基于搭配关系的有标复句层次关系分析*
2016-08-11刁胜权汪春红刘凤娇
李 源 刁胜权 汪春红 郑 印 刘凤娇
(华中师范大学计算机学院 武汉 430079)
基于搭配关系的有标复句层次关系分析*
李源刁胜权汪春红郑印刘凤娇
(华中师范大学计算机学院武汉430079)
摘要为解决由于长复句以及搭配关系所导致的复句层次自动识别准确率下降问题,论文分析了复句中的标点使用规律,提出了基于SVM的分句界定方法;并基于复句关系词搭配规则,建立了复句的上下文无关文法形式化模型;依据该模型,提出一种改进的移进-归约算法;以期提高复句层次关系识别的准确率。
关键词复句; 层次关系; 自动识别; 分句划分; 移进规约
Class NumberTP391
1 引言
复句作为一种汉语语法的重要实体单位,其所表达的语义信息丰富而复杂。复句的层次分析,是自然语言处理领域很有意义且极具挑战性的课题之一。对复句进行层次关系的研究,不仅会加深对复句内部联结规律的认识,准确理解复句语义,也将会对复句信息工程的纵深化发展起到很大的促进作用[1]。
关于复句层次关系,前人已有很多研究,语言本体和应用层面如汪国胜、刘秀明、胡金柱,沈威,吴锋文,罗进军,鲁松、白硕等分别对复句关系层次[2~4]、结构分析、关系词标注及自动识别的研究与探讨,为我们进一步分析复句层次关系作出了可贵探索。理论与基础性工程方面如汉语复句关系词库的建设及其利用[5],汉语复句语料库,现代汉语介词知识库,清华大学的SDN和TCT973树库等成果,为我们提供了资源支撑。同时杜超华、胡金柱等、胡金柱、沈威等对复句关系词的识别研究[6],为我们分析复句层次关系做了相应的前期准备工作。
复句层次关系的分析需要以分句的准确界定为前提[8],然后利用关系词这一复句逻辑语义标志分析各分句间的依属关系,而分句的界定又需要充分把握标点符号这一语法成分。分句间以逗号、分号间隔,通常情况下,逗号、分号可以作为分句界定的标志,但排除下述情况:逗号也用于主语与谓语之间的停顿、谓语与状语之间的停顿等。汉语复句不仅标点丰富而复杂,而且复句关系词使用起来灵活多变,又包含多种隐现形式;复句关系词语是“复句中用来联结分句标明关系的词语”[9]。它是分句间逻辑关联和语义关系的形式标志,所以复句层次关系分析必须着重依靠关系词这一标志。
因此本文在研究汉语标点使用规律的基础上,首先针对分句界定问题提出了基于SVM的分句界定方法。最后,对复句的上下文无关文法形式化模型与基于搭配关系的移进-归约算法进行了分析和改进,提出一种基于搭配关系的有标复句层次分析方法。
2 有标复句的分句界定
复句是包含两个或两个以上分句的句子[9]。复句中各分句间语义上互相依存,结构上相互独立。分句间以逗号、分号间隔。根据《中华人民共和国国家标点符号用法》,分号仅用作复句中各分句间的分隔符号。因此界定分句只需分析逗号的抽象特征。
2.1逗号的形式化定义
复句由逗号分割出各个语言块,判断一个逗号是否可以界定分句必须依靠与其相邻的两个语言块。根据逗号两侧语言块的抽象特征,对逗号作如下定义。
定义
复句中逗号左右两侧的语块各有两种可能:分句或短语,在这里把逗号定义为其左右语块的有序对:〈L,R〉。L和R的取值各有两种:短语P(Phrase)或者分句C(Clause),因此,逗号的值空间为:〈P,P〉,〈P,C〉,〈C,P〉,〈C,C〉。
如例1,逗号两侧的语言块皆为分句,逗号值为〈C,C〉。例2中逗号表示主语和谓语之间的停顿,逗号值为〈P,P〉。
1) 政府的预算方案可能难以在货币议会获得通过【,/w】但政府仍决定要求议会于正月5日就货币该方案进行表决。/w
2) 完成祖国统一【,/w】是/v大势所趋。/w
对于〈P,C〉与〈C,P〉逗号两侧语言块不同质的两种情况。在观察实际语料的基础上进行分析和总结,对它们进一步细分:〈P,C〉与〈C,P〉分别细分为〈P,C〉-Ⅰ、〈P,C〉-Ⅱ与〈C,P〉-Ⅰ、〈C,P〉-Ⅱ。分别示例如下:
〈P,C〉-Ⅰ:
3) 我喜欢在春天去观赏桃花,/w在夏天去欣赏荷花,在秋天去观赏红叶【,/w】但更喜欢在冬天去欣赏雪景。/w
〈P,C〉-Ⅱ:
