基于SVM主动学习的微信监测研究*
2016-08-11高学伟郑世珏李松丽
高学伟 郑世珏 高 丽 李松丽
(华中师范大学计算机学院 武汉 430079)
基于SVM主动学习的微信监测研究*
高学伟郑世珏高丽李松丽
(华中师范大学计算机学院武汉430079)
摘要论文通过支持向量机(SVM)主动学习算法对微信文章进行包含四种警度级别(红、橙、黄、绿)的分类,利用微信信息的警度评估分析技术,构建微信信息预警系统,预测可能影响社会安全态势的事件和现象。为了评估分类器的性能,我们对随机抓取的3036个不同警度级别的微信文章样本进行了分类实验,并在学习样本数量不等的情况下,分别用改进的SVM主动学习算法与传统SVM和主动学习SVM两种分类器对测试样本进行分类,通过多次实验分析验证了改进的SVM主动学习方法在微信舆情监测[1~3]的可行性。
关键词支持向量机; 主动学习; 微信; 监测
Class NumberTP393
1 引言
随着互联网的快速发展,手机使用者数量也随着增长,现在不管走到哪都能看到智能手机的身影,而智能手机的出现,加速了移动终端的进程。微信作为一款手机软件与个人信息紧密相关,而微信公众平台相比于其他网络平台在传播方面也具有明显的优势。首先它是熟人网络,小众传播,传播有效性更高。另外微信公众平台,是一对多传播,信息高达到率。直接将消息推送到手机,因此达到率和被观看率几乎是100%。随着微信用户的增加,微信信息量也呈现一种爆炸式增长,各种微信信息传播内容良莠莫辨,混淆视听,微信舆情挖掘研究也变得日趋重要。相比较微博来说,微信中信息的传播、推广很难被发现,建立一种微信内容监测的专业化、智能化和个性化监测预警系统很有必要。针对这一目标,本文将研究基于对象级别的微信中文信息监测预警关键技术。通过爬虫[4~6]爬取微信公共平台中的文章,并由支持向量机(Support Vector Machine,SVM)主动学习方法对文章[10~15]进行包含四种警度级别(红、橙、黄、绿)的分类,利用微信信息的警度评估分析技术,构建微信信息预警系统,预测可能影响社会安全态势的事件和现象。为了评估分类器的性能,我们采用了3036个不同警度级别的微信文章样本并对其进行分类,并在学习样本数量不等的情况下,分别用传统SVM和主动学习SVM两种分类器对测试样本进行分类,通过多次实验分析验证了SVM主动学习方法在微信舆情监测的可行性。
