基于主成分分析法的风电功率短期组合预测
2016-09-06吴金浩杨秀媛
吴金浩 杨秀媛 孙 骏
(北京信息科技大学,北京 100192)
基于主成分分析法的风电功率短期组合预测
吴金浩杨秀媛孙骏
(北京信息科技大学,北京 100192)
间歇性与不确定性是风力发电的固有特性,在风力发电迅速发展的背景下风电功率预测的重要性日渐凸显。为了减少单一模型在个别预测点误差较大的情况,提高整体预测方法的预测精度及相对误差率,本文采用反向传播(BP)神经网络以及支持向量机(SVM)两种基本模型进行组合,并引入粒子群(PSO)以及交叉验证(CV)算法来优化模型中的参数。结合主成分分析法(PCA)对原始数据进行预处理,在不降低预测精度的前提下,对原数据进行降维处理从而提高运算效率。使用模型分别对未来5天进行预测,结果表明组合预测模型的标准平均误差(NMAE)、标准均方根误差(NRMSE)都满足国内现行指标,而且预测精度比单一模型有很大提高,相对误差更加稳定,有效减少了较大误差点的出现。实例研究表明,基于主成分分析法的风电功率短期组合预测模型的可行性。
风功率预测;主成分分析法;BP神经网络;粒子群算法;支持向量机;组合预测
随着对风力发电的深入研究,风电固有的间歇性以及不确定性成为了制约其发展的主要因素。大容量风电场接入电网后,造成电网电压、频率的波动,给调度运行带来很大困难,甚至威胁到电力系统的稳定运行。因此,及时、精确地预测风电功率是首先需要解决的问题[1-2]。
目前,已经有研究人员做了风电功率预测多种方面的研究。文献[3]使用时间序列法建模,得到预测时刻与前段时刻风速的关系,并确定神经网络输入变量数目,这种方法本质是基于时间序列模型,在风况发生突变时无法准确预测,对较长时间的预测也无法得到精确结果;文献[4]理论分析得出风功率由风速、风向等因素决定,使用数值天气预报系统收集的历史数据,建立BP神经网络模型,在风电场实装显示预测效果良好,模型预测误差在15%左右,需要进一步优化或者开发更精确的预测模型;文献[5]将粒子群(PSO)算法与基于前向神经网络模型相结合,从而提高功率预测的精度,结果显示模型平均误差以及标准差都有不同程度地下降,预测准确率高于优化前的结果;文献[6]使用交叉熵理论来确定组合预测的权值,先分析各预测模型的交叉程度,再根据公式求取权值,结果显示使用交叉熵理论的组合模型精度较高。
目前传统的组合预测的只是解决了单一预测模型可能出现较大误差的问题,但基础组合算法本身精度并不高,而且普遍存在运算时间较长、无法在工程上应用的问题。本文先对基础算法进行优化,提高BP神经网络与SVM的精度再进行组合,这样整体预测效果获得很大提升。然后使用主成分分析法对原始数据进行主成分分析数据预处理,在不降低预测精度的前提下减少运算时间。实测数据研究表明,本文提出的组合预测模型可以稳定、高效的完成预测任务,具有很大工程应用的潜力。
1 主成分分析法
主成分分析法(principal components analysis,PCA)是一种多元统计分析方法,利用降维的思想在少量信息损失的前提下,将多个指标转化为若干综合指标[8]。因此,面对多输入因素的问题,只需考虑几个主要的组成部分,从而使问题得到简化,提高分析效率。结合本文风电功率预测模型,可用于解决预测模型输入变量多、部分变量之间相关、运算时间过长的问题。
理论分析表明:主成分是原数据矩阵的协方差矩阵的特征向量的线性组合,它们是互不相关的,其方差为数据矩阵的特征根。计算出矩阵的特征根值并按照顺序排列为λ1≥λ2≥…≥λp> 0。其中,第一主成分的贡献率定义为,是第一主成分的方差与总方差和的比值;前两个主成分的贡献率定义为,前k个主成分的累计贡献率定义为。当前k个主成分的贡献率达到85%,就可以认为主成分可以代替原始数据。
选择风速、风向、温度、湿度和压强五个因素作为预测模型的输入项。对风向分别进行正弦、余弦计算,得到六维的原始输入数据,然后运用PCA对原数据分析处理。
2 预测模型及优化方案
2.1预测模型的选择
风电输出功率与风速、风向等多种因素有关,使用传统的建模方式很难精确表达。人工智能方法如BP神经网络、SVM等具有较强的非线性学习能力,能通过统计数据学习得到其内在关系。BP神经网络与SVM都具有很强的模式分类和非线性函数逼近能力,BP神经网络采用的是基于经验风险最小化原则,而SVM是基于结构风险最小化原则,考虑的是经验风险和置信界之和的最小化。两种方法在非线性函数拟合方面各有优势,具有组合互补的可行性。
2.2BP神经网络模型与粒子群算法参数优化
BP(Back Propagation)神经网络是一种按误差逆向传播算法训练的多层前馈网络(Multilayer Feedforward Neural Networks,MFNN)模型[11]。网络结构如图1所示,u和y分别是网络的输入、输出向量,网络由输入层、隐层和输出层节点组成,前层至后层节点通过权值连接。

