基于HBase的位置数据区域查询研究
2016-08-02何首武蒋林利李晓英
何首武,蒋林利,李晓英,3
(1.桂林理工大学南宁分校,广西南宁 530001;2.广西科技师范学院数学与计算机科学系,广西来宾 546199;3.武汉大学计算机学院,湖北武汉 430072)
基于HBase的位置数据区域查询研究
何首武1,蒋林利2,李晓英1,3
(1.桂林理工大学南宁分校,广西南宁530001;2.广西科技师范学院数学与计算机科学系,广西来宾546199;3.武汉大学计算机学院,湖北武汉430072)
摘要:随着位置服务的广泛应用,如何对海量位置数据进行高效的空间查询成为研究热点.结合对分布式数据库HBase存储机制与Geohash编码原理的研究,基于GeoHash构建空间索引,设计位置数据存储模型,并在此基础上探讨一种多边形区域查询算法.通过与传统MySQL数据库的试验对比,验证了该算法具有较高的查询效率和良好的可扩展性.
关键词:位置数据;HBase;GeoHash;区域查询
0 引言
面对海量的空间数据,如何对其进行高效存储、管理与发布,已成为一个迫切需要解决的问题[1].将NoSQL数据库应用于GIS是解决大规模空间数据存储与管理的有效手段[2].HBase作为Apache Hadoop中的一个子项目,已在海量空间数据的管理中得到广泛应用,如何在HBase数据库中实现高效的空间查询成为了研究热点.
传统关系数据库通常使用基于树的索引(如R树、四叉树等)实现空间查询[3],以此类索引处理海量空间数据效率较低.基于行健的HBase数据库难以支持传统的多维空间索引,因此需要对空间数据进行降维处理,以映射到一维空间进行索引和查询.文献[4,5]采用Hilbert曲线降维法,利用数学模型将多维坐标降维为字符串,以便HBase存储和处理,并且能够最大限度地保证空间对象之间的逻辑相关性;其缺点是降维过程中运算量比较大.
Geohash[6]是一种地理编码,它可以把二维的经纬度坐标编码成一维的字符串,已被广泛应用于需要使用一维索引处理空间数据的情况[7],但对Geohash在区域查询的应用探讨较少.文献[8]探讨了基于Geohash的面数据区域查询,但其主要是基于关系数据库MySQL实现.
本文依据HBase数据模型及位置数据的特征,基于GeoHash构建空间索引,并在此基础上探讨了一种多边形区域查询算法,为海量位置数据的存储与处理提供一种有效的解决方案和思路.
1 Geohash概述
Geohash编码是一种经纬度地理编码系统,能够将经度信息和纬度信息进行转换,得到一个可以进行排序和比较操作的字符串编码.Geohash算法的主要思想是对给定的经纬度值,利用二分法的思想来进行无限的区间逼近.本文以纽约时代广场某地的坐标值(-73.980844,40.758703)为例,介绍Geohash编码算法.
(1)地球纬度区间是[-90,90],将其进行二分为[-90,0],[0,90],称为左右区间,可以确定40.758703属于右区间[0,90].
(2)将右区间进一步二分,递归上述过程.可以预见,40.758703总是属于某个区间[a,b].随着每次迭代区间[a,b]在不断缩小,根据极限可知[a,b]会收敛到40.758703,用δ来描述就是,任意给定一个ε,总存在一个N使得:为任意给定的纬度.
(3)上述过程保证了算法收敛性,收敛的过程如下:如果给定的纬度x0.758703)属于左区间,则记录0,如果属于右区间则记录1,这样随着算法的进行会产生一个序列10111,序列的长度跟给定的收敛次数N相关.同理,计算经度-73.980844的位序列为01001.按偶数位放经度,奇数位放纬度的规则,以精度递增的顺序将经度和纬度位序列交叉排列生成一个新的位序列0110010111.根据Geohash算法中所使用的Base32编码表[6],对合并后的二进制序列进行Base32编码,从而得到地理坐标(-73.980844,40.758703)的Geohash编码为dr.
根据Geohash算法的编码规则,当编码长度越长表示的区域精度就越高,可以根据具体应用需求,来确定合适的编码长度.通过Geohash编码,空间上相邻的位置在编码上可能具有相同的前缀,使之在解决附近地点搜索的问题上具有明显优势.
2 基于HBase的位置数据存储模型
HBase是一个基于列模式、稀疏存储、排序的映射表,表中的数据单元通过行键、列族和列限定符和时间戳进行索引和查询定位,每一个列属于特定的列族.HBase表模式的设计主要包括行键设计和列族设计.本文以纽约出租车数据[9]为研究对象,出租车载客记录包含出租车编号、司机编号、起始终止的时间和地点、行驶距离、行驶速度等14个要素,主要数据的详细描述见表1.

