基于大数据吞吐效益评估的网络数据综合调控算法研究*
2016-08-10闫娜
闫 娜
(陕西财经职业技术学院 咸阳 712000)
基于大数据吞吐效益评估的网络数据综合调控算法研究*
闫娜
(陕西财经职业技术学院咸阳712000)
摘要鉴于当前云网络研究过程中普遍存在的吞吐困难、评估机制单一及难以解决网络拥塞现象等问题,论文在大数据吞吐效益评估基础上,提出了一种网络数据综合调控算法。首先,通过在数据生命周期内评估数据调控成本,依据网络数据具有的大数据吞吐性能进行资源匹配;然后将用户级别的资金价值、生命周期等因素嵌入到成本函数中,从而实现了网络数据的资源调度优化,降低了网络拥塞现象的发生。仿真结果表明,与DBC算法相比,论文算法能够提高网络节点的吞吐性能,增强网络的数据调控效率,改善节点带宽的运行性能,具有较好的实际部署价值。
关键词云网络; 大数据吞吐; 网络数据综合调控; 资源调度; 调控成本; 质量因素
Class NumberTP393
1引言
随着云网络计算技术的飞速发展,网络中数据并发量及用户数据资源量也呈现飞速发展的趋势,对云网络系统的数据资源调度及处理性能也提出了很高的要求。然而当前研究过程中,大部分云网络系统依然采取传统的资源调度及管理模式,往往通过确定的成本函数来对当前的任务进行调度,处理过程中一般以系统为中心,很少通过用户数据的性能综合评估成本,以便实现网络数据资源的合理调度,导致网络计算性能难以随着用户数据的增长而得到改善,成为云计算技术中一个重要的瓶颈[1]。
为解决云网络中资源调度问题,实现更好的数据处理性能,人们做出了很多的研究工作[2]。olliffeD等[3]提出了一种基于经济管理模型的网络数据调控算法,通过综合评估用户数据资源及形同节点的性能,采用最低成本评估机制实现对资源的有效利用。然而,该种算法由于仅仅基于系统端对数据进行评估,当用户数据资源的请求处于不同层次时,将难以实现数据的精确调度。Yang K等[4]提出了一种基于密集归类的数据调控机制,通过将用户数据归类为不同密集程度的任务的方式赋予不同的用户数据处理资源,从而实现对用户数据的转发与处理。但是,该种算法对用户带宽占有情况未能加以考虑,当多个用户同时在处理节点上进行数据处理时往往会造成严重的数据拥塞现象。Bal M等[5]在用户侧数据供给基础之上,采用供给侧弹性判断机制对网络数据量进行实时评估,实现了高并发数情况下的网络数据拥塞控制。然而。该种机制由于需要在整体层面上对用户侧数据供给进行判断,当网络环境复杂时数据处理效率呈现不断下降的趋势。
