统计关联规则决策树在医疗数据中的应用
2016-08-18王旭晨陈小惠
王旭晨,陈小惠
(南京邮电大学 自动化学院,江苏 南京210023)
统计关联规则决策树在医疗数据中的应用
王旭晨,陈小惠
(南京邮电大学 自动化学院,江苏 南京210023)
提出一种基于统计关联规则的增量决策树分类算法,称为SARMT(Statistic Association Rules Miner Tree),它基于快速决策树(Very Fast Decision Tree,VFDT)技术来挖掘医疗数据。与VFDT不同,改进的SARMT算法不依赖于样本分裂节点的数量。在医疗大数据中,通常缺少大量可用的数据样本,因此SARMT算法更加适用于医疗环境中。将SARMT算法和VFDT算法应用于不同的三个医疗数据集上,实验结果表明在执行时间相当的情况下, SARMT算法在处理医疗数据中有更高的准确率。
医疗数据;决策树;关联规则;SARMT;VFDT
0 引言
随着知识发现的发展,决策树在很多领域中得到应用。对于医疗领域而言,其应用大多数集中在疾病诊断上。决策树的思路[1-2]是找出最有分辨能力的属性,把数据库划分成许多个子集(一个子集对应树的一个分支),然后对每个子集递归调用分支过程,直到所有子集包含同一类型的数据。它的优点主要是描述简单、分类速度快,比较适合处理大规模的数据。
分类任务的目标[3-4]是建立一个模型来描述和区分数据类别,在大数据中,通常使用增量技术进行分类,该算法可以将新加入的样本纳入原有的样本集中,使最后生成的规则是建立在原有的样本和新加入的样本之上而不需要重新建立决策树。文献[5]提出一种基于Hoeffding树的决策树——VFDT(Very Fast Decision Tree)算法,它使用信息增益和基尼系数指标为属性进行评估测量,并且对原始的决策树算法进行了优化。文献[6]指出该算法的一些不足,例如它需要足够多的叶子节点保证该树的增长,因此需要大量的数据样本提供这些信息。然而,医疗行业总体数据存储量不是很大,且各医疗机构之间的差异比较大,具体到某一种病情的可用数据样本就更少了。所以在数据存储量不是很多的情况下,VFDT算法的准确性和效率都不是很高。
1 相关研究方法
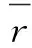
(1)
Hoeffding约束规则有一个特点是观察值生成的概率是独立分布的,但缺点是约束规则比从属分布保守,需要更多的样本。VFDT的主要特性之一是它可以保持良好的准确性并且使用相关Hoeffding约束规则来处理大量数据。
2 统计关联规则决策树
2.1统计关联规则
统计关联规则是一种基于分布定量值的可以显示数据子集之间关系的规则,它为其他关联规则的生成过程提供统计测试来确认其有效性。统计关联规则的优点是不需要数据离散化,因为离散化过程可能会导致信息丢失,往往扭曲挖掘算法的计算结果。
在本文中,统计关联规则挖掘的概念适用于属性评估,来验证何时分裂节点以及使用何种属性。特征向量可以定量地描述数据,因此,需要一个合适的方法来定量挖掘关联规则的数据。本文提出SARMT(Statistic Association Rules Miner Tree)算法,其目标是找到一种统计关联规则来选择一组可以保留其他特性的最小数据集。
2.2SARMT算法
本文基于VFDT算法,利用统计关联规则作为启发式方法[8]提出了SARMT算法,选择合适的属性作为测试节点,并通过统计数值数据来决定何时完成树节点的分割。它是一种增量决策树构造算法,负责处理数值数据。正如前面提到的,由于Hoeffding树的限制,VFDT需要构建更多的样本,而SARMT提出构建比VFDT少的样本,且保持良好的准确性,同时根据数据描述获得更少的执行时间。