4) 自1997年4月以来【,/w】长沙市纺织系统共有1.1万名位下岗职工被重新安排就业。/w
〈C,P〉-Ⅰ:
5) 在家里,/w他是乖孩子【,/w】在学校,/w他是好学生。/w
〈C,P〉-Ⅱ:
6) 学生们来到了操场【,/w】高高兴兴地。/w
〈P,C〉-Ⅰ如例3,逗号左侧为状语块,右侧为分句。例4中逗号在状语和其修饰的句子之间,我们把这类句子归为〈P,C〉-Ⅱ。例5为〈C,P〉-Ⅰ,句子中逗号左侧是分句,右侧是一个状语块。〈C,P〉-Ⅱ如例6所示,逗号左侧是一个分句,右侧为一个状语。
总结上述规律:当逗号是用来连接并列的两个短语或者作为同一个分句中两个成分的分隔符时,逗号值为〈P,P〉,〈P,C〉-Ⅱ,〈C,P〉-Ⅱ,为分句内分隔符。当逗号值为〈C,C〉,〈P,C〉-Ⅰ和〈C,P〉-Ⅰ时,逗号作为分句之间的停顿。
2.2SVM分类器的构建及训练测试
依据上述规律,选用SVM算法对句子中的每个逗号进行分类,进而可以确定出其复句中各分句间的切分点,为后续复句关系的自动判定做好准备。至于判定逗号属性的SVM分类器[10],下面仅以线性可分的情况进行构建:
定义分类函数为:f(x)=wTx+b。f(x)=0则x为超平面上的点;f(x)≥0时对应分类值为1;f(x)<0时对应分类值为-1。
寻求分类函数f(x)=wTx+b的问题转化为对w,b的最优化问题,训练集中一个点距离超平面的远近可以表示为分类预测的确信程度;对于给定的训练集T和超平面(w,b),超平面关于样本点(x,y)的几何间隔为
r=(wTx+b)/‖w‖=f(x)/‖w‖
(1)
定义超平面(w,b)关于训练集T的几何间隔为超平面(w,b)关于T中所有样本点(xi,yi)的几何间隔最小值:
r=minri,i=1,2,…,n
(2)
寻求唯一的几何间隔最大分离超平面问题可以表示为下面的约束最优化问题:
maxr,w,br1/‖w‖
s.t.yi(wTxi+b)≥r1,i=1,2,…,m
(3)
式(3)中r1为函数间隔。
函数间隔的取值不影响最优化问题的解,取r1=1代入前面的最优化问题,即将离超平面最近的点的距离定义为1/‖w‖,最大化1/‖w‖和最小化1/2·‖w‖2等价,于是得出下面线性可分支持向量机学习的最优化模型:
maxr,w,b1/2·‖w‖2
s.t.yi(wTxi+b)≥r1,i=1,2,…,m
(4)
式(4)中凸二次规划问题求解w*与b*,涉及到条件极值、拉格朗日乘法等,由于篇幅问题不再列出。最终分类函数为
(5)
式(5)中αi为Lagrange乘子。
根据f(x)的符号来确定x(即根据逗号两边的语言片段而提取的特征向量)的归属。
所有的SVM训练和测试过程基本一致,都是根据训练集进行训练,产生最优模型并将模型信息储存在“model”文档中,然后依据该模型预测测试文本中的数据。SVM进行训练之前,必须从现有语料中提取有利于分类的特征并将其转换成SVM所需要的格式。SVM对逗号的分类仅作为对复句逻辑语义关系分析所用语料的预处理,由于时间问题,对逗号属性特征向量的抽象提取这部分仅参照前人已有的技术。
本文从CCCS语料库中抽取了复句1221条,依次使用SVM进行了分句界定,并人工校验;准确率达94.04%以上,已达到下一步分析复句层次关系的要求。
3 基于搭配关系的有标复句层次关系分析
本文对有标复句层次关系的分析是基于复句的上下文无关文法模型之上。上下文无关文法是用一组规则进行运算的语言生成器,它是由一个四元组(V,Σ,R,S)构成,其中V是一个字母表,Σ是终结符(V的子集),R是规则的集合(为(V-Σ)×的有穷子集),S∈(V-Σ)是起始符,V-Σ表示非终结符集合。由上下文无关文法G生成的语言L(G),称做上下文无关语言。
3.1改进的复句上下文无关文法描述
复句关系词是复句逻辑语义关系的重要形式标记[8],对有标复句进行层次关系的自动判定,必须依靠关系词这一资源。因此下文基于关系词采用上下文无关文法对复句进行形式化描述:
G=(V,R,P,S),其中V={S,R,Cf,Cb},
R={因果,转折,并列等},
S={S1,S2,S3…},
P={S→R,R→Cf+Cb,