鉴于当前研究中存在的上述问题,本文提出了一种基于大数据吞吐效益评估的网络数据综合调控算法,通过综合评估数据调控成本及大数据吞吐性能基础上,实现了对整体效益的建模。随后通过引入用户级别的质量因素,增强了数据处理性能,从而提高了网络数据处理质量,实现了调控有效性,降低了网络拥塞程度。随后通过仿真实验证明了本文算法的有效性。
2网络数据调度机制假设
目前大多数云计算环境下的调度和资源管理问题一般仍使用传统形式,即由调度构件如Glbous根据确定的花费函数来决定任务执行,但这些花费函数一般都是以系统为中心的,不能由用户的QoS参数,如存取价格、服务传送时间片等驱动[6]。在经济管理模型下,不同的系统当然不会花费同样的价格来存取相同的资源[7]。同时,终端用户也并不一定想要支付最高的价格来获得最有效的资源利用,而是有可能基于需求、价值、优先权和可供使用的预算协商一个特定的价格[8]。因此,从本质上而言,云网络中的数据调控机制可以简化为系统节点针对不同用户数据实现在资源受限情况下的最佳调度[9]。
在大数据的背景之下,各个用户数据需要能够在某个处理节点资源受限的情况下满足最低的服务要求,因此用户数据流与处理节点之间的实时交互因素将是最重要的处理因素[10]。云网络下的实时交互因素主要体现在节点反馈速度、资源可用性能、网络数据吞吐性能上[11]。本文选择资金价值(Money)、生命周期(Time)、处理可靠性(Reliability)三个实时交互维度性能约束条件下实现节点资源受限情况下对用户数据资源的调控工作。节点响应和用户数据需求被虚拟化为成本函数:benefit_c、benefit_dt和benefit_r。分别代表用户数据对节点响应时的成本代价。然后根据实时交互维度性能综合计算整体的数据处理代价。该问题的本质为N个数据请求需要节点通过调度M个网络资源来实现数据的最佳调度。此外,本文假设如下:
1)N个数据请求彼此之间处于互相独立状态,不存在进程依赖的现象;
2)M个网络资源只能通过特定的处理节点进行资源调度处理,即任意一个网络资源不能被第二个处理节点进行并发资源处理;
3) 任意一个节点,在当前数据请求未被释放时,将不得接收其他的数据请求。
3本文网络数据综合调控算法设计
由于第1节可知,整个调度过程需要遵循经济效益最大化原则,节点在处理数据时必须将N个数据请求与节点能够控制的M个网络资源进行最佳匹配,使得节点能够满足数据请求的同时,尽量减少资源的分配压力。对于任意一个用户数据请求而言,也希望能够以最短的生命周期实现自身请求的尽量满足。从而实现处理节点及用户数据的经济效益最大化。整个算法分为资源调度匹配、资源调度优化两个阶段。