2 微信监测预警平台
2.1微信接入与监测
微信公众平台发表的文章通常是很难直接抓取出来的,至少到目前为止微信还没有公开API接口供我们使用。但是本文开发人员还是发现了一种可以间接爬取出微信公众平台的文章方法,因为腾讯公司向搜狗公开了后台接口,也就是说搜狗可以爬取出公众平台文章。然而我们爬取公众平台的文章的方法就是通过搜狗这个开放平台来完成爬取任务。
通过网络爬虫从各种微信站点收集发布的异构信息,从这些信息中,抽取其中的语义,输入警情预测系统,对将要出现的警情通过预警发布系统进行发布,并对造成警情的警度和警源进行分析。图1是整个平台的数据流程图。

图1 微信监测预警平台流程图
2.2微信预警模型
微信热点态势分析和预报是预警系统中非常重要的一个环节,将直接影响到问题的处理结果。如果准确预警却不能正确发布,同样将不能起到预期的作用。譬如,如果发布的警度低于实际问题的危险性,有可能导致问题不被重视从而延长应对时间;如果发布的警度高于实际问题的危险性,同样可能导致相关人员的不信任感增强,甚至丧失对整个系统的信任感。因此,必须设计合理的微信文化安全分析和预报机制和系统,以保证预警能够得到尽可能合理、快捷的处理。
我们的预警机制采用多级联动的四色预警方法,其主要流程如图2所示。当发现预测警情时及时发布,上报公安监管部门,还通报其它相关部门的网站和安全监控系统,实现警情统一数据交换。四色预警即将警情分成红、橙、黄、绿四色,红色是代表微信文化秩序混乱、影响微信文化安全的警情多发、系列性事件高发,需采取整治或关停措施的;橙色是代表微信安全受到威胁,警情明显上升,需密切关注加强防控;黄色是代表出现少量的警情,需要注意跟踪和观察;绿色是指微信文化安全能够得到保障,安全和谐的微信环境。
目前还缺少通用的、公认的警度划分方法,这就要求预警系统能够针对不同的预警指标采取不同的确定方法,最好能采取多种方法,综合多方面意见加以确定。另外,警限的确定和警度的划分是稳定性和动态性的统一,警限一旦确定应在一定时间尺度内保持相对的稳定,但决不能是一成不变的,应能随着时间的推移、环境的变化、势态的发展、主次矛盾的转化而不断调整和修正。

