基于出租车轨迹数据的人口活动分析
2016-08-02韩吉德王祖顺
韩吉德,王祖顺,王 霞
(青海省第二测绘院,青海 西宁 810001)
基于出租车轨迹数据的人口活动分析
韩吉德,王祖顺,王霞
(青海省第二测绘院,青海 西宁 810001)
摘要:根据轨迹数据识别出人们感兴趣的区域,并且挖掘出人们的日常出行特性,作为数据挖掘的一个热点逐渐受到人们的重视。目前,绝大多数大城市的出租车上都安装有GPS,其记录的轨迹数据在时间和空间上都包含丰富的信息,分析出租车的轨迹数据能在一定程度上反映城市人口的出行情况,挖掘有价值的信息。文中挖掘出租车轨迹数据中的乘客上下车的位置点数据,经过数据预处理、地图匹配以及整合后,对位置点进行有权重的热点区域分析,叠加到地图上进行人口活动分析。
关键词:出租车轨迹;数据挖掘;热点区域;人口活动
随着卫星技术、传感器技术、无线技术、RFID技术的出现和快速发展,实时追踪移动对象的运动轨迹已经变成现实,并且现在每天都产生着海量的移动对象的轨迹数据,这些看似杂乱无章的时空数据实际蕴含着丰富的信息,人们逐渐认识到,如何高效准确地挖掘出其中的价值变得尤为重要。数据挖掘是一个从不完整的、不明确的、大量的并且包含噪声,具有很大随机性的应用数据中,提取出隐含其中、事先未被人们获知、却潜在有用的知识或模式的过程。从海量的出租车轨迹数据中挖掘出人口活动的信息属于移动轨迹数据挖掘的范畴。数据挖掘的整个过程分为数据预处理、数据挖掘、结果解释和评价。
1地图匹配
出租车轨迹数据具有范围广、成本低、数据提取方便等优点,但是由于受到GPS定位精度的影响,位置点数据很难精确定位,往往会偏离交通路网,因此,为了更准确的分析,需要进行地图匹配,将位置偏差的点重新定位到交通路网上。
地图匹配必须满足两个前提条件:
1)GPS点所表示的车辆行驶在已知的道路网上;
2)匹配的道路网络数据精度比GPS点精度要高得多。
地图匹配算法多种多样,总体分为点到点的匹配、点到线的匹配、线到线的匹配,考虑到点到点的匹配算法的精度问题以及线到线的匹配算法的复杂性,本文选择点到线的匹配算法,该算法不仅考虑两点的距离,还将道路线信息加入考虑因素,设置一个匹配度的概念,如图1所示,假设待匹配点P到道路CG的垂直距离为d,设距离所占权重为φ,P点的行驶方向与道路的夹角(0~90°)大小为Q,角度所占权重为μ,再对两者加权相加,则P点到道路CG的匹配度为S。

图1 地图匹配
地图匹配算法的详细流程:读取出租车轨迹点—以该点为圆心确定搜索范围(100m)—匹配范围内的道路—计算待匹配点与道路的匹配度—选取匹配度最高的道路—更新待匹配点坐标。由于匹配的道路网数据坐标系为WGS-84,而GPS点经纬度也为WGS-84,故不需进行坐标转换。
2数据整合与热点区域分析
轨迹点数据因为其数据量巨大,在地图上的分布比较分散,从原始数据上很难挖掘出有价值的信息。因此需要对数据进行聚类,从而使数据能够分门别类。本文采用数据整合处理,取代复杂的聚类算法。数据整合就是将坐标位置在误差允许范围内的点聚为一个点,容差的值非常关键:容差过大会导致要素折叠或导致面或线被删除,还可能导致不应该移动的折点被移动。要使误差降至最小,选择的 x,y 容差值应尽量小。数据整合X,Y,需要将同一个坐标位置的重合点计数,以计数来表示权重。