图1 BP神经网络示意图
传统的BP神经网络使用梯度下降法调整参数,这种方法相邻两次迭代的搜索方向是正交的,迭代在向极小值靠近的过程中,走的是曲折的路径,使得网络收敛速度下降,可能找到的是局部极值而不是整体极值。为解决这些问题,采用粒子群优化算法(Particle Swarm Optimization,PSO)来进行参数寻优。粒子群算法是一种群体智能算法,根据生物种群特性,所有粒子都将跟随最优粒子在空间中移动,直到找到问题的极值。PSO算法优化BP神经网络整体流程如图2所示。
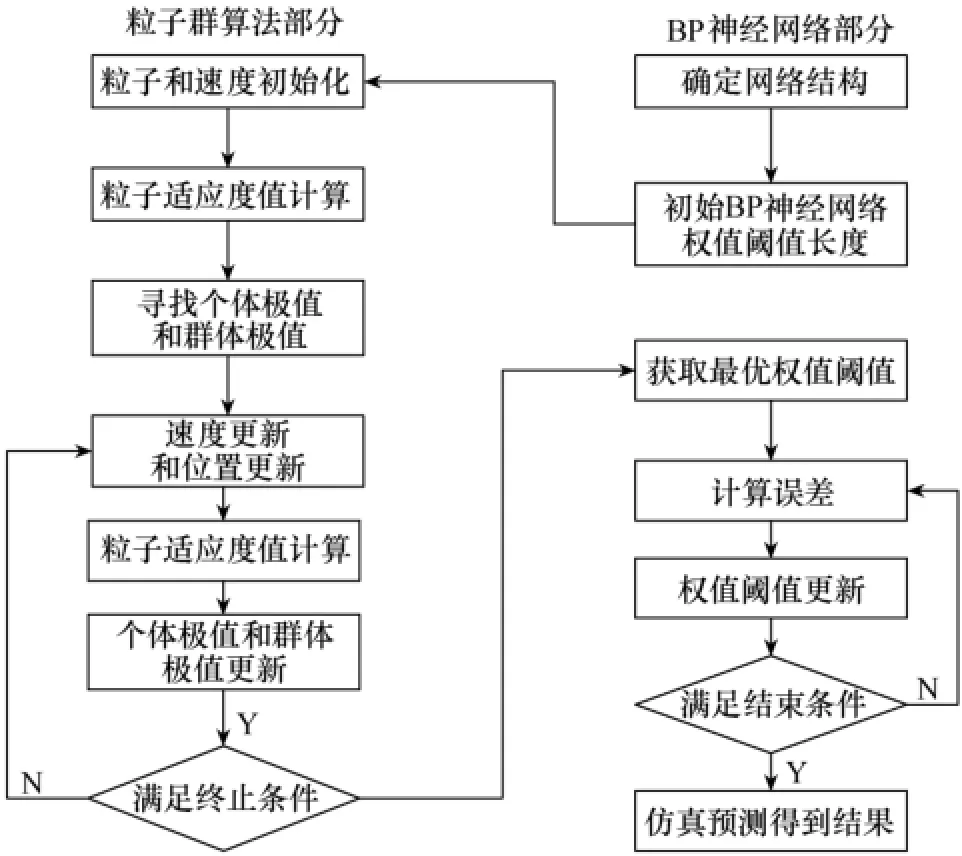
图2 PSO-BP神经网络流程图
2.3支持向量机模型与交叉验证算法参数优化
支持向量机(support vector machine,SVM)是90年代中期发展起来的基于统计学理论的一种机器学习方法,通过寻求结构风险最小来提高学习机泛化能力,在统计样本数量较少时也能获得良好的统计规律[12]。SVM主要任务是在空间中寻找一个最优超平面来逼近目标函数,其基本原理如图3所示。
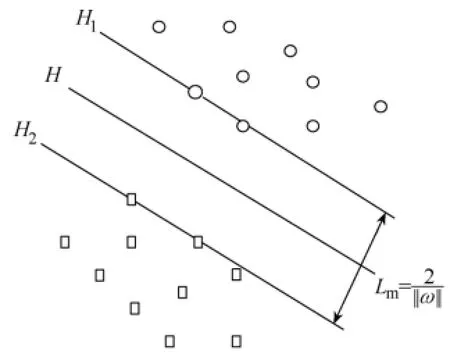
图3 SVM原理示意图
图3中,H为分类超平面;1H和2H为距分类超平面最近的两平行面;mL为两平面间隔。假设样本是线性可分的,任务就是实现把样本点分开,且保证分类间隔尽可能大。实际情况多数样本都是线性不可分的,使用一个非线性映射,把低维的输入数据映射到高维特征空间,然后在高维空间内寻找最优分类平面。
当使用SVM模型进行回归预测时,寻找最优的惩罚参数c和核函数参数g能得到比较理想的预测准确率。本文使用交叉验证法(cross validation,CV)来确定参数c和g,首先将原始数据分成K组,将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为交叉验证法下分类器的性能指标。CV算法优化SVM整体流程如图4所示。