SARMT算法的总体结构与VFDT相似,但与VFDT不同的是SARMT算法可以决定何时执行节点的划分,能够分类描述数据,而且数据样本比VFDT少。这里只描述与VFDT不同的算法步骤。
假设T是数据集,ai是属性,aik是第k个数据的属性,xj是类,Txj∈T。μai和σai分别表示数据集属性的平均值和标准差。又定义了三个阈值:Δμmin表示允许类xj中ai的平均值与剩余项集中ai的平均值的最小误差;σmax表示类中ai的最大标准差;γmin表示最小置信度。计算公式分别如式(2)、(3)、(4)。
(2)
(3)
γmin=μai(Txj)-μai(T-Txj)
(4)
每个属性ai的平均值和标准差分别由类xj产生,当观察值是最小样本时,SARMT选择满足以下条件的属性:
(1)ai在类xj中应该有不同于其他类的行为;
(2)ai在类xj中应该提供一个统一行为。
为了满足这些条件,限制兴趣度的使用。标准误差置信水平Z计算如式(5):
(5)
SARMT算法描述如下:
(1)SARMT是一个根节点
(2)for each样本e do
(3)将e使用SARMT分成叶子节点l
(4)在l中更新统计数据
(5)增加n1(l中样本的数量)
(6)ifn1modnmin=0 and 所有的样本都是叶子节点且不在同一类中 then
(7)选择满足条件:(μai(Txj)-μai(T-Txj))≥Δμmin的属性
(8)选择满足条件:σai(Txj)≤σmax的属性
(9)计算Zij
(10)if 至少选择一个属性and (Zij
(11) Xa作为识别更多类的属性,并满足高于μai(T-Txj)且低于σai(Txj)
(12)用一个分裂的内部节点Xa代替l
(13)for 所有分裂的分支 do
(14)添加一个有初始数据的新叶子节点
(15)end if
(16) end if
第4行更新的数据是SARMT的Δμai(Txj)和σai(Txj),如果只选择一个属性,选择xa为分裂节点(第11行);如果有两个或更多属性满足条件,SARMT选择属性xa作为测试节点(第12~14行)。
与VFDT不同的是,SARMT不依赖于样本数量,所以它可以生成和适应没有数量限制的样本模型,从而比VFDT更加灵活。
3 实验及结果分析
本文使用真实的数据集进行了3个实验,数据随机抽取100个样本,对ECG信号、PPG信号以及血压的指标进行统计,并且分别使用SARMT和VFDT算法,对结果的准确性、树的大小和执行时间进行比较。
心电图(Electrocardiogram,ECG)是反映心脏兴奋的电活动过程,它可以鉴别与分析各种心律失常的情况,也可以反映心肌受损的程度和发展过程以及心房、心室的功能结构情况。在日常生活中对患者进行心电监护可以为医生临床诊断提供参考,对普通人而言,心电图有助于用户监测身体健康状态。光电容积脉搏波(Photoplethysmograph,PPG)是心脏的搏动沿动脉血管和血流向外周传播而形成的,脉搏波传递的快慢与人体心血管的多项参数都有密切关系。血液在血管内流动时,无论心脏收缩或舒张,都对血管壁产生一定的压力。当心脏收缩时大动脉里的压力最高,这时的血液称为“高压”;左心室舒张时,大动脉里的压力最低,故称为“低压”。平时所说的“血压”实际上是指上臂肱动脉,即胳膊窝血管的血压测定,是大动脉血压的间接测定。正常的血压是血液循环流动的前提,血压在多种因素调节下保持正常,从而为各组织器官提供足够的血量,以维持正常的新陈代谢。血压过低或过高(低血压、高血压)都会造成严重后果,血压消失则是死亡的前兆,这些都说明了血压有极其重要的生物学意义。