有了每个点的权重信息以后就可以进行热点区域分析。本文采用核密度分析方法,该方法用于计算每个输出栅格像元周围的点要素的密度。概念上,每个点上方均覆盖着一个平滑曲面。在点所在位置处表面值最高,随着与点的距离的增大表面值逐渐减小,在与点的距离等于搜索半径的位置处表面值为零。搜索半径参数值越大,生成的密度栅格越平滑且概化程度越高。值越小,生成的栅格所显示的信息越详细。计算密度时,仅考虑落入邻域范围内的点或线段。如果没有点或线段落入特定像元的邻域范围内,则为该像元分配NoData。如果面积单位比例因子的单位相对于要素(点间距离或线段长度,取决于要素类型)很小,则输出值可能会很小。
本文的研究路线主要为:
Step1:数据预处理。该阶段主要对数据进行筛选、集成、选择等操作;
Step2:数据挖掘。对经过数据预处理的轨迹点数据进行整合、密度分析;
Step3:结果解释和评价。将分析结果与电子地图叠加,结合POI位置,分析人口活动规律。
3实验
本文使用的是北京市2012-11-01全天24h的2000辆出租车轨迹数据,数据说明如表1所示。

表1 数据项说明表
数据预处理主要分为以下几点:
1)北京市经纬度范围为39°28′~41°05′N、115°25′~117°35′E,凡是超过此范围的数据都将被剔除;
2)数据项出现空的情况:当速度为空,因为不影响本文的研究,故可以忽略,其余项如经度、纬度、时间等如果为空,就将该条记录删除;
3)提取上下乘客点:根据“触发事件”字段,提取出下客点(0=变空车)、上客点(1=变载客)数据;
4)将全天24h的数据分成5个时段,分别为0:00—8:00、8:00—12:00、12:00—16:00、16:00—20:00、20:00—24:00,以便于从时空两个角度分析人口出行活动情况。
数据整合操作使用ArcMapDataManagementTools工具箱中的integrate工具。通过不断调整容差值,确定容差为50m时,整合效果比较合适。经过整合以后,同一个位置会表示多个点,采用SpatialStatisticsTools工具箱中的CollectEvents工具可以完成点数的统计,该工具可将重合点合并:它会创建一个新的输出要素类,其中包含在输出要素类中找到的所有唯一位置。然后,它会添加一个名为ICOUNT的字段,以保存每个唯一位置所有事件点的总和。
经过CollectEvents,生成的Icloud字段作为核密度分析中Population的值,即权重。通过调整搜索半径及输出象元大小,得到详细程度适当的结果。
整个过程通过ArcMap建模得到,模型如图2所示。

图2 热点分析建模
为了结合北京市的地图信息,将ArcGISonline上共享的北京市地图(含POI)加载到本地,并调整透明度,与栅格图叠加,因为含有POI信息,因此更有利于说明人口活动的规律。图3~图5为3个时段乘客上车点的数据分析得到的热点区域分布图(说明:因为不是最新数据,所以以下分析仅作学术研究说明,并不一定与实际相符)。