图4 CV-SVM流程示意图
3 风电功率预测的组合模型
3.1组合模型的概念
组合预测就是使用多种预测方法对同一模型预测,根据不同的计算规则确定预测方法的权值,最后整合为一个综合模型[17]。采用组合预测法消除单一预测方法中的较大误差,提高整体模型的稳定性。
假设使用m种方法对模型分别预测,单一预测方法的预测值分别为fi, i=1,2,…,m 。则组合预测可表示为f=l1f1+l2f2+…+lmfm,其中l1, l2,…,lm为各种预测方法的加权系数。组合预测的主要任务是确定各预测方法的权值,下文给出三种常见的加权系数计算方法。图5经过优化的BP神经网络与SVM预测模型的组合示意图。

图5 组合预测模型
3.2算术平均法
算术平均法也称为等权平均法,对m种单项预测模型取相同的权值,即各模型比重相同。算术平均法适用于无法确定单项预测模型详细精确度的情况。由于算术平均方法计算简单,工程上可以快速得出结果,适用性比较强。
系数计算式:

3.3预测误差平方和倒数法
预测误差平方和倒数法,考虑到每种方法的预测精度,是一种非等权值的计算方法。需要先计算出每种预测的误差平方和,这个值越大对应的预测精度就越低,相应模型的权值也会比较小,再根据系数计算公式求取每种模型的权值,该方法更符合客观规律。
系数计算公式:

