基于LDA的网络评论主题发现研究
2016-08-11王庆福王兴国
王庆福,王兴国
(辽宁行政学院,辽宁 沈阳 110161)
基于LDA的网络评论主题发现研究
王庆福,王兴国
(辽宁行政学院,辽宁 沈阳 110161)
目前国内存在各种类型的舆论平台,以资讯类舆论平台为主,咨询类平台的受众通常都会对咨询进行评论,分析提取评论中主题内容,对评论信息进行分类分析。了解当前网民的核心诉求具有非常重要的意义。主题模型作为主题发现中重要的模型手段,对主题的定位具有明显的效果。
网络评论;主题发现;网民导向
伴随着新闻资讯类平台的不断出现,网络上越来越多的网民评论信息,这些信息一方面反映了当下网民对当前时政的看法,另一方面也可以分析当前网民的兴趣点。因此对网络评论的分析一方面可以提供施政机关以舆情导向,另一方面,通过网民的评论分析也可以对平台改善用户体验,分析用户行为提供重要借鉴。
政府机关的官方网站有很多市民的评论信息,今日头条和网易新闻等社交媒体也有众多的网民评论信息,电商平台有众多的用户对商品和服务的评价信息。分析这些评论信息背后用户的意图,对施政机关来说,可以提高自身施政的力度,电商平台等可以分析用户的评论来改善服务,或者可以通过用户的满意程度来调整推荐的内容等。
1 LDA算法简介
主题模型的表示中,主题可以定义为一个概念,它可以由一系列的单词组成,主题是这些单词的条件概率。可以直白地认为主题是一个桶,桶内装满了各种出现概率高的单词,这些单词与这个主题有很强的关联性。
主题是一个隐藏的信息,需要通过一定的手段来做发现,可以理解为每篇文档都以一定的概率包含某个词,文档通过包含的词来体现一定的主题,文档需要从主题中选取一些需要的词来组成文档,这是一个完整的过程。因此,生成一篇文档时,每个词出现的概率如公式1所示。
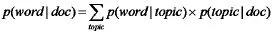
(公式1)
将主题模型的公式表示具体到图的形式如图1所示。
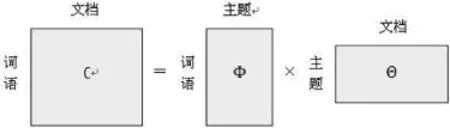
图1 主题模型的公式示意
“文档-词语”构成矩阵表示每个词语在文档中出现次数,即出现频率。“词语-主题”矩阵表示每个词语在给定主题中出现频率。“文档-主题”矩阵表示每个文档包含该主题的概率。给定一系列文档,首先对文档进行分词,计算各个文档中词语频率可得到“文档-词语”矩阵,主题模型即是通过“文档-词语”训练得到“词语-主题”和“文档-主题”矩阵。
主题模型最早使用SVD的LSA(隐形语义分析),然后引入基于概率的pLSA(ProbabilisticLatent Semantic Analysis),其参数学习采用EM算法和后来改进PLSA,引入hyperparameter的LDA(Latent Dirichlet Allocation),其参数学习主要采用EM和Gibbs sampling,下面主要介绍LDA。
2 主题发现
网民的评论并没有主题信息,展现形态是一条一条的语句,需要对这些语句进行分析处理,构建主题模型进行训练。LDA以文档集合D作为输入(会有切词,去停用词,取词干等常见的预处理,略去不表),希望训练出的2个结果向量(设聚成k个Topic,VOC中共包含m个词),如图2所示。
对每个D中的文档d,对应到不同topic的概率θd=<Pt1,…,Ptk>,其中,Pti表示d对应T中第i个topic的概率。计算方法是直观的,Pti=nti/n,nti其中表示d中对应第i 个topic的词的数目,n是d中所有词的总数。
t=<Pw1,…pwm>,其中,Pwi表示t生成VOC中第i个单词的概率。计算方法同样很直观,Pwi=nwi/n,其中nwi表示对应到topic t的VOC中第i个单词的数目,N表示所有对应到topic t的单词总数。