表1 出租车数据说明
位置数据的处理单元是二维坐标(dropoff_longi⁃tude,dropoff_latitude),而HBase只支持一维数据的处理,因而,需要对空间数据进行降维处理.本文基于Geohash在出租车下客的经度与纬度上建立索引,采用两者的Geohash字符串编码作为HBase行健.针对位置对象的特征,HBase数据表设计为单个列族,每个行键下会有多个列限定符,数据表结构表2所示. HBase按照行健字典顺序进行排序,Geohash字符串前缀匹配越多的坐标点,其在HBase中就会被存储得越接近,因而有利于实现数据的本地化.

表2 HBase数据表结构
3 基于Geohash的多边形区域查询
多边形区域查询,指给定一个空间多边形区域,检索出该多边形区域内的所有空间对象信息[10],比如查询时代广场街区内的所有出租车信息.本文的多边形区域查询过程:首先,建立多边形查询区域与Geohash编码的关联,将多边形查询区域转换成一组Geohash编码.然后,在该Geohash前缀集上执行HBase前缀匹配过滤,返回候选集合.最后,执行精确过滤,过滤无效的查询对象,最终返回满足条件的查询结果.具体流程见图1.
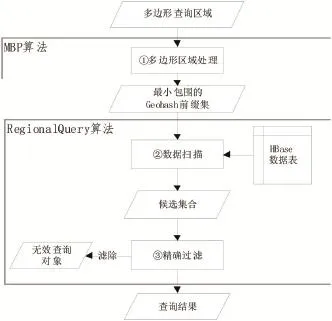
图1 多边形区域查询流程
3.1相关概念
为了便于多边形区域查询算法的描述与讨论,先列出相关的定义:
1.形心[11](Centroid)多边形的形心,指平面多边形的几何中心.
2.凸包[12](Convex Hull)是一个计算几何中的概念,给定二维平面上的点集,凸包就是将最外层的点连接起来构成的凸多边型,它能包含点集中所有的点.
3.2多边形区域处理
一个Geohash字符串编码代表的是一个规则的矩形,多边形区域处理的核心是将被查询的多边形区域转换为多个邻接的Geohash矩形区域,且这些矩形组合区域的凸包最小包含着该多边形区域;即计算一组最小包含查询区域的Geohash前缀集(Mininum Bounding Prefixes-MBP),详见算法1.
算法1MBP算法
输入:多边形区域
输出:最小包含查询区域的Geohash前缀集
步骤:
1)计算多边形查询区域的形心.
2)根据指定精度,计算该形心对应的Geohash编码.由于计算Geohash时需指定字符精度,本算法根据查询区域的应用需求,指定初始精度INIT_PRECESION.
3)基于该Geohash编码的矩形区域计算其凸包,并检查该凸包对查询多边形的包含情况,若不包含,则执行步骤4;否则,返回该Geohash编码,结束查询.
4)将该Geohash编码加上它的8个直接邻居[8],计算该组合区域的凸包,并检查该凸包对查询多边形的包含情况.若不包含,则降低初始精度INIT_PRECESION,即INIT_PRECESION减一,扩大查询范围,重复执行步骤2;否则,返回该Geohash编码加上它的8个直接邻居所组成的集合,结束查询.
MBP算法的输入是多边形查询区域,输出为计算出的包含查询区域的最小包围Geohash前缀集.最小包围使得HBase扫描的次数和扫描覆盖的空间区域降到最小,以提高查询效率.该算法的关键在于确定最佳的Geohash初始精度,以提高查询效率.
3.3HBase数据扫描与精确过滤
HBase数据扫描阶段通过调用MBP算法获取Geohash前缀集,执行HBase前缀匹配扫描,返回查询所得的候选集合;在精确过滤阶段,检查每一个返回的候选对象是否落在查询多边形区域内,并移除位于前缀集区域但不位于多边形查询区域内的无效数据;最终返回符合条件的结果集.算法2包含了多边形区域查询流程(图1)的第②步和第③步.
算法2RegionalQuery算法
输入:多边形查询区域
输出:查询区域内的结果集
步骤:
1)根据多边形查询区域,调用MBP算法获取最小包围的Geohash前缀集.
2)对于Geohash前缀集中的每个Geohash编码,逐一执行HBase前缀匹配扫描,返回所有候选结果集.
3)对于候选结果集的每个元素,检验该元素代表的空间位置是否包含在多边形查询区域内,若未包含,则从结果集移除该元素.
4)返回符合条件的所有results.
