到模型训练过程中要引入切分、强制对齐等技术进行分步训练,难以对模型训练时间进行准确把握,同时声学模型训练过程的耗时对解码识别过程影响不大,故未对训练速度做定量分析。
3 总结
本文提出一种基于Dropout RDBN+HMM的声学模型构建方法。该方法使用修正线性函数代替传统的Logistic函数进行DBN的训练,使用修正线性函数的硬判决对网络进行优化,增强了模型的表征能力;同时引入Dropout策略对网络模型进行调整,防止训练过程中出现过拟合,促使系统构成一个均值网络,提高了网络的泛化能力。本文在声道环境复杂、会话主题多样的多个数据集中进行了测试,新的声学模型构建方法相对于传统方法取得了2.0%的词错误率提升,表明本文提出的基于Dropout RDBN+HMM的声学模型构建方法相对于传统方法的优越性。
[1] 郑铁然. 基于音节网格的汉语语音文档检索方法研究[D]. 哈尔滨: 哈尔滨工业大学.2008.
[2] 韩纪庆, 张磊, 郑铁然. 语音信号处理[M]. 北京: 清华大学出版社. 2004.
[3] Torres-Carrasquillo P A, Singer E, Kohler M A., et al. Approaches to language identification using gaussian mixture models and shifted delta cepstral features [C]//Proc ICSLP. 2002: 33-36.
[4] Mohamed A, Dahl G, Hinton G. Acoustic modeling using deep belief networks [J]. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(1): 14-22.
[5] Dahl G E, Sainath T N, Hinton G E. Improving deep neural networks for lvcsr using rectified linear units and dropout[C]//ICASSP, 2013.
[6] Hinton G, Srivastava N, Krizhevsky A, et al. Improving neural networks by preventing co-adaptation of feature detectors[J]. The Computing Research Repository, abs/1207.0580, 2012.
[7] Vinod Nair, Geoffrey G, Hinton. rectified linear units improve restricted boltzmann machines[C]//ICML-10.2010.
[8] Zeiler M D, Ranzato M, Monga R., et al. On Rectified Linear Units for Speech Processing[C]//ICASSP, 2013.
[9] Hinton G, Salakhutdinov R.. Reducing the dimensionality of data with neural networks [J]. Science. 2006, 313(5786): 504-507.
[10] Yu D, Seltzer M. Improved bottleneck features using pre-trained deep neural networks[C]//Proceedings of the International Speech Communication Association, 2011, Florence, Italy: 237-240.
[11] Yu D, Deng L, Dahl G E. Roles of pre training and fine-tuning in context-dependent dbn-hmms for real-world speech recognition[C]//NIPS 2010 Workshop on Deep Learning for Speech Recognition and Related Applications, 2009.
[12] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks[C]//Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, 2011.
[13] Purves D, George J, Augustine, Fitzpatrick D, et al. Neuroscience [M]. 2nd, Sinauer Associates Inc, 2001. ISBN 087893-741-2.
[14] Chakroborty S, Roy A, Majumdar S, et al. Capturing complementary information via reversed filter bank and parallel implementation with mfcc for improved text-independent speaker identification[C]//Computing: Theory and Applications, 2007 ICCTA07 International Conference on: IEEE. 2007: 463-467
[15] Hinton G. A practical guide to training restricted boltzmann machines [R]. Technical Report 2010-003, Machine Learning Group, University of Toronto, Canada, 2010.
Acoustic model based on Dropout rectified deep belief network in large vocabulary continuous speech recognition system
CHEN Lei1, 2, YANG Jun-an1,2, WANG Long1, 2, LI Jin-hui1, 2
(1. Electronic Engineering Institute, Hefei 230037, Anhui, China;2. Key Laboratory of Electronic Restriction, Anhui Province, Hefei 230037, Anhui, China)
To improve representation ability of acoustic model and prevent over fitting in large vocabulary continuous speech recognition system, this article proposes a method of establishing the acoustic model based on Dropout rectified Deep Belief Network (DBN). This method uses rectified linear function instead of traditional Logistic function as the activation function for DBN training, and the rectified linear function that is closer to the working mode of biological neural network can improve acoustic representation ability of the model, simultaneously Dropout strategy is introduced to avoid the synergy between nodes and to prevent over fitting. The actual test certificate on public speech databases proves the superiority of the proposed method over the conventional one.
large vocabulary continuous speech recognition; deep belief network; rectified linear function; over fitting; Dropout
TP391
A
1000-3630(2016)-02-0146-09
10.16300/j.cnki.1000-3630.2016.02.0012
2015-03-08;
2015-04-17
国家自然科学基金资助项目(60872113)
陈雷(1990-), 男, 辽宁铁岭人, 硕士研究生, 研究方向为语音识别和机器学习。
陈雷, E-mail: plory89@163.com