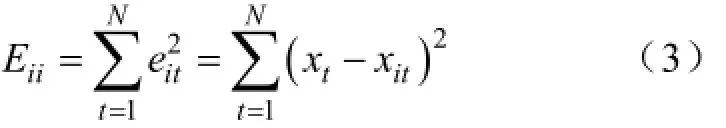
式中,itx为第i种方法在第t时刻的预测值,tx为同一对象在第t时刻的观测值,ite为第i种单项预测方法在第t时刻的预测误差。
3.4二项式系数法
二项式系数法也是一种非等权计算方法,具体做法与平方和倒数不同。需要先求各单一预测模型的误差方差和Eii,再对其进行排序,不妨设E11>E22>…>Emm。根据统计学中位数的概念,排在中间模型对应的权系数最大,远离中位数的模型权系数较小。
系数计算式:

4 风电功率预测评估指标
国家能源局2011年发布的《风电场功率预报管理暂行办法》规定风电场功率预测系统提供的日预测曲线最大误差不超过25%;实时预测误差不超过15%;全天预测结果的均方根误差应小于20%[19]。
现行行业标准[20]及文献广泛采用标准平均误差(normalized mean absolute error, NMAE)、标准平均相对误差(normalized mean relative error,NMRE)、标准均方根误差(normalized root mean square error, NRMSE)等来评估风功率预测效果。NMAE指预测值与真实值之间平均相差多少,是绝对误差的平均值;NMRE是指绝对误差占真实值的百分比;NRMSE是观测值与真实值偏差的平方和观测次数n比重的平方根,反映预测的精密度。

式中,x(i) 为样本真实值;x′(i)为样本预测值;capP是风电场的额定装机容量;N为预测样本个数。本文采用前两个指标来评估预测模型。
5 算例分析
5.1风电场基本情况
本文算例风电场装备80台额定容量1.5MW的双馈感应风力发电机组(WPG-DFIG),总装机容量为120MW,风机轮毂高度65m,叶轮直径58m。连续采集2013年5月的各项数据,数据分辨率为15min。使用5月前26天数据训练模型,首先选择5月27日作为预测日,预测长度为一天,即96个点。每一点输入项为风机实时风速、风向、温度、湿度和压强五个因素,输出项为风电机组实时输出功率。然后使用训练好的模型,分别对28、29、30、31日进行预测并作误差分析。
5.2PCA数据预处理
首先对数据进行归一化处理,统一各参数的量纲。风速归一化采用公式对实时风速进行处理,式中vmax为历史最大风速。气温、气压、湿度的归一化方法与风速一致。风向可能在0°~360°之间变化,只对风向取正弦值或余弦值并不能完全区分0°~360°内所有风向,因此风向要取正弦、余弦两个值来描述。归一化后训练数据为一个2496×6的矩阵,预测数据为一个96×6的矩阵。
然后进行主成分提取,计算归一化后训练数据的协方差矩阵,求出协方差矩阵的特征根及贡献率并依据累积贡献率提取主成分,计算结果见表1。
由表1可知前三个特征值累计贡献率已达96.9719%,说明前三个主成分基本包含了全部信息,取前三个特征值,计算出相应的特征向量,计算结果见表2。
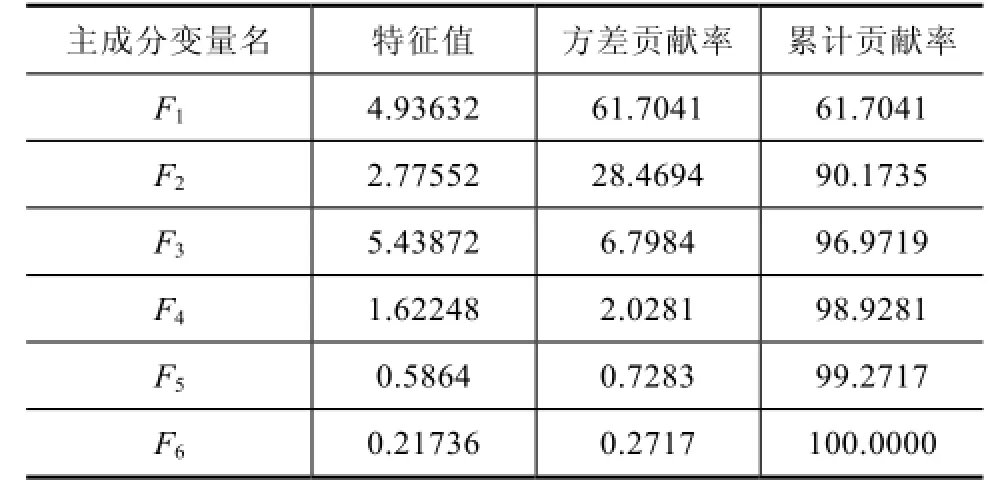
表1 特征值及贡献率