R=Cf+φ,R=Cf+R,
R=φ+Cb,R=R+Cb,
R=φ+φ,Cf=因为|只要|只有|……
Cb=所以|就|才|……
}
对上面复句的文法G的解释如下:
V表示所有元素的集合,包括关系类型集合(因果、并列等)和分句集合(S1,S2等)。R为关系类型的集合。S代表复句,是起始符。P为规则的集合:复句由关系构成,关系由因果、并列转折等构成,因果关系由因果类前呼标和因果类后应标构成,因果类前呼标包括“因为”、“因”等,因果类后应标包括“所以”、“因此”等……。
说明:由于当在语义环境信息已足够时,复句经常出现关系词隐现的情况。针对此问题该文法对原有复句上下文无关文法进行了改进[7],将零关系词〈1〉作为一个实体,与其他关联词同等对待;规则中引入了关系词的前呼标Cf和后应标Cb。
3.2基于搭配关系的移动归约算法分析
有标复句层次分析是基于文法L(G)构造的。基本数据结构包括栈和队列,队列主要存放待处理数据(关系词五元组对象〈2〉),栈记录已移进的数据,操作包括移进、归约、拒绝和接受四种。针对关系词搭配规则的移进-归约过程,依据归约条件和归约方式,把归约分为关系归约和句法归约两大类。
1) 关系归约即关系搭配表中的两个关系词归约为相应的逻辑关系,假设P1为前呼标对象,P2为后应标对象,则P1,P2归约为R(P1,P2)=相应逻辑关系LR(因果、并列、转折等)。
句法归约是对同一分句的关系词对象进行归约,同一分句关系词对象没有逻辑关系即R(P1,P2)没返回值。
下面根据关系搭配规则,因程序编码的需要,将归约情形归纳如下(设S1为栈顶元素,S2为栈顶第二个元素,q1为待入栈的元素,S为归约后产生的的五元组对象):
1〉条件:连续三分句,S2前呼标,S1零关系词,q1前呼标。归约为:R(S1,S2)=“并列关系”;S入栈;重新申请q1入栈。
21〉条件:连续三分句,S2前呼标,S1零关系词,q1后应标;且S2与q1有匹配的逻辑关系。归约为:R(S1,S2)=“并列关系”;S入栈;重新申请q1入栈。
22〉条件:连续三分句,S2前呼标,S1零关系词,q1后应标;且S2与q1不匹配。归约为:R(S1,S2)=相应逻辑关系;申请S入栈;重新申请q1入栈。
3〉条件:连续三分句,S2后应标,S1零关系词,q1后应标。归约为:R(S1,S2)=“并列关系”;S申请入栈;重新申请q1入栈。
4〉条件:连续三分句,S1是零关系词,q1零关系词。归约为:R(S1,q1)=“并列关系”;S入栈。
5〉条件:连续三分句,S2关系词,S1后应标,q1前呼标。归约为:R(S1,S2)=相应逻辑关系;申请S入栈;重新申请q1入栈。
6〉条件:连续三分句,S2关系词,S1后应标,q1后应标。归约为:R(S1,S2)=相应逻辑关系;申请S入栈;重新申请q1。
7〉条件:连续两分句,S1前呼标,q1后应标。归约为:R(S1,q1)=相应逻辑关系;申请S入栈。
8〉条件:连续三分句,S2关系词,S1是前呼标,q1后应标;且S2和S1名称相同。归约为:R(S1,S2)=“并列关系”;S入栈;重新申请q1入栈。
9〉条件:连续两分句,S1前呼标,q1为前呼标;S1和q1的名称相同。归约为:R(S1,q1)=“并列关系”;S入栈。
10〉条件:同一分句,S1为前呼标,q1为待入栈关系词。归约为:R(S1,q1)句法归约;S入栈。
11〉条件:同一分句,S1后应标,q1为待入栈关系词。归约为:R(S1,q1)句法归约;S入栈。
12〉条件:连续两分句,进行关系归约,S1关系词,q1后应标。归约为:R(S1,q1)=相应逻辑关系;申请S入栈。
13〉条件:队列为空,S2和S1为连续两分句,S2关系词,S1后应标。归约为:R(S2,S1)=相应逻辑关系;S入栈。
14〉条件:队列为空,S2和S1为连续两分句,S2为零关系词,S1为后应标。归约为:R(S2,S1)=相应逻辑关系;S入栈。
15〉条件:队列为空,S2和S1为连续两分句,S2前呼标,S1零关系词。归约为:R(S2,S1)=相应逻辑关系;S入栈。
3.3有标复句移进-归约实例分析
例7我们宁可少打点粮食,多吃点亏,也不能把党的性质改了!