图2 微信安全态势分析和预报系统
网络爬虫抓到公共号的文章后,通过设定的阈值来判断是否为敏感文章,并通过阈值的大小来划分红、橙、黄、绿四色的预警级别。设定的阈值F的计算公式为
(1)
其中n为数据库中的敏感词个数,wi是第i个敏感词所对应的权重,ni是第i个敏感词在文章中出现的总次数,N是文章的总字数。
3 SVM及主动学习
3.1主动学习
主动学习的概念是Simon于1974年首次提出[7],是构造有效训练集的方法,其原理是它制定了某种选择策略,要求分类器可以自动地从给定的未标注的样本中选择出最有价值的样本,提供给用户进行标注,然后将新标注的样本加入到训练集再次训练学习器,如此循环往复,从而在多次迭代中不断改善学习器性能。它的目标在于通过迭代抽样,寻找有利于提升分类效果的样本,进而减少分类训练集的大小,在有限的时间和资源的前提下,提高分类算法的效率[8]。
主动学习算法[9~11]可以由以下五个组件进行建模:
A=(C,L,S,Q,U)
其中C为一个或一组分类器;L为一组已标注的训练样本集;Q为查询函数,用于在未标注的样本中查询信息量大的样本;U为整个未标注样本集;S为督导者,可以对未标注样本进行标注。
主动学习算法主要分为两个阶段:第一阶段为初始化阶段,随机从未标注样本中选取小部分,由督导者标注,作为训练集建立初始分类器模型;第二阶段为循环查询阶段,S从未标注样本集U中,按照某种查询标准Q,选取一定的未标注样本进行标注,并加到训练样本集L中,重新训练分类器,直至达到训练停止标准为止。
3.2支持向量机
支持向量机[12]是Cortes和Vapik于1995年提出的一种基于结构风险最小化准则的学习器,它在解决小样本、非线性以及高维模式识别中表现出许多特有的优势。其目的是找到一个最优分类超平面以最大间隔将两类数据分开。不管在二分类还是多分类问题上SVM都能有良好的学习效果。
假设训练集D={(x1,y1),(x2,y2),…,(xm,ym)},其中输入xi∈Rm,yi∈{-1,+1}。SVM首先输入空间x映射到特征空间z=φ(x)。通常情况下,特征空间的维数是很高的,考虑到数据在线性空间上是可分的,存在向量w和b满足:
yi(〈w,φ(xi)〉+b)≥1
(2)
