3D-HEVC中深度图编码技术研究进展
2016-08-22雷海卫刘文怡王安红
雷海卫,刘文怡,王安红
(1. 中北大学 仪器科学与动态测试教育部重点实验室,山西 太原 030051;2. 太原科技大学 电子信息工程学院,山西 太原 030024)

3D-HEVC中深度图编码技术研究进展
雷海卫1,刘文怡1,王安红2
(1. 中北大学 仪器科学与动态测试教育部重点实验室,山西 太原 030051;2. 太原科技大学 电子信息工程学院,山西 太原 030024)
3D-HEVC是为了满足3D视频和自由视点视频的高效编码而最新制定的视频编码标准,它要求同时编码几个视点的纹理视频和深度图。完全采用传统的技术来编码深度图会使得深度图内部锐利边界处产生伪影效应,为此,一些新的针对于深度图的编码工具被开发。详细介绍了这些编码工具,同时介绍了编码深度图时所使用的率失真优化方法。
3D-HEVC;深度图编码;率失真优化
1 3D-HEVC简介
HEVC(High-efficiency Video Coding)作为最新一代的视频编码标准由运动图像专家组(Moving Picture Experts Group,MPEG)和国际电信联盟电信标准化部(International Telecommunication Union Telecommunication Standardization Sector,ITU-T)的视频编码专家组共同建立的视频编码联合协作小组(Joint Collaborative Team on Video Coding,JCT-VC)在2013年制定完成。由于其高效性(相比AVC/H.264,性能翻倍)被广泛关注。随后,为了满足3D视频和自由视点视频的高效编码需求,3D视频编码协作小组(Joint Collaborative Team on 3D-Video, JCT-VC)成立,负责制定一个新的视频编码标准——3D-HEVC[1-2]。
3D-HEVC作为HEVC的扩展,用来编码深度增强的3D视频,格式可以是立体视频、多视点视频以及多视点视频加深度。这种灵活的配置结构可以适用于不同的解码器,也可以满足在不同显示设备上的显示需求。3D-HEVC的系统结构如图1所示。

图1 3D-HEVC的系统结构
通常,编码器端需要对几个视点(包括基本视点和依赖视点)的纹理视频以及对应的深度图进行编码,产生既包含纹理又包含深度信息的码流,相机参数也包含在码流中。解码器端如果是一个3D视频解码器,那么编码的纹理视频、对应的深度图以及相机参数将被解码器重建出来。然后,通过采用基于深度图绘制的技术[3]合成出多个虚拟视点。原有视点和虚拟视点用于在一个自由立体显示设备上显示。如果3D视频解码器连接的是一个立体显示设备,那么一个立体视频对将被产生用于在立体显示设备上显示。如果3D视频解码器连接的是一个传统的2D显示设备。那么一个原有视点或虚拟视点将用于在传统2D设备上显示。
除了3D视频解码器,接收端的解码器也可以是一个传统的2D视频解码器。这时,解码器前面需要额外连接一个码流抽取器,负责只抽取基本视点的码流,抽取出的码流经2D解码器解码后用于在传统的2D显示设备上显示。
编码器端编码的多个视点也可以配置为包含一个立体视频对的结构。此时,立体视频对子码流可以经码流抽取器从复合的3D视频码流中抽取出来。抽取的码流被立体视频解码器解码后用于在立体显示设备上显示。
如前所述,3D-HEVC中解码端重建的深度图和对应的纹理视频可以通过基于深度图绘制的技术来合成中间的虚拟视点。此外,深度图中的深度还可以为纹理视频的编码提供辅助的信息。基于这些信息,新的用于改善纹理图编码的工具被开发,比如面向深度的基于邻居块的视差矢量(Depth-oriented Neighboring-block-based Disparity Vector, DoNBDV)[4]和基于深度的块划分(Depth-based Block Partitioning, DBBP)[5],这些基于深度的编码工具的使用有主于提高纹理图的编码性能。因此,如何高效且高质量地编码深度图显得尤为重要。
2 深度图编码
深度图的编码基本沿用了HEVC中的编码技术,包括基于块的编码结构以及相关的编码工具。然而,深度图具有有别于纹理视频的特征,它内部包含了大块的平坦区域和一些锐利的边界。因此,使用HEVC对深度图编码,解码后的深度图内部边界处会产生伪影效应,而这些伪影会使合成的虚拟视点产生几何失真。为了改善对深度图的编码,HEVC中原有的一些编码工具被禁用,比如循环滤波(In-loop Filtering)模块。一些编码工具被修改,比如运动补偿预测(Motion-compensated Prediction)和视差补偿预测(Disparity-compensated Prediction)过程中将不再进行插值操作,使运动矢量的预测值不再保持1/4像素精度而是整像素精度。另外,还增加了一些新的深度图编码工具。比如深度图建模模式(Depth Modelling Mode)[6]、简化的深度图编码(Simplified Depth Coding)[7]、深度查找表(Depth Lookup Table)[7]等。
2.1深度图建模模式
为了更好地编码深度图内部锐利的边界区域,引入了深度图建模模式,它被看做是新增加的帧内预测模式。最初的深度图建模模式包含了DMM1,DMM2,DMM3和DMM4四种模式,目前保留使用的是DMM1(Explicit Wedgelet Signalling)和DMM4(Inter-component-predicted Contour Partitioning)。深度图建模模式将要编码的深度块分割为两个非矩形的区域,每个区域用一个常量值来表示。这样的模型需要包含两个信息,一个是分割信息,指明每一个样本点属于哪个区域;另一个是常量值信息,指明区域中的所有样本点的深度值。由于分割区域的方式不同,因此存在两种不同的区域分割,即楔形分割和轮廓形分割。图2描述了这两种分割,其中左侧代表了连续的信号空间,右侧代表了离散的信号空间。