3.1资源调度匹配
若当前云网络中存在N个数据请求,每个请求的长度为Li,用指令数来度量,单位为Mi百万指令,其资金价值Money及生命周期Time可以由用户指定,全部请求按照指令长度进行排序:
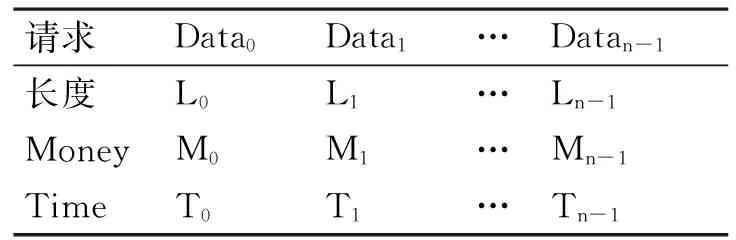
表1 提交的数据请求列表
对于任意时刻而言,系统处理节点需要将性能最好的资源分配给拥有最大资金价值的数据请求,当该资源能够满足资金价值(Money)、生命周期(Time)、处理可靠性(Reliability)三个维度的要求时,则处理之[12]。否则将考虑下一个可用的资源,并标注为已用资源。反复进行该过程直到数据处理过程结束。
整个资源调度匹配流程如下所示:
Step 1:系统处理节点随时接收用户数据请求;
Step 2:在数据请求的生命周期之内进行以下步骤:
1) 首先根据当前可用资源表进行数据请求的读取;
2) 根据数据请求的资金价值及生命周期,按照最佳资源匹配原则进行匹配;
3) 确认生命周期内可调度资源总量,再次进行匹配;
4) 计算运行结果并反馈
Step 3:资源调度匹配结束。
3.2资源调度优化
本文算法实质是通过综合评估数据流的资金价值(Money)、生命周期(Time)、处理可靠性(Reliability)三个信息交互维度,实现对数据流的综合调控。其中Money可以代表数据流的运营成本及数据吞吐成本,Time在网络实践中代表数据流的生命周期及最大处理周期,Reliability代表数据带宽及吞吐性能。
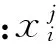
从信息交互维度可知,资金价值(Money)、生命周期(Time)、处理可靠性(Reliability)彼此处于互相独立状态,第一信息交互维度评估函数benefit_c与处理过程中花费的资金数量密切相关:
(1)
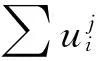
而第二信息交互维度评估函数benefit_dt与数据请求的生命周期密切相关:
(2)
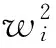
第三信息交互维度评估函数benefit_r代表调度的可靠性:
(3)
其中,g代表网络总体数据请求数量,f为数据请求的最大生命周期内的最小数据请求总数。
因此,任务的效用函数是这三部分的加权函数:
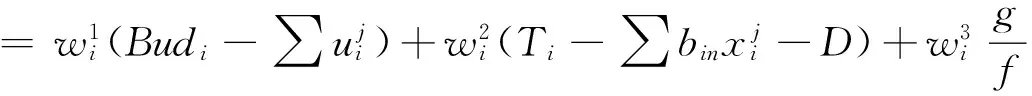
(4)
整个系统的效用函数:
Benefitsystem=∑Benefit_T
(5)
将系统效益函数最大化可得系统效益Bsystem并满足:
(6)
上述过程是一个典型的线性规划过程,通过柯西数学收敛准则可以迅速求出模型(6)的最佳解满足如下的表达式:
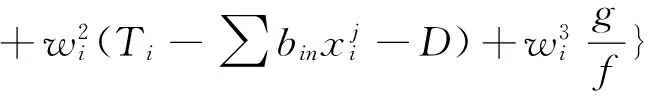
(7)
再利用拉氏求解发构造以下的辅助函数:
(8)
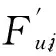
(9)
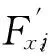
由于模型(7)和模型(9)对应的拉氏函数具有同一性,因此,当模型(7)取最优解时,模型(9)也同时获得最优解。
4仿真实验
由于云网络中的数据请求是处于并发状态,且网络节点总数对系统处理性能有非常大的影响,且数据请求的资金价值、生命周期、可靠性能与节点同时呈现正向比例关系。因此本文仿真算法主要从数据吞吐率、拥塞率、数据处理时间、分组投递率三个指标上,同当前广泛用到DBC算法[12]进行对比,以便验证本文算法的优势。本文仿真采取NS2仿真平台,详细仿真参数表如表2所示。
表2 仿真参数表
4.1数据吞吐性能
图1显示了在不同请求并发数量情况下,本文算法与DBC算法的数据吞吐带宽测试。从图中可以看到,本文算法数据吞吐率始终高于DBC算法。这是由于随着数据请求并发数量的不断增加,网络中数据流量也呈现急剧增加的状态,导致网络中数据拥塞出现的概率显著提高,而本文算法采用基于三维评估的方式,综合考虑了数据请求的资金价值、生命周期及可靠性的基础上,实现了数据的最佳处理,提高了数据吞吐性能。而对DBC算法由于仅仅考虑数据传输的可靠性因素,对数据请求的其他因素考虑较少,导致网络拥塞现象发生时难以实现对数据的实时处理,降低了数据吞吐性能。
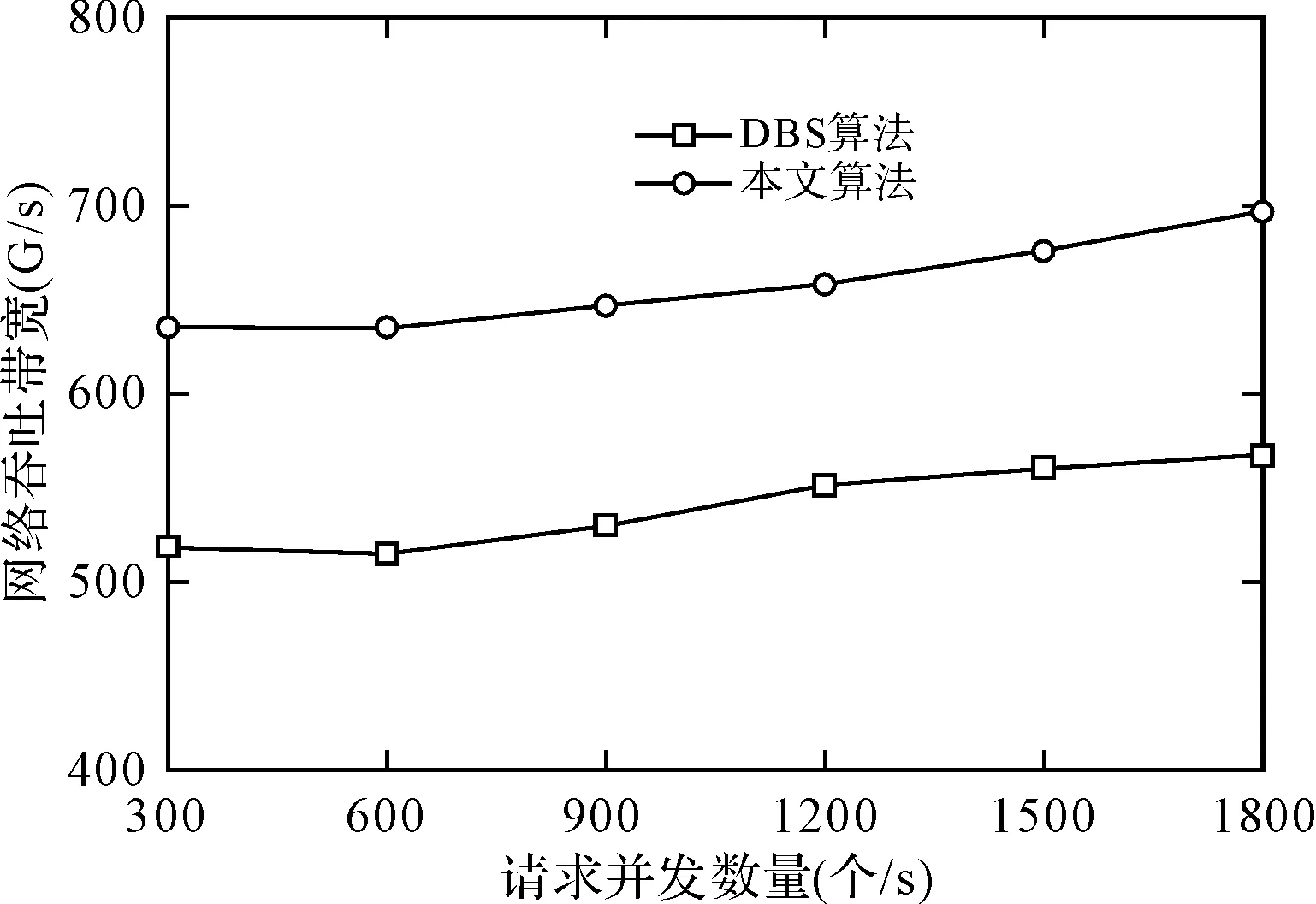
图1 不同算法的数据吞吐性能测试
4.2拥塞率
图2显示了在不同网络处理节点数量的情况下,本文算法与DBC算法的拥塞率测试。从图中可以看到,本文算法的拥塞率始终低于DBC算法,具有较好的稳定性。这是因为随着网络处理节点数量的不断增加,网络整体可调度的资源也随之增加,降低了网络拥塞节点在网络处理节点中所占据的比例。本文算法在数据生命周期内评估数据调控成本,能够在网络拥塞发生的情况下通过调度其他节点的处理能力的方式,满足当前请求的响应质量,因而降低了拥塞率。