对于训练集〈w,φ(x)〉表示w和φ(x)的点积。SVM构造了一个超平面,(〈w,φ(x)〉+b),使得正例和负例的间隔最大。因此:
f(x)=〈w,φ(x)〉+b
(3)
预测输入x的标记。在许多实际的应用中,线性可分超平面是不存在的,因此引入松弛因子ξi≥0
yi(〈w,φ(xi)〉+b)≥1-ξi,i=1,…,m
(4)
为了进一步简化,最优分类面问题可以进一步演化为在式(4)的约束下求解下列问题的最小值:

(5)
其中ξi≥0,Cp是惩罚参数。因为特征空间的维度很高,准确获得w和φ(w)比较困难。因此引入核函数技术。只要非线性映射函数K(x,x)′满足Mercer条件,都可以作为核函数,并且K(x,x)′=〈φ(x),φ(x′)〉。
常见的核函数[13~15]有以下几种:
1) 线性核函数:
K(x,xi)=(xi·x)
(6)
2) 多项式核函数:
K(x,xi)=[p(xi·x)+s]q
(7)
3) Sig Mod核函数:
K(x,xi)=tanh(μ(xi·x)+c)
(8)
4) 径向基核函数:
K(x,xi)=exp(-γ|x-xi|2)
(9)
如果核函数选择适当,可将输入空间中的线性不可分问题转换为特征空间中的线性可分问题,在我们的实验中选用的是径向基函数K(x,xi)=exp(-γ|x-xi|2)为核函数。
为了减少评价样本所需要代价,仔细、合理地选择训练样本是必不可少的操作,我们在文本分词的时候就根据四种类别的关键词库对文章做出模糊的类别标注,这样在主动学习过程中就会大大减少人为的标注,提高了分类准确性。改进后的SVM实现主动学习的算法[16]流程图如图3所示。
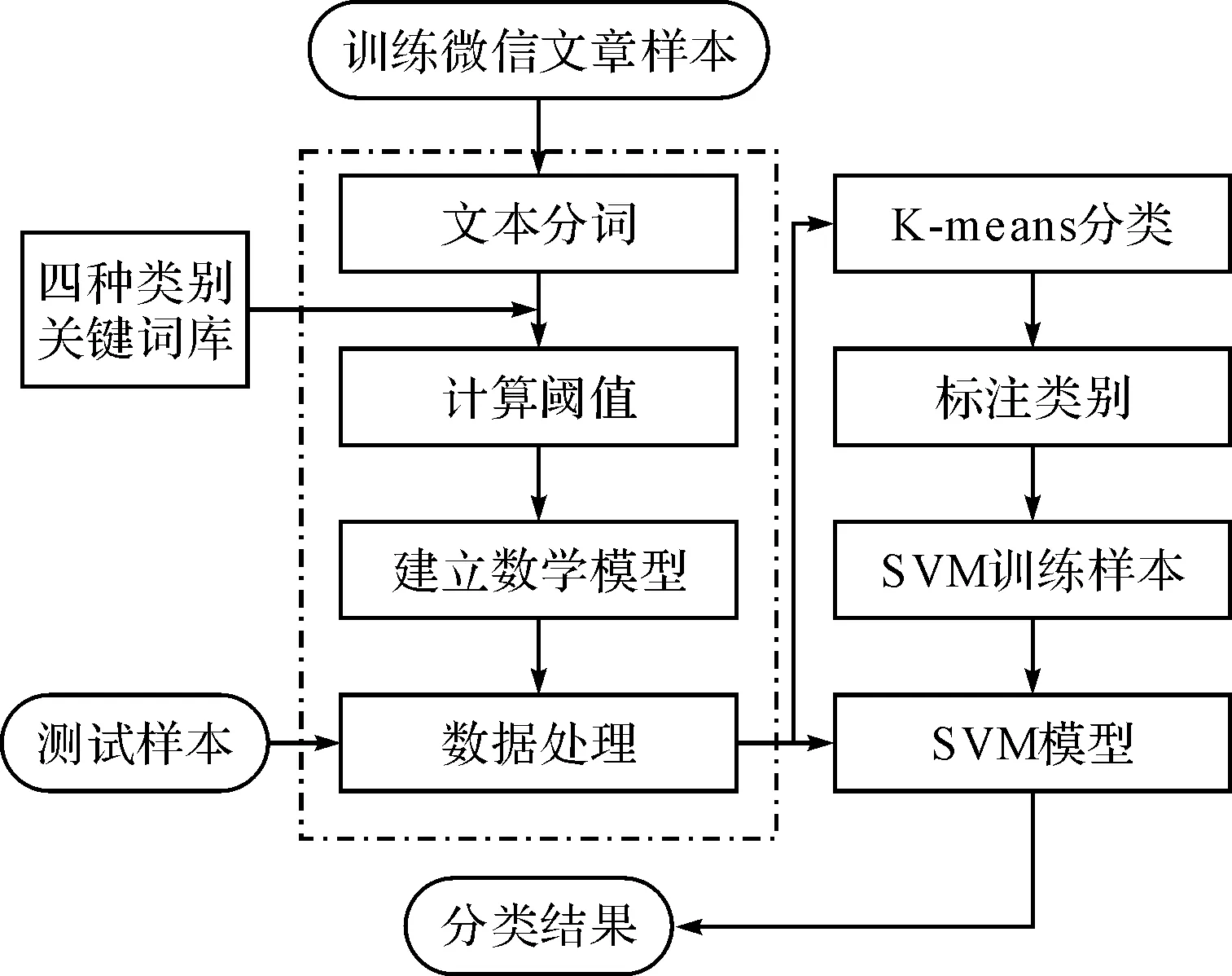
图3 SVM主动学习算法流程图
输入:不带类别标注的候选样本集Tr,每次从候选样本中采样的个数n。
输出:分类器f。
方法:
准备:对将要训练的文章样本进行分词处理,计算出对应类别的相关因子υ,并依据相关因子的最大值max(υ)对文章做出模糊的类别标注。
步骤1:通过K-means算法从候选样本集Tr中选择1个样本,构造初始训练样本集I0,使I0中至少包含有一个正例样本和一个负例样本,执行T0=Tr-I0操作。
步骤2:进行第i次采样学习,在样本集Ii-1基础上寻找最优分类超平面fi,从样本集Ti-1中选择距离fi最近的n个样本,这n个样本组成的集合记为Bi。