图2 块的楔形分割(上)和轮廓形分割(下)
轮廓形的区域分割要参考同一视点的纹理图中同位的亮度分量块。它采用了一种阈值的方法,亮度块4个角的样本点的均值作为阈值,依据亮度块中每个样本点值大于还是小于这个阈值分割出P1和P2两个区域。最后,把亮度块的区域分割结果看作是深度块的区域分割。
楔形的区域分割采用了完全不同的机制,楔形的所有分割方案将根据块的大小事先被计算出来并编号。在定义了起点和终点之后,这些分割方案被分成2类和6个方向。如图3所示,左侧是相邻边的情况,右侧是对边的情况。4个相邻边的情况分别表示4个不同的方向,编号为0~3;2个对边的情况代表另外2个方向,编号为4和5。此外,角点也被定义。对于相邻边的情况,角点被定义为4个角中离起点和终点距离最近的那个点。对于对边的情况,角点分别被定义为左下和右下角的点。起点和终点的位置也遵循一定的规则:相邻边的情况,起点和终点的位置必须是偶数;对边的情况,起点的位置必须是偶数,终点位置没有要求。

图3 楔形分割方案:邻边情况(左)对边情况(右)
经过上述的定义后,不同的方向以及不同的起点和终点位置均代表了一种不同的分割方案。这些所有的分割方案被存储在一个列表中,当对某个深度块进行编码时,将从列表中选取一个最佳匹配的分割方案作为当前深度块的分割。
除了对当前深度块进行区域分割外,还要为每个区域选取一个最佳的常量值来近似此区域的深度值。取区域内所有样本点的均值作为常量值是一个不错的选择,但这个方法不是基于视点合成优化的方法。因此,一个包含粗选和提炼两步的搜索算法被开发,用于为每个区域寻找最佳的常量值。
2.2简化的深度编码
简化的深度编码也称为分段的DC编码(Segment-wise DC Coding, SDC),是用于深度图的一种可供选择的残差编码方法。如果使用SDC,当前编码的编码单元被划分为一个或两个分割区域,每个区域中一个单一的残差值被编码。由于跳过了变换和量化过程而直接在像素域进行编码,伪影效应在一定程度上被降低。另外,要求使用SDC编码的编码单元所对应的预测单元(Predicted Unit,PU)的划分形式必须是2N×2N。SDC分为帧内的分段DC编码(Intra-SDC)和帧间的分段DC编码(Inter-SDC)。
2.2.1Intra-SDC
当采用Intra-SDC方式时,当前编码单元可以采用HEVC中的帧内预测模式或DMM模式进行预测。如果采用的是传统帧内预测模式,整个编码单元被看作一个分割;如果采用的是DMM模式,整个编码单元被看做两个分割区域。
以采用传统预测模式为例来说明SDC的过程,编码时,首先经过预测得到当前预测单元的预测块,取预测块中4个角样本点的平均值作为当前预测单元的预测值。再取当前预测单元中所有样本点的均值与预测值的差作为残差。最后只编码和传输这个单一的残差值。解码时,仍然是先通过预测得到预测块,在预测块的基础上加上这个残差值即得到重建的编码块。
2.2.2Inter-SDC
Inter-SDC与Intra-SDC类似,只是在预测时采用的是帧间预测方式。
2.3分段预测SDC
分段预测SDC[8]是SDC的扩展,与深度图建模模式类似,它会把当前的编码块分割成两个区域,每个区域用一个单一值来表示。分段预测SDC的预测过程可以采用帧内预测,也可以采用帧间预测,其整个过程通常包含以下3个步骤。