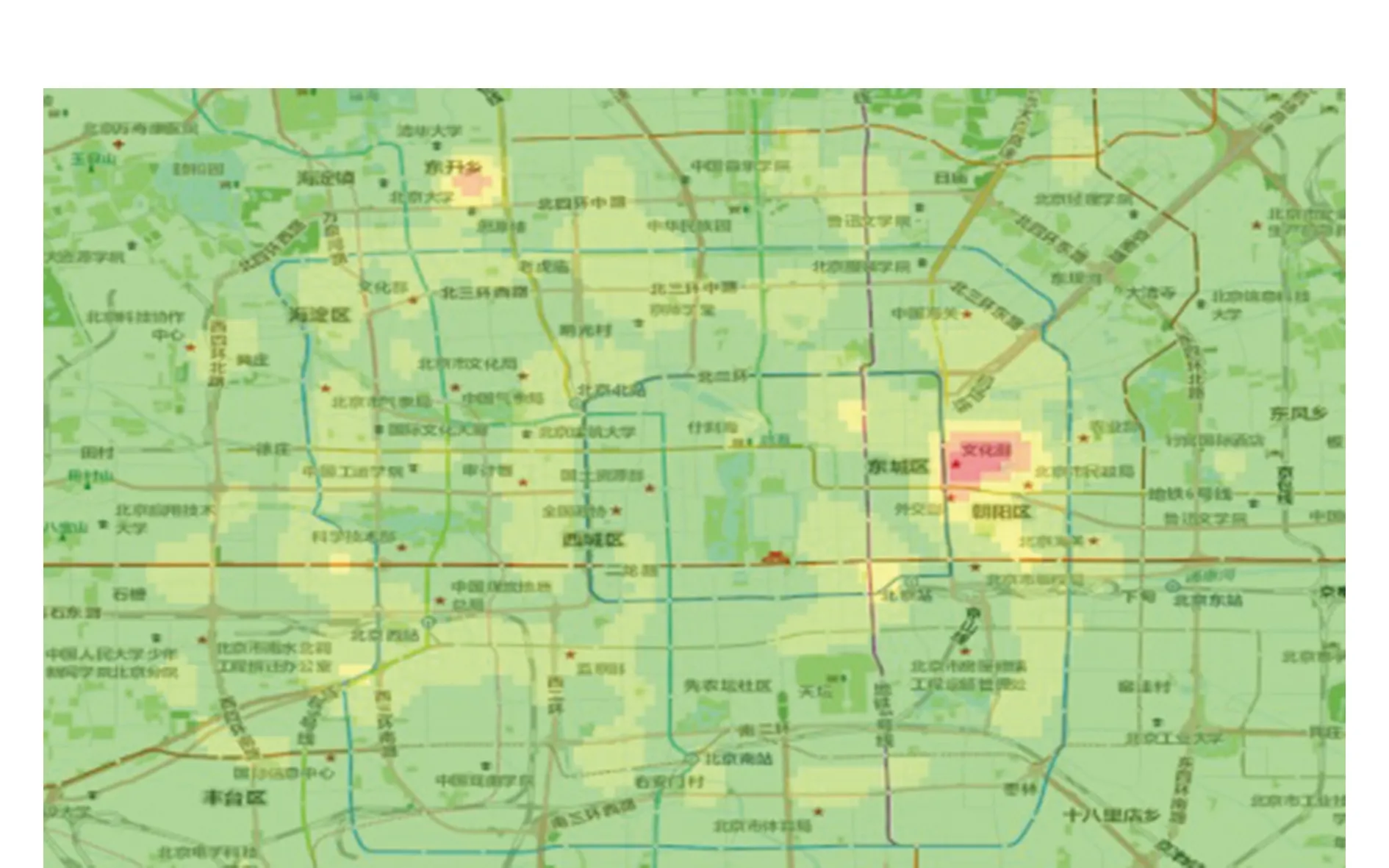
图3 0:00-8:00

图4 8:00-12:00
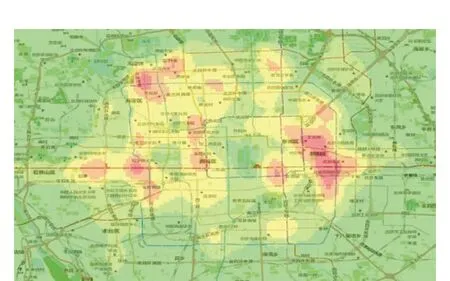
图5 20:00-24:00
总体来说,从凌晨到8:00人口活动非常稀少,整个图中只出现两个相对比较密集的点,从地图上得知分别是工人体育场、朝阳医院附近以及北京大学、清华大学附近;而到8:00-12:00,这时候的上班人群比较多,乘车点分布较为分散,五环以内都比较密集,但相对的左侧的海淀区、丰台区相对于右侧的朝阳区较为密集,因此分析,上午从海淀区、丰台区出发上班的相对较多。晚上20:00—24:00,朝阳区与东城区区域乘车人口最为密集,而海淀区、丰台区则相对较稀疏,与白天形成对比,相对比较合理。因此分析整体的大趋势是白天从海淀区、丰台区往朝阳区、东城区,而到夜晚则相反。
再对比乘客下车的位置点分布:
下车点(见图6)位置说明这个时间点乘客想要到达的目的地,从图上显示分布较为密集主要是火车站、飞机场等,从左往右,自下而上依次为丰台西站、北京西站、中国海关,机场路上的酒店宾馆聚集

图6 0:00-8:00(下车点)
点以及飞机场。因为在这个时间段去的目的地肯定是车站或机场较多。因此0:00-8:00人口的主要活动趋势是从市区到各个火车站以及机场。
4结束语
由于数据的局限性,本文只采用了一天的数据进行分析,没有对比工作日与休息日之间的不同,并且本文只对人们的出行活动做了简略的、简单的分析,但是基于位置与时间的轨迹数据对于时空GIS的研究有重要的意义,通过对人们出行规律的准确掌握,可以提供基于位置的各种各样的服务,为商铺、公园等选址提供决策依据,优化交通调度系统,有效地缓解交通堵塞等。
参考文献:
[1]郑宇,谢幸.基于用户轨迹挖掘的智能位置服务[J].中国计算机学会通讯, 2010, 6(6): 23-30.
[2]马云飞.基于出租车轨迹点的居民出行热点区域与时空特征研究[D].南京:南京师范大学, 2014.
[3]张明月.基于出租车轨迹的载客点与热点区域推荐[D].长沙:湖南科技大学, 2013.
[4]袁冠.移动对象轨迹数据挖掘方法研究[D].北京:中国矿业大学, 2012.
[5]阳宪惠.工业数据通讯与控制网络[M].北京:清华大学出版社,2001.
[6]YUANNJ,ZHENGYu,ZHANGLiuhang,etal.T-Finder:ARecommenderSystemforFindingPassengersandVacantTaxis[C].IEEE,KnowledgeandDataEngineering, 2012.
[7]HUANGL,LIQ,YUEY.ActivityidentificationfromGPStrajectoriesusingspatialtemporalPOIs’attractiveness[C].ZhouXF.Proceedingsofthe2ndACMSIGSPATIALInternationalWorkshoponLocationBasedSocialNetworks.SanJose,California:ACMPress, 2010.