步骤3:正确标注这n个样本的样本类别。
步骤4:执行Ii=Ii-1∪Bi,Ti=Tr-Ii,如果Ti为空或者满足某种指标时终止学习,否则返回到步骤2。
步骤5:返回f=fi,算法结束。
4 实验结果分析
为了评估分类器的性能,我们随机地爬取了3036个不同警度级别的微信文章样本并对其进行分类,并记录下了传统的SVM算法下分类准确率和在主动学习下SVM算法下分类准确率。实验所用的分类环境是台湾大学林智仁(Lin Chih-Jen)教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包libsvm,根据训练样本的特征选取的核函数是径向基RBF核函数。核函数中的gamma函数设置-g参数为2.8,-c参数设置为1.2。样本集中的样本分为教育、军事、经济和生活四个分类类别,其中不同类别的训练样本数与测试样本数如表1所示。
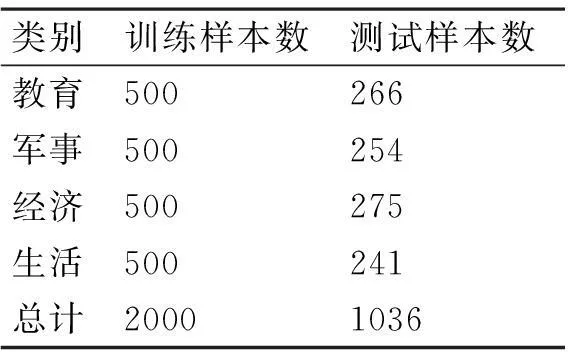
表1 不同数据下两种SVM分类器准确率比较
为了验证SVM主动学习分类器在微信监测中的分类效果比传统的支持向量分类器分类效果优越,我们在实验中验证了在不同训练样本个数的情况下,传统的支持向量机分类器与主动学习的支持向量机分类器在分类准确率上的差异,正如表2所显示的那样,随着学习样本数目的逐渐递增,两种支持向量分类器的分类准确率都在增加,但是采用了主动学习的支持向量分类器分类的准确率要明显的优于传统的支持向量分类器。表3显示的是SVM主动学习算法与改进后的性能比较。介于某些文章的类别不确定性,所以在训练分类器的时候,训练数据点的向量距离相差或大或小,并不理想,所以图表上显示的数据并不完美。但是从大体上来说,改进后的算法在性能上要优于原始算法。
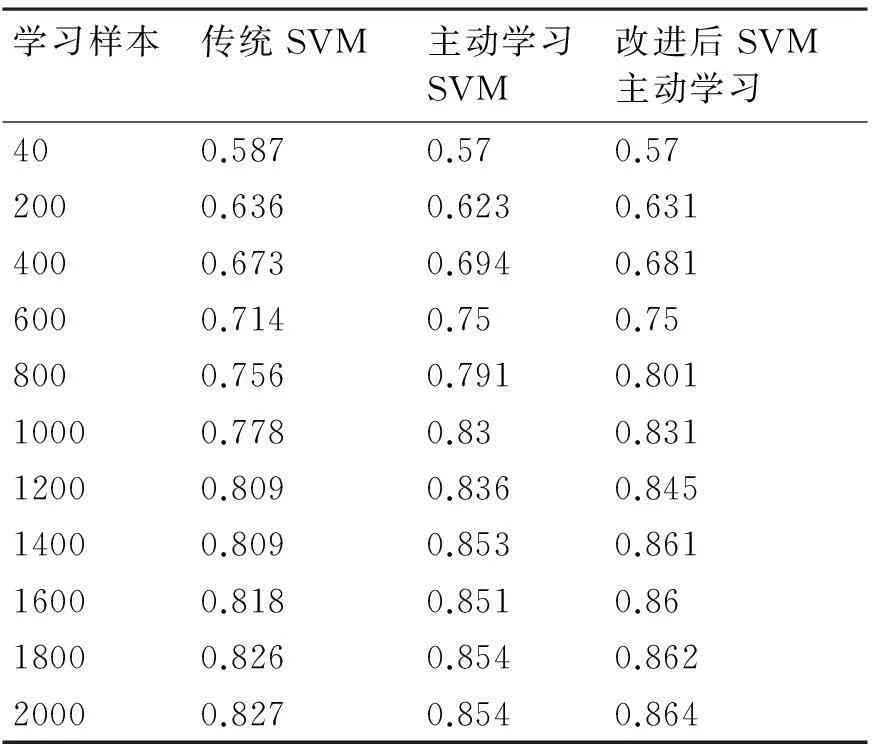
表2 不同数据下原始SVM分类器与主动学习分类器准确率比较
为了使实验数据更具说服力,我们在训练样本确定的情况下,分别做了多次实验,取其平均的分类准确率,并用仿真图4显示出来,这样,改进后的分类器要比SVM主动学习分类器和传统的SVM分类器的分类效果清晰地显示出来了。