1) 预测:通过帧内或帧间预测方式得到当前编码块的预测块。
2) 区域划分:根据阈值T把预测块分为两个区域,其中T为预测块中4个角样本点的平均值。
3) 为每个区域计算一个单一值:单一值被定义为V=E+O,其中E是预测块中某个区域的估计值,可以通过计算此区域内所有样本点的平均值得到。O是对应的偏移量,可以通过计算编码块中属于此区域的样本点的均值再减去E得到,O是需要编码和发送到解码端的数据。
2.4深度查找表
深度图中样本点的深度值是所有可用深度值(用8位表示深度,则深度值的范围为0~255)的一个子集,因为深度图在采集时被强量化了。依据这个事实,通过使用深度查找表[7]可以进一步减小编码深度图时所使用的比特数目。深度查找表建立了深度值与其对应的索引之间的一一对应关系。为了构建深度查找表,编码器需要先从即将编码的深度图序列中读取一定数量的帧,通过扫描帧中的样本点来获得深度图中的深度值。
深度查找表用D(·)表示,索引查找表用I(·)表示,深度映射表用M(·)表示,Dt为t时刻的深度图,深度查找表构建过程的伪代码如下:
1.Initialization
index counteri=0
2.Process each sample positionpinDtfor multiple time instancest:






i=i+1

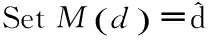

以简化的深度编码方式为例来说明深度查找表的使用过程。在使用深度查找表的情况下,当前编码块所有样本点的均值(dorig)和预测值(dpred)的差将不再作为残差被编码,而是根据各自的深度值dorig和dpred在索引表中查找出各自的索引,两个索引的差iresi被编码,如式(1)所示
(1)
(2)

(3)
最终,每个样本点的重建值Px,y^由式(4)计算得到
(4)
式中:Px,y表示位置(x,y)处样本点的预测值。
2.5单一深度帧内模式
观察发现深度图中包含大量的平坦区域,且区域中的样本点具有几乎相同的深度值。单一深度模式(Single Depth Intra Mode)[9]被设计用来编码这些平坦区域,也就是说单一深度模式仅使用一个深度值来表示当前编码单元(Coding Unit, CU)。这个深度值会从当前编码单元相邻的样本点中选取。如图4所示,位置An/2和Bn/2处的样本点被选为深度值的候选,同时被放入到样本点候选列表。候选的索引被编码用来指明采用哪一个样本点的值来填充当前编码单元。如果当前编码单元采用了单一深度模式编码,将不再处理残差信号。

图4 被选为候选的样本点
3 深度图编码的率失真优化
由于深度图主要用来合成虚拟视点,而不会被直接观看。因此,完全以深度图自身的失真作为深度图编码质量的度量标准将不再合适。深度图编码的率失真优化过程应同时考虑深度图自身的失真以及合成视点的失真。为了测量合成视点的失真情况,两个新的度量标准被设计,它们分别是合成视点失真变化(Synthesized View Distortion Change,SVDC)[10]和视点合成失真(View Synthesis Distortion,VSD)[11]。
3.1合成视点失真变化
合成视点失真变化定义为两次的合成视点与参考视点的失真之差,如式(5)所示
(5)


