声学场景深度识别系统设计
2016-08-10黄程韦
李 嘉,黄程韦,韩 辰
(1.江苏省广播电视总台,南京 210013;2.苏州大学,苏州 215006)
声学场景深度识别系统设计
李 嘉1,黄程韦2,韩 辰1
(1.江苏省广播电视总台,南京 210013;2.苏州大学,苏州 215006)
基于视频的监控系统存在很多不足,声学场景识别系统依据基于人耳听觉仿生的目标声音识别技术,积极探索先进的人耳仿生理论、特征提取技术、目标声音分类技术,实现对声音场景进行自动化分类和信息抽取,具有广泛的应用前景。
声音识别;声音场景;特征提取;神经网络
1 引言
声学场景深度识别系统既可对目前的视频监控进行有益的补充,以应对遮蔽、光照变化、死角等情况,还可对声音信号场景进行识别,方便自动搜索海量数据、识别目标,并实时发现和处理突发事件。
2 系统设计
2.1 系统总体架构
系统总体框架如图1所示。

图1 系统总体架构
2.2 网络拓扑
音频传感器尺寸较小,可较为隐蔽的布放,也可以和视频摄像头布置在一起,作为对视频监控的有益补充,将采集的音频特征通过Wi-Fi、数据网络或者有线方式传输给后台数据中心处理。
2.3 功能设计
该系统可实现如下几个功能:场景识别,身份识别,内容检索,声源定位与信号增强。
3 关键技术原理
3.1 信号特征提取
通过对公共场所异常声音声谱图等特性的分析,将公共场所异常声音信号转换为异常声音的声谱图,采用2D-Gabor滤波器对声谱图时频特征进行特征描述;采用随机非负独立成分分析(SNICA)提取异常声音的声谱图特征,最后采用稀疏表示分类(SRC)方法进行分类识别。
下面描述基于人耳掩蔽效应的增强算法。由于语音信号通常是逐帧进行处理的,写成帧的形式
y(m,n) = x(m,n) + d(m,n)
式中,m为帧的序号,m=1,2,3…;n为帧内数据点序号,n=0,1,…,N-1,N为帧长。对等式两边进行傅里叶变换,可得
Y(m,k) = X(m,k) + D(m,k)
式中,k是离散频率;Y(m,k),X(m,k),D(m,k)分别是含噪语音y(m,n)、纯净语音x(m,n)、噪声d(m,n)的傅立叶变换。
增强以后的语音幅度谱函数可以表达为

增强函数的形式可以表达为
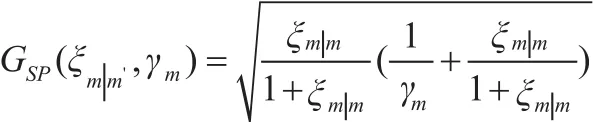
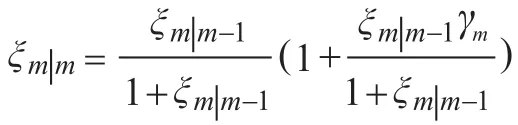
定义信号功率谱估计
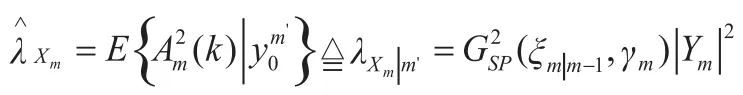
式中,Am(k)为第m帧估计语音谱的幅度,则有增强后的语音谱函数为
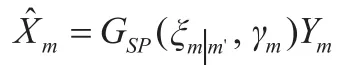


根据可听闻阈的要求,令

上式就是令畸变噪声的能量在掩蔽阈值以下,而不被人耳感知。为了推导方便,令
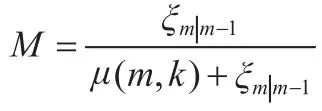
则有
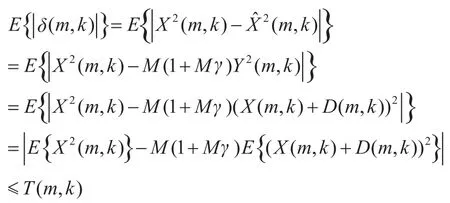