[8]YUEY,HUB.Identifyingshoppingcenterattractivenessusingtaxitrajectorydata[C].JiangB,HuangW.Proceedingsofthe2011internationalworkshoponTrajectorydataminingandanalysis.Beijing:ACMPress, 2011.
[责任编辑:张德福]
DOI:10.19349/j.cnki.issn1006-7949.2016.10.014
收稿日期:2015-10-11
作者简介:韩吉德(1977-),男,工程师.
中图分类号:P208
文献标识码:A
文章编号:1006-7949(2016)10-0069-03
Population activity analysis based on taxi trajectory data
HAN Jide,WANG Zushun,WANG Xia
(QinghaiProvinceNo.2SurveyingandMappingInstitute,Xi’ning810001,China)
Abstract:It is difficult in data mining to discover the region of interest and dig out the people's daily travel features according to the trajectory data,which gradually draws the attention of the people. At present, the taxi in most of the cities has been set with GPS,which records trajectory data with rich information in time and space. To a certain extent, it can reflect the travel of the urban population and dig out useful information by analyzing the trajectory data of the cab. This paper mainly presents the positions of getting on or off the taxi and then data preprocessing, map matching, and integration. After all it can be done to analyze the region of interest with the weight and the trajectory data of the cab with map.
Key words:taxi trajectory; data mining; region of interest; population activity