表2 特征向量表
通过特征向量写出主成分表达式如下:
第一主成分:

第二主成分:

第三主成分:

通过上述表达式对数据进行PCA处理,则训练数据转换为2496×3的矩阵,预测数据转换为96× 3的矩阵。处理后变为3个输入参数,这3个输入互不相关且包含原来参数所有的信息。原来几项参数之间互有联系,全部作为输入会导致信息冗余,经过PCA处理后可以在不影响精度的情况下,提高运算速度。
5.3单一模型的预测
对于BP神经网络模型,选用包含一个隐含层的3层网络,隐层神经元传递函数采用S型正切函数,输出层神经元传递函数采用S型对数函数。进过PCA数据预处理后,输入变为3维,隐层节点数定为7。方向传播使用梯度下降法调整权值和阈值。然后使用粒子群算法优化BP神经网络的初始权值和阈值,进化次数定为30,种群规模定为60。为防止粒子盲目搜索,将其位置和速度分别限制在区间[5,5]-[0,1]。
表3是两种预测方法的标准平均误差、标准均方根误差以及训练时间。图6是两种预测方法得到的一天时间(96个点)预测结果。可以看出,BP神经网络可以基本完成预测任务,经过粒子群算法参数寻优后预测精度得到进一步提高,但某些点明显存在误差过大的情况,单独使用这一种模型效果不佳。
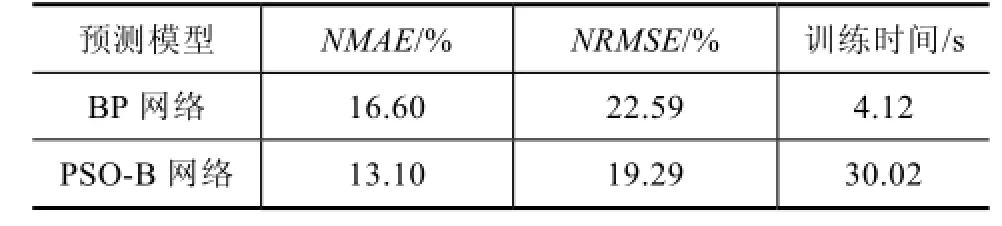
表3 神经网络模型预测误差及训练时间
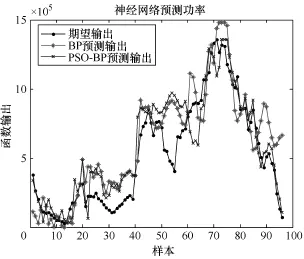
图6 神经网络模型预测效果对比
对于支持向量机模型,使用径向基函数作为核函数,svmtrain程序中的惩罚参数c和核函数g,任意给定两个较小的值。然后使用交叉验证的方法,通过计算可以找到一定意义最佳的参数c和g。
表4是两种预测方法的标准平均误差、标准均方根误差以及训练时间。图7是两种预测方法得到的一天时间(96个点)预测结果。可以看出,经过交叉验证参数寻优后预测精度有所提高,但两种预测模型也存在在某些点误差比较明显的情况。SVM预测精度与BP神经网络的预测精度在同一水平,而且误差较大的点并不一致,这是下文两种模型组合的基础。