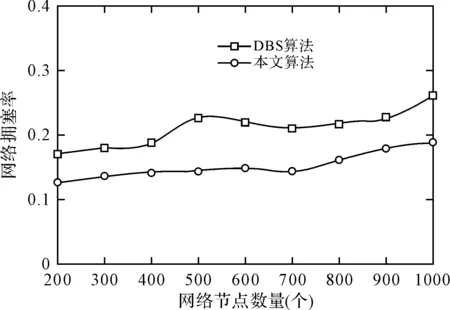
图2 各算法的网络拥塞率测试
4.3数据处理时间
图3显示了在不同的数据生命周期之内,本文算法与DBC算法的数据处理时间测试,从图中可以看到本文算法的数据处理时间始终低于DBC算法。这是因为DBC算法仅仅从带宽因素上对数据请求进行相应,一旦某个节点因请求未释放而后续数据请求纷至沓来之时,会发生因处理带宽不足而导致的拥塞现象。而本文算法可以将处理带宽等映射为资金价值(Money)、生命周期(Time)、处理可靠性(Reliability)三个维度,并在三个维度上同时通过计算最佳成本函数的方式实现最优传输,因此,本文算法的数据处理时间比DBC算法要低。
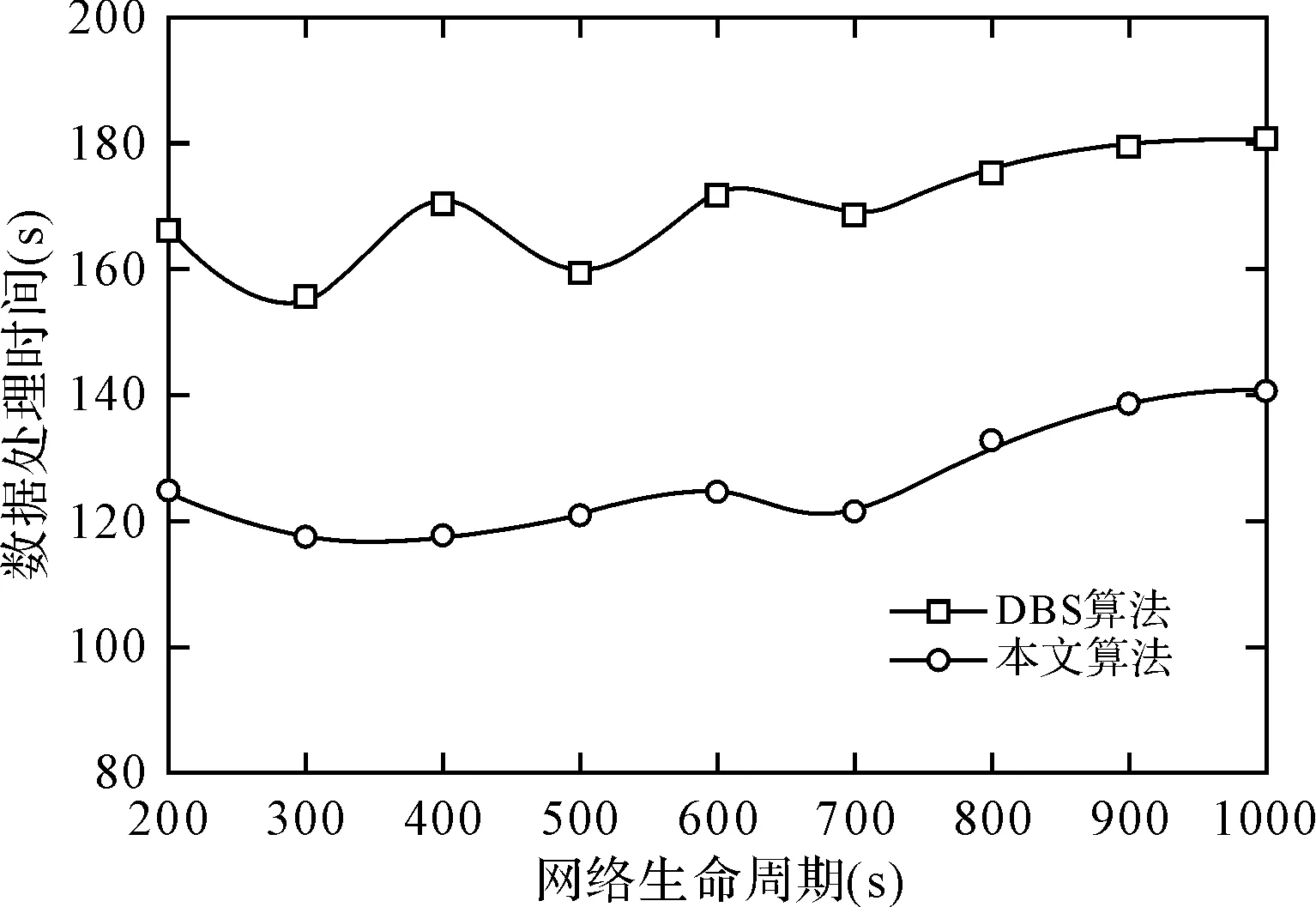
图3 两种算法的数据处理时间测试
4.4分组投递率
图4显示了在不同数据传输率的情况下,本文算法与DBC算法的分组投递率测试结果,从图中可以看到本文算法的分组投递率始终低于DBC算法,这是因为DBC算法仅仅采用单纯投递机制,当处理节点处于拥塞状态时将难以实现数据请求的实时相应。而本文算法同时可将单一节点的数据处理性能映射到其他节点上,且通过综合评估资金价值(Money)、生命周期(Time)、处理可靠性(Reliability)三个维度来实现数据的实时相应,从而降低了数据请求的时延,大大提高了分组投递性能。
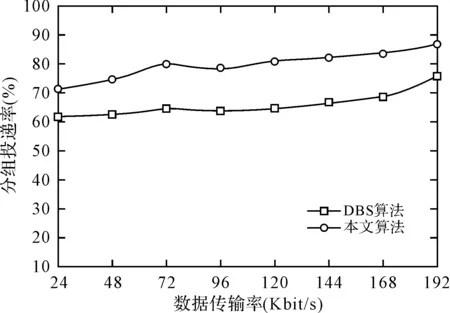
图4 各算法的分组投递率测试结果
5结语
本文提出了一种基于大数据吞吐效益评估的网络数据综合调控算法,主要通过综合评估数据请求的调控成本,在资金价值(Money)、生命周期(Time)、处理可靠性(Reliability)三个维度上实现节点资源受限情况下的数据请求的实时并发相应,从而实现了用户数据请求的实时调控,提高了网络的运行质量及性能。仿真实验表明:与DBC算法相比,本文算法能够改善网络拥塞状况,降低数据处理时间,提高网络数据吞吐性能具有明显的优势,在实践中具有很强的部署价值。
下一步,本文将通过引入无线传感网机制,通过云网络-自感网自适应映射机制,将云网络数据处理节点的处理能力映射到自感网中进行数据处理映射,从而进一步降低实践部署的成本及代价,有力提高网络的信息处理能力,实现效益的最大化。
参 考 文 献
[1] 胡自林,徐云,毛涛.基于效益最优的云网络资源调度[J].计算机工程与应用,2014,26(7):69-70.