针对这三种采集的样本数据,表1显示了每个样本类的参数值Δμamin和σmax(在实验前,已计算参数值),在所有的实验中,假设γmin=0.99。

表1 SARMT 参数
表2总结了实验结果,可以看出,与VFDT相比,SARMT在所有的实验中在执行时间相当的情况下精度更高。可以肯定的是,在实验数据集下,SARMT比VFDT描述了更少的数据集。虽然SARMT处理数据时使用了比较多的步骤,但是其使用数据集血压、PPG和ECG创建出的决策树,分类的精确度更高。
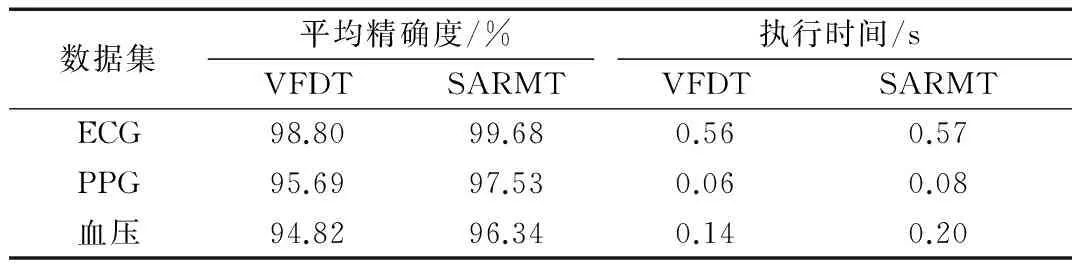
表2 实验结果
图1~图3显示了VFDT和SARMT算法应用在3种样本数据中准确度和所创建树的大小(节点个数)的对比。
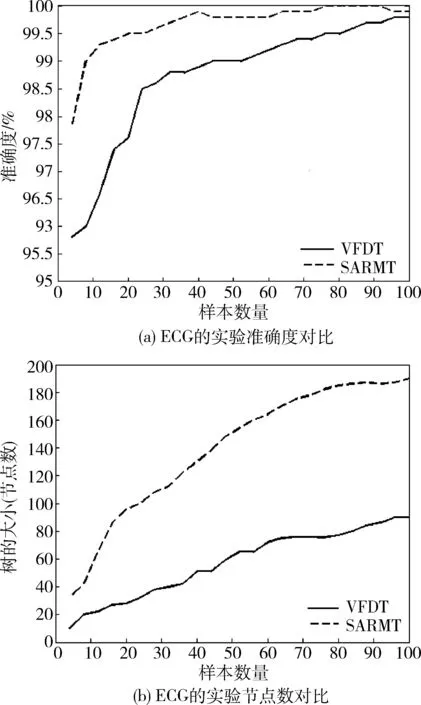
图1 ECG的实验结果

图2 PPG的实验结果
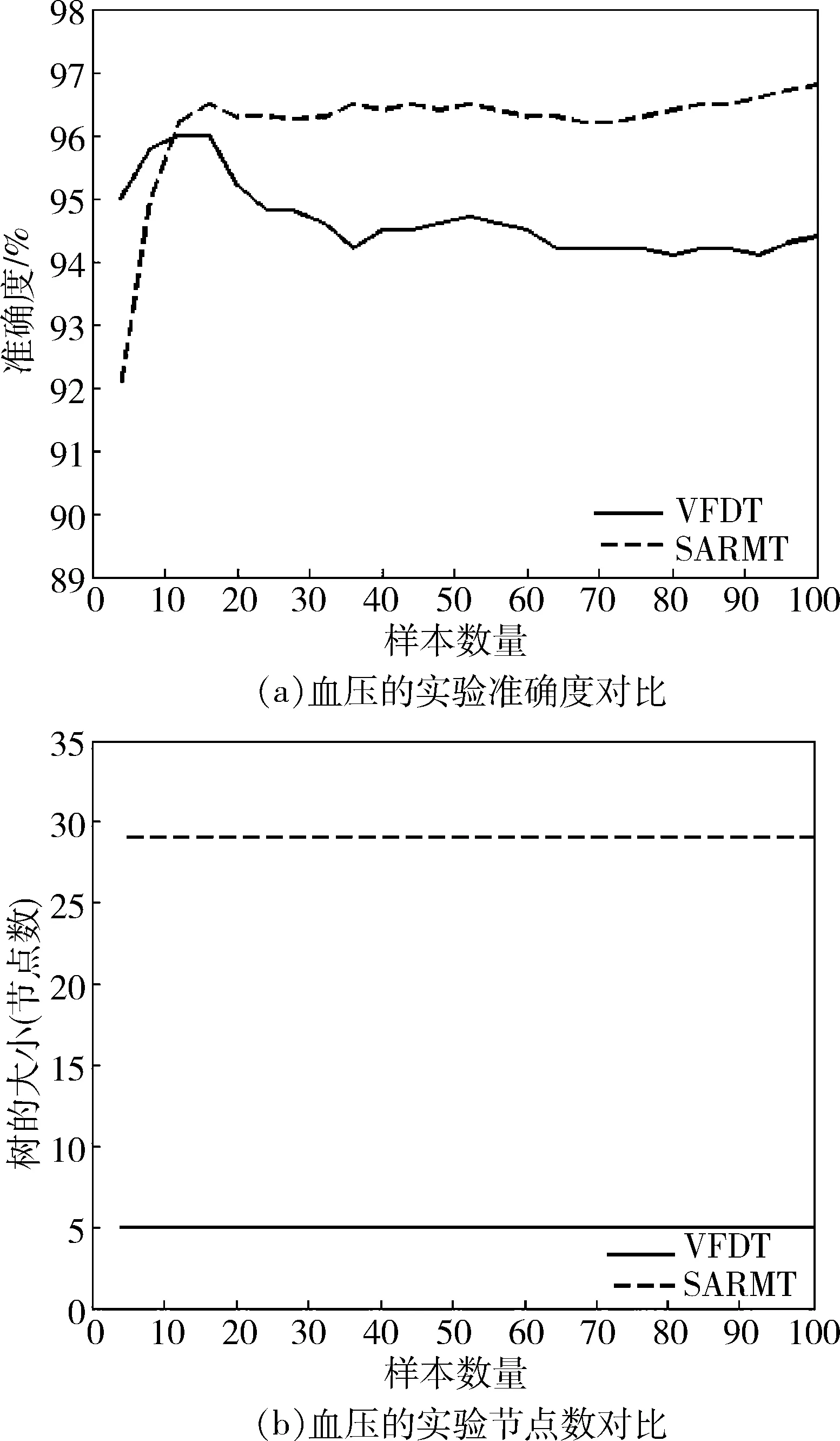
图3 血压的实验结果
实验表明,从第一个样本开始,使用SARMT描述的数据集可以更快速地捕获数据的变化。VFDT不能详细地描述数据,而SARMT创建的是独立的样本,可以详细地描述数据。虽然ECG和PPG数据集需要建立一个更大的树,但在执行时间相当的情况下,SARMT用于测试的节点分裂的速度比使用信息增益的Hoeffding树(即VFDT)更快。
4 结论
本文基于VFDT算法提出了一种针对医疗数据的统计决策树的分类算法——SARMT算法。实验表明,SARMT是一种适合数据流分类的方法,通过比较实验结果,SARMT可以实现在执行时间相当的情况下,保持实验良好的准确性。与VFDT相比,SARMT描述了比较小的数据集,因为它不像VFDT的分裂节点的方法依赖于样品的数量。在未来的工作中,希望可以使用SARMT算法处理一些概念漂移的问题,添加一个自动估计参数并且通过有噪音的数据集来扩展实验。
[1] 谭俊璐,武建华.基于决策树规则的分类算法研究[J].计算机工程与设计, 2010,31(5):1017-1019.
[2] 颜延,秦兴彬,樊建平,等.医疗健康大数据研究综述[J].科研信息化技术与应用,2014,5(6):3-16.
[3] PATIL A, ATTAR V. Framework for performance comparison of classifiers[C]. Proceedings of the International Conference on Soft Computing for Problem Solving (SocProS 2011), Springer India, 2012: 681-689.
[4] DONMINGOS P, HULTEN G. Mining high-speed data streams[C]. In Proceedings of the sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, USA, 2000:71-80.
[5] BIFET A. Adaptive stream mining: pattern learning and mining from evolving data streams[C].Proceedings of the 2010 Conference on Adaptive Stream Mining, Ios Press, 2010: 112-129.
