基于协同过滤的个性化应用推荐方案
2016-08-09崔刚
崔刚
【摘要】 本文借鉴互联网协同过滤算法,根据电信运营商实际状况,合理选取输入指标,探索“基于用户”和“基于物品”算法和用途的差异,将算法应用到手机应用个性化推荐中,应用效果提升明显,较好地符合互联网时代客户需求特征。
【关键词】 大数据 协同过滤算法 智能推荐 互联网应用
一、引言
4G时代,用户流量规模及价值提升至关重要,河南移动公司一直致力于以客户需求为中心,以运营为导向的流量经营研究。积极践行传统电信服务转型中“数字内容和应用”的发展模式理念,通过应用个性化应用推荐的探索,逐步完善“数字内容及应用精益运营体系”的建设目标。
传统的手机应用推荐没有深入识别真正有需求的客户,盲目下发营销推荐短信,客户转化率不足1%,造成资源的浪费且降低了客户满意度。本课题将重点解决根据用户消费行为快速、准确找到手机应用潜在目标用户的问题,通过引入互联网协同过滤算法,预先计算相似度, 从而迅速对推荐要求做出响应,满足真正有需求的客户,避免客户骚扰,提升客户转化率,驱动流量增长。
二、 实施思路
2.1 实施方法
手机应用个性化推荐的核心技术是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的物品或信息。基于协同过滤的推荐机制是利用集体智慧的典型方法,根据所有用户对物品或者信息的偏好,发现用户的相关性,或是发现物品或者信息本身的相关性,然后再基于这些关联性进行推荐。
2.2 模型选型
协同过滤( Collaborative Filtering, 简称 CF),一般是在海量的用户对物品或者信息偏好中,发掘出小部分和目标用户品味比较相似的用户成为邻居用户群,基于邻居历史偏好信息组织成一个排序的目录,为指定用户进行推荐。
核心问题是:如何找到与目标用户相似品味的用户集合?如何找到具有相似属性的物品或信息?
为了解决第一个问题“找到相似品味的用户”,采用基于用户的协同过滤推荐机制,在用户的历史偏好的数据上计算用户的相似度,基于相似用户的历史偏好信息,为当前用户进行推荐。
针对第二个问题“找到具有相似属性的物品或信息”,采用基于物品的协同过滤推荐机制,使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。
三、实施方案
协同过滤的核心步骤,主要包括如下三个步:1)收集用户偏好信息;2)找到相似的用户或物品;3)计算推荐。
算法实现流程如图1。
3.1 收集用户偏好
用户偏好度定义:根据不同行为反映用户喜好的程度将它们进行加权,得到用户对于物品的总体喜好,按照系统现有数据,选取“日均使用频次”作为偏好评估指标。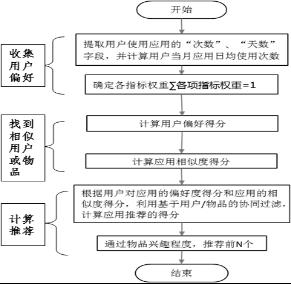

应用个性化推荐中,用户对某种应用的偏好度评价指标取“日均使用频次”。日均使用1次得1分,2次得2分,3次得3分,4次得4分,5次及以上得5分,生成评价结果清单。
3.2找到相似的用户或物品
1)相似度计算方法:
计算基础:向量(Vector)
计算结果:主要是计算两个向量的距离,距离越近相似度越大。
应用思路:基于用户-物品偏好的二维矩阵。
将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度;将所有用户对某个物品的偏好作为一个向量来计算物品之间的相似度。
2)如何根据相似度找到“用户 ”或“ 物品”的邻居:
(1)固定数量的邻居:不论邻居的“远近”,只取最近的 K 个,作为其邻居。
(2)基于相似度门槛的邻居:以当前点为中心,距离为 K 的区域中的所有点都作为当前点的邻居,此方法得到的邻居个数不确定,但相似度不会出现较大的误差。
3.3 计算推荐
1)基于用户的协同过滤(User CF)
计算思路:
(1)建立向量:按照每个用户对所有物品的偏好得到一个向量;(2)计算用户相似度:通过向量间的计算得到用户之间的相似度;(3)找到相似邻居:通过计算方法,找到当前用户X的 K 邻居群体;(4)推荐清单:根据邻居的相似度权重及对物品的偏好,预测当前用户X无偏好记录或未购买的物品,计算得到一个排序的物品列表向当前用户X推荐。