HU Zilin, XU Yun, MAO Tao. Cloud cyber source based on optimal dispatching[J]. Computer Engineering and Applications,2014,26(7):69-70.
[2] LEE W. A data mining framework for constructing features and models for intrusions detection systems[D]. New York: Computer Science Department of Columbia University,2012(7):33-76.
[3] Jolliffe D, Tran T, Nguyen T. Data mining network coding[J]. IEEE Trans. on Vehicular Technology,2009,58(2):914-925.
[4] Yang K, Shahabi C. An efficient k nearest neighbor search for multivariate time series[J]. Information and Computation,2013,6(1):65-98.
[5] Bal M. Rough Sets Theory as Symbolic Data Mining Method: An Application on Table[J]. Information Sciences Letters,2013,2(1):111-116.
[6] 孙大为,常桂然,李凤云.一种基于免疫克隆的偏好多维QoS云资源调度优化算法[J].电子学报,2011,23(8):1824-1831.
SUN Dawei, CHANG Guiran, Li Fengyun. An optimization algorithm for multidimensional preference QoS cloud resource scheduling based on immune clone[J]. Chinese Journal of Electronics,2011,23(8):1824-1831.
[7] 张爱科,符保龙.基于最大收益平衡点动态变化的云资源调度算法[J].重庆邮电大学学报(自然科学版),2014,5(7):706-711.
ZHANG Aike, FU Baolong. The cloud resource scheduling algorithm of maximum profit equilibrium based on dynamic change[J]. Journal of Chongqing University of Posts and Telecommunications(Natural Science Edition),2014,5(7):706-711.
[8] Lcala-Fdez J. KEEL Data-Mining Software Tool: Data Set Repository, Integration of Algorithms and Experimental Analysis Framework[J]. Journal of Multiple Valued Logic $Soft Computing,2011,12(17):204-209.
[9] 张恒巍,卫波,王晋东.基于分布估计蛙跳算法的云资源调度方法[J].计算机应用研究,2014,11(2):3225-3233.
ZHANG Hengwei, WEI Bo, WANG Jindong. The estimation of distribution of cloud resource scheduling method based on shuffled frog leaping algorithm[J]. Journal of Computer Application,2014,11(2):3225-3233.
[10] Thelwall, Wilkinson D. Data mining emotion in social network communication: Gender differences in MySpace[J]. Journal of the American Society for Information Society for Information Science and Technology,2010,61(1):190-199.
[11] 黎明,吴跃,陈佳.基于语义搜索引擎的云资源调度[J].计算机应用研究,2015,12(2):3735-3749.
LI Ming, WU Yue, CHENG Jia. Semantic search engine based on cloud resource scheduling [J]. Computer Application Research,2015,12(2):3735-3749.
[12] Gounder V, Prakash R, Abu-Amara H. Micheline data miming: date and techniques[J]. Wireless Communications and Systems,2014,1(1)1:1-6.
收稿日期:2016年1月22日,修回日期:2016年2月27日
作者简介:闫娜,女,硕士,讲师,研究方向:计算机应用、网络优化。
中图分类号TP393
DOI:10.3969/j.issn.1672-9722.2016.07.025
Network Data Synthesis Control Algorithm Based on Large Data Throughput Benefit Evaluation
YAN Na
(Shaanxi Vocational College of Finance and Economics, Xianyang712000)
AbstractIn view of the existing problems in the process of cloud network research, it is difficult to solve the problem, the evaluation mechanism is simple and it is difficult to solve the problem of network congestion. First, the cost of data control in the data life cycle is evaluated based on the data of the network data has a large data throughput performance of interval division. Then the user level quality factor is added to the cost function, so as to realize the effective control of the network data, and reduce the occurrence of network congestion. Simulation results show that this algorithm can improve the throughput performance of the network nodes, and enhance the performance of the network, and improve the performance of the node bandwidth, which has good practical value.
Key Wordscloud network, large data throughput, network data integrated control, resource scheduling, regulation cost, quality factor