图2 LDA主题模型学习
在表1中,给出了一些主题对应的词语概率表示,表示这些词语落在当前主题(桶)内的概率。

表1 主题-词语对应
许多算法可以训练一个LDA模型。选择EM算法,因为它简单并且快速收敛。用EM训练LDA有一个潜在的图结构,在GraphX之上构建LDA是一个很自然的选择。
LDA主要有2类数据:词和文档。把这些数据存成一个偶图(见图3),左边是词节点,右边是文档节点。每个词节点存储一些权重值,表示这个词语和哪个主题相关;类似的,每篇文章节点存储当前文章讨论主题的估计。

图3 文档-词语-主题表示
LDA是众多主题模型中一种,它们都是基于概率分布假设的领域。LDA试图通过当前的已知数据推测生成未知数据即隐藏主题的过程。LDA的过程定义了观测数据和推测隐藏数据之间的联合概率分布。通过使用联合分布来推测估算隐藏变量的条件分布(后验概率)进行数据分析。对于LDA而言,观测数据就是文档和词语构成的联合矩阵数据,隐藏变量就是词语之间主题结构。则推测文档中隐含的主题信息其实就是在给定数据的前提下生成隐藏变量的分布。
LDA主要基于多种假设信息,LDA将文档表示成词袋的形式,文档中各个词语构成词袋中各个元素,其通过弱化文档中某些信息来发现文档中潜藏的更加复杂的结构。这种假设虽然在某种程度上不符合现实,但是在发现文本中语义结构信息确具有非常重要大意义。LDA通过构建文档和词语之间的关联性,以理论化的方式对关联矩阵进行矩阵分解,分解的要义就是通过发现文档和词语之间的潜藏信息(主题结构)。LDA巧妙地将未知隐藏数据的分析转化为当前已经信息进行分析(后验概率)。在LDA和隐马尔可夫模型之间进行切换的主题模型。这些模型显著地扩展了参数空间,并且显示了语言建模带来的性能提升。
3 结语
LDA是一个优秀的模型,主题被作为隐藏的信息可同时作用在词语和文档上,它并非是单一主题的适配,而是多个主题同时发现的结果,每组文档通过不同的概率分布来包含着多种主题。值得一提的是,产生的LDA的模型参数和概率分布可以通过简单的微调可适用于其它的推断算法。为了适配用户偏好、机器翻译、搜索日志、用户评论和社交网络等多种数据,LDA衍生出多种类型的数据进行分析。
LDA模型的推断算法不仅在文本处理领域崭露头角,也被广泛运用在其它领域。例如研究者们通过类别文本中词语包含主题信息,在图像分析时,每幅图像都可以表征为由一个个视觉模型组合而成,则此处的视觉模型可以联想为文本中主题信息,主题模型在图像领域可以被用来进行图像分类,图像识别等。另外,主题模型可以实现对原始数据的压缩,通过将原始数据转换为联合矩阵的形式,联合矩阵经过主题训练后分解为矩阵相乘的形式,分解后的矩阵包含了原始数据中主要信息,可以提取适当的维度来实现数据压缩的效果。
[1]陈文涛,张小明,李舟军.构建微博用户兴趣模型的主题模型的分析[J].计算机科学,2013(4):127-130,135.
[2]朱旭东,刘志镜.基于主题隐马尔科夫模型的人体异常行为识别[J].计算机科学,2012(3):251-255,275.
[3]王李冬,魏宝刚,袁杰.基于概率主题模型的文档聚类[J].电子学报,2012(11):2346-2350.
[4]魏强,金芝,许焱.基于概率主题模型的物联网服务发现[J].软件学报,2014(8):1640-1658.
[5]杨潇,马军,杨同峰,等.主题模型LDA的多文档自动文摘[J].智能系统学报,2010(2):169-176.
Research on Topic Discovery in Online Reviews Based on LDA
Wang Qingfu,Wang Xingguo
(Liaoning Academy of Governance,Shenyang 110161,China)
The various types of public opinion platform, based on information platform of public opinion and consulting platform audience usually comments on consultation, analysis to extract thematic content review, to review the information for classification analysis, to understand the core demands of the current Internet users has very important significance. Topic model, as an important model in the subject discovery, has obvious effect on the orientation of the subject.
online review; topic discovery; public opinion
王庆福(1979-),男,辽宁沈阳,本科,讲师;研究方向:计算机网络与数据库技术。