表4 支持向量机模型预测误差及训练时间

图7 支持向量机模型预测效果对比
5.4组合模型的预测
两种经过参数优化后的模型PSO-BP以及CV-SVM的标准平均误差均小于15%,标准均方根误差均小于20%,且数值在同一数量级,符合组合预测的要求。根据上文计算公式得到三种模型的权系数见表5,三种组合模型预测误差及训练时间见表6,组合模型的预测结果如图8所示,相对误差如图9所示。
由于图8可以直观看到,组合预测的预测效果十分明显。其中平方和倒数模型的预测精度最高,其标准平均误差为9.31%,标准均方根误差为12.63%,比单一预测模型以及其他方法相比优势明显。由于选取的两种模型本身精度差距不大,因此可以看到算术平均模型的精度排第二,在工程上使用可以牺牲精度而提高效率。二项式模型效果较差,这是由于本文只选取了两种模型组合,如选三种及以上数量的模型组合,二项式模型就能发挥很好的作用。三种模型的预测时间基本等同于原来两种预测模型的时间之和。由图9可以看出基本上预测点误差值能保持在一点范围内,显示出了组合预测模型平稳的优势。图中只有一个点有相对误差大于10%,但不能排除该数据本身有误的可能性。

表5 三种组合模型权系数

表6 三种组合模型预测误差及训练时间

图8 三种组合模型的预测结果

图9 三种组合模型的预测相对误差
使用平方和倒数组合模型分别对5月28日、29日、30日、31日进行预测,并作误差分析,结果如表7所示,而且无较大相对误差的出现。最后可以得出使用本文的组合模型能有效减少较大误差的出现,提高预测精度的结论。