图5 合成视点失真变化的原理图
3.2视点合成失真
为了降低率失真优化的计算复杂度,另一个描述合成视点失真的度量标准被定义,即视点合成失真。它基于深度图的失真不是线性影响合成视点的失真,而是随相应的纹理图的变化而变化。如式(6)所示

(7)
式中:f表示焦距;L表示当前视点和合成视点的基线距离;Znear和Zfar分别表示场景的最近和最远深度值。
4 小结
本文对3D-HEVC新增的深度图编码工具以及率失真优化方法进行了总结,这些工具的使用能在一定程度上改善深度图的编码性能。然而,针对如何高效编码深度图的研究工作远没有结束。另外,过高的编码复杂度是需要考虑的另一个问题,它制约着编码的实时性处理。
[1]SULLIVAN G J,BOYCE J M,YING C,et al. Standardized extensions of High Efficiency Video Coding (HEVC)[J]. IEEE journal of selected topics in signal processing,2013,7(6):1001-1016.
[2]田恬,姜秀华,王彩虹.新一代基于HEVC的3D视频编码技术[J].电视技术,2014,38(11):5-8.
[3]FEHN C. Depth-image-based rendering(DIBR),compression and transmission for a new approach on 3D-TV[C]//Proc. Stereoscopic Displays and Virtual Reality Systems XI. San Jose,CA,United States:SPIE,2004:93-104.
[5]CHANG Y L,WU C L,TSAI Y P, et al. CE1.h:depth-oriented neighboring block disparity vector (DoNBDV) with virtual depth retrieval,JCT3V-C0131[S].2013.
[6]MERKLE P,BARTNIK C,MULLER K,et al. 3D video:depth coding based on inter-component prediction of block partitions[C]//Proc. Picture Coding Symposium (PCS). Krakow,Poland:IEEE,2012:149-152.
[7]FABIAN J. 3D-CE6.h:simplified depth coding with an optional depth lookup table,JCT3V-B0036[S].2012.
[8]ZHANG K,AN J C,ZHANG X G,et al. Segmental prediction for Inter-SDC in 3D-HEVC,JCT3V-I0075[S].2014.
[9]CHEN Y W,LIN J L,HUANG Y W,et al. Single depth intra mode for 3D-HEVC, JCT3V-H0087[S].2014.
[10]TECH G,SCHWARZ H,MULLER K,et al. 3D video coding using the synthesized view distortion change[C]//Proc. Picture Coding Symposium (PCS). Krakow,Poland:IEEE,2012:25-28.
[11]BYUNG T O,KWAN-JUNG O. View synthesis distortion estimation for AVC- and HEVC-compatible 3-D video coding[J]. IEEE transactions on circuits and systems for video technology,2014,24(6):1006-1015.
责任编辑:时雯
Advances in encoding depth map in 3D-HEVC
LEI Haiwei1,LIU Wenyi1,WANG Anhong2
(1.KeyLaboratoryofInstrumentationScience&DynamicMeasurement,MinistryofEducation,NorthUniversityofChina,Taiyuan030051,China;2.SchoolofElectronicInformationEngineering,TaiyuanUniversityofScienceandTechnology,Taiyuan030024,China)
3D-HEVC is a newly developed video coding standard to efficiently encode the 3D video and free view video, which requires simultaneous coding of texture video and the corresponding depth map. Encoding the depth map by using the traditional techniques would produce artifacts at the sharp boundaries,therefore,some new depth map coding tools have been developed. This paper details these coding tools, also introduces the rate distortion optimization methods used in encoding the depth map.
3D-HEVC;depth map coding;rate distortion optimization (RDO)
TN919.8
ADOI:10.16280/j.videoe.2016.07.004
国家基金委重大国际(地区)合作研究项目(61210006);国家自然科学基金项目(61272262)
2015-12-07
文献引用格式:雷海卫,刘文怡,王安红.3D-HEVC中深度图编码技术研究进展[J].电视技术,2016,40(7):15-19.
LEI H W,LIU W Y,WANG A H.Advances in encoding depth map in 3D-HEVC[J].Video engineering,2016,40(7):15-19.