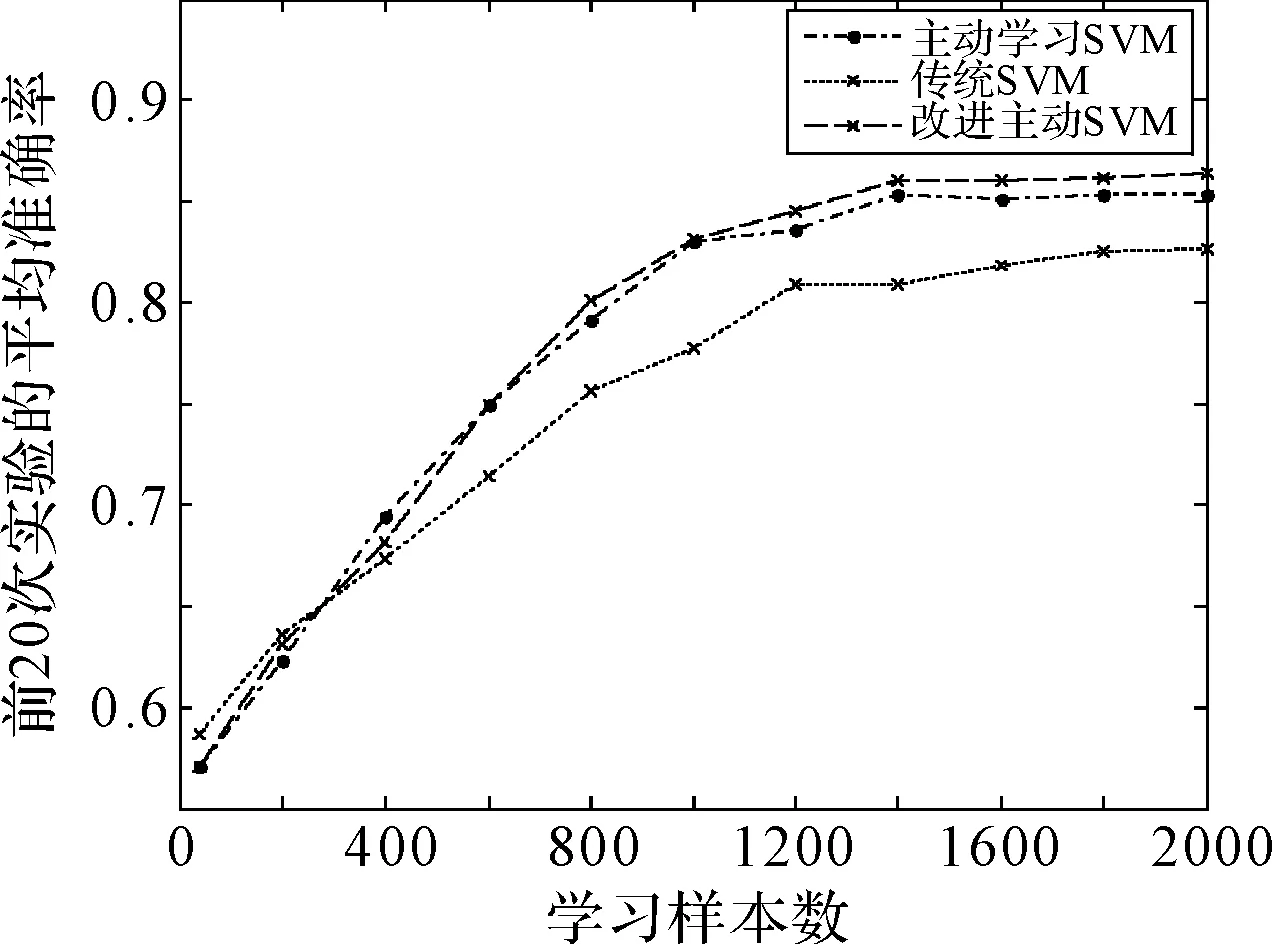
(a)

(b)图4 不同数据下两种SVM分类器准确率比较
通过图4不难发现,改进后的主动学习下SVM分类准确率要比传统的SVM分类准确率高。因此可以确定支持向量机主动学习分类器在微信监测中的效果要比传统支持向量机分类器监测效果明显。
5 结语
为了能更好地净化网络环境,微信监测是不可能忽视的一部分。因为微信公众平台是小众传播,传播有效性高,微信信息量也随着用户的增加呈现出一种爆炸式的增长,各种微信信息传播内容良莠莫辨,混淆视听,微信舆情挖掘研究变得日趋重要,而目前我们的研究也只是一些皮毛。在我们的实验中验证了主动学习SVM在微信监测中的可行性,相比传统SVM,采用主动学习SVM的监测效果有一定的优势,但这还不能说明主动学习SVM在监测分类中一定是最好的,所以在接下来的研究中,我们会不断改进并探索更为优秀的算法。
参 考 文 献
[1] 陈忆金,曹树金,陈少驰,等.网络舆情信息监测研究进展[J].图书情报知识,2011(6):41-49.
CHEN Yijin, CAO Shujin, CHEN Shaochi, et al. Research progress of network public opinion information monitoring[J]. Library and Information Knowledge,2011(6):41-49.
[2] 陆浩.网络舆情监测研究与原型实现[D].北京:北京邮电大学,2009.
LU Hao. Research and prototype implementation of network public opinion monitoring[D]. Beijing: Beijing University of Posts and Telecommunications,2009.
[3] 杨印.网络舆情监测系统的设计与实现[D].厦门:厦门大学,2014.
YANG Yin. Design and implementation of network public opinion monitoring system[D]. Xiamen: Xiamen University,2014.