[6] 晋爱莲,耿丽娜,薄芳芳.多标签决策树分类在数字医学图像分类中的应用[J].中国数字医学,2013,8(3):90-92.
[7] 郑伟发,李培亮,郑梁珠,等.高速数据链的挖掘算法——VFDT 算法[J].广东商学院学报,2002(S2):118-120.
[8] 马希骜,王国胤,于洪.决策域分布保持的启发式属性约简方法[J].软件学报,2014(8):1761-1780.
An application of statistical association rules decision tree in medical treatment data
Wang Xuchen,Chen Xiaohui
(College of Automation , Nanjing University of Posts and Telecommunications, Nanjing 210023, China)
This paper proposed a decision tree classification algorithm based on incremental statistical association rules, which is called SARMT(Statistic Association Rules Miner Tree).And it is based on VFDT (Very Fast Decision Tree)technology to mine medical data. Different from VFDT, the improved SARMT algorithm does not depend on the number of samples split node. In big medical data, usually lack of a large number of available data samples, so SARMT algorithm is more suitable for medical environments. In this paper, the SARMT algorithm and VFDT algorithm are applied in three different medical datasets, the experimental results show that SARMT algorithm has higher accuracy in the processing of medical data when the execution time is considerable.
medical data; decision tree; association rules; SARMT; VFDT
TP391
A
10.19358/j.issn.1674- 7720.2016.15.023
2016-04-06)
王旭晨(1993-),女,硕士研究生,主要研究方向:数据挖掘。
陈小惠(1961-),男,博士,教授,主要研究方向:网络化测控系统、嵌入式系统与智能仪器、传感器网络与信息融合。
引用格式:王旭晨,陈小惠. 统计关联规则决策树在医疗数据中的应用[J].微型机与应用,2016,35(15):78-81.