化简后得到

即
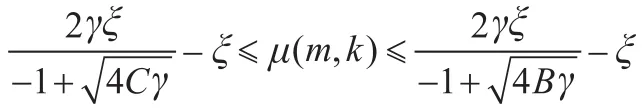
3.2 模型优化算法
在模型优化方面,通过启发式优化方法,对模型参数进行优化;通过高阶马尔科夫场对识别结果进行动态纠正,提高识别鲁棒性。
3.3 深度机器学习
在深度机器学习方面,依据人耳听觉特性,研究符合认知规律的深度神经网络模型。依据短时记忆规律,提高声音目标的识别模型。
3.4 概率模型
高斯混合模型对这些数据的适应能力较强,可能是多数应用场合的一种合理选择。高斯混合模型(GMM)可以定义为
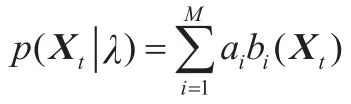
式中,X是语音样本的D维特征向量,t为其样本序号;bi(X),i=1,2,…,M是成员密度;ai,i=1,2,…,M是混合权值。每个成员密度是一D维变量的关于均值矢量Ui和协方差矩阵的高斯函数,形式如下
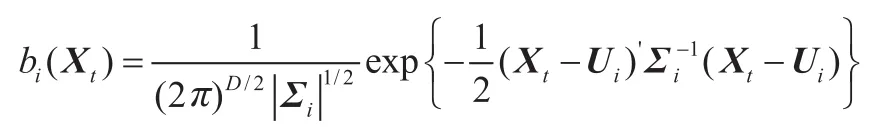
其中混合权值满足条件:
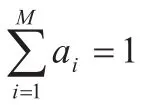
完整的高斯混和密度由所有成员密度的均值矢量、协方差矩阵和混合权值参数化。这些参数聚集一起表示为

根据贝叶斯判决准则,基于GMM的识别可以通过最大后验概率来获得,
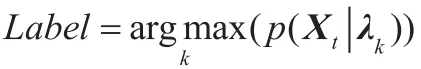
式中,k为类别序号。
对于高斯混合模型的参数估计,可以采用EM (Expectation-maximization)算法进行。EM是最大期望算法,它的基本思想是从一个初始化的模型开始,去估计一个新的模型,使得。这时新的模型对于下一次重复运算来说成为初始模型,该过程反复执行直到达到收敛门限,这类似于用来估计隐马尔科夫模型(HMM)参数的Baum-Welch重估算法。每一步的EM重复中,下列重估公式保证模型的似然值单调增加:
方差矩阵的重估:

GMM各个分量的权重、均值和协方差矩阵的估计值,通过每一次迭代趋于收敛。
高斯混合模型中的混合度,在理论上只能推导出一个固定的范围,具体的取值需要在实验中确定,各高斯分量的权重可以通过EM算法估计得到,在EM算法的迭代中,要避免协方差矩阵变为奇异矩阵,保证算法的收敛性。
4 技术应用
声学场景识别系统目前有两大类应用:安防监控和内容检索,这两类主要应用可以很好地用于智慧城市中。基于音频的安防监控在工业、消费者、政府部门有不同的应用。音频场景识别技术的另一个重要应用,是在基于内容的多媒体检索中。
[1] 李嘉,黄程韦,余华.语音情感的唯独特征提取和识别[J].数据采集与处理,2012(03)
[2] 黄程韦,赵艳,金赟,于寅骅,赵力.实用语音情感的特征分析与识别的研究[J].电子与信息学报,2011, 33(1): 112-116. EI: 20111213768173
[3] 黄程韦,金赟,王青云,赵艳,赵力.基于特征空间分解与融合的语音情感识别[J].信号处理,2011, 26(6): 835-842
[4] Chengwei Huang, Dong Han, YongqiangBao, Hua Yu, and Li Zhao,Cross-language Speech Emotion Recognition in German and Chinese,ICIC Express Letters, vol.6, no.8, August, 2012,pp.2141-2146. EI:20123515376775
[5] Chengwei Huang, Yun Jin, Yan Zhao, Yinhua Yu, Li Zhao, Speech emotion recognition based on re-composition of two-class classifiers. International Conference on Affective Computing and Intelligent Interaction and Workshops, Amsterdam, Netherlands, 10-12 Sept. 2009. EI: 20101112772813
Talk about Acoustic Scene Recognition System
Li Jia1, Huang Chengwei2, Han Chen1
(1.Jiangsu Broadcasting Corporation, Nanjing, 210013; 2.Soo Chow University, Suzhou, 215006)
As video monitoring systems has many deficiencies, Acoustic Scene Recognition System is built on target voice recognition technology based on Bionic ear hearing, and actively explore advanced ear bionic theory,feature extraction, target sound classification technology. It can achieve the sound scene automated classification and information extraction, and has broad application prospects.
Voice Recognitio; Sound Scene; Feature Extraction; Neural Networks
10.3969/J.ISSN.1672-7274.2016.07.005
TN912 文献标示码:A
1672-7274(2016)07-0012-03