4 试验设计与结果分析

图2 HBase与MySQL的区域查询效率对比
4.1试验环境及数据
试验由4台配置相同的服务器组成HBase集群,每台服务器的软硬件环境如表3所示,其中一台机器单机测试MySQL.试验数据采用2013年全年的纽约出租车数据,平均每月的数据文件约1.4亿条记录,全年数据总量大小约30G.试验的查询区域是半径不超过2.5km的任意几何区域.

表3 试验环境
4.2多边形区域查询性能分析
试验对比不同数据量下,HBase与MySQL数据库下区域查询算法的响应时间.从图2a可以看出,随着数据量的增大,HBase耗时很少且查询响应时间基本不受影响,但MySQL查询耗时上升较快.将查询区域扩大并基于更大规模数据的实验(图2b),MySQL查询耗时随数据量的增长而急剧上升;而在HBase集群下,该算法的响应时间虽有所增加,但幅度变化较小.试验表明,在HBase集群下该算法具有较好的时效性.
5 结语
云计算技术为海量数据的存储提供了一种新的解决方案.Geohash编码把二维经纬度坐标降维成一维字符串,且空间位置相邻的Geohash编码具有相同的前缀,据此,本文基于Geohash构建空间索引,并基于该索引探讨一种多边形区域查询算法.与传统关系数据库MySQL相比,HBase集群环境下查询效率有较大的提升,可以满足区域查询中的时效性要求,为更高层次的应用提供了参考.
[参考文献]
[1]郑坤,付艳丽.基于HBase和GeoTools的矢量空间数据存储模型研究[J].计算机应用与软件,2015,32(3):23-26.
[2]刘经南,方媛,郭迟,等.位置大数据的分析处理研究进展[J].武汉大学学报:信息科学版,2014,39(4):379-385.
[3]过志峰,王宇翔,杨崇俊.空间数据索引与查询技术研究及其应用[J].计算机工程与应用,2002,38(23):176-178.
[4]WANG L,CHEN B,LIU Y.Distributed storage and index of vector spatial data based on HBase[C].Proceedings of the 2013 21st International Conference on Geoinformatics.Piscataway:IEEE,2013:1-5.
[5]陆锋,周成虎.一种基于Hilbert排列码的GIS空间索引方法[J].计算机辅助设计与图形学学报,2001,13(5):424-429.
[6]Niemeyer G.Geohash[EB/OL].2013-06-20,http://en.wikipedia.org/wiki/Geohash.
[7]DIMIDUK N,KHURANA A.HBase in Action[M].New York:Manning Publicatons Co,2012:203-215.
[8]金安,程承旗,宋树华,等.基于Geohash的面数据区域查询[J].地理与地理信息科学,2013,29(5):31-35.
[9]NYC Taxi Trips by andresmh[EB/OL].2014-11-11.http:// www.andresmh.com/nyctaxitrips/.
[10]丁琛.基于HBase的空间数据分布式存储和并行化查询算法的研究[D].南京:南京师范大学,2014.
[11]Centroid[EB/OL].[2015-05-13].https://en.wikipedia.org/ wiki/Centroid.
[12]Convex hull[EB/OL].[2003-11-03].https://en.wikipedia. org/wiki/Convex_hull.
(责任编辑:李洁坤)
中图分类号:TP311
文献标识码:A
文章编号:2096-2126(2016)03-0140-04
[收稿日期]2016-03-02
[基金项目]2015年度广西职业教育教学改革立项项目“计算机应用技术(Web方向)“产品驱动”实践教学体系的改革研究与实践”(桂教职成(2015)22号)。
[作者简介]何首武(1979—),男,山西河曲人,硕士,讲师,研究方向:云计算、数据管理。
[通讯作者]李晓英(1981—),女,山西汾阳人,硕士,讲师,武汉大学计算机学院访问学者,研究方向:数据管理。
The Research of Location Data Regional Query Based on HBase
HE Shouwu1,JIANG Linli2,LI Xiaoying1,3
(1.Campus of Nanning,Guilin University of Technology,Nanning,Guangxi,530001China;2.College of Mathematics and Computer Science,Guangxi Science&Technology Normal University,Laibin,Guangxi,546199 China;3.Computer School,Wuhan University,Wuhan,Hubei,430072 China)
Abstract:With the growing popularity of location-based services,how to make the efficient spatial query in the massive location da⁃ta has become an important research topic.With the research of storage mode of distributed database HBase and Geohash code,the data⁃base model of the location data was proposed,in which the row key was designed by the method of the spatial index based on GeoHash.A polygon region query algorithm is discussed on the basis of the above work..The HBase cluster environment is used to verify high efficien⁃cy of the proposed method.Compared with the traditional MySQL database,the proposed algorithm achieves better query efficiency and scalability.
Key words:location big data;HBase;GeoHash;regional query