具体示例:对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 - 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。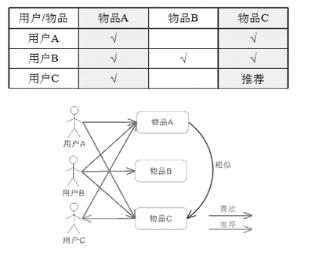
2)基于物品的协同过滤(Item CF)
计算思路: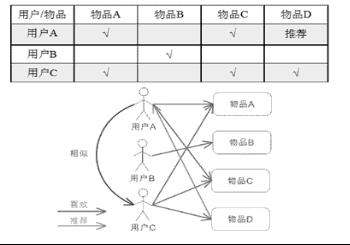
(1)建立向量:将所有用户对某个物品的偏好作为元素建立该物品的向量(2)得到物品相似度:通过向量间的计算得到物品之间的相似度(3)找到相似物品:通过计算方法,找到某个物品的相似物品(4)推荐清单:根据每个用户历史的偏好,预测当前用户尚未表示偏好的物品,计算得到一个排序的物品列表作为向当前用户推荐的清单。
具体示例:对于物品 A,根据所有用户的历史偏好,喜欢物品 A 的用户都喜欢物品 C,得出物品 A 和物品 C 比较相似,而用户 C 喜欢物品 A,那么可以推断出用户 C 可能也喜欢物品 C。
3)协同过滤推荐实例
假设要向U1推sohu,选择两个最近邻居
基于用户的协同过滤推荐得分:
U1:(U2 :0.85,U3:0.70, U4:0,U5:-0.79)
两个相邻的邻居为U2和U3,Sohu计算推荐的得分为:(0.85*3+0.70*5)/(0.85+0.7)=3.9
基于物品的协同过滤推荐得分:
Sohu: (QQ: 0.99, WeChat: 0.92, MSN:0.72,LeTV:0.93) 两个相邻的邻居为QQ和LeTV,Sohu计算推荐的得分为: (0.99*5+0.93*4)/(0.99+0.93)=4.5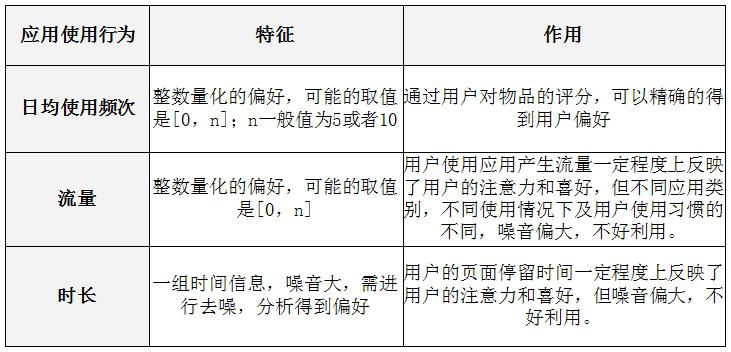
3.4用户/物品的协同过滤(UserCF/ItemCF)适用场景
UserCF适合用于内容推荐,因为做为一种物品,内容的更新非常快,每时每刻都有新的内容出现,而ItemCF需要维护一张物品相关度的表,如果物品更新很快,那么这张表也需要很快的更新,在技术上很难实现。绝大多数相关度表都只能做到一天一次更新,这在内容推荐的时候是不可接受的。
而UserCF只需用户相似度表,虽然UserCF也需要对新增用户更新相似度表,但在内容推荐中,内容的更新速度远高于新入网用户的加入速度,完全可以给用户相似度高的用户推荐热门内容,因为相比ItemCF,UserCF显然利大于弊。
同时从技术上考虑UserCF需要维护一张用户相似度的矩阵,ItemCF也需要维护一张物品相似度的矩阵。ItemCF适用于物品数据量远小于用户量,物品更新速度较慢。而UserCF适用于物品数据量远大于用户量,且物品更新速度快,推荐要求时效性高。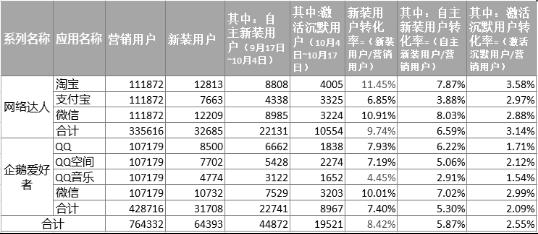
四、应用情况及效益分析
在实际的流量运营中,开展针对单用户多应用的组合营销,实现数据驱动的“轻资源、智能化”的实时营销。基于应用活性将淘宝、支付宝、微信三个应用组合为网络达人系列应用,将QQ、QQ空间、QQ音乐、微信四个应用组合为企鹅爱好者,对比运营。基于物品的协同过滤算法(ItemCF)得到网络达人和企鹅爱好者两个系列组合应用的潜在目标用户,经过个性化推荐运营后,网络达人系列应用高于企鹅爱好者系列应用的新装用户转化率。淘宝应用的新装用户转化率最高为11.45%,QQ音乐新装用户转化率最低为4.45%。运营效果数据如表3。
五、结束语
通过学习互联网较成熟的协同过滤算法,合理选取输入指标,探索“基于用户”和“基于物品”算法和用途的差异,将协同过滤算法固化到大数据分析平台中,通过对全部目标用户相似度的计算,可以支持对推荐要求做出迅速响应,从而达到拉升客户转化率的目的,有效缓解移动公司促销成本压力,较好地符合互联网时代客户需求特征。
参 考 文 献
[1]周军锋,汤显,郭景峰;一种优化的协同过滤推荐算法[J];计算机研究与发展;2004年10期
[2]张锋;常会友;使用BP神经网络缓解协同过滤推荐算法的稀疏性问题[J];计算机研究与发展;2006年04期.
[3]张光卫;李德毅;李鹏;康建初;陈桂生;;基于云模型的协同过滤推荐算法[J];软件学报;2007年10期
[4]张亮;推荐系统中协同过滤算法若干问题的研究[D];北京邮电大学;2009年
[5]施凤仙;陈恩红;;结合项目区分用户兴趣度的协同过滤算法[J];小型微型计算机系统;2012年07期