表7 未来4日预测误差及训练时间
6 结论
本文基于实测数据,先使用PCA方法对数据进行降维处理,后建立组合预测模型预测未来24h风力发电功率。从数据预测效果和误差分析,可以得到以下结论:
1)主成分分析法可以对观测变量降维,能够客观地反映影响风功率预测的各种影响因素,在保证预测精度的前提下提高运算速度。
2)经过参数优化后PSO-BP神经网络与CV-SVM模型可以获得高的预测精度,两种模型精确度在同一水平而且误差较大的点不尽相同,适合进行模型组合。
3)分别求出算术平均法、误差平方和倒数法、以及二项式系数法的权值,分析得出组合预测可以有效减少较大误差的出现,从而提高预测精度。本文两种模型组合的情况,误差平方和倒数法模型精度最高。
4)组合预测受基础预测模型精度的限制,因此选择合适的两种或者多种组合模型是关键。目前风电功率物理预测模型发展迅速,未来可以考虑将历史数据外推模型与物理模型组合起来,以应对各种复杂地形、不同天气条件下预测任务。
[1] 何东, 刘瑞叶. 基于主成分分析的神经网络动态集成风功率超短期预测[J]. 电力系统保护与控制,2013, 4(4): 50-54.
[2] 周松林, 茆美琴, 苏建徽. 基于主成分分析与人工神经网络的风电功率预测[J]. 电网技术, 2011, 35(9):128-132.
[3] 杨秀媛, 肖洋, 陈树勇. 风电场风速和发电功率预测研究[J]. 中国电机工程学报, 2005, 25(11): 1-5.
[4] 范高锋, 王伟胜, 刘纯. 基于人工神经网络的风电功率短期预测系统[J]. 电网技术, 2008(22): 72-76.
[5] 杨志凌, 刘永前. 应用粒子群优化算法的短期风电功率预测[J]. 电网技术, 2011, 05(5): 159-164.
[6] 陈宁, 沙倩, 汤奕, 等. 基于交叉熵理论的风电功率组合预测方法[J]. 中国电机工程学报, 2012(4):29-34, 22.
[7] 孟安波, 陈育成. 基于虚拟预测与小波包变换的风电功率组合预测[J]. 电力系统保护与控制, 2014,3(3): 71-76.
[8] 罗毅, 刘峰, 刘向杰. 基于主成分—遗传神经网络的短期风电功率预测[J]. 电力系统保护与控制,2012(23): 47-53.
[9] 王丽婕, 冬雷, 高爽. 基于多位置NWP与主成分分析的风电功率短期预测[J]. 电工技术学报, 2015, 5(5): 79-84.
[10] 王丽婕, 冬雷, 廖晓钟, 等. 基于小波分析的风电场短期发电功率预测[J]. 中国电机工程学报, 2009(28):30-33.
[11] 范高锋, 王伟胜, 刘纯, 等. 基于人工神经网络的风电功率预测[J]. 中国电机工程学报, 2008(34):118-123.
[12] 王贺, 胡志坚, 仉梦林. 基于模糊信息粒化和最小二乘支持向量机的风电功率波动范围组合预测模型[J]. 电工技术学报, 2014(12): 218-224.
[13] Ernst B, Oakleaf B, Ahlstrom ML, et al. Predicting the wind[J]. Power and Energy Magazine, IEEE, 2007,5(6): 78-89.
[14] Peiyuan C, Pedersen T, Bak-Jensen B, et al. ARIMA-based time series model of stochastic wind power Generation[J]. IEEE Transactions on Power Systems, 2010, 25(2): 667-676.
[15] Chen Xia, Dong Zhaoyang, Meng Ke, et al. Electricity price forecasting with extreme learning machine and bootstrapping[J]. IEEE Transactions on Power Systems,2012, 27(4): 2055-2062.
[16] 刘纯, 范高锋, 王伟胜, 等. 风电场输出功率的组合预测模型[J]. 电网技术, 2009(13): 74-79.
[17] Rodrigues AB, Da Silva MD. Confidence intervals estimation for reliability data of power distribution equipments using bootstrap[J]. IEEE Transactions on Power Systems, 2013, 28(3): 3283-3291.
[18] Khosravi A, Nahavandi S, Creighton D. Prediction intervals for Short-Term wind farm power Generation forecasts[J]. IEEE Transactions on Sustainable Energy,2013, 4(3): 602-610.
[19] 风电场功率预测预报管理暂行办法[S]. 北京: 国家能源局, 2011
[20] 风电功率预测功能规范[S]. 北京: 国家电网公司,2011.
The Combination Forecasting Model for Wind Farm Power based on PCA
Wu Jinhao Yang Xiuyuan Sun Jun(Beijing Information Science and Technology University, Beijing 100192)
Intermittency and uncertainty is the inherent characteristics of the wind power and in the rapid development of wind power generation background the importance of wind power forecasting is becoming more and more obvious. In order to reduce the error of the single model and are improve the prediction accuracy and relative error rate of the whole forecasting method, the paper combine two basic models of BP neural network and support vector machine(SVM), and introduce the particle swarm and cross validation to optimize the parameters. The original data are preprocessed by principal component analysis (PCA). In the premise of little reducing the accuracy of prediction, the original data is reduced to the dimension of the original data to improve the operation efficiency. The results show that the NMAE and NRMSE of the combined forecasting model meet the domestic current index. And the accuracy of the model is improved, and the relative error is more stable. This method can effectively reduce the appearance of large errors. In the final, these prove the feasibility of the combination forecasting model for wind farm power based on PCA.
wind power forecast; principal components analysis (PCA); BP neural network; particle swarm; support vector machine (SVM); forecast combination
国家自然科学基金(51377011)
吴金浩(1988-),男,山东省济宁市兖州区人,本科,主要从事风电场与水电厂协同运行研究工作。