该复句经预处理过程中的分句界定,关系词提取并调用词库中配位字段后得到三个关系词元素〈3〉:[宁可1-f],[φ2],[也3-b]。依据上文中16种归约情形进行决策判断。详细的移进归约步骤如图1所示。
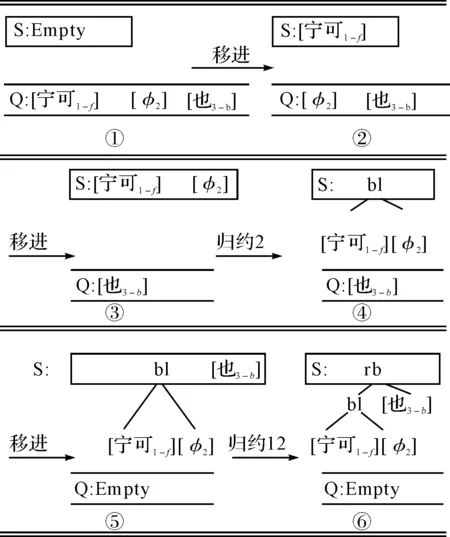
图1 有标复句移进归约实例分析
4 实验结果及分析
上文移进-归约方法实现了复句层次关系的判定;现从语料库中选择多种类型的复句,首先进行分句界定、关系词提取等预处理,最后进行层次关系的实验测试与结果分析。
语料库选用CSSS〈4〉,库中有65万多条复句,很难对所有的复句进行处理;因此,按照复句的复杂程度,从单重到多重抽取部分复句作为语料,进行实验。本文选取语料库中1000条复句作为层次分析的测试用例,进行开放性测试,实验结果如表1所示。
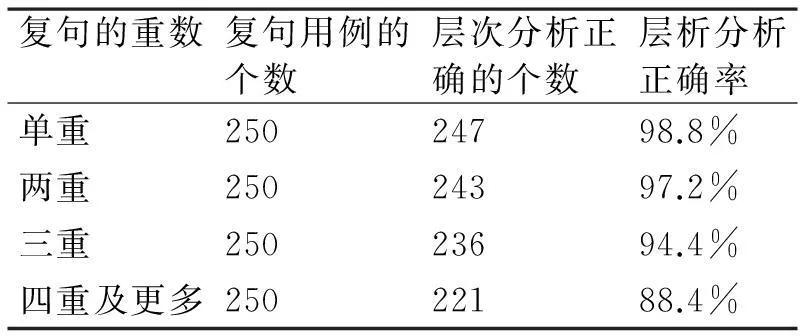
表1 实验结果表
鲁松等在文献中选择了因果、让步、目的等十种关系的328条复句进行开放性测试,正确率达到了93.8%;本文选择语料库中复句,从单重到多重分类进行实验和统计分析,单重复句的正确率最高达到98.8%;其次是出现频率较高的二重复句,准确率达到97.2%;四重及以上复句,正确率88.4%;整体准确率达到了94.7%。错误原因包括分句界定、关系
词标注出错,还有相关的语义语境等方面。
5 结语
本文在中文分词与词性标注的基础上,对有标复句进行层次关系分析,提出了一种基于关系词搭配的移进-归约算法。在分句界定问题上使用基于SVM的分句划分方法,达到了较高的准确率;并构建了复句的上下文无关文法形式化模型,改进了移进-归约算法,推导出复句的层次关系树。层次识别整体准确率达到94.7%。
本文对有标复句层次关系的分析是基于逻辑关系的二义性与关系词的就近匹配原则;但有些关系词比如“……一边……一边……一边……”等情况,构建相应的规则表必须要借助于语义分析。下一步工作将针对此问题进行语义关系方面的研究。
参 考 文 献
[1] 姚双云.小句中枢理论的应用与复句信息工程[J].汉语学报,2005(4):73-81.