[4] Rennie J, McCallum A. Using reinforcement learning to spider the web efficiently[C]//Proceedings of the Internet Conference on Machine Learning, Slovenia,1999.
[5] A. Arasu, J. Cho, H. Garcia-Molina, et al. Searching the web[J]. ACM Transaction on Internet Technology,2001.
[6] 罗一纾.微博爬虫的相关技术研究[D].哈尔滨:哈尔滨工业大学,2013.
LUO Yishu. Research on related technologies of micro blog[D]. Harbin: Harbin Institute of Technology,2013.
[7] Simon H A, Lea G. Problem solving and rule education: a unified view knowledge and organization[J]. Knowledge and Cognition,1974,15(2):63-73.
[8] Vapnik V. Statistical Learning Theory[M]. New York, Wilet,1998:11-23.
[9] 张健沛,徐华.支持向量机(SVM)主动学习方法研究与应用[J].计算机应用,2004(1):1-3.
ZHANG Jianpei, XU Hua. Research and application of active learning method for support vector machine(SVM)[J]. Computer Application,2004(1):1-3.
[10] 邵曦,姚磊.基于SVM主动学习的音乐分类[J].计算机工程与应用,2014:1405-0097.
SHAO Xi, YAO Lei. Music classification based on SVM active learning[J]. Computer Engineering and Application,2014:1405-0097.
[11] 刘康,钱旭,王自强.主动学习算法综述[J].计算机工程与应用,2012,34:1-4,22.
LIU Kang, QIAN Xu, WANG Ziqiang. Overview of active learning algorithm[J]. Computer Engineering and Application,2012,34:1-4,22.
[12] Vlachos A. Actibe learning with support vector machines[D]. Edinburgh: Master Science, School of Informatics, University of Edinburgh,2004.
[13] Tong S, Koller D. Support vector machine active Learning with applications to text classification[J]. Journal of Machine Learning Research,2002,2:45-66.
[14] 朱红斌,蔡郁.基于主动学习支持向量机的文本分类[J].计算机工程与应用,2009,2:134-136.
ZHU Hongbin, CAI Yu. Text classification based on active learning support vector machine[J]. Computer Engineering and Applications,2009,2:134-136.
[15] 刘晓亮,丁世飞,朱红,等.SVM用于文本分类的适用性[J].计算机工程与科学,2010,6:106-108.
LIU Xiaoliang, DING Shifei, ZHU Hong, et al. Applicability of SVM for text classification[J]. Computer Engineering and Science,2010,6:106-108.
[16] Tong S, Koller D. Support vector machine active learning with applications to text classification[J]. Journal of Machine Learning Research,2002,2:45-66.
收稿日期:2015年10月5日,修回日期:2015年11月20日
基金项目:湖北省教育厅2013年高等学校教学研究项目:基于移动学习的研究生微课程教学模式研究(编号:2013096)资助。
作者简介:高学伟,男,硕士研究生,研究方向:数据挖掘。郑世珏,男,教授,博士生导师,研究方向:数据挖掘。高丽,女,硕士,正高级工程师,研究方向:数据挖掘。李松丽,女,硕士研究生,研究方向:数据挖掘。
中图分类号TP393
DOI:10.3969/j.issn.1672-9722.2016.04.034
Monitoring and Early-warning on WeChat Based on SVM Active Learning
GAO XueweiZHENG ShijueGAO LiLI Songli
(Department of Computer Science, Central China Normal University, Wuhan430079)
AbstractIn this paper, by using the support vector machine(SVM) active learning algorithm, four types of alarm level(red, orange, yellow, green) classification are made on WeChat. By using the evaluation analysis technology of Wechat information, WeChat information early warning system is constructed to prediction events and phenomena that may affect social security. In order to evaluate the performance of the classifiers, 3036 different warning level sample grabed randomly are conducted classification experiment. And in the different learning samples, traditional SVM and active learning SVM are used to classify the test samples. Repeated experiments verify the feasibility of SVM active learning method in WeChat public opinion monitoring.
Key Wordssupport vector machine, active learning, WeChat, monitoring