YAO Shuangyun. Application of the Theory of Clausal Pivot and Complex Information Engineering[J]. Chinese Linguistics,2005(4):73-81.
[2] 鲁松,白硕,李素建,等.汉语多重关系复句的关系层次分析[J].软件学报,2001,12(7):39-47.
LU Song, BAI Shuo, LI Sujian, et al. Parsing the Logical Embedded Complex Sentences in Chinese[J]. Journal of Software,2001,12(7):39-47.
[3] 吴锋文.面向信息处理的“一标三句式”复句层次关系判定[J].北方论丛,2012(1):69-73.
WU Fengwen. Recognition of hierarchy and semantic relatirelations of compound sentence made up of one mark and three clauses faced to Chinese information processing[J].The Northern Forum,2012(1):69-73.
[4] 胡金柱,陈江曼,杨进才,等.基于规则的连用关系标记的自动标识研究[J].计算机科学,2012,39(7):196-200.
HU Jinzhu, CHEN Jiangman, YANG Jincai, et al. Research on Auto-identifying of Adjoining Relation Markers Based on Rule[J]. Computer Science,2012,39(7):196-200.
[5] 胡金柱,吴锋文,李琼,等.汉语复句关系词库的建设及其利用[J].语言科学,2010,9(2):25-34.
HU Jinzhu, WU Fengwen, LI Qiong, et al. Establishment and Exploitation of Relationship Marked for Chinese Complex Sentences[J]. Linguistic Sciences,2010,9(2):25-34.
[6] 杜超华,胡金柱,沈威,等.基于复句语料库分词系统研究[J].计算机数字与工程,2007,35(5):7,56-57,94.
DU Chaohua, HU Jinzhu, SHEN Wei, et al. Research on the segmentation system based on the Corpus of Chinese Compound[J]. Computer & Digital Engineering,2007,35(5):7,56-57,94.
[7] 邢福义.汉语语法学[M].长春:东北师范大学出版社,1996.
XING Fuyi. Chinese grammar[M]. Changchun: Northeast Normal University Press,1996.
[8] 吴锋文,胡金柱,肖明,等.基于规则的汉语复句层次关系自动识别研究[J].华文教学与研究,2010(1):89-96.
WU Fengwen, HU Jinzhu, XIAO Ming, et al. Research on auto-matic recognition of Chinese compound sentences based on Rules[J]. TCSOL Studies,2010(1):89-96.
[9] 邢福义.汉语复句研究[M].北京:商务印书馆,2001.
XING Fuyi. Research on Chinese sentence[M]. Beijing: The Commercial Press,2010.
[10] 罗强,奚建清.一种结合SVM学习的产生式依存分析方法[J].中文信息学报,2007,21(4):23-28,43.
LUO Qiang, XI Jianqing. An SVM-Based Generative Statistical Algorithm for Chinese Dependency Analysis[J]. Journal of Chinese Information Processing,2007,21(4):23-28,43.
收稿日期:2015年10月7日,修回日期:2015年11月27日
基金项目:教育部人文社会科学研究规划基金项目:现代汉语复句依存句法自动分析方法研究(编号:14YJA740020)资助。
作者简介:李源,男,博士,副教授,硕士生导师,研究方向:中文信息处理,软件工程等。刁胜权,男,硕士研究生,研究方向:中文信息处理。汪春红,女,硕士研究生,研究方向:中文信息处理。郑印,男,硕士研究生,研究方向:中文信息处理。刘凤娇,女,硕士研究生,研究方向:中文信息处理。
中图分类号TP391
DOI:10.3969/j.issn.1672-9722.2016.04.027
Analysis of Marked Complex Sentence Hierarchy Based on Collocation Relationship
LI YuanDIAO ShengquanWANG ChunhongZHENG YinLIU Fengjiao
(School of Computer, Huazhong Normal University, Wuhan430079)
AbstractIn order to solve the accuracy decline of automatic recognition caused by long sentence and collocation relation, punctuation rules are analyzed, on this basis, a kind of clause-partitioning method is proposed based on SVM classification, and a formal model of sentence context free grammar is established based on collocation relationship. According to the model, an improved shift-reduce algorithm is proposed to increase the accuracy of automatic identification.
Key Wordssentence, hierarchy, automatic recognition, classification clause, shift and reduce
